生活就像一颗巧克力,你永远不知道下一颗是什么味道
——《阿甘正传》
文章目录
- 定义
- 图纸
- 一个例子:假如你的采集器供应商提供了不同类型的返回值
- 单独的遍历流程
- 实现
- 碎碎念
- 如果读写同时进行会发生啥?
- 外部迭代和内部迭代
- 迭代器和其他模式
- 迭代器和组合
- 迭代器和状态
定义
提供一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示
迭代器模式,又称为游标模式。所以迭代器和游标本质上是一回事,虽然在各个语言中的具体实现和命名会有差异
比如Java里面的容器类有的那个东西叫迭代器、但是操作数据库时的那个ResultSet我们又将他称之为游标,但本质上他们是一回事
迭代器在Java和.net环境中的应用随处可见,两者的默认容器的实现中都使用的迭代器模式,而且他们的foreach遍历,本质上都是对迭代器遍历写法的简化
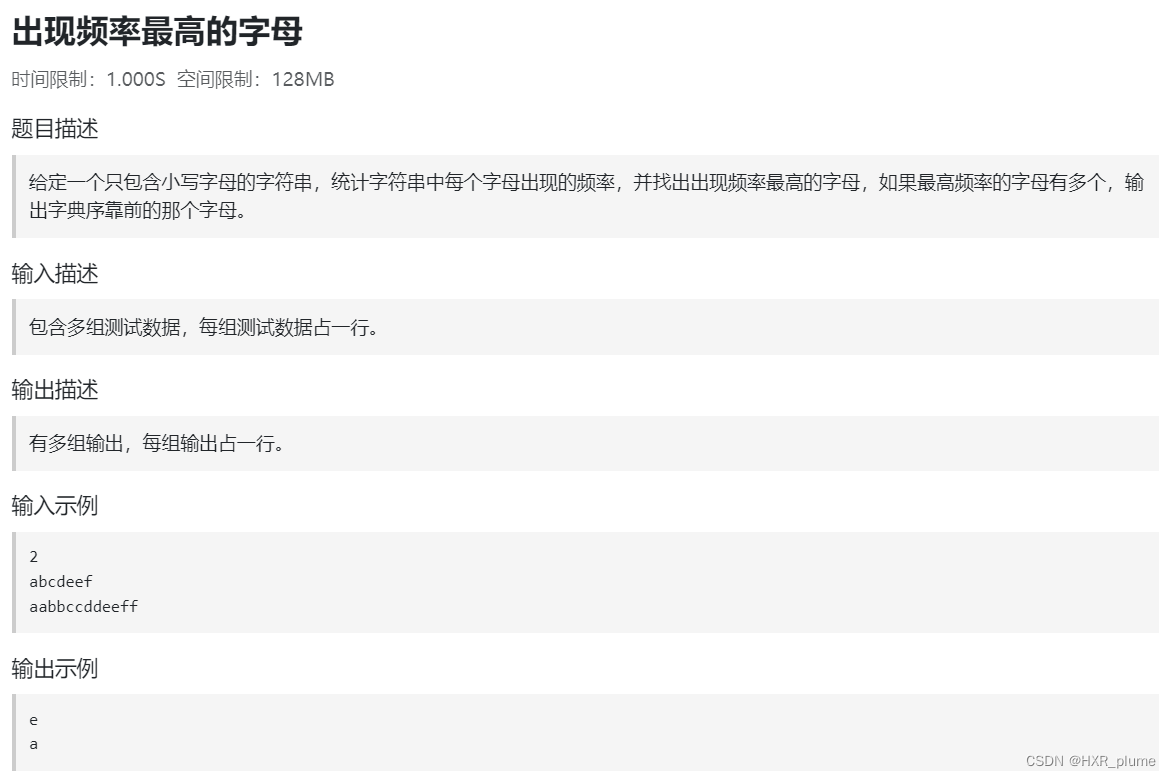
图纸
一个例子:假如你的采集器供应商提供了不同类型的返回值
这个名字好,不去写本日系轻小说都可惜了,恨不得一个标题就把内容全剧透完
虽然这个标题又俗又长,但是这种情况其实非常常见。至少在鄙人目前还不算长的职业生涯里,几乎每次换设备供应商都会有 这种情况的出现。因为这玩意也没个标准,一些老式设备返还的甚至都不是json。所以这个例子算抛砖引玉,但我由衷地希望 各位道友不需要考虑这样的问题
准备好了吗?这次的例子开始了:
假定你的公司升级考勤机,从原来的磁卡考勤机,换成人脸考勤机。但是磁卡考勤机不会直接报废,因为某些特殊位置依然可以使用他。这样一来,你每次读取数据的时候就要同时读取两种考勤机上的数据。
接着,我们根据两种考勤机的API,构造出这样一个结构:
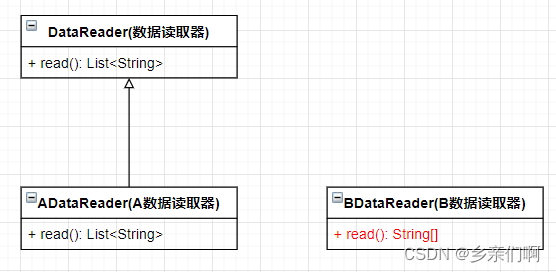
我们定义了一个 **DataReader(数据读取器)**接口用于定义可以从考勤机硬件上获取到的信息(比如考勤机号、ip地址等数据),在里面我们通过 read() 方法读取考勤机上的数据,并把读取到的数据以返回值的形式返回给 client代码。
但是在写 DataReader 的具体实现的时候,出现了一个很严重的问题,我们发现A类型的考勤机API和B类型的考勤机API,在读取考勤机上的数据时,提供了完全不同的返回值
为了简化所以使用了 String 类型作为返回值,但是实际情况考勤机返回的一定是各家考勤机自己定义数据格式的原始数据。这时候一般做法是:定义一个包含所需信息的数据bean,并在 read() 方法中把读取到的原始数据转换成你自己定义的bean对象
这就很尴尬了,不同的集合类型,我们没办法用相同的方式去遍历他们,这就意味着在操作A考勤机的返回值时我们要这样写:
for(int i = 0;i<list.size();i++){
String element = list.get(i);
//对element做的操作
}
而当考勤机是B时,我们要这样写:
for(int i = 0;i<array.lenth;i++){
String element = array[i];
//对element做的操作
}
现在我们的需求是:无论从哪里读取上来的数据,对element做的操作 这部分是一致的,不一致的是对容器对象的遍历方式
也就是说,我们需要一个方案,可以把对容器对象的遍历过程进行解耦
单独的遍历流程
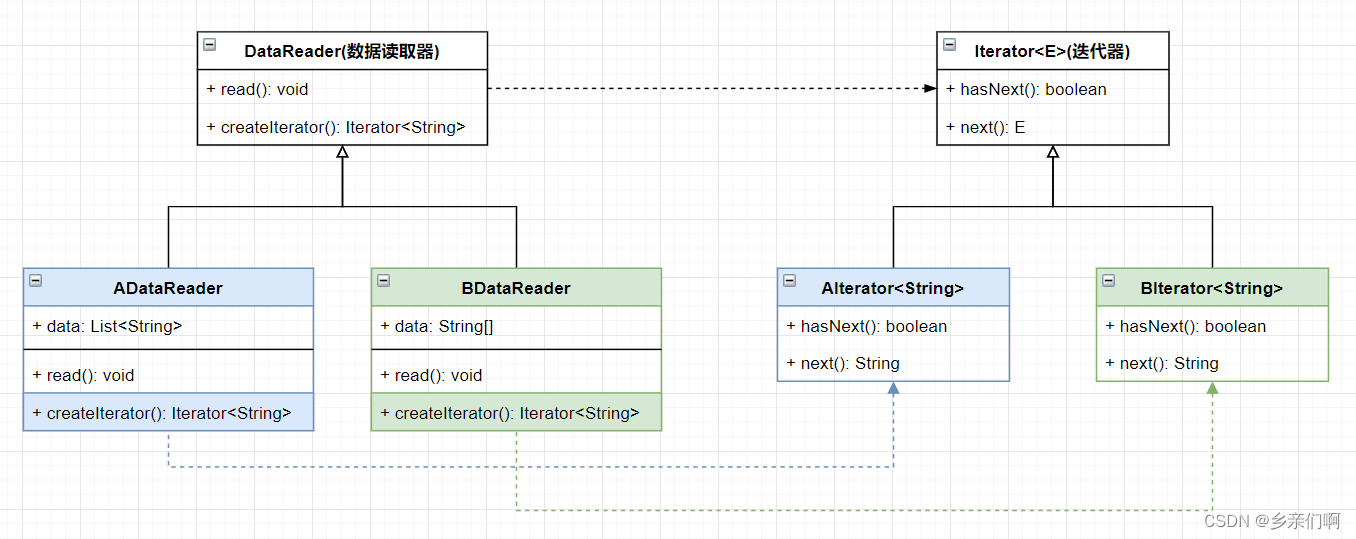
迭代器模式 这时候是你的最优选,具体的做法是这样的:
实现
/**
* 数据读取器
*/
public interface DataReader {
/**
* 从考勤机上读取记录和各类信息
*/
void read();
/**
* 创建对应的迭代器
*/
Iterator<String> createIterator();
}
/**
* 迭代器
*/
public interface Iterator<E> {
/**
* 还有下一个吗?
*
* @return true:有
*/
boolean hasNext();
/**
* 下一条记录
*/
E next();
}
/**
* A类型的数据读取器
*/
public class ADataReader implements DataReader {
//从考勤机里读取上来的记录
private List<String> data;
@Override
public void read() {
System.out.println("A类型考勤机正在从考勤机里读取数据。。。");
data = new ArrayList<>();
for (int i = 0; i < 5; i++) {
data.add(i + "");
}
System.out.println("A类型考勤机读取完毕");
}
@Override
public Iterator<String> createIterator() {
if (data == null) {
throw new RuntimeException("还没有执行对考勤机的读取");
} else {
return new AIterator();
}
}
class AIterator implements Iterator<String> {
private int cursor = 0;
@Override
public boolean hasNext() {
return cursor < data.size();
}
@Override
public String next() {
return data.get(cursor++);
}
}
}
/**
* B类型的数据读取器
*/
public class BDataReader implements DataReader {
private String[] data;
@Override
public void read() {
System.out.println("B类型考勤机正在从考勤机里读取数据。。。");
data = new String[5];
for (int i = 0; i < 5; ) {
data[i] = (char) (++i + 96) + "";
}
System.out.println("B类型考勤机读取完毕");
}
@Override
public Iterator<String> createIterator() {
if (data == null) {
throw new RuntimeException("还没有执行对考勤机的读取");
} else {
return new BIterator();
}
}
class BIterator implements Iterator<String> {
private int cursor = 0;
@Override
public boolean hasNext() {
return cursor < data.length;
}
@Override
public String next() {
return data[cursor++];
}
}
}
使用迭代器模式后,我们把 read 方法的职能进一步细化了,这个方法从此只负责从硬件上读取对应的数据到内存中,并存储在对应的 DataReader 内的 data 属性中
接着我们通过定义 createIterator 方法,对不同 DataReader 中不同 data 类型的遍历过程进行了解耦。这些变化被封装到我们定义的 Iterator 迭代器类树中(为了方便迭代器对底层容器的访问,我们还把两个AB两个迭代器写成了ABDataReader的子类)
至此 client代码 在遍历从考勤机中读取到的数据时不再关心底层的数据到底是以何种结构聚合在一起,而我们的程序将来如果要面对新的容器类型时,也只是新增一个 Iterator 子类的工作量而已
而这正是一个标准的迭代器实现
碎碎念
如果读写同时进行会发生啥?
但上面的实现存在一个问题:如果 client代码 调用迭代器进行迭代到一半,我又调用了一次 read 刷新了被迭代的容器。这时候迭代器的状态就失效了,可能会出现迭代越界,又或者重复迭代/漏迭代的问题
这是很危险的,所以一个健壮的迭代器应该可以保证即便在迭代过程中对容器进行修改也不会出现这么危险的行为
如果你在Java或者C#中对被迭代的容器进行修改,那么当你调用下一个next方法时会得到一个异常。为了实现这样的效果,一种常用的手法就是在迭代器被创建出来的时候向被遍历的容器注册自身,而容器在修改自身的时候可以向迭代器发出通知,就像这样(以A为例):
/**
* A类型的数据读取器
*/
public class ADataReader implements DataReader {
//从考勤机里读取上来的记录
private List<String> data;
//进行注册的迭代器列表
private final Set<AIterator> iteratorSet = new HashSet<>();
@Override
public void read() {
//把所有当前注册的迭代器都置为无效
for (AIterator aIterator : iteratorSet) {
aIterator.isUsable = false;//无效化
}
iteratorSet.clear();//清空注册列表,以便资源回收
System.out.println("A类型考勤机正在从考勤机里读取数据。。。");
data = new ArrayList<>();
for (int i = 0; i < 5; i++) {
data.add(i + "");
}
System.out.println("A类型考勤机读取完毕");
}
@Override
public Iterator<String> createIterator() {
if (data == null) {
throw new RuntimeException("还没有执行对考勤机的读取");
} else {
AIterator iterator = new AIterator();
iteratorSet.add(iterator);//注册迭代器
return iterator;
}
}
class AIterator implements Iterator<String> {
private boolean isUsable = true;
private int cursor = 0;
@Override
public boolean hasNext() {
if (isUsable) {
return cursor < data.size();
} else {
throw new RuntimeException("此迭代器已失效");
}
}
@Override
public String next() {
if (isUsable) {
return data.get(cursor++);
} else {
throw new RuntimeException("此迭代器已失效");
}
}
}
}
在改良后的代码里,我们为 AIterator 引入了 isUsable(是否可用) 的概念。只有当这个值为true的时候,迭代器里的方法才能正常调用,否则会抛出一个异常
然后我们在 ADataReader 中新增了一个 iteratorSet 用于记录当前生效的这一批迭代器
接着,当我们每次调用 read 试图更新 data 的值的时候都会把 iteratorSet 里注册的所有迭代器的可用性变为false
这就实现了我们对迭代器的保护
外部迭代和内部迭代
在上例中,我们封装了不同类型的容器的遍历过程,以实现 client代码 可以随时随地用自己喜欢的方式遍历 DataReader 中的内容
事实上还有一种解决方案可以在不使用 Iterator 的情况下实现和上例同样的效果,而且可以不让 client代码 随意遍历 DataReader 里的内容,就像这样(以B为例):
/**
* 数据操作手柄
*/
public interface DataHandler<E> {
/**
* 具体的对数据的操作方法
*/
void handle(E e);
}
/**
* B类型的数据读取器
*/
public class BDataReader {
public void read(DataHandler<String> dataHandler) {
String[] data = new String[5];
for (int i = 0; i < data.length; ) {
data[i] = (char) (++i + 96) + "";
}
for (int i = 0; i < data.length; i++) {
dataHandler.handle(data[i]);
}
}
}
这段代码很简单,看出门道了吗?
对,他封装的区域正好跟上例是相反的
在上例中,我们封装了容器遍历的过程;而本例中,我们封装的是对每个具体元素要做的操作
我们定义了一个 DataHandler(数据手柄) 用于盛放我们要对每个具体元素要做的操作,然后把这个操作作为参数传递给 read 方法,我们把遍历的过程依然保留在 read 方法中,抽离出对每个元素具体的操作,这样也能实现我们的需求
这种写法在四人组的设计模式中把他称之为内部迭代器,因为迭代的过程依然被保留在容器的内部。但是事实上这种写法远不只是在迭代器中被使用,我们封装一段操作,然后把这段操作作为参数传给某个方法;然后当方法执行到符合某个条件时调用这段操作。
当你需要在很多操作的执行前和执行后执行一些固定的操作,而这些操作又不值当你用装饰者模式时,这种写法就是你的最优解。而且在JavaScript中,他还有个专有名词——回调函数
迭代器和其他模式
迭代器和组合
组合模式本身就是多个对象的聚合,所以应用组合模式的对象大多数都会使用迭代器模式
迭代器和状态
在我们改写A类型考勤读取器时,我们通过一个变量的不同状态来控制同一个迭代器的相同接口的行为,这本质上就是状态模式的一种应用
万分感谢您看完这篇文章,如果您喜欢这篇文章,欢迎点赞、收藏。还可以通过专栏,查看更多与【设计模式】有关的内容