👦个人主页:@Weraphael
✍🏻作者简介:目前学习C++和算法
✈️专栏:C++航路
🐋 希望大家多多支持,咱一起进步!😁
如果文章对你有帮助的话
欢迎 评论💬 点赞👍🏻 收藏 📂 加关注✨
目录
- 一、哈希思想
- 二、常见的哈希函数
- 2.1 直接定址法
- 2.2 除留余数法
- 三、哈希冲突
- 3.1 哈希冲突的原因
- 3.2 如何解决哈希冲突
- 闭散列(开放定址法)
- 开散列(链地址法、开链法、哈希桶)
- 四、unordered系列
- 4.1 与map和set的区别
- 4.2 map/set与unordered_map/unordered_set的性能测试
一、哈希思想
哈希是一种 映射 思想。它是将存储的值跟存储的位置建立映射关系,由这种思想而构成的数据结构称为 哈希表(散列表)
哈希表中插入数据和查找数据 的步骤如下:
-
插入数据:根据当前待插入的元素的键值,通过哈希函数计算出哈希值,并存入相应的位置中
-
查找数据:根据待查找元素的键值,计算出哈希值,判断对应的位置中存储的值是否与键值相等
例如:数据集合{1,7,6,4,5,9},哈希函数设置为:hash(key) = key % capacity(capacity为存储元素底层空间总的大小)
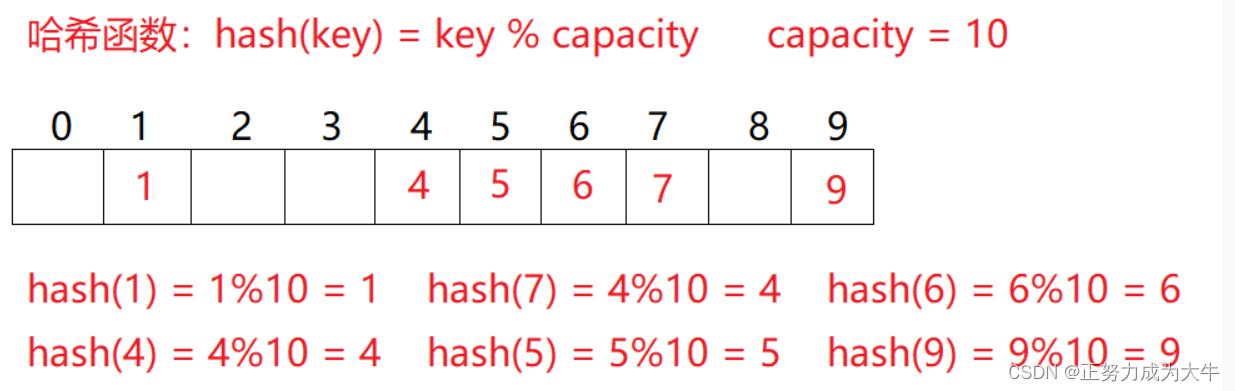
显然,这个哈希表并没有把所有位置都填满,数据分布无序且分散。
因此,哈希表又称为散列表。
那么如何建立映射关系呢?这就要涉及到哈希函数了。
二、常见的哈希函数
2.1 直接定址法
函数原型:Hash(key) = A * key + B(A, B为常数)
- 适用场景:值的分部范围比较集中。例如:统计字符字符出现的次数。
- 缺点:需要提前知道键值的分布情况。
2.2 除留余数法
函数原型:Hash(key) = key % m (m为哈希表的大小)
- 适用场景:范围不集中,分布分散的数据
- 缺点:容易出现哈希冲突,需要借助特定方法解决。
三、哈希冲突
3.1 哈希冲突的原因
哈希冲突:又称哈希碰撞,不同的值可能会映射到同一个位置。
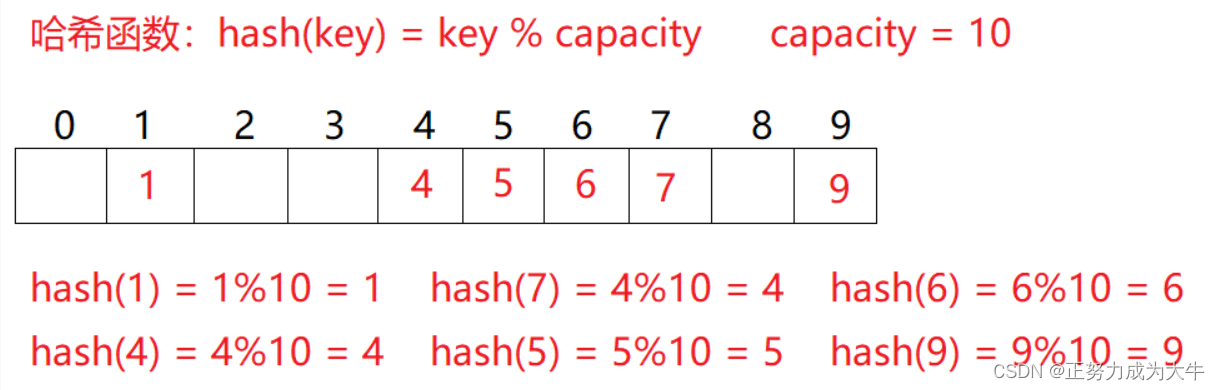
如果继续插入元素 44,哈希值 hash(44) = 44 % 10 = 4,此时哈希值为 4 的位置处已经有元素了,无法继续存入,此时就发生了 哈希冲突。
3.2 如何解决哈希冲突
闭散列(开放定址法)
当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把
key存放到冲突位置中的下一个空位置中去。
那么如何寻找下一个空位置呢?
- 线性探测法:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
例如,我们用除留余数法(hash(key)=key%10)将序列{1, 6, 10, 1000, 101, 18, 7, 40}插入到表长为10的哈希表中,插入过程如下:

通过上图可以看到,随着哈希表中数据的增多,产生哈希冲突的可能性也随着增加,最后在40进行插入的时候更是连续出现了四次哈希冲突。于是如果哈希表接近满的话,插入、查找、删除的效率都会越来越低。
- 优化方案:二次探测,每次向后探测
i ^ 2步。尽管如此,闭散列的效果还是不尽人意,实际中还是 开散列 用的更多一些
开散列(链地址法、开链法、哈希桶)
所谓 开散列 就在原 存储位置 处带上一个 单链表,如果发生 哈希冲突,就将 冲突的值依次挂载即可。因此也叫做 链地址法、开链法、哈希桶。
例如,我们用除留余数法将序列{1, 6, 15, 60, 88, 7, 40, 5, 10}插入到表长为10的哈希表中,当发生哈希冲突时我们采用开散列的形式,将哈希地址相同的元素都链接到同一个哈希桶下,插入过程如下:

- 开散列 中进行插入时,如果对应位置的哈希值被占了,那么就在对应位置开一块链表进行存储。
- 开散列中进行查找时,需要先根据哈希值找到对应位置,并在单链表中进行遍历。
一般情况下,单链表的长度不会太长的,因为扩容后,整体长度会降低。如果单链表真的过长了,我们还可以将其转为红黑树,此时效率依旧非常高。
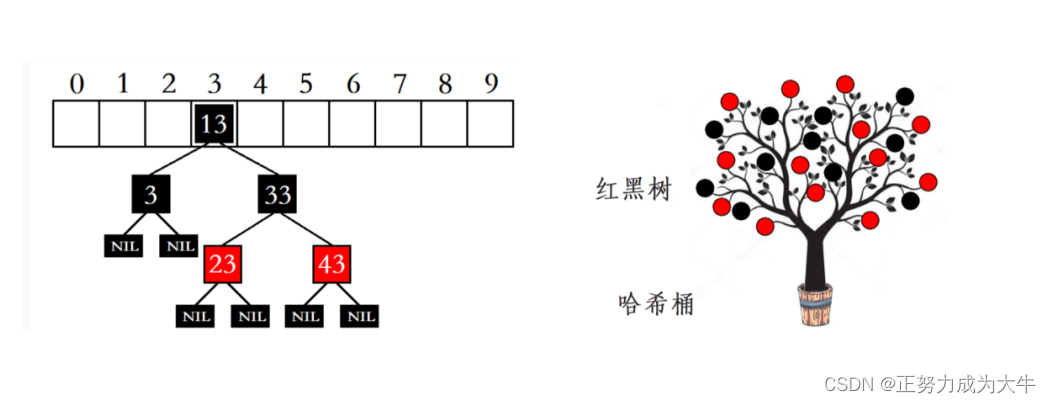
- 值得一提的是 哈希表(开散列法)最快时间复杂度为
O(N),平均是O(1)。
哈希表(开散列法) 和快排一样很特殊,时间复杂度不看最坏的,看 平均时间复杂度,因为 最快的情况几乎不可能出现。
四、unordered系列
4.1 与map和set的区别
哈希表最厉害的地方在于 查找速度非常快,比红黑树还快,时间复杂度是
O(1)(后面的性能测试见)。因此在C++11标准中,利用 哈希表 作为底层结构,重写了set / map,就是unordered_set / unordered_map。
unordered系列的使用和map以及set几乎没区别,使用方面建议大家查文档:点击跳转
要说有区别如下:

4.2 map/set与unordered_map/unordered_set的性能测试
说到一个容器的性能,我们最关心的实际就是该容器增删查改的效率。我们可以通过下列代码测试
set容器和unordered_set容器insert、find以及erase的效率。
【测试代码】
#include <iostream>
#include <unordered_set>
#include <unordered_map>
#include <set>
#include <map>
#include <vector>
using namespace std;
void Performance_testing()
{
// set和unordered_set
const int N = 1000000; // 一百万
set<int> s;
unordered_set<int> us;
vector<int> v;
v.reserve(N);
srand(time(0));
for (int i = 0; i < N; i++)
{
v.push_back(rand());
// v.push_back(rand() + i);
// v.push_back(i);
}
// =========== 插入测试 =================
size_t begin1 = clock();
for (auto e : v)
{
s.insert(e);
}
size_t end1 = clock();
cout << "set的插入时间:" << end1 - begin1 << endl;
size_t begin2 = clock();
for (auto e : v)
{
us.insert(e);
}
size_t end2 = clock();
cout << "unordered_set的插入时间:" << end2 - begin2 << endl;
// =========== 查找测试 =================
size_t begin3 = clock();
for (auto e : v)
{
s.find(e);
}
size_t end3 = clock();
cout << "set的find:" << end1 - begin1 << endl;
size_t begin4 = clock();
for (auto e : v)
{
us.find(e);
}
size_t end4 = clock();
cout << "unordered_set的find:" << end4 - begin4 << endl;
cout << "set插入数据个数:" << s.size() << endl;
cout << "unordered_set插入数据个数:" << us.size() << endl;
// =========== 删除测试 =================
size_t begin5 = clock();
for (auto e : v)
{
s.erase(e);
}
size_t end5 = clock();
cout << "set删除:" << end5 - begin5 << endl;
size_t begin6 = clock();
for (auto e : v)
{
us.erase(e);
}
size_t end6 = clock();
cout << "unordered_set删除:" << end6 - begin6 << endl;
}
int main()
{
Performance_testing();
return 0;
}
- 对
1000个数做增删查改操作
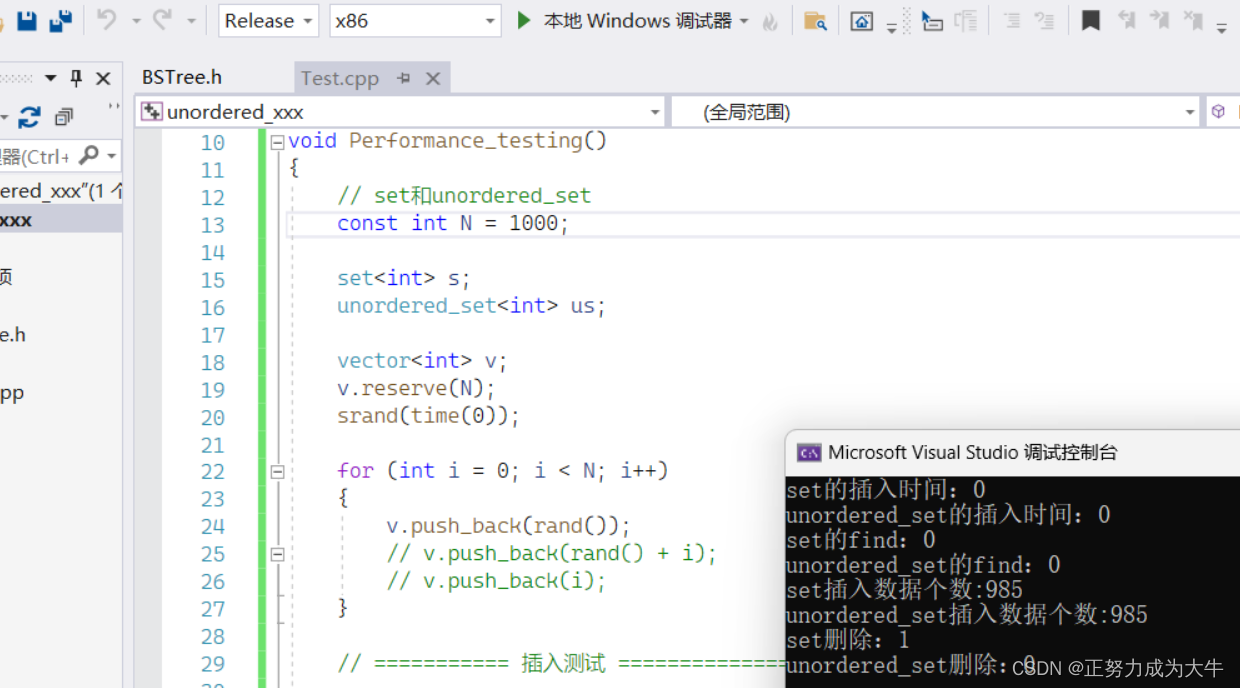
我们发现:当数据量小的时候,它们的效率差不多。
- 对
10000000个数做增删查改操作
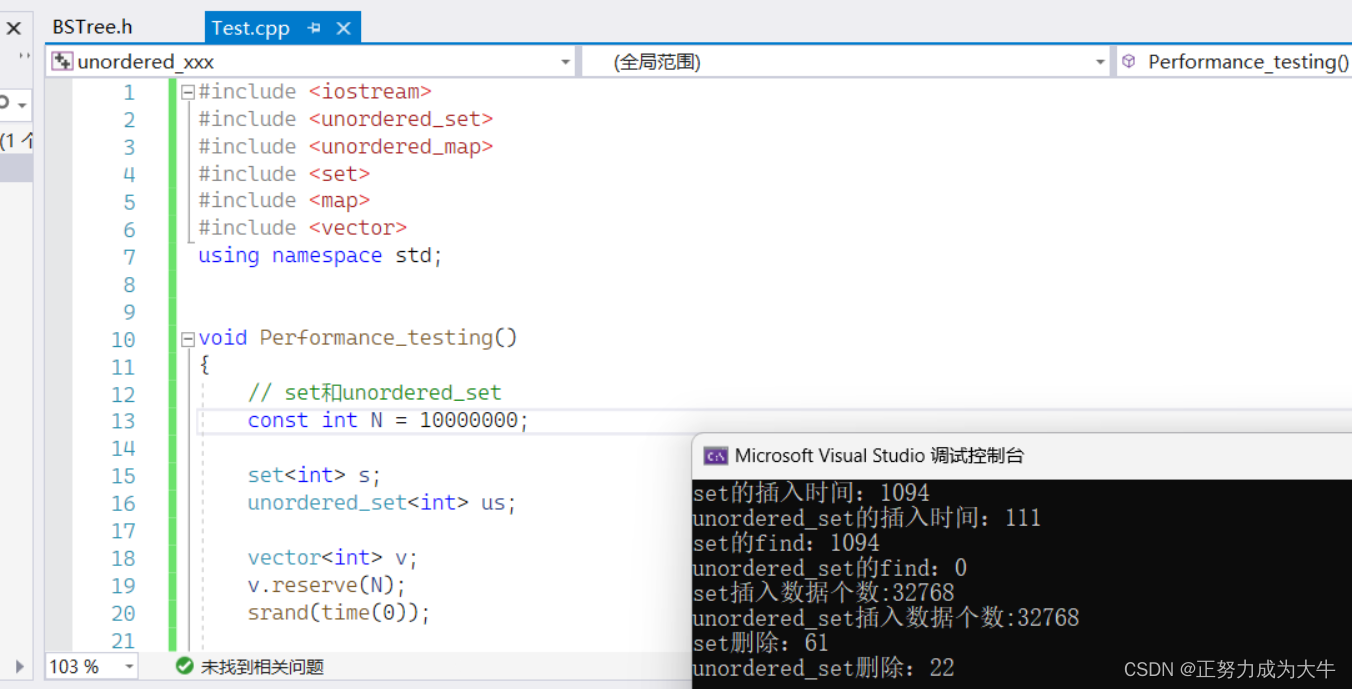
当数据量达到一千万的时候,明显unordered系列快多了。
根据测试结果可以得出以下结论:
-
当处理数据量小时,
map/set容器与unordered系列容器增删查改的效率差异不大。 -
当处理数据量大时,
map/set容器与unordered系列容器增删查改的效率相比,unordered系列容器的效率更高。
因此,如果在unordered系列和map/set容器,应该首选unordered系列; 另外如果需要存储的序列为有序时,应该选用map/set容器。