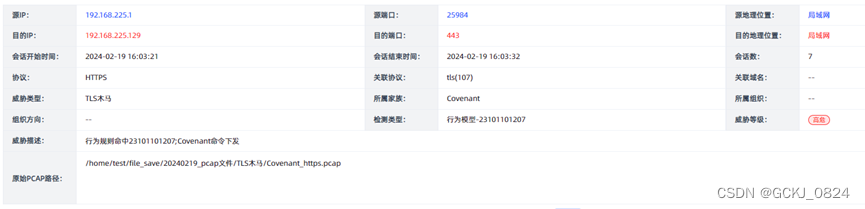
本文是性能问题分析排查思路的展开内容之一,主要分为日志1期,机器4期、环境2期共7篇系列文章,本期是第一篇,讲日志的分析方法和经验。
系列文章传送门:
一图梳理性能问题分析排查思路-总体概述(0)

一般分析步骤
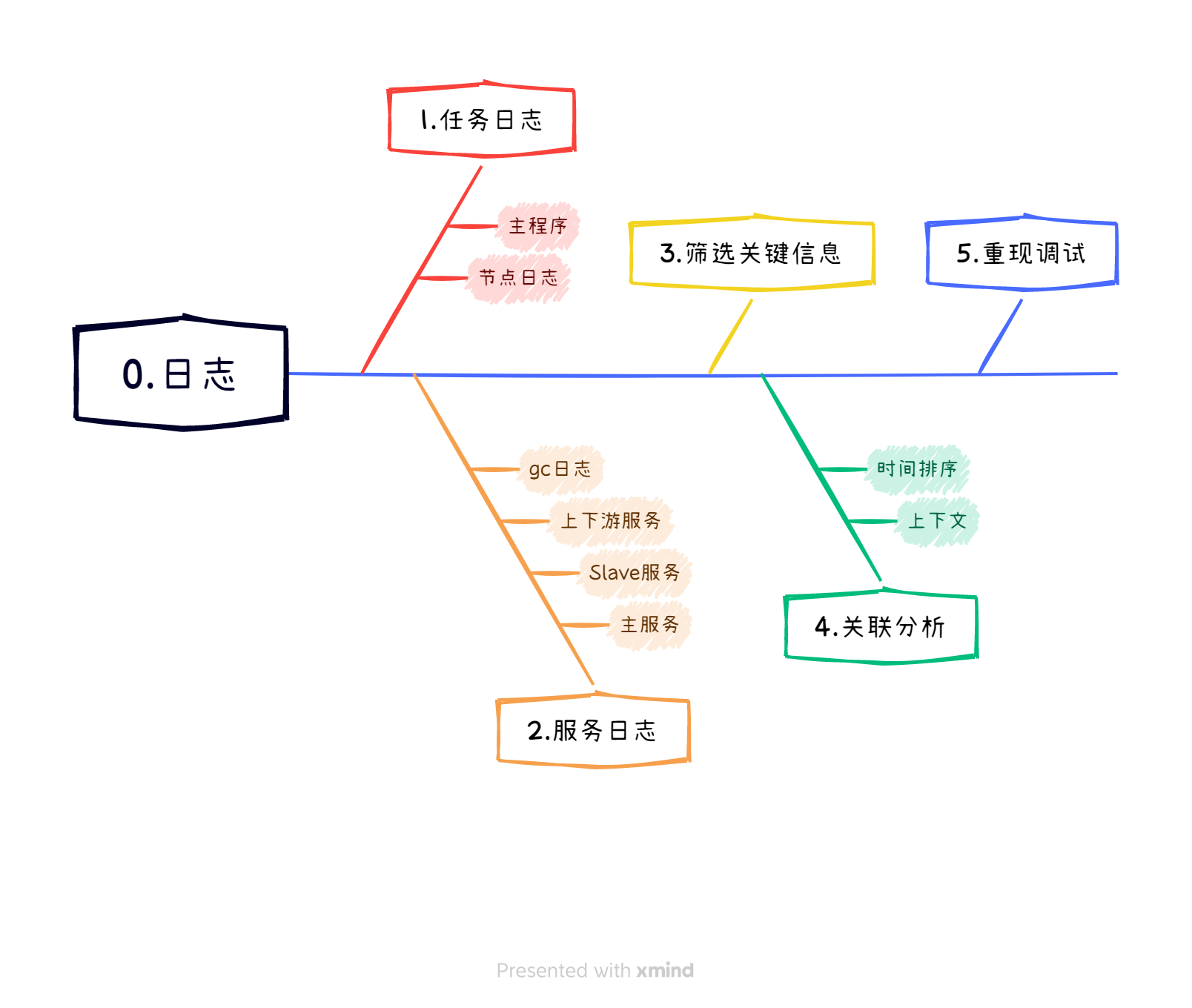
大数据领域,日志的范畴很广泛,主要思路如下:
-
收集相关日志:
- 任务日志:对于运行在YARN等分布式计算框架上的任务,首先要获取任务执行过程中的标准输出(stdout)和标准错误(stderr)日志,这些日志可能包含了任务启动、运行、失败的具体信息,包括错误栈、资源分配状况、任务进度等。
关键在于找到第一现场,最后的错误往往是由更早的错误引发的!
- 服务日志:针对具体的大数据服务组件,如HDFS NameNode、DataNode、YARN ResourceManager、NodeManager、Kafka Broker、HBase RegionServer等,收集其运行时的日志文件,这些日志记录了服务内部状态变化、请求处理情况、异常事件等重要信息。
错误不一定发生在每一个节点上,如不能定位到节点,分布式的服务需要关注每一个节点的信息。
- 上下游服务日志:如果问题涉及到多个服务之间的交互,例如数据流经Elasticsearch、Flink、Kafka等中间件,也需要查看这些上游和下游服务的相关日志,以便确定数据传输是否正常、是否存在接口调用失败或超时等问题。
这招很管用!
-
筛选关键信息:
- 使用grep、awk等命令行工具或日志管理平台进行关键词过滤和搜索,快速定位到包含错误信息或异常堆栈的部分。
- 查看日志中与时间戳相关的条目,找到问题发生的时间窗口内的日志记录(以便回溯对应时间段的硬件资源状态)。
-
关联分析:
- 将不同来源的日志按时间顺序排列,观察同一时间段内各服务的状态和交互情况。
- 分析错误前后的上下文信息,寻找可能导致问题的触发因素,如资源耗尽、并发冲突、配置错误等。
-
深度解析:
- 对于复杂的系统错误或性能瓶颈,可能需要深入理解日志中所反映出的系统内部机制,比如内存溢出、磁盘空间不足、网络延迟高等问题(这在机器相关章节展开)。
- 如果是代码级别的错误,通过错误栈跟踪查找引发问题的具体代码行,结合源码进一步分析(在环境章节展开讲)。
-
重现与调试:
- 在条件允许的情况下,尝试复现问题并开启额外的日志级别(debug或trace级别),以获取更详细的运行时信息。
- 如果有必要,可以通过远程调试或者增加临时日志输出来追踪特定变量的变化或流程控制路径。
不能重现的问题往往是没有找到根因!
常见的错误类型
HDFS与YARN类
| 组件 | 错误关键词 | 解释说明 |
|---|---|---|
| Hadoop | namenode.SafeModeException | 安全模式下无法操作 |
| Hadoop | ConnectException: Call From datanode-host | DataNode连接失败 |
| YARN | ConnectException:Failed to connect to server | ResourceManager无法启动或连接失败 |
| YARN | Failed to launch container … ExitCode xx is -104 | 容器初始化失败 |
| YARN | FileAlreadyExistsException | 输出目录已存在等 |
| Hadoop | RemoteException: StandbyException … | HA模式下Active NameNode变更 |
| Hadoop | UnknownHostException: namenode-host | NameNode服务未响应或不可达 |
| Hadoop | sasl.SaslException: GSS initiate failed | Kerberos认证失败 |
| YARN | OutOfMemoryError: Java heap space | Map或Reduce任务内存溢出 |
| Hadoop | IOException: Failed to handshake with NN | DataNode与NameNode之间通信失败 |
Hive和HBase类
| 组件 | 错误关键词 | 解释说明 |
|---|---|---|
| Hive | FAILED: MetaException(message:Got | 元数据比如表或分区创建、删除、更新等操作失败 |
| Hive | FAILED: ParseException line x:xx | SQL语句解析错误,如语法不符合规范 |
| Hive | SemanticException [Error 10001]: Line xx | SQL语句虽符合语法,但在执行计划生成阶段出现语义错误 |
| Hive | HiveExecutionException Error while processing | 在查询执行过程中发生的异常 |
| Hive | .FileNotFoundException: File does not exist | 与HDFS相关的读写错误,如文件不存在、权限不足 |
| Hive | DAG submission failed due to | Tez作为执行引擎时,由于资源不足等导致失败 |
| Hive | hive.serde2.SerDeException: | 在序列化或反序列化数据时遇到的问题 |
| HBase | ZooKeeperConnectionException: HBase is unable to connect | ZK连接异常 |
| HBase | IllegalArgumentException: KeyValue size too large | RowKey过大错误 |
| HBase | Lease expired on client… for table … | RegionServer租约过期错误 |
Spark类
| 组件 | 错误关键词 | 解释 |
|---|---|---|
| Spark | OutOfMemoryError: Java heap space | 内存溢出 |
| Spark | NoClassDefFoundError, ClassNotFoundException | 依赖库缺失或版本冲突 |
| Spark | SocketTimeoutException: Read timed out | 网络通信错误 |
| Spark | FetchFailedException: Connection from | Spark Shuffle错误 |
| Spark | sql.AnalysisException:Table or view not found | 表或视图不存在,或者SQL语句语法有误 |
| Spark | YarnAllocationException | 向YARN资源管理器申请资源失败 |
日志处理的常用命令
基础类:cat + grep关键字,less、more、tail
统计类:wc统计行数、字符数
管道类:awk配合grep
tail -n 1000 /var/log/hadoop/xxxx.log | grep "Error" | awk '{print $1, $4}' > errors.txt
工具类:split将很大的日志文件切分成小文件,zip或tar压缩!