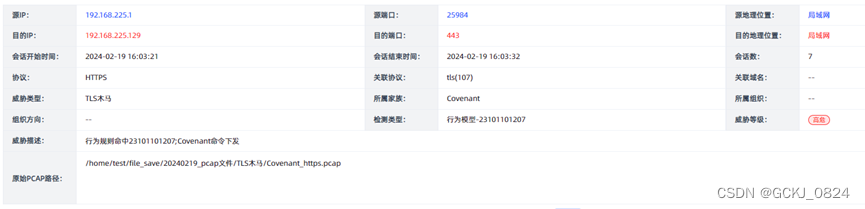
项目地址:https://localrf.github.io/
题目:Progressively Optimized Local Radiance Fields for Robust View Synthesis
来源:KAIST、National Taiwan University、Meta 、University of Maryland, College Park
提示:文章用了slam的思想,边运动边重建,并将场景划分为 若干个小的TensorRT块。每个块单独优化辐射场和像机pose

文章目录
- 摘要
- 一、引言
- 二、相关工作
- 2.1 新视图合成
- 2.2 可扩展的视图合成
- 2.3 相机姿态估计
- 三、方法
- 3.1 公式和准备知识
- 3.2 渐进的摄像机pose和辐射场的联合优化
- 3.3 局部辐射场
- 3.4 实施
- 3.4.1 Loss
- 3.4.2 优化配置
- 四、实验
- 4.1.数据集
- 4.2.对比方法
- 4.3 定量分析
- 4.4 定性评价
- 4.5 局限性
- 总结
- 在这里插入图片描述
摘要
LocalRF:从一个随意捕获的视频,重建一个大规模的场景。该任务的两个核心挑战。 首先,大多数现有的辐射场重建方法依赖于SFM预估计的像机pose ,这些算法经常在野外视频中失败。其次,单一的全局辐射场能力有限,不能在无界场景中扩展到更长的轨迹 。为了处理未知pose,我们 联合估计具有辐射场的相机pose,并逐步优化,显著提高重建的鲁棒性。为了处理大型的无界场景, 我们在临时窗口内,动态分配局部辐射场(逐帧训练),这进一步提高了鲁棒性(例如,即使在适度的pose 漂移下,也能表现得很好),并扩展到大型场景。实验对TANKS 和 TEMPLES数据集,以及收集的户外数据集的广泛评估。
一、引言
逼真视觉合成的密集场景重建有许多重要的应用,例如VR/AR(虚拟旅行、对重要文化文物的保存)、视频处理(稳定和特殊效果)和映射(房地产、人级地图)。近年来,在提高利用辐射场[22]进行重建的保真度方面取得了快速的进展。与大多数传统的方法不同,辐射场可以模拟一些常见的现象,如依赖于视图的外观、半透明性和复杂的微观细节。
1.1 挑战
本文目标:创建使用单一手持相机获得的大规模场景的辐射场重建。面临着两个主要的挑战: (1)估计一个长路径的精确摄像机轨迹和(2)重建场景的大尺度辐射场。 难点:观测到的变化可以用相机运动或辐射场建模视图相关外观的能力来解释。因此,许多辐射场估计技术假设精确的pose是已知的(通常在辐射场优化期间是固定的)。然而,实践中必须使用单独的方法,如运动结构(SfM),来估计预处理步骤中相机的pose(SfM在手持视频设置中经常失败)。因为与辐射场不同,它不建模依赖于视图的外观,在没有高度纹理特征的情况下,甚至在有轻微的动态运动(如摇摆的树枝)的情况下失败
为了消除对已知相机姿态的依赖,Barf、NeRF–等方法[11,17,41]提出了联合优化相机pose和辐射场。这些方法在处理几个帧和一个良好的姿态初始化时表现良好。然而,正如我们的实验所示,他们很难从零开始估计摄像机的长轨迹,并且经常处于局部最小值。
1.2 我们的工作。
本文从经典的增量SfM算法和基于关键帧的SLAM系统中汲取灵感,提出了一种联合位姿和辐射场的估计方法。 方法的核心是,使用重叠的局部辐射场,逐步处理视频序列。具体地,在更新辐射场的同时,逐步估计输入帧的pose 。为了模拟大规模的无界场景,我们动态地实例化局部辐射场,主要优点:
- 我们的方法可以扩展处理任意长的视频,而不损失准确性,也没有触及内存限制。
- 增加了鲁棒性,因为错误估计的影响是局部有限的。
- 增加了锐度,因为我们使用多个辐射场来建模场景的局部细节
实验数据:TANKS 和 TEMPLES数据集,以及一个新的数据集 STATIC HIKES(12个户外场景,使用4个消费者相机)。这些数据具有挑战性,因为长手持相机轨迹,运动模糊,和复杂的外观。
1.3 贡献:
- 逐步估计摄像机的姿态和辐射场,从而显著提高了鲁棒性。
- 多个重叠的局部辐射场提高视觉质量,并支持大规模无界场景建模。
- 提供了一个新收集的视频数据集,提出了现有视图合成数据集没有涵盖的新挑战。
1.4 局限性
限制。LocalRF 联合估计管道中的姿态,旨在从重建的辐射场中合成新的观点,但不执行全局bundle adjustment 和 loop closure(即,不是一个完整的SLAM系统)。我们把这个重要的方向留给了未来的工作。
二、相关工作
2.1 新视图合成
新视角合成的目的是从多个姿态图像中合成新的视角。近年来,神经隐式表征显示出了很有前途的新观点合成结果[22]。然而,实现高质量的无artifact渲染结果,仍然是一项具有挑战性的任务。最近的工作通过解决不一致的相机曝光或照明[20,32,36]、处理动态元件[8,16,18,28,29,43]、抗锯齿[3]、高噪声[21]或从减少的帧数[27]中进行的优化,进一步提高了视觉质量。虽然这些基于隐式表示的方法可以产生高质量的结果,但它们需要几天的时间来训练。为了提高训练效率,一些工作还探索了具有体素类结构[33,35]、张量分解[6]、光场表示[1,2]或散列体素/MLP混合[24]的更显式表示。我们的工作还利用了TensoRF [6]最近的优势。
2.2 可扩展的视图合成
已经提出了几种方法来支持无界场景[4,47]。然而,这些方法要么需要全向(omnidirectional)输入[10],代理几何[42],专门的无人机拍摄[40],或卫星拍摄[44],并努力处理在地面上捕获的单目视频。最近,Mip-NeRF 360 [4]将背景收缩到一个收缩的空间中,而NeRF++ [47]优化了一个环境地图来表示背景。BlockNeRF [36]是可扩展的,但需要多视图输入和多个观察结果。NeRFusion [49]使用预先训练的2D CNN和稀疏的3D CNN构造每帧局部特征体。它是可扩展的,并在大型室内场景上表现出良好的精度,但它不能处理摄像机姿态估计或无界室外场景。由于表示大多是在可选的每个场景优化之前重建的,所以同时优化姿态并不简单。
与这些约束相比,我们的方法是鲁棒性的,适用于任意的长相机轨迹,并且只以随意捕获的单目第一人称视频作为输入。
2.3 相机姿态估计
视觉测速法(Visual odometry) 从视频中估计相机的姿势。它们要么是依赖通过最大化照片一致性[46,51]得到的颜色,要么是手工特征[25,26,34]。最近,基于学习的方法[ Particlesfm、Particlesfm等9,15,39,50,51]学习以自监督的方式优化摄像机轨迹,并显示出很强的结果。类似地,许多方法扩展了NeRF,从光度损失[11,17,41]的辐射场联合优化相机姿态。然而 ,这些方法在大场景中难以重建和合成真实的图像,而对于具有长摄像机轨迹的单眼第一人称视频往往会失败。Vox-Fusion [45]和Nice-SLAM [53]可以实现良好的姿态估计,但都是为RGB-D输入设计的,需要精确的深度: VoxFusion分配稀疏体素网格,用Nice-SLAM来确定沿射线采样。请注意,我们的目标并不在于估计照相机的姿势。相反,专注于重建重叠的局部辐射场,使逼真的视图合成。我们相信,集成诸如global bundle adjustment 等先进技术可以改善我们的结果
三、方法

LocalRF以一个很长的单目视频作为输入,目标是重建场景的辐射场和摄像机轨迹,使自由视点的新视图合成。LocalRF选择TensoRF [6]作为基本表示(基于其质量、合理的训练速度和模型大小)。TensoRF用一个分解的四维张量建模场景,该张量将一个三维位置x映射到相应的体积密度σ和视图相关的颜色c。然而,它只有在精确的已知摄像机姿态下才能实现,而TensoRF的表示能力需要提高,以便从无界场景的长轨迹中捕捉细节。
LocalRF通过提高联合摄像机姿态和辐射场估计的鲁棒性,来解决对已知摄像机pose的需要,并将该方法扩展到处理任意长的输入序列。提出了一种渐进式优化方案,采用一个移动的临时窗口处理输入视频,并逐步更新辐射场和相机姿态。这一过程确保了新的帧被添加到相机pose和辐射场表示的良好收敛方案中,有效地防止卡在较差的局部极。此外,我们在整个优化过程中动态分配新的局部辐射场,这些场由有限数量的输入帧(在一个时间窗口内)监督。这进一步提高了在使用固定内存处理任意长的视频时的鲁棒性。
3.1 公式和准备知识
优化过程中,我们估计了P个相机的姿态 [ R|t ]k,k∈[1…P],以及M个局部辐射场的参数Θj,j∈[1…M]。
给定一个像素,使用相机参数和pose来生成一个射线r。沿着这条射线采样3D位置{xi},并查询一个提供颜色和密度的辐射场,并体渲染光线:
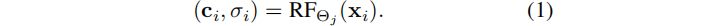

δi为两个连续样本点之间的距离,Ti为沿射线的累积透射率。使用输入帧的颜色C的L1损失作为监督。 TensoRF 具有类似于BARF的[17]的显式的粗到细的优化,并减少了收敛到局部最小值的可能性。
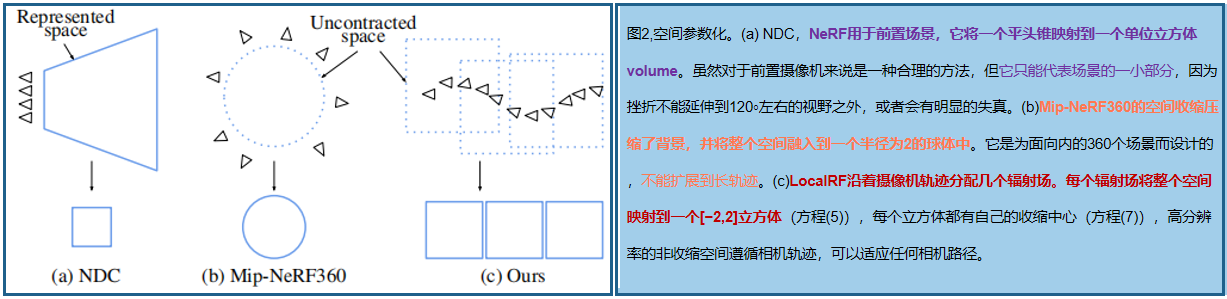
为了处理无界的场景,利用Mip-NeRF360的收缩的场景参数化,在查询我们的辐射场模型之前,将每个点映射到一个[−2,2]空间:
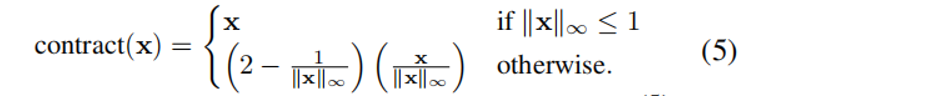 这里我们使用L∞范数来充分利用TensoRF的正方形边界框。虽然Mip-NeRF360缩放相机pose,可以保持感兴趣区域周围的非收缩空间(原文:Mip-NeRF360 scale camera poses
这里我们使用L∞范数来充分利用TensoRF的正方形边界框。虽然Mip-NeRF360缩放相机pose,可以保持感兴趣区域周围的非收缩空间(原文:Mip-NeRF360 scale camera poses
to keep the uncontracted space around the area of interest),但我们不能采用这种策略,因为我们联合估计pose和辐射场(pose是未知的)。我们通过动态创建新的辐射场来实现适当的缩放。
3.2 渐进的摄像机pose和辐射场的联合优化
现有的姿态校准方法 [Barf、NeRF–等11,17,41] 已经证明,联合优化辐射场和摄像机pose可以在小镜头场景中获得令人满意的效果。然而,当处理较长的序列时,联合优化失败了,因为估计的pose处于局部最小值(见图4)。 为了提高鲁棒性,我们只用少量的帧(实验中为前五帧)开始优化,并逐步引入后续帧的优化 。使用轨迹末的当前帧p,来初始化新的pose (p + 1):
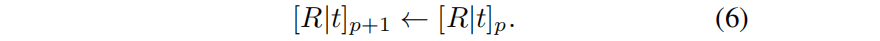
然后将 [R|t]p+1 添加到训练参数中,新的帧的颜色,作为辐射场的监督。新帧的参数的收敛性得益于辐射场的初始化和当前估计的pose,使其不太容易陷入局部极小值。由于在轨迹的末端添加了摄像机pose,因此它还引入了一个局部性先验,强制每个pose都接近前一个pose,而没有明确的约束。

3.3 局部辐射场

上一步方案提供了更鲁棒的pose估计,但它仍然依赖于一个单一的全局表示 ,导致问题建模长视频: (1)任何错误估计(例如,离群的pose)产生全局的影响,可能导致重建崩溃。(2)具有固定容量的单一模型,不能代表任意长度视频的细节,导致模糊(图5b)。解决方案之一:使用类似Mega-NeRF对辐射场空间进行预分区,但是此处相机的pose在优化之前是未知的。LocalRF:当估计的相机pose轨迹,离开当前辐射场的非收缩空间时,就会动态地创建一个新的辐射场。新的辐射场集中在最后一个估计的相机pose的位置tj 处:

采样射线时,我们使用此平移使辐射场成为中心:
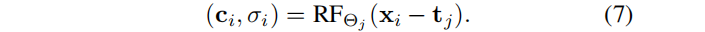
我们用视频帧的一个子集(包含当前辐射场所在的所有帧,以及前面的30帧),来监督每个辐射场。重叠的30帧至关重要:所有重叠辐射场的渲染颜色 C ^ \hat{C} C^j(r) 混合在一起,进一步提高了一致性。每一帧使用混合权重,在重叠区域内线性增加/减少。当创建一个新的辐射场时,停止优化以前的辐射场,并从内存中清除监控帧。
3.4 实施
3.4.1 Loss
除了颜色的监督外,还使用相邻帧之间的单目深度和光流。使用RAFT [38]来估计帧-帧光流Fk→k+1,k∈[1…P−1]和DPT [30]来估计每帧单目深度d。为了实现这些损失,我们首先通过交换公式(2)中样本的距离来渲染深度图:

得到深度监督(两个D都做了归一化,因为单目估计的尺度和位移变化):
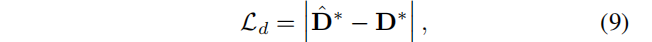
归一化方法仿照论文[31:Towards robust monocular depth estimation],如下:
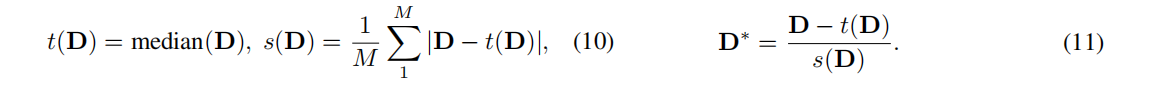
实践中,从batch的16张图像中采集光线,并获得每个图像的比例和位移。利用相对的相机pose和渲染的深度图中,获得预期光流:
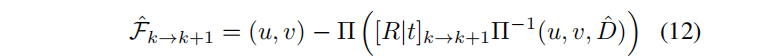
Π表示投影三维点到图像坐标,Π−1逆投影像素坐标和深度,到一个三维点。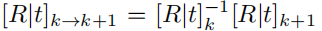 是练续两帧之间的相对像机pose,将第k个像机空间中的点,带到第k+1的空间中。最后将预测的流与表示法中的预测流进行比较:
是练续两帧之间的相对像机pose,将第k个像机空间中的点,带到第k+1的空间中。最后将预测的流与表示法中的预测流进行比较:
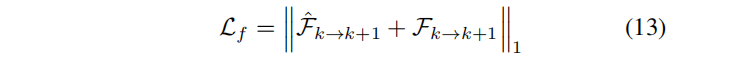
我们使用相同的过程来监督使用反向光流Fk→k−1。光流计算直接利用了公式(12)中的姿态和场景的几何形状,这为其优化提供了一个清晰的梯度信号。
3.4.2 优化配置
所有参数都使用β1 = 0.9和β1 = 0.99的Adam进行优化。我们从初始化为identity的五种姿态和一个初始的TensoRF模型开始。然后,对于每100次迭代,我们在视频中添加下一个监督帧。优化过程中,所有的学习率、损失权重和TensoRF分辨率保持在其初始状态,确保辐射场不会过拟合于第一帧。我们的初始学习速率为旋转5·10−3,平移5·10−4,初始TensoRF分辨率为643,初始正则化损失权重为1,深度为0.1。渐进式帧配准,直到估计的相机pose超出了非收缩空间:∥tp−tj∥∞≥1,其中tp 最后一帧的平移,tj 是当前优化的辐射场中心。
从这一新的点开始,细化了TensoRF,每添加新帧进行600次迭代(图3c)。调度器和正则化损失呈指数级下降到0.1倍,我们将TensoRF向上采样到6403。在此阶段之后分配一个新的TensoRF,并从第一帧中禁用监督。我们重复这个过程,直到重建整个轨迹。在一个NVIDIA泰坦RTX上进行1000帧的优化需要30到40个小时。
四、实验
4.1.数据集
Tanks and Temples: 选择没有动态元素的序列(21场景中的9个),保留一个每五帧运动缓慢,降低视频全高清分辨率(2048×1080或1920×1080),并保持第一个1000图像方法与静态数据加载器可以预加载图像和射线在合理的系统内存。
Static Hikes: 我们还收集了一个新的具有徒步旅行序列的数据集。它包含具有较大相机轨迹的手持序列,以测试可伸缩性和姿态估计的鲁棒性。它包括12个1920×1080静态户外场景视频,由GoPro Hero10拍摄,GoPro×9与窄视场,以及LG V60 ThinQ和三星Galaxy S21的宽摄像头。
4.2.对比方法
无界户外场景对比:Mip-NeRF360和NeRF++ 。Mip-NeRF360结合Instant-NGP[24]的哈希编码和Mip-NeRF360的场景收缩,有效地表示无限的场景。预处理的poes采用MultiNeRF[23]的脚本来运行COLMAP。我们还比较了可伸缩表示Mega-NeRF[40](我们的实验使用2×2网格大小)。SCNeRF需要COLMAP作为初始化:在我们的实验中,当使用NeRF和NeRF++基从头优化姿态时失败(我们得到NaN渲染)。因此,我们必须从完全自我校准的评估中排除SCNeRF。
4.3 定量分析
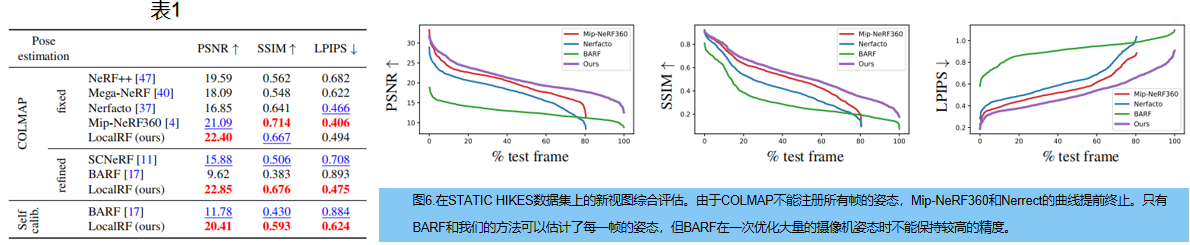
定量评价新视图,选择每10帧作为测试图像。表1显示了合成视图和相应的GT视图之间的PSNR、SSIM和LPIPS 。平均值在PSNR的平方误差域计算,SSIM的√ 1 − S S I M ˉ \bar{1−SSIM} 1−SSIMˉ。
使用COLMAP姿态,LocalRF获得了与Mip-NeRF360 [4]相似的质量。Mega-NeRF [40]为不同类型的输入数据设计,尽管使用了几个辐射场,但质量较低。与其他自校准辐射场方法[11,17]相比,我们在从头开始优化姿态时获得了更好的结果,这要归功于我们的渐进优化,允许一次从头开始估计更少的参数,并在相机姿态之前增加了一个灵活的局部性。图6显示,在具有更长的轨迹和更具挑战性的场景的静态上升数据集上,LocalRF始终获得了比自校准的BARF [17]方法更好的结果。依赖于COLMAP的Mip-NeRF360 [4]不能对19.5%的测试帧产生结果。
4.4 定性评价
图7、8、9显示了定性结果,感兴趣可以翻到最后;表2显示了消融实验的结果,同样放在最后面。
4.5 局限性
实验表明,LocalRF可以稳健地估计长相机的轨迹,同时保持高分辨率的表示。然而,我们的pose估计和渐进方案假设我们使用的是一个没有拍摄变化的连续视频。这意味着 LocalRF不适合于从没有连贯性的非结构化帧集合中重建场景。我们也不处理动态元素 。在图8的最后一行中的动态元素会导致模糊的区域。我们观察到的另一个限制是,突然的旋转会破坏姿态估计,导致图像渲染不佳。
总结
提出了一种从随意拍摄的视频中重建大场景辐射场的新方法。LocalRF的核心思想是:1)一种联合估计摄像机姿态和辐射场的渐进优化方案;2)动态实例化局部辐射场。实验对两个数据集做了广泛评估,证明了鲁棒性和保真度。
以下是定性实验结果:
图7:在 TANKS 和 TEMPLES数据集新视图。(a)和(b)局部性允许对照明变化和姿态估计失败具有更强的鲁棒性。©因为遵循轨迹的较少收缩的空间,得到更清晰的结果:

图8: STATIC HIKES上结果:局部辐射场允许我们保持整个轨迹的锐度。一些依赖于预处理姿态的Mip-NeRF360结果缺失了。我们的方法可以稳健地优化姿态,即使在其他方法不太可靠的场景中也能取得良好的结果。

图9:输入路径偏差。LocalRF可以渲染偏离输入路径的新视图:

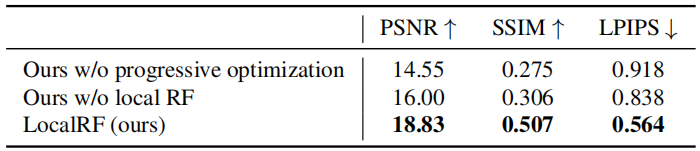
表2:STATIC HIKES数据集上的消融结果:
d
\sqrt{d}
d
1
0.24
\frac {1}{0.24}
0.241
x
ˉ
\bar{x}
xˉ
x
^
\hat{x}
x^
x
~
\tilde{x}
x~
ϵ
\epsilon
ϵ
ϕ
\phi
ϕ