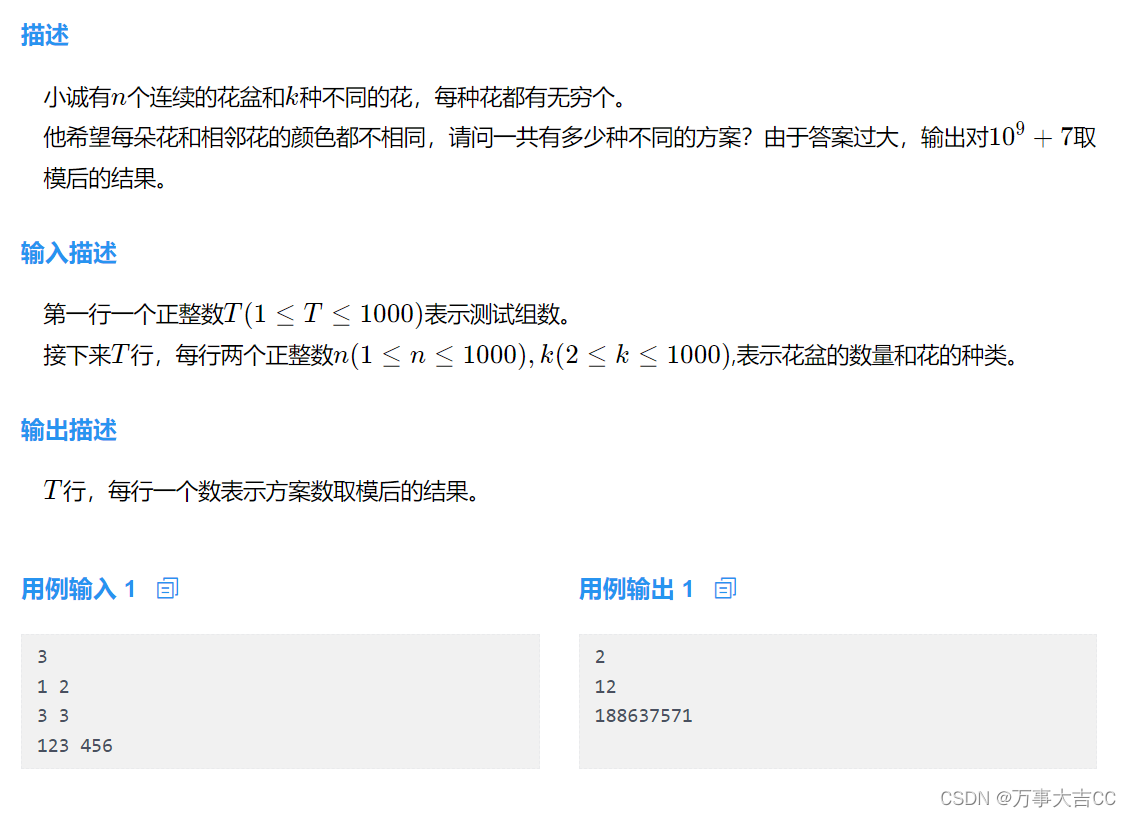
无边无形的互联网遍地是数据,品类丰富、格式繁多,包罗万象。数据采集,或说抓取,就是把分散各处的内容,通过各种方式汇聚一堂,是个有讲究要思考的体力活。君子爱数,取之有道,得注意遵守相关的法律法规和网站的使用政策😎
楔子
21世纪是信息时代,信息就是财富。数据(信息)采集是指从信息使用者的需要出发,通过各种渠道和形式获取相关信息的过程.。采集及时、准确、全面的信息是信息管理的基本前提,同时也是管理者决策的参考依据。
写论文时,从统计局网站粘贴几个数值;不定时将公示结果转存到Excel;批量把在线的高清美图下载到本地。这些都是 WEB 数据采集的日常例子。
信息采集最简单最原始的方式,就是人力直接操作,CTRL+C、CTRL+V一套组合拳下来,数据就到碗里来了👏🏻。不过,这数据量一旦上来,铁打的人都吃不消。于是乎,人们想到了用电脑来代替人工,爬虫程序就这样诞生了。
在此之前,我们应该先简单了解下网页内容渲染机制。
网页渲染机制

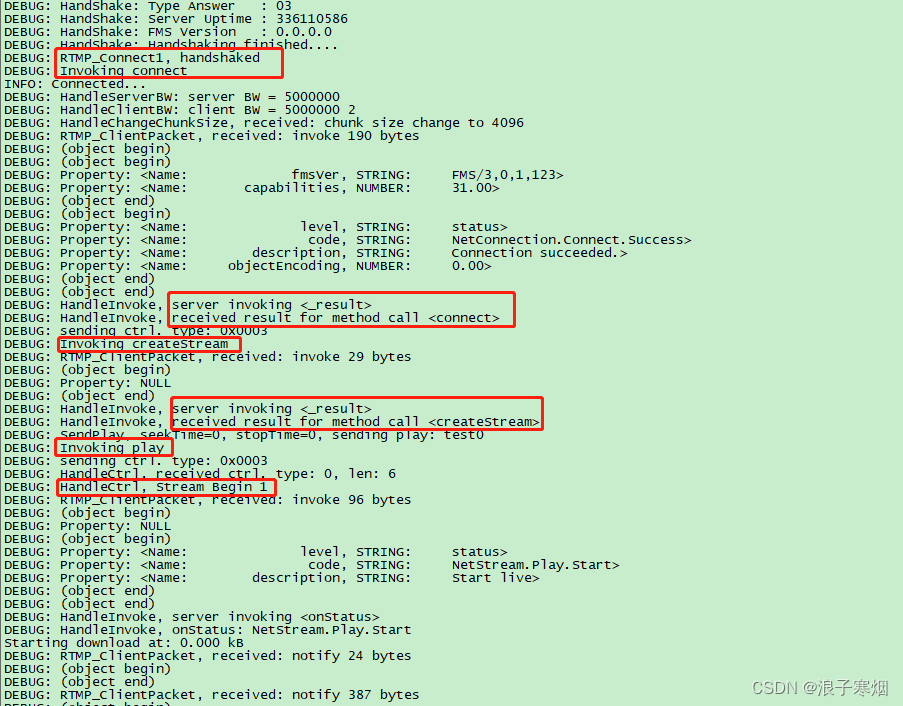
上图是 WEB 页面交互的简单模型,不谈及安全机制、浏览器兼容等😄。
常见自动化程序方案
所谓的自动化程序,就是用机器大批量地发起请求,拿到响应后再做处理。专业术语叫做
网页爬虫或者网页机器人。
模拟请求(基于代码或爬虫框架)
此方案需要我们至少熟悉一门编程语言(Python、Node.js、Java等),自行编写代码或者借助优秀的开源爬虫框架,实现数据获取。某些场景,还需要通过抓包分析目标网站的参数规则,然后通过组合式请求方能达到目的。
这里罗列下我用过或收藏且还在不断更新维护的框架:
| 名称 | 开发语言 | 简介 |
|---|---|---|
| Scrapy | Python | A fast high-level web crawling & scraping framework for Python. |
| Pyspider | Python | A Powerful Spider(Web Crawler) System in Python. |
| Nutch | Java | 一种高度可扩展、可伸缩的开源 Web 爬虫软件项目。功能强大,支持 Hadoop 集群内运行 |
| webmagic | Java | 一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。真的非常简单😄 |
| Spiderman2 | Java | 开源Web数据抽取工具,我没实际使用过 |
| node-crawler | Node.js | Web Crawler/Spider for NodeJS + server-side jQuery 😉 |
开发者工具 F12 🛠️
首先访问目标网站,按需进行登录,然后按下键盘 F12(或者 Ctrl+Shift+I)进入开发者工具,可以在控制台中写或贴入 JS 脚本,回车收尾😎。
这是我常用的一种方式,用户验证脚本跟少规模作业。
自动化测试工具(Selenium/Puppeteer/Playwright)
WEB 自动化测试工具,是指通过程序代替人工完成验证 WEB 功能的过程。当然,也能利用它来抓取数据。这类工具通过驱动程序(webdriver、DevTools Protocol),驱使浏览器执行既定的动作/脚本。
- Selenium:老牌大哥,我最开始接触的自动化测试工具,支持 Chrome、Edge、Firefox、IE、Safari 等浏览器,对开发语言支持也很广:Java、Python、C#、Ruby、JavaScript
- Puppeteer: Chrome 开发团队在 2017 年发布的一个 Node.js 包,用来模拟 Chrome 浏览器的运行。主打对 Chrome 的良好支持,社区有针对 Java、Python 版本。
- Playwright:微软大厂出品,浏览器支持 Chrome、Edge、Firefox、Safari,官方提供 Java、Python、Node.js、C# 编程语言的 SDK。
Electron / Traui
这两个软件跟上一节工具基本一致,之所以单独列出来,是因为它们提供了更丰富的接口,既能控制浏览器完成任务,又可以制作 GUI 界面(可用于与爬虫程序交互)。
2019年那会,我用闲余时间基于 Electron 做了个小玩具:


浏览器扩展(插件)
官方应该叫做浏览器扩展(Extensions),但是我们习惯叫做插件😄,后续文章我将重点以此方式进行实践。
浏览器扩展(插件)是运行在特定浏览器,遵循相关规范的应用程序包,由 JS、CSS、HTML 组成,能够管理标签页、注入代码、操作DOM、监控页面活动等。
插件功能非常强大,具体的文档详见Chrome Extensions Document。不过有一个小遗憾是不能在插件内打开标签页的开发者工具,官方给出的回答是出于安全考虑。
有大佬做的强大插件webscraper插件(本地使用免费)👍。
小结
我们在做数据采集时,可以根据实际情况灵活选择方案。不过,无论是何种方式,都要随着目标网站的更新迭代,做相应的适配,否则会出现程序无效的情况,而这是一个耗时耗力的过程🙂。
另外,部分网站会对自动化测试工具进行检测,可以参考:bot.sannysoft.com/,正常浏览器会看到如下的结果图。

拦路虎🧱
拦路虎之 IP 限制
当 ip 被限制,就无法正常访问网站或服务。我们的请求很可能被防火墙、网关、WAF(Web 应用防护系统)等前置设备、应用拦截,压根没有到藏在后面的网站。常用应对方式是更换终端IP,比如用代理。
拦路虎之验证码
验证码就是用来拦截爬虫程序的,常见有字符图片验证码(数字+字母+中文,再来点干扰线跟字符变形,增加识别成本),也会有逻辑交互类,以及手机/邮箱接收验证码。

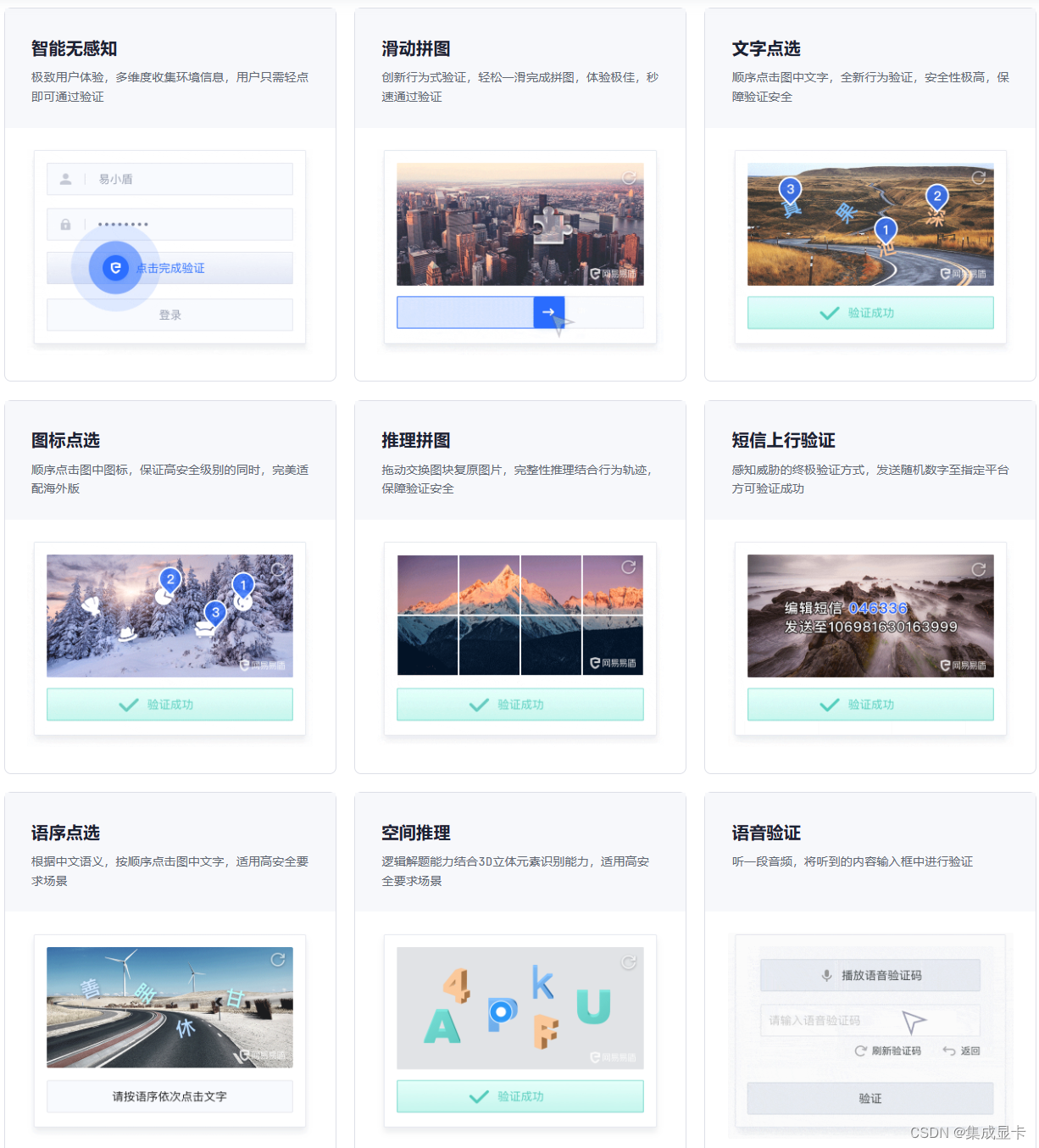
现代验证码越来越先进(下图是网易网盾首页列出来的常见类型),即使对正常用户也是很艰难才能完成验证。
这里不得不提一下谷歌「我不是机器人」的验证:reCAPTCHA ,没少被它蹂躏🤣。但是关于 reCAPTCHA 又有一个让我觉得非常惊艳的故事,是关于如何把人类纸质书数字化的,当时靠人工、机器字符识别的效率、效果都不行,于是该公司(后来被谷歌收购)想到把书籍扫描件分割为无数个小图,显示为验证码,让用户进行识别,然后得到最多的结果作为纸质书内容的数字字符(会有算法的参与),具体的看这篇文章:你以为自己在填验证码,其实你是在给Google义务劳动。
这真是太酷了!全人类共同参与到知识数字化进程中来,是在为人类文明做贡献,想想就很激动👏。

聊完常见验证码,是不是要开始说下怎么怎么自动识别它们?
对于文字型可以用OCR,简单交互类的可以用脚本模拟人工拖拽动作,逻辑类的话就难很多,需要对症下药。当然也可以花钱调商用接口,我用过的有超级鹰。
拦路虎之行为检测
关于行为检测,我没有深入了解,只是在一个爬取某国外社交平台数据时,直接告诉我,是因为操作路径每次都一样而被拦截😒。
结语
有数据的地方就有江湖,爬取与反爬取,是一个长期博弈的过程。今天道高一尺,明日魔高一丈,唯有不断学习进步,方能跬步前行。
此外,数据采集是整个流程的第一环,以后还需要对数据进行清洗、真假鉴定、切割分类、打标签等等。就好比厨房做菜,采集即为买菜回来,接着要挑选、洗菜、切菜、烹饪、摆盘、上桌、洗碗刷盘。