一、前言
在生产系统中,经常可能面临的一个状况就是,随着实际业务发生变更,现有的数据模型可能需要调整,而且到了必须调整不可的时候,那就只能硬着头皮做了;
数据模型的调整,说的大一点,可能是某一个业务模块整个设计需要推翻重来,或者涉及到其中局部关键模块的调整,比如数据表,数据库,或者大数据推荐模型的某个指标算法等;
现实中,诸如此类的场景不一而足,需要视情况而定,本篇分享一个小编在实际业务中碰到的一个场景,需要调整es索引的mapping结构,以及于此带来的数据迁移相关的问题。
二、问题来源
2.1 问题背景
生产系统中,某一块关于日志的业务数据采用es纯粹,其中某个字段采用了分词,以便于界面上多维度的关键字检索,其中涉及到的es索引中相关字段类比如下:
PUT /my_index1
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text",
"index": false
},
"address": {
"type": "text",
"index":true
}
}
}
}在该索引中,address为分词字段,存储进去的索引将会被分词处理,因此在执行搜索的时候如果使用matchQuery这样的API,将会走分词;
2.2 需求变更
现在客户的需求是,我需要针对 “address”这个字段进行精确的搜索,即输入什么搜索词,搜出来的文档就应该是精确包含这个词汇的文档;
让我们来捋捋这个需求吧,客户的需求也许就是简单一句话,但开发人员需要全面思考这个需求背后的逻辑,至少在我来看,这个需求将会带来下面这几点的关注:
- 现有的索引是否还能继续使用?
- 如果能继续使用现有的索引,是否只要调整下API层面的逻辑就能满足要求了?
- 现有的索引是否只需要调整下字段的属性为keyword就行了呢?
- 如果现有的索引不能使用了该怎么办?
关于这几个问题,通过实际操作以及相关的技术调研,这里做一下集中解答
1、只在现有的API层面上进行调整,比如将matchQuery()调整为termQuery(),经过测试,无法满足要求;
2、或者在API层面上,将matchQuery调整为es中的模糊查询,仍然无法满足要求;
API层面的调整无法满足要求的原因分析
- 之前的数据对于该字段来说已经被分词,那么在使用精确查询语法termQuery的时候,比如查询“我是中国人”的时候,查询的时候,es将无法从索引中按照 “我是中国人”这样的关键词从文档中进行匹配,而是被拆分成“我”,“我是”,“中国人”等,这样的关键词去做搜索,所以得到的结果无法满足要求;
- 如果使用模糊查询语法,比如wildcard,原理上将,这种模糊查询需要字段在创建的时候type设置为wildcard,如果是keyword类型,查询性能将会大大降低;
综上所述,单纯的从API层面进行调整,是无法满足需求的,这就意味着,不得不对当前的索引进行字段的类型上的调整,对es有一定了解的同学应该知道,es的索引一旦创建,将不能对索引中的字段进行任何类型上的变更,那么,到这里,问题的解决办法就比较明显了
1、创建新索引,索引中对该查询字段的类型设置为 “keyword”类型;
2、调整API层面的查询为termQuery() ——精确查询;
似乎到这里就完事了,其实事情远远不止这些;
2.3 新索引的问题
到上面这一步,如果后续的查询全部走新的索引,ok,那就没问题了,但作为一个生产系统,老数据尤其是这类比较重要的日志数据,那是一定要能够继续使用的,你用新的索引,新的API查询新的索引能够满足要求,老的索引中的数据怎么整?
这就是接下来要说的一个相对比较棘手的活儿,就涉及到es历史数据迁移的问题;
关于es数据迁移,网上可以找到很多种方式,有离线工具迁移的方案,也有一些中间件迁移的,甚至可以通过程序的方式做迁移,不过为了尽可能减少数据迁移带来的工作成本的开销,这里采用一种相对简单,并且操作性比较强的迁移方式,就是:_reindex + 修改alias的方式;
三、_reindex 数据迁移操作演示
为了验证上述所说的方案实际操作上的可行性,我们通过下面的实操做一下验证;
3.1 为 my_index1 添加几条数据
PUT my_index1/_doc/1001
{
"id":1001,
"name":"jerry",
"address":"杭州市西湖区"
}
PUT my_index1/_doc/1002
{
"id":1002,
"name":"lihua",
"address":"杭州市下城区"
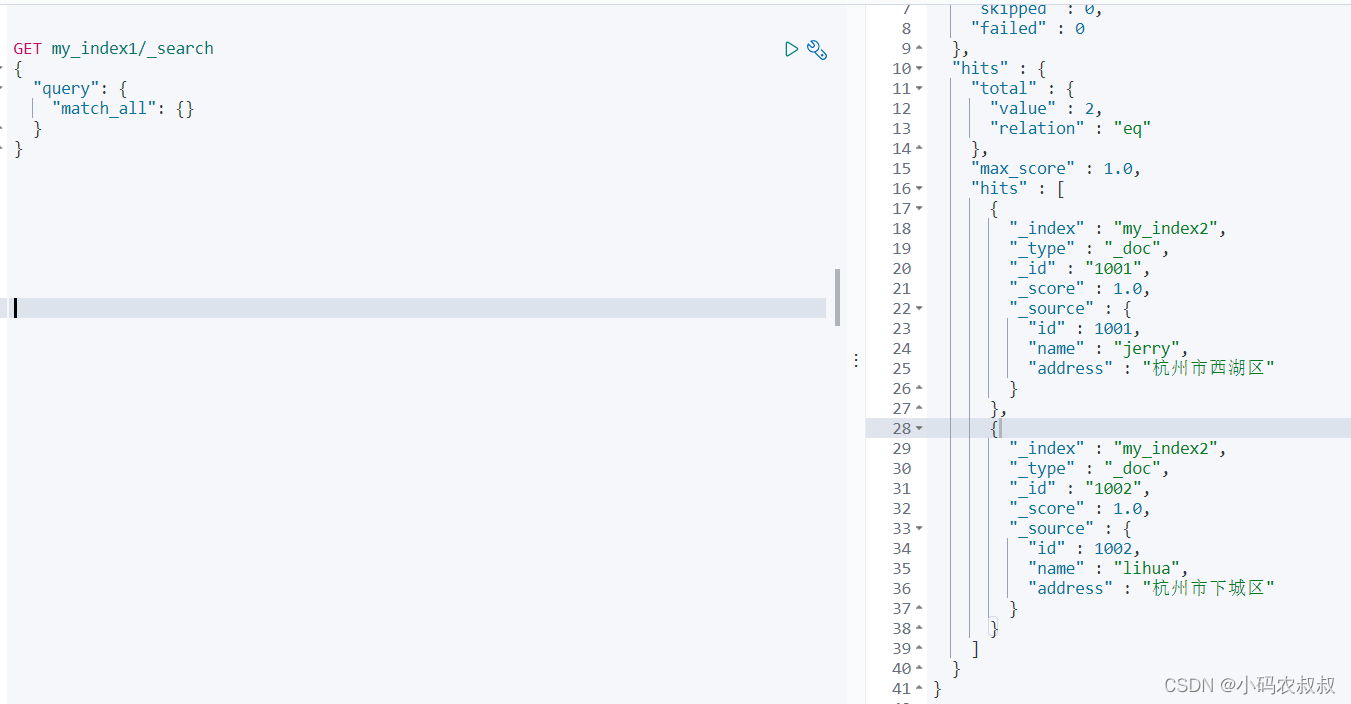
}查询一下刚刚添加进去的数据
GET my_index1/_search
{
"query": {
"match_all": {}
}
}

3.2 创建新的索引 my_index2
将address字段设置为keyword类型,完整的mapping如下:
PUT /my_index2
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text",
"index": false
},
"address": {
"type": "keyword"
}
}
}
}
此时查询当前my_index2为空

3.3 使用 _reindex 进行索引数据迁移
语法如下
POST _reindex
{
"source": {
"index": "my_index1" #源数据对应的索引名称
},
"dest": {
"index": "my_index2" #目标索引的名称
}
}
执行完毕后,再次查询my_index,数据已经迁移过来了;

_reindex 在使用中还有一些细节上的问题,比如要迁移的索引数据量非常大的时候,可以设置相关的参数(如批次数量)达到提升迁移的效率,网上相关的资料比较多;
3.4 给新索引设置 _alias(别名)
事实上,当数据迁移完成之后,后续程序上的查询将不再走之前的索引,也就是说my_index1这个索引就没有存在的必要了,需要删掉,删掉之后,为了为了尽可能减少代码上的调整,因为代码上查询的索引名还是my_index1,为了兼容之前的使用,往往需要设置一下_aliases ,通俗来说,就是别名,就是给my_index2设置一个别名,这样设置之后,不管是查询my_index2,还是my_index1,都可以查到数据;
DELETE my_index1
POST _aliases
{
"actions": [
{
"add": {
"index": "my_index2",
"alias": "my_index1"
}
}
]
}此时的效果就是,不管是查询my_index2,或者查询my_index1,都可以查到数据了;
四、es 索引数据迁移程序设计与实现
通过第三步,我们从理论上验证了使用reindex这种方式对于索引数据迁移的可行性,但这个距离实施还有一定的距离,因为在具体操作的时候还面临着下面的一些现实问题:
- 生产环境的索引不止一个,索引为一周一个,格式类似着这样: biz_log_20200101,biz_log_20220108 ...... 这意味着生产环境下的索引非常多,保守估计在300个以上,手工操作不现实;
- 生产环境未安装es的可视化操作工具,而且也不允许安装;
经过一定的评估,结合实施的可行性,决定通过程序的方式来完成这个数据迁移过程;
4.1 迁移实现思路
下面这幅图可以表达整个迁移的实现逻辑,程序层面的实现将会按照图中的步骤来实施;

4.2 前置准备
提前准备三个索引,为后面程序中的实现做数据上的准备
PUT /biz_log_20221101
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"detail": {
"type": "text",
"index": true
}
}
}
}
PUT /biz_log_20221102
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"detail": {
"type": "text",
"index": true
}
}
}
}
PUT /biz_log_20221103
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"detail": {
"type": "text",
"index": true
}
}
}
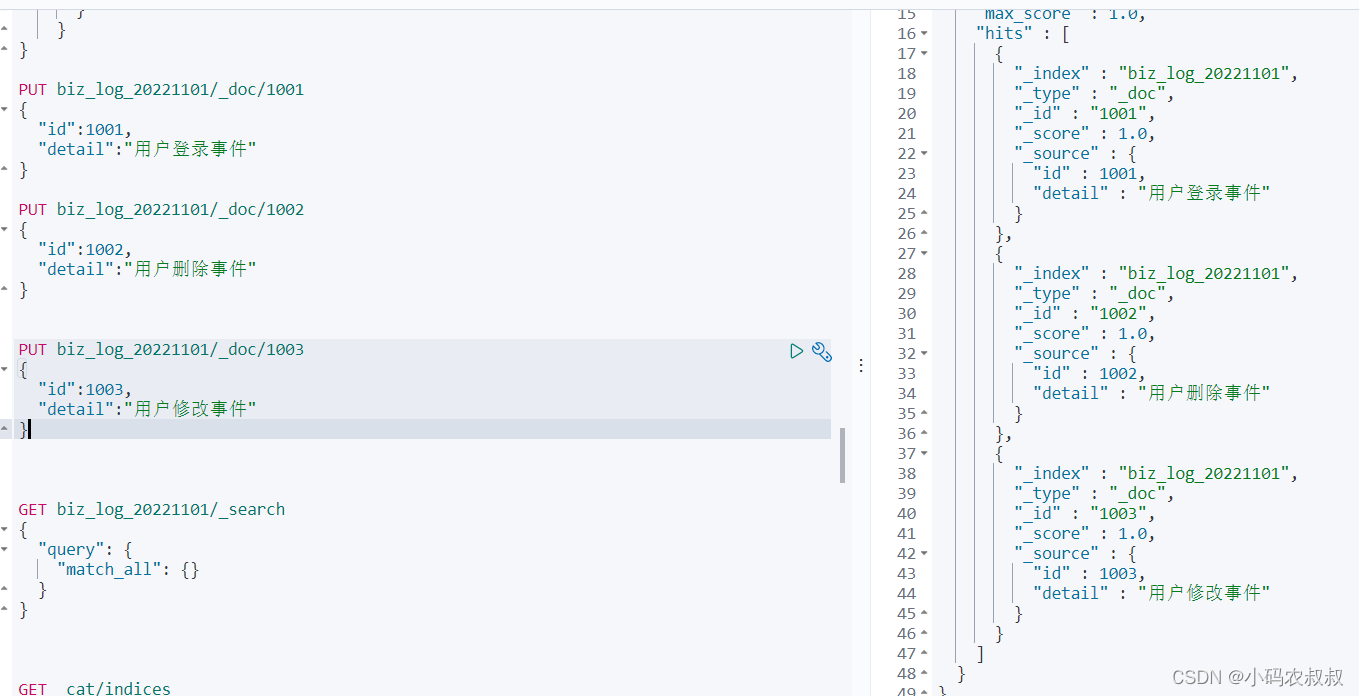
}给每个索引添加3条数据
PUT biz_log_20221101/_doc/1001
{
"id":1001,
"detail":"用户登录事件"
}
PUT biz_log_20221101/_doc/1002
{
"id":1002,
"detail":"用户删除事件"
}
PUT biz_log_20221101/_doc/1003
{
"id":1003,
"detail":"用户修改事件"
}
GET biz_log_20221101/_search
{
"query": {
"match_all": {}
}
}
其他的两个索引也做如此的操作;
4.3 代码实现
1)pom中 添加如下核心依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.6.RELEASE</version>
<relativePath/>
</parent>
<dependencies>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.11.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-jcl</artifactId>
<version>2.11.2</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
<!--<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.9</version>
</dependency>-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
</dependency>
</dependencies>2)迁移核心实现代码
import com.congge.entity.BizLog;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.alias.Alias;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.util.CollectionUtils;
import java.util.*;
public class EsCreateTemplateUtils {
public static RestHighLevelClient esClient;
static {
esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("你的Es连接IP", 9200, "http"))
);
}
private static ObjectMapper objectMapper = new ObjectMapper();
public static void main(String[] args) throws Exception {
List<String> allIndexs = getAllIndexs();
List<String> newIndexs = new ArrayList<>();
List<String> aliasIndexs = new ArrayList<>();
for (String index : allIndexs) {
if (index.startsWith("biz_log")) {
aliasIndexs.add(index);
String newIndex = index + "_ali";
newIndexs.add(newIndex);
//从当前索引查询出数据来
List<BizLog> logs = searchIndexAll(index);
//删除旧的索引
deleteIndex(index);
createTemplateIfNeed(newIndex,index);
//执行数据迁移
if(!CollectionUtils.isEmpty(logs)){
for(BizLog bizLog : logs){
addData(newIndex,bizLog);
}
}
}
}
System.out.println("所有的索引名称 +++++++++++");
List<String> allIndexs1 = getAllIndexs();
allIndexs1.forEach(item ->{
System.out.println(item);
});
System.out.println("所有的索引名称 +++++++++++");
//从新的索引查询数据
System.out.println("从新索引查询数据 -------------");
for (String index : newIndexs) {
//执行数据迁移
List<BizLog> logs = searchIndexAll(index);
logs.forEach(item ->{
System.out.println("新索引的数据 : detail :" + item.getDetail());
});
}
System.out.println("从新索引查询数据 -------------");
//从alias索引中查询数据
System.out.println("从alias索引查询数据 -------------");
for (String index : aliasIndexs) {
//执行数据迁移
List<BizLog> logs = searchIndexAll(index);
logs.forEach(item ->{
System.out.println("alias索引的数据 : detail :" + item.getDetail());
});
}
System.out.println("从alias索引查询数据 -------------");
esClient.close();
}
public static void deleteIndex(String indexName) throws Exception {
DeleteIndexRequest getIndexRequest = new DeleteIndexRequest(indexName);
esClient.indices().delete(getIndexRequest, RequestOptions.DEFAULT);
System.out.println("索引删除成功:"+indexName);
}
/**
* 写入数据
* @throws Exception
*/
public static void addData(String indexName, BizLog logBean) throws Exception{
IndexRequest indexRequest = new IndexRequest();
indexRequest.index(indexName);
String userData = objectMapper.writeValueAsString(logBean);
indexRequest.source(userData,XContentType.JSON);
//插入数据
IndexResponse response = esClient.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(response.status());
System.out.println(response.getResult());
}
/**
* 查询数据
* @param indexName
* @return
* @throws Exception
*/
public static List<BizLog> searchIndexAll(String indexName) throws Exception{
SearchRequest request = new SearchRequest();
request.indices(indexName);
// 索引中的全部数据查询
SearchSourceBuilder query = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
request.source(query);
SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
List<BizLog> logs = new ArrayList<>();
for (SearchHit searchHit : hits){
BizLog bizLog = new BizLog();
System.out.println(searchHit.getSourceAsString());
Map<String, Object> sourceAsMap = searchHit.getSourceAsMap();
bizLog.setId(Integer.valueOf(sourceAsMap.get("id").toString()));
bizLog.setDetail(sourceAsMap.get("detail").toString());
logs.add(bizLog);
}
return logs;
}
/**
* 获取索引名称
*
* @return
*/
public static List<String> getAllIndexs() {
GetIndexRequest getIndexRequest = new GetIndexRequest("*");
try {
GetIndexResponse getIndexResponse = esClient.indices().get(getIndexRequest, RequestOptions.DEFAULT);
return Arrays.asList(getIndexResponse.getIndices());
} catch (Exception e) {
System.out.println(e);
}
return new ArrayList<>();
}
public static void createTemplateIfNeed(String indexName,String aliasName) throws Exception{
// 创建索引
org.elasticsearch.client.indices.CreateIndexRequest request = new org.elasticsearch.client.indices.CreateIndexRequest(indexName);
Map<String, Object> properties = new HashMap<>();
Map<String, Object> detailMap = new HashMap<>();
detailMap.put("type", "keyword");
properties.put("detail", detailMap);
Map<String, Object> idType = new HashMap<>();
idType.put("type", "integer");
idType.put("store", true);
properties.put("id", idType);
Map<String, Object> mappings = new HashMap<>();
mappings.put("properties", properties);
//创建别名映射
request.alias(new Alias(aliasName));
request.mapping(mappings);
org.elasticsearch.client.indices.CreateIndexResponse response = esClient.indices()
.create(request, RequestOptions.DEFAULT);
System.out.println(response);
}
}涉及到的实体类
@Data
public class BizLog {
private Integer id;
private String detail;
}按照上面所有的步骤操作之后,本段代码可以直接运行,并跑成功,但这段代码如果要是直接拿过去使用最好再做一些工具类上面的封装,但是总体的业务逻辑执行顺序基本上是按照上面的业务图走的;
运行之后,控制台也可以看到我们预期输出的结果;


这时,我们再通过kibana去查询一下所有索引,留下的就是我们新创建的索引,之前的索引被删掉了;

如果任意查询某个新的索引,可以看到数据已经成功同步进去了;

如果我们查询alias的名称,也是可以查到数据的;

3) 使用_reindex API实现
细心的同学可能会发现,在上面的数据迁移实现中,好像并没有用到reindex的API实现,数据如果这样去迁移的话,量小的话还没什么,量大的话就有点不太好了,下面我们使用reindex的方式调整一下逻辑吧;
数据恢复
首先将数据恢复成调整之前的状态

完整的代码调整成下面这样,主要是增加了关于reindex的操作API方法
import com.congge.entity.BizLog;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.extern.slf4j.Slf4j;
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.alias.IndicesAliasesRequest;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkItemResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.reindex.BulkByScrollResponse;
import org.elasticsearch.index.reindex.ReindexRequest;
import org.elasticsearch.index.reindex.ScrollableHitSource;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.util.CollectionUtils;
import java.io.IOException;
import java.util.*;
@Slf4j
public class ReindexTest {
public static RestHighLevelClient esClient;
static {
esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("你的Es地址", 9200, "http"))
);
}
private static ObjectMapper objectMapper = new ObjectMapper();
public static void main(String[] args) throws Exception {
List<String> allIndexs = getAllIndexs();
List<String> newIndexs = new ArrayList<>();
List<String> aliasIndexs = new ArrayList<>();
for (String index : allIndexs) {
if (index.startsWith("biz_log")) {
aliasIndexs.add(index);
String newIndex = index + "_ali";
newIndexs.add(newIndex);
//从当前索引查询出数据来
List<BizLog> logs = searchIndexAll(index);
createTemplateIfNeed(newIndex);
if(!CollectionUtils.isEmpty(logs)){
//执行数据迁移
reindex(index,newIndex);
//删除老索引
//deleteIndex(index);
//设置新索引的别名为老索引
//setIndexAlias(newIndex,index);
}
}
}
//删除老索引
for(String index : aliasIndexs){
deleteIndex(index);
}
//统一设置别名
for(int i=0;i<newIndexs.size();i++){
setIndexAlias(newIndexs.get(i),aliasIndexs.get(i));
}
System.out.println("所有的索引名称 +++++++++++");
List<String> allIndexs1 = getAllIndexs();
allIndexs1.forEach(item ->{
System.out.println(item);
});
System.out.println("所有的索引名称 +++++++++++");
//从新的索引查询数据
System.out.println("从新索引查询数据 -------------");
for (String index : newIndexs) {
//执行数据迁移
List<BizLog> logs = searchIndexAll(index);
logs.forEach(item ->{
System.out.println("新索引的数据 : detail :" + item.getDetail());
});
}
System.out.println("从新索引查询数据 -------------");
//从alias索引中查询数据
System.out.println("从alias索引查询数据 -------------");
for (String index : aliasIndexs) {
//执行数据迁移
List<BizLog> logs = searchIndexAll(index);
logs.forEach(item ->{
System.out.println("alias索引的数据 : detail :" + item.getDetail());
});
}
System.out.println("从alias索引查询数据 -------------");
esClient.close();
}
/**
* index设置别名
* @param index
* @param alias
* @throws Exception
*/
public static void setIndexAlias(String index,String alias) throws Exception{
IndicesAliasesRequest indicesAliasesRequest = new IndicesAliasesRequest();
IndicesAliasesRequest.AliasActions aliasAction = new IndicesAliasesRequest.AliasActions(IndicesAliasesRequest.AliasActions.Type.ADD);
aliasAction.index(index).alias(alias);
indicesAliasesRequest.addAliasAction(aliasAction);
esClient.indices().updateAliases(indicesAliasesRequest, RequestOptions.DEFAULT);
}
public static void deleteIndex(String indexName) throws Exception {
DeleteIndexRequest getIndexRequest = new DeleteIndexRequest(indexName);
esClient.indices().delete(getIndexRequest, RequestOptions.DEFAULT);
System.out.println("索引删除成功:"+indexName);
}
/**
* 查询数据
* @param indexName
* @return
* @throws Exception
*/
public static List<BizLog> searchIndexAll(String indexName) throws Exception{
SearchRequest request = new SearchRequest();
request.indices(indexName);
// 索引中的全部数据查询
SearchSourceBuilder query = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
request.source(query);
SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
List<BizLog> logs = new ArrayList<>();
for (SearchHit searchHit : hits){
BizLog bizLog = new BizLog();
System.out.println(searchHit.getSourceAsString());
Map<String, Object> sourceAsMap = searchHit.getSourceAsMap();
bizLog.setId(Integer.valueOf(sourceAsMap.get("id").toString()));
bizLog.setDetail(sourceAsMap.get("detail").toString());
logs.add(bizLog);
}
return logs;
}
/**
* 获取索引名称
*
* @return
*/
public static List<String> getAllIndexs() {
GetIndexRequest getIndexRequest = new GetIndexRequest("*");
try {
GetIndexResponse getIndexResponse = esClient.indices().get(getIndexRequest, RequestOptions.DEFAULT);
return Arrays.asList(getIndexResponse.getIndices());
} catch (Exception e) {
System.out.println(e);
}
return new ArrayList<>();
}
public static void createTemplateIfNeed(String indexName) throws Exception{
// 创建索引
org.elasticsearch.client.indices.CreateIndexRequest request = new org.elasticsearch.client.indices.CreateIndexRequest(indexName);
Map<String, Object> properties = new HashMap<>();
Map<String, Object> detailMap = new HashMap<>();
detailMap.put("type", "keyword");
properties.put("detail", detailMap);
Map<String, Object> idType = new HashMap<>();
idType.put("type", "integer");
idType.put("store", true);
properties.put("id", idType);
Map<String, Object> mappings = new HashMap<>();
mappings.put("properties", properties);
//创建别名映射
//request.alias(new Alias(aliasName));
request.mapping(mappings);
org.elasticsearch.client.indices.CreateIndexResponse response = esClient.indices()
.create(request, RequestOptions.DEFAULT);
System.out.println(response);
}
/**
* reindex 索引数据
* @param sourceIndex
* @param newIndex
* @throws Exception
*/
public static void reindex(String sourceIndex,String newIndex) throws Exception{
ReindexRequest request = buildReindexRequest(sourceIndex,newIndex);
// 2 执行
try {
BulkByScrollResponse response = esClient.reindex(request, RequestOptions.DEFAULT);
// 3 解析
// 获取总耗时
TimeValue took = response.getTook();
log.info("总耗时: {}", took.getMillis());
// 请求是否超时
boolean timedOut = response.isTimedOut();
log.info("请求是否超时: {}", timedOut);
// 获取已经处理的文档数量
long total = response.getTotal();
log.info("处理的文档数量: {}", total);
// 获取更新的文档数量
long updated = response.getUpdated();
log.info("更新的文档数量: {}", updated);
// 获取创建的文档数量
long created = response.getCreated();
log.info("创建的文档数量: {}", created);
// 获取删除的文档数量
long deleted = response.getDeleted();
log.info("删除的文档数量: {}", deleted);
// 获取执行的批次
int batches = response.getBatches();
log.info("执行的批次数量: {}", batches);
// 获取跳过的文档数量
long noops = response.getNoops();
log.info("跳过的文档数量: {}", noops);
// 获取版本冲突数量
long versionConflicts = response.getVersionConflicts();
log.info("版本冲突数量: {}", versionConflicts);
// 重试批量索引的次数
long bulkRetries = response.getBulkRetries();
log.info("重试批量索引的次数: {}", bulkRetries);
// 重试搜索操作的次数
long searchRetries = response.getSearchRetries();
log.info("重试搜索操作的次数: {}", searchRetries);
// 请求阻塞的总时间,不包括当前处于休眠状态的限制时间
TimeValue throttled = response.getStatus().getThrottled();
log.info("请求阻塞的总时间,不包括当前处于休眠状态的限制时间: {}", throttled.getMillis());
// 获取查询失败
List<ScrollableHitSource.SearchFailure> searchFailures = response.getSearchFailures();
log.info("查询失败的数量: {}", searchFailures != null ? searchFailures.size() : 0);
// 获取批量操作失败
List<BulkItemResponse.Failure> bulkFailures = response.getBulkFailures();
log.info("批量操作失败的数量: {}", bulkFailures != null ? bulkFailures.size() : 0);
} catch (IOException e) {
e.printStackTrace();
}
}
public static ReindexRequest buildReindexRequest(String sourceIndex,String newIndex) {
// 1 构建ReIndexRequest
ReindexRequest request = new ReindexRequest();
// 1.1 设置源索引,接收的是一个可变参数,可设置多个索引
request.setSourceIndices(sourceIndex);
// 1.2 设置目标索引: 注意先去将该索引的映射,分片等信息设置好
request.setDestIndex(newIndex);
// 1.3 其他可选参数
// 设置目标索引的版本类型
// request.setDestVersionType(VersionType.EXTERNAL);
// 设置目标索引的操作类型
// request.setDestOpType("create");
// 默认情况下,版本冲突会中止重新索引进程
// request.setConflicts("proceed");
// 通过添加查询限制文档,比如这里就是只对language字段词条是包括java的进行操作
// 简单了来说就是进行文档的过滤
//request.setSourceQuery(new TermQueryBuilder("language", "java"));
// 默认情况下是1000
// request.setSourceBatchSize(100);
// 设置超时时间
request.setTimeout(TimeValue.timeValueMinutes(10));
// reIndex之后刷新索引
request.setRefresh(true);
return request;
}
}
使用reindex的时候,注意要重新调整下循环体内部的逻辑执行顺序,然后可以直接运行上面的代码即可完成数据的迁移;

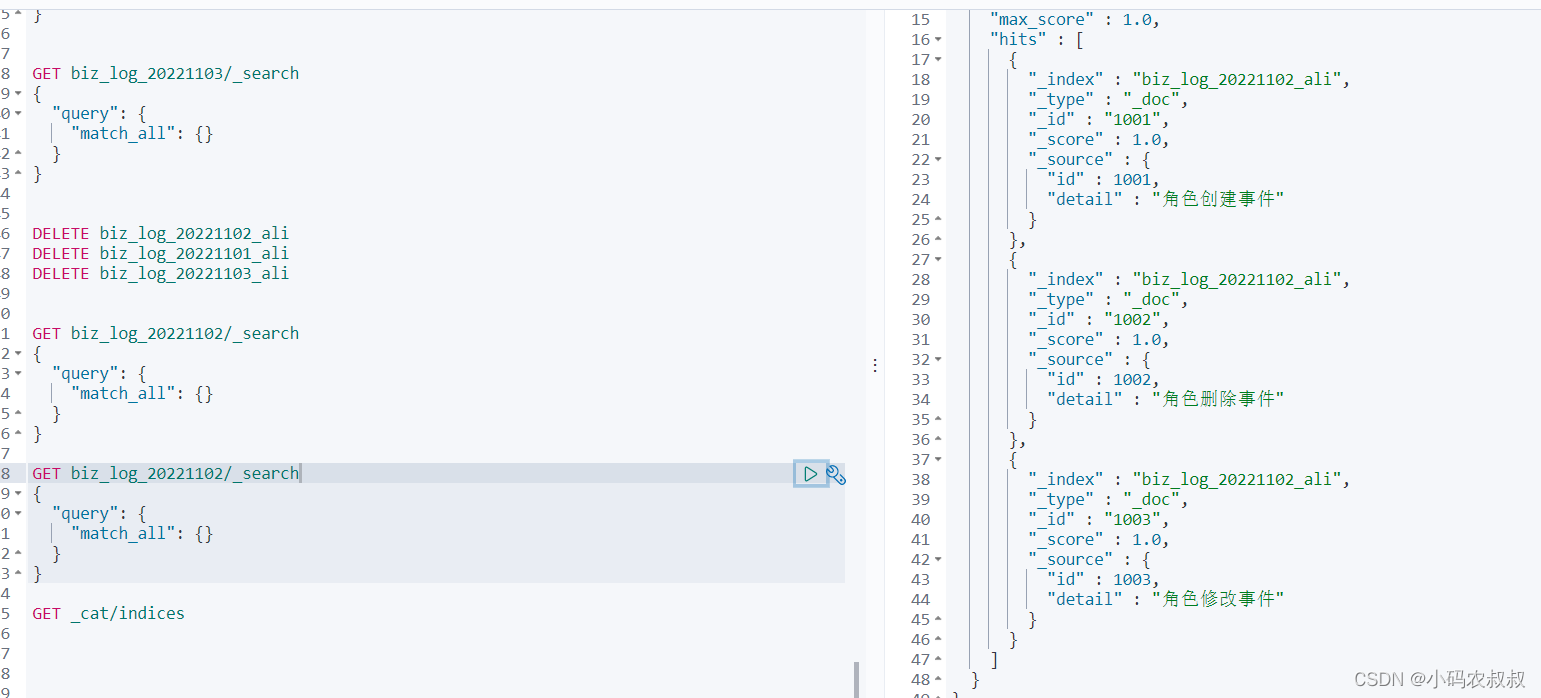
最后随机找一个索引查询下

或者查询索引的别名,可以看到也能查询出数据来;
友情提示
- 如果对应的索引数据量太大该怎么办?程序中执行很可能会造成OOM?甚至迁移过程中对其他应用造成影响怎么办?
- 如果现实条件允许的情况下,可以考虑在机器上安装相关的数据迁移工具实现;
总结
本篇使用较大的篇幅论述了如何基于已经在运行中的es索引,结合实际业务进行数据迁移的完整过程,从理论到实际操作落地,当然还有些细节的地方有待完善,有兴趣的同学可以继续深入研究。