[实例讲解]计算机处理任务的方法和原理
文章目录
- [实例讲解]计算机处理任务的方法和原理
- 情景一 所有的事情自己做
- 情景二 找人去帮忙处理打印
- 情景三 分别找人处理编码和打印
- 情景四 不特定指定人去帮忙
- 结束语
在学习和工作中,我们自己都需要做很多的事情,事情大多都是我们亲自一件一件去完成,每件事情都是自己动手,那在做事情的花费时间就是每件事情时间的总和。但我们都梦想着有一天能当上领导,当有任务的时候,我们可以交给下属去做,我们直接获取结果就好,不用关注做事情的过程,这样就可以提高我们处理事情的效率。那这种情景在计算机中是如何模拟呢?
这里我们就提出一个名词:线程
在计算机中定义线程是计算机执行任务的基本的单位,即我们的任务可以交给线程去执行。
在介绍线程之前,我们先介绍一下计算机中的任务执行:首先任务需放在内存,当得到调度的时候就需要分配CPU时间,有了CPU支持,任务才可以执行。常见的执行方式有两种:当我们采用一种串行的方式去执行任务,即CPU处理好当下的任务,才会去处理下一个任务,这样的执行时间就是每个任务时间的总和;当在性能要求较高的场景下,我们会采用一种并发的方式去执行任务,在每个线程执行任务时,会获得CPU时间片,在这一点时间内可以处理当前任务。在并发的方式中,每个任务都能通过一定的方式获取到一部份CPU时间。这样宏观下就可以看到多个任务在一起执行,而且并发也可以很好地利用CPU的性能。
串行:

并发:
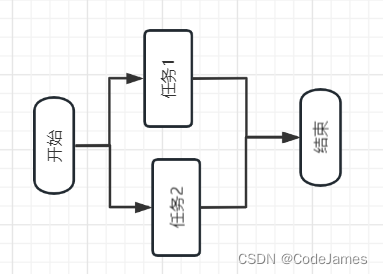
在讲解如何创建线程之前我们先建立两个方法:
方法1:模拟打印的方法
/**
* 打印方法
*/
public static void doPrint(){
try{
Thread.sleep(2000); // 模拟该方法处理时花费的时间
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("--- doPrint ---");
}
方法2:模拟我们敲代码的方法
/**
* 编写代码方法
*/
public static void doCode(){
try{
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("--- doCode ---");
}
情景一 所有的事情自己做
这种情景就是串行处理所有的事情,一件一件去处理,接下来以代码实现:
/**
* 串行调用
* @param args
*/
public static void main(String[] args) {
long start = System.currentTimeMillis();
doCode();
doPrint();
System.out.println(System.currentTimeMillis() - start);
}
如代码所示,我们首先记录开始时间,然后串行去处理方法2和方法1。
执行的结果:
--- doCode ---
--- doPrint ---
5005
如结果所示,串行执行方法的时间花费是两个方法的总和,这就相当于敲代码和打印这两件事自己来做,这种串行也是我们平时常见的编程方式,虽然很方便,但是并没有很好地利用计算机的性能,可能会导致无意义的等待。
情景二 找人去帮忙处理打印
在这个情景中,我们采用一个线程去处理打印方法,模拟我们把一些事情提前给到其他人处理,自己只需等待结果处理完即可。接下来看看代码实现:
public static void main(String[] args) throws InterruptedException {
long start = System.currentTimeMillis();
// 建立一个线程,找个人去打印
Thread threadA = new Thread(() -> {
try {
doPrint();
} catch (Exception e) {
throw new RuntimeException(e);
}
}, "threadA");
// 启动一个线程
threadA.start();
doCode();
// 阻塞等待线程结果
threadA.join();
// 打印花费的时间
System.out.println(System.currentTimeMillis() - start);
}
如上代码所示,使用Thread建立了一个线程threadA,让线程去处理打印方法,然后使用start()方法启动线程,最后使用join()等待线程threadA执行完毕。
接下来看看执行的结果:
--- doPrint ---
--- doCode ---
3032
如上结果所示,使用线程后,时间是doCode多一点点,这样使用线程后main线程就只需处理一个方法,执行效率得到了极大提升。
情景三 分别找人处理编码和打印
在这种场景下,我们可以使用两个线程分别去处理两件事情,在main方法中我们就只需花费时间去获取结果就好。
代码如下:
// 找到两个人进行处理
public static void main(String[] args) throws InterruptedException {
long start = System.currentTimeMillis();
Thread threadA = new Thread(() -> {
try {
doPrint();
} catch (Exception e) {
throw new RuntimeException(e);
}
}, "threadA");
Thread threadB = new Thread(() -> {
try {
doCode();
} catch (Exception e) {
throw new RuntimeException(e);
}
}, "threadB");
// 启动线程
threadA.start();
threadB.start();
// 阻塞当前线程,等待两个线程运行结束
threadA.join();
threadB.join();
System.out.println(System.currentTimeMillis() - start);
}
如上所示,采用了两个相处去处理编码和打印两个方法。
运行结果:
--- doPrint ---
--- doCode ---
3047
大家可能有疑惑怎么时间和情景二结果一致呢?这是因为在Main方法(线程)中我们需要等待两个线程的运行结果,在代码中我们使用到了join()方法,这个方法是一种同步阻塞的方法,即他会阻塞Main线程,等待threadA和threadB两个线程运行结束。又因为是用了两个线程,所以等待的时间就是较长方法的时间。
情景四 不特定指定人去帮忙
在上面的几个情景中,我们都显示去创建了每个线程;其实线程的创建和销毁在计算机中是比较的耗资源的,因此为了解决每次的线程创建和销毁,我们都会使用线程池来处理任务,即在线程中会一直存在一些已经创建的线程,每次有任务就直接分配CPU时间片唤醒线程就可以了。接下来我们就来使用线程池来处理我们的两个方法。
创建一个线程池
private final static int AVAILABLE_PROCESSORS = Runtime.getRuntime().availableProcessors();
private final static ThreadPoolExecutor POOL_EXECUTOR = new ThreadPoolExecutor(AVAILABLE_PROCESSORS, AVAILABLE_PROCESSORS * 2, 1, TimeUnit.MINUTES, new LinkedBlockingDeque<>(5), new ThreadPoolExecutor.CallerRunsPolicy());
如上我们就建立了一个线程池POOL_EXECUTOR啦,其中AVAILABLE_PROCESSORS是为了获取计算机的核心数量;然后使用了ThreadPoolExector显示创建了一个线程池POOL_EXECUTOR。
其中ThreadPoolExector中的参数分别为:
-
AVAILABLE_PROCESSORS:核心线程数量,在线程池中会一直存在的线程。 -
AVAILABLE_PROCESSORS * 2:最大的线程数量。 -
1, TimeUnit.MINUTES:空闲时间为1分钟,即当过多的线程执行完任务后,会等待1分钟,如果没有任务执行就会销毁掉多余的线程。 -
new LinkedBlockingDeque<>(5): 这个是一个任务队列,当创建的线程数量大于最大的线程数时,就会把多余的线程添加到任务队列中。 -
new ThreadPoolExecutor.CallerRunsPolicy():当任务队列都满了时,就会执行拒绝策略,将新加的任务给抛弃掉。
然后将编码和打印的任务都交给线程池来执行:
public static void main(String[] args) throws InterruptedException {
long start = System.currentTimeMillis();
POOL_EXECUTOR.execute(() -> {
try {
doPrint();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
POOL_EXECUTOR.execute(() -> {
try {
doCode();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
System.out.println(System.currentTimeMillis() - start);
// 挂起当前线程
Thread.currentThread().join();
}
运行结果:
63
--- doPrint ---
--- doCode ---
如结果所示,使用了线程池,执行了我们的方法,并且main方法等待的时间大大缩小了,但是他的执行顺序是排到第一的。这其实是因为我们没有阻塞去等待其他的方法,所有在main线程中,先打印了时间,这也是并发的原因,线程的执行顺序是不能保证的。
那如何阻塞线程池的任务?
//修改doPrint和doCode两个方法,添加返回值。
/**
* 打印方法
*/
public static String doPrint1(){
try{
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("--- doPrint ---");
return "Print Task Done";
}
/**
* 编写代码方法
*/
public static String doCode1(){
try{
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("--- doCode ---");
return "Code Task Done";
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
long start = System.currentTimeMillis();
Future<?> doPrint = POOL_EXECUTOR.submit(() -> {
try {
doPrint1();
} catch (Exception e) {
e.printStackTrace();
}
});
Future<?> doCode = POOL_EXECUTOR.submit(() -> {
try {
doCode1();
} catch (Exception e) {
e.printStackTrace();
}
});
// 阻塞线程
doPrint.get();
doCode.get();
System.out.println(System.currentTimeMillis() - start);
}
运行结果:
--- doPrint ---
--- doCode ---
3051
如上所述,当线程使用execute()方法时,是不需要阻塞去获取结果的,这种可以使用到日志打印。使用submit()就可以使用get()方法去阻塞获取结果。
结束语
在实际的开发中,使用线程去实现异步执行的地方很多,但我们都常用线程池来实现并发处理的,能提高效率,也提高可靠性。欢迎大家来公众号沟通,谢谢!