背景
最近公司内部在做某自研数据存储的下线工作,这里我们暂且化名其为DistributeSQL,由于DistributeSQL不再进行服务支持,需要迁移项目中使用到该存储到其他数据存储中。
本篇来聊聊这次在数据存储迁移过程中的方案设计思路、实现的大致细节以及对技术组件选型、技术能力储备重要性的理解。
技术调研
技术选型的思路很清晰,首先,要找到与DistributeSQL技术能力匹配的其他存储进行替换;其次,要对数据迁移的方案进行全面、细致的设计;最终,分阶段进行改造落地和实施。
定位
接下来需要做数据存储组件来替代DistributeSQL,DistributeSQL的自我定位是分布式表格数据库,其本质是支持强一致性、在线事务处理(OLTP)的持久化存储,此次采用MySQL作为存储替代。
原因
- 1⃣️ 借鉴了
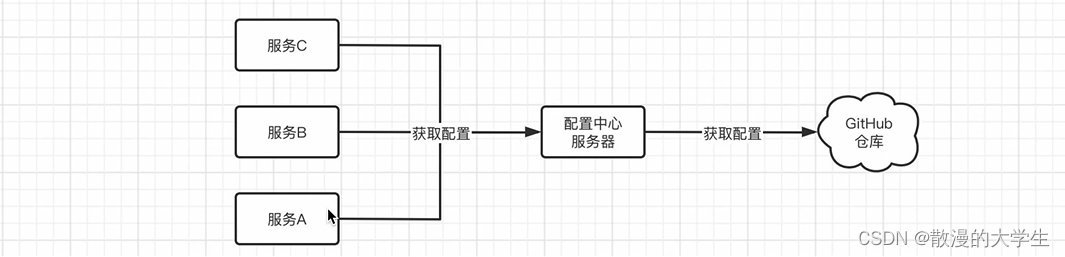
DistributeSQL团队迁移建议,调研了其他团队迁移实践案例方案 - 2⃣️ 此前迁移到
DistributeSQL的源数据存储是MySQL,理论上可以支持逆向数据回溯 - 3⃣️ 结合团队内
DistributeSQL数据存储量级不高、更新频率低、业务依赖度不高等现状
使用现状
当前使用现状比较清晰,主要是和数据层直接贴缘的应用服务,也是本次要涉及代码改造影响的一部分,交互方式主要是通过DistributeSQL Binlog进行读写,此外由于DistributeSQL也支持数据oplog即类MySQL的binlog能力支持,在业务实际使用中还存在DistributeSQL Binlog读方式交互。
DistributeSQL SDK读DistributeSQL SDK写DistributeSQL Binlog读
方案设计
架构图
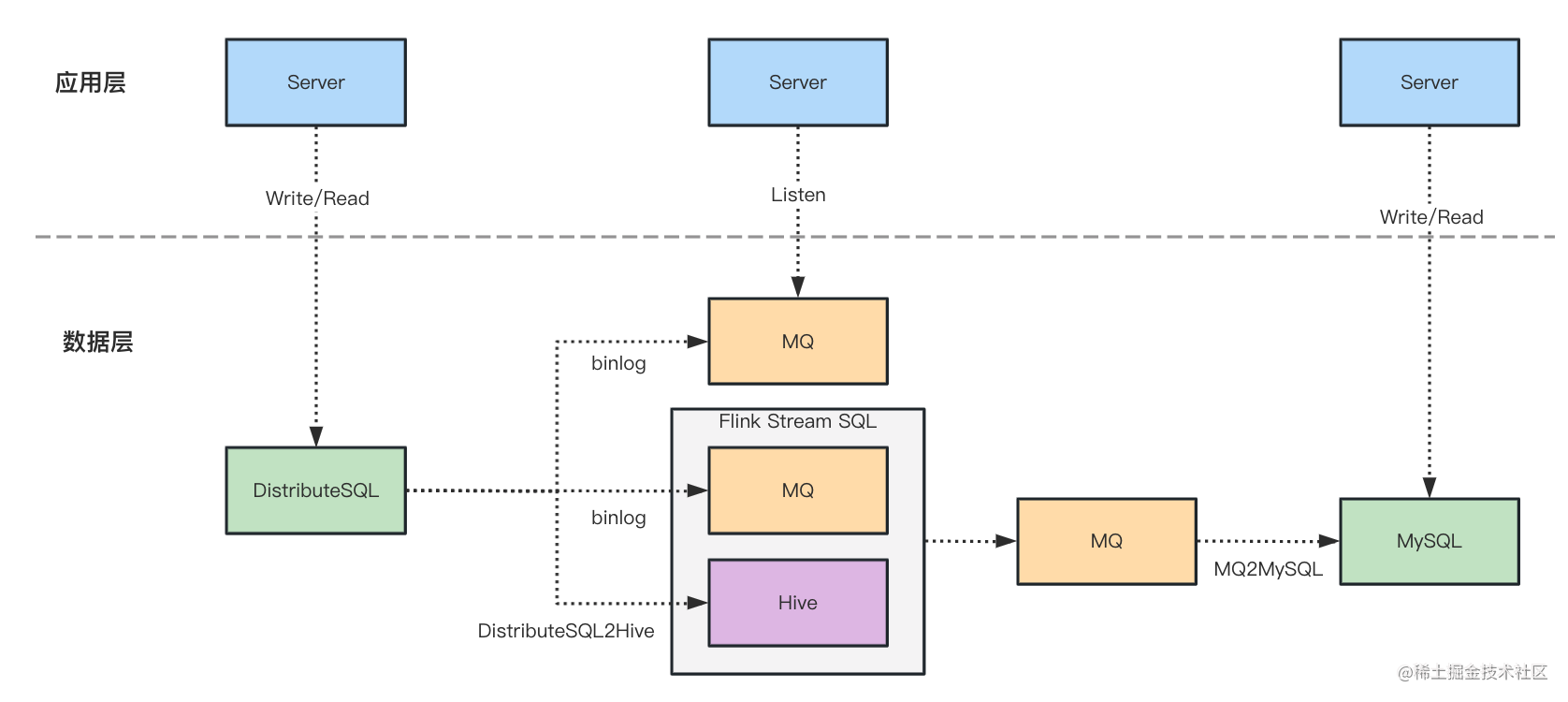
根据使用现状进行迁移方案设计,从应用层、数据层两个模块分开进行:
-
应用层
应用层主要是对贴缘层SDK改造以满足
MySQL的读写能力支持,由于之前接入了DistributeSQL binlog读取,因此这部分也需要进行MySQL binlog的读取替代。-
DistributeSQL SDK读- 支持
MySQL读能力支持 - 增加路由开关控制
- 支持
-
DistributeSQL SDK写- 支持
MySQL写能力支持 - 增加路由开关控制
- 支持
-
DistributeSQL binlog读- 支持
MySQL binlog读能力支持 - 增加路由开关控制
- 支持
-
-
数据层
如果自身服务能够容忍停机迁移,可以直接设计纯离线迁移方案,复杂度较低一些,若不能则需要既考虑存量数据迁移,也要支持DistributeSQL实时数据的同步迁移能力准备,也就是说在不停机的情况下,做到让业务无感知。
根据业务情况我们选择了做实时和离线迁移的能力支持和方案,这里既有业务的现实不可接受的客观因素,还有很重要的一点在于团队内对于已经对数据层开发有了较多沉淀积累,公司内部提供的数据开发平台能力和工具功能非常强大,也就是说团队成员有能力且有平台能支持我们快速搭建实时与离线链路,再者之前有实践跑通过MySQL到Clickhouse的数据链路打下较为扎实的技术储备能力。
流程图
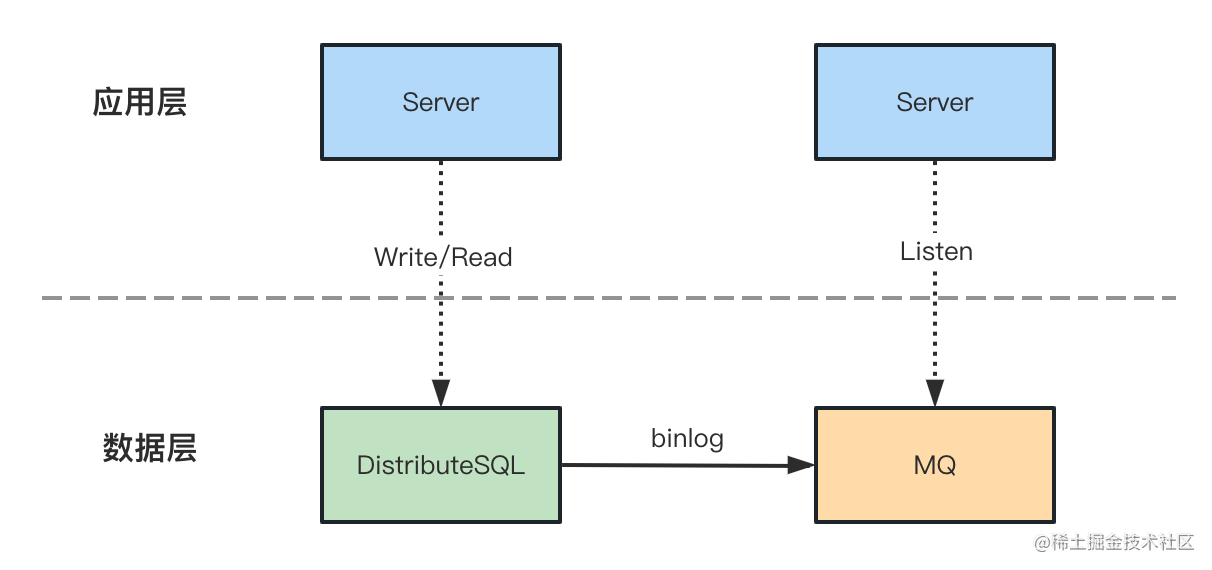
DistributeSQL -> MySQL数据同步链路,示意如下:
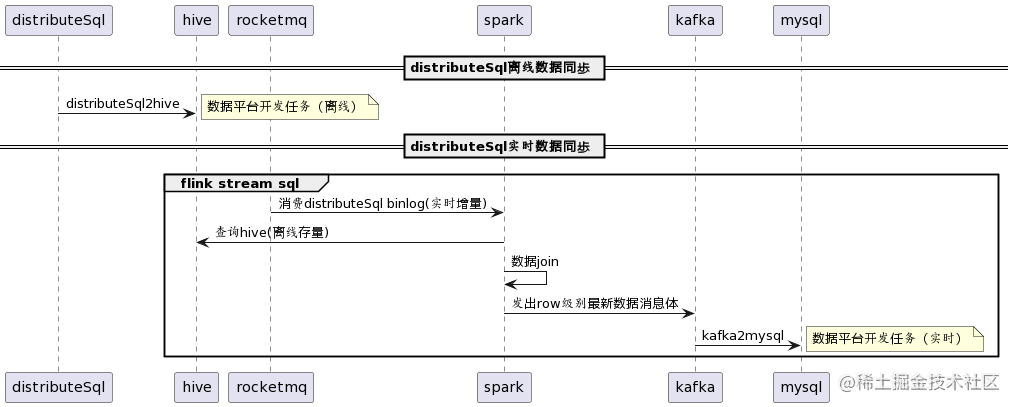
关于DistributeSQL到MySQL的数据层链路可以按照离线、实时分为两条,并分别进行数据层开发:
- 离线
离线链路可以直接使用公司数据平台提供的DistributeSQL2Hive任务进行离线迁移
- 实时
实时链路相对复杂一些,这里参考了之前搭建准实时数仓的方式,通过公司数据平台配置Flink Streaming SQL任务,读取DistributeSQL的实时binlog数据即MQ,监听每次增量时在Spark任务中联查离线Hive进行Join,通过数据主键完成数据唯一性对比和去重,保证每次处理数据都是最新数据,最终将结果写入到Kafka中,然后通过数据平台Kafka2MySQL任务完成最终目标数据源写入。
Flink Streaming SQL逻辑可以分为四部分:
[1] 监听增量
RocketMQ消息,即DistributeSQL binlog数据
[2] 查询DistributeSQL已经离线的Hive存量数据
[3] 将存量Hive、增量MQ进行去重JOIN得到最新的Row级别数据
[4] 写入到Flink流式中,最终以Kafka消息体形式输出
示例如下:
-- ********************************************************************
-- Author: guanjian
-- CreateTime: 2023-01-04 18:02:30
-- Description:
-- Update: Task Update Description
-- ********************************************************************
-- 【引入用到的函数和资源】
CREATE LEGACY FUNCTION nanoTime AS 'com.xxx.stream.NanoTime';
CREATE function TIMESTAMP_TO_LONG AS 'com.xxx.flink.time.TimestampToLong';
ADD Resources flink_connector_custom_11;
--【这里对标DistributeSQL的binlog,是以RMQ形式接入的】
-- [1] 增量实时 DistributeSQL binlog,即 RocketMQ
CREATE TABLE delta_rmq_data (
id ROW<before_value BIGINT, after_value BIGINT, after_updated BOOLEAN>,
number ROW<before_value INT, after_value INT, after_updated BOOLEAN>,
time ROW<before_value TIMESTAMP, after_value INT, after_updated BOOLEAN>,
string ROW<before_value VARCHAR, after_value VARCHAR, after_updated BOOLEAN>
)
WITH (
'scan.startup-mode' = 'timestamp',
'connector' = 'rocketmq',
'cluster' = 'your cluster',
'topic' = 'youer topic',
'group' = 'your topic group', --消费者组,自定义即可
'format' = 'binlog',
'tag' = 'your tag', --自定义
'binlog.target-table' = 'your table', --自定义
'scan.force-auto-commit-enabled' = 'true',
'scan.startup.timestamp-millis' = '1638288000000' --2021-12-01 00:00:00 每次重新上线可以不修改,因为后续会去重,修改会减少计算量
);
-- [2] 全量离线 DistributeSQL已经离线的Hive数据
CREATE TABLE base_hive_data (
id BIGINT,
number INT,
time TIMESTAMP,
string VARCHAR
)
WITH (
'connector' = 'xxx',
'query' = 'SELECT CAST(id AS BIGINT ) ,
CAST(number AS INT ) ,
CAST(time AS TIMESTAMP) ,
CAST(string AS VARCHAR )
FROM LF_HL_HIVE.hive_database.hive_table
WHERE p_date = ''${date}''',
'base_path' = 'hdfs://xxx.db/',
'conf' = 'set yarn.cluster.name=xxx;set mapreduce.job.queuename=xxx;' --yarn集群、队列
);
-- [3] union all 全量
CREATE VIEW union_data AS
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER(
PARTITION BY
id
ORDER BY
main_order DESC,
ts DESC
) AS rn
FROM (
SELECT id.after_value AS id,
number.after_value AS number,
time.after_value AS time,
string.after_value AS string,
1 AS main_order,
nanoTime() AS ts
FROM delta_rmq_data
WHERE binlog_body.event_type = 'INSERT'
OR binlog_body.event_type = 'UPDATE'
UNION ALL
SELECT id,
number,
time,
string,
0 AS main_order,
nanoTime() AS ts
FROM base_hive_data
)
)
WHERE rn = 1;
-- [4] 写入到kafka
CREATE TABLE data_bmq_sink (
id BIGINT,
number INT,
time TIMESTAMP,
string VARCHAR,
p_date BIGINT
)
WITH (
'properties.request.timeout.ms' = '120000',
'json.timestamp-format.standard' = 'RFC_3339',
'connector' = 'kafka-0.10',
'properties.cluster' = 'your kafka cluster', --kafka 集群名
'topic' = 'your kafka topic', --kafka topic名
'parallelism' = '9',
'format' = 'json',
'sink.partitioner' = 'row-fields-hash',
'sink.partition-fields' = 'id'
);
INSERT INTO data_bmq_sink
SELECT id,
number,
time,
string,
TIMESTAMP_TO_LONG(LOCALTIMESTAMP) AS p_date
FROM union_data;
落地流程
开发&上线步骤
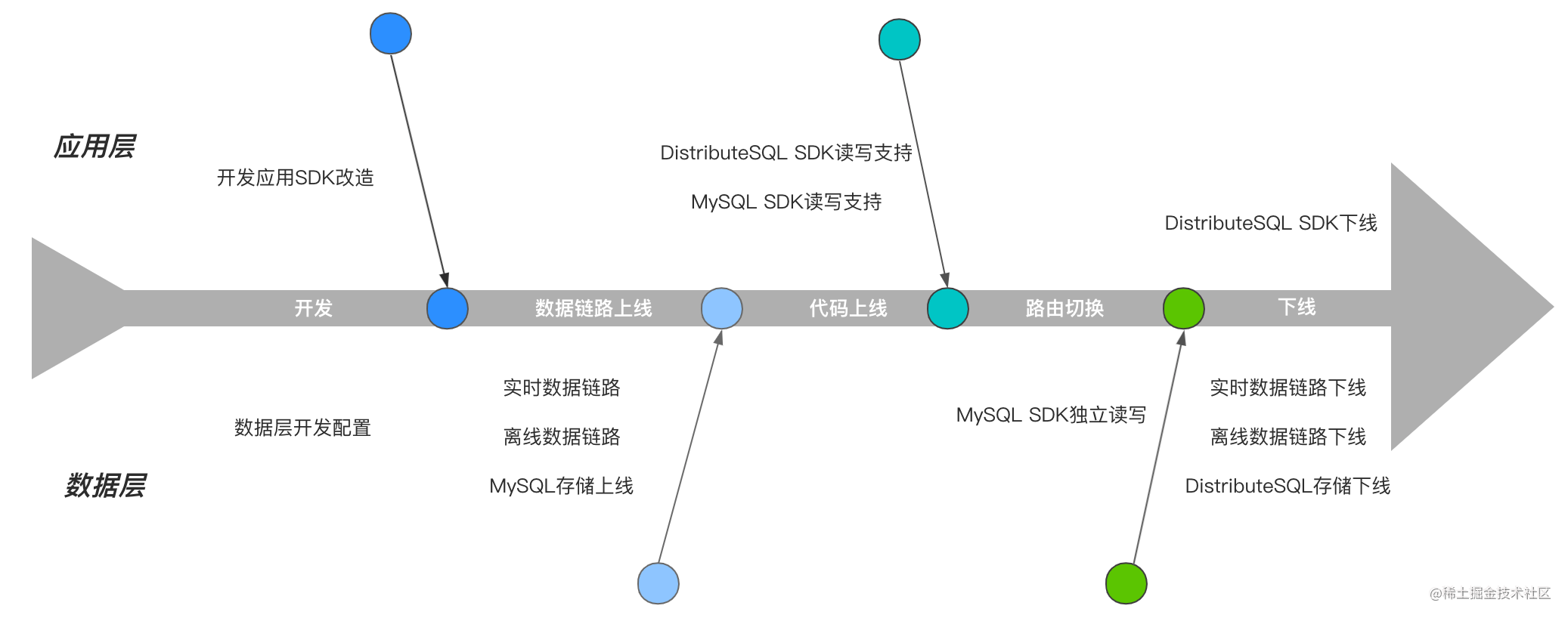
- 开发
这一阶段可以分开进行,主要是应用服务的代码SDK改造和数据层数据平台任务开发以及配置等相关工作。SDK改造是对最终接入数据源MySQL的读写支持,并在业务代码中增加路由开关为后续切换做准备,还有就是通过数据平台能力搭建离线、实时数据链路为数据迁移和同步做准备。 - 数据链路上线
当数据层开发完毕后可以先行投产,将存量数据进行同步并服役实时数据链路保持热更新效果,这些操作是完全独立的数据链路搭建和储备,对线上业务完全没有影响。 - 代码上线
当代码上线后,意味着应用层已经具备双数据存储的SDK读写能力,此时仍然对业务没有丝毫影响。 - 路由切换
此环节是最为重要的一环,也是对本次改造产生变化的影响的部分,切换成功后就意味着数据读写开始使用新存储架构进行承载,标志着方案已经成功落地,这部分的一些问题探讨可以参考下面部分。 - 下线
该部分为最终收尾环节,对于线上业务理论不存在任何影响,是对资源回收的处理。
读写一致性剖析
关于数据迁移最重要的是要保证尽量业务层无感知,通过较为完备的技术方案将所有变更带来的影响全部拦截在系统层面进行治理,核心之重充分考虑数据读写一致性问题,
| 阶段 | 读写逻辑 | 变化 | 问题 | 解决方案 |
|---|---|---|---|---|
| 开发 | [1] 业务数据读写链路:DistributeSQL Write/Read | - | - | - |
| 数据链路上线 | [1] 业务数据读写链路:DistributeSQL Write/Read[2] 业务数据同步链路:DistributeSQL -> MySQL | 业务数据源未发生切换,此时业务对数据同步链路无感知 | - | - |
| 代码上线 | [1]业务数据同步链路:DistributeSQL -> MySQL | 业务数据源未发生切换,此时业务对数据同步链路无感知; 此时具备MySQL、DistributeSQL读写能力 | - | - |
| 路由切换 | [1]业务数据读写链路:MySQL Write/Read[2]业务数据同步链路:DistributeSQL->MySQL | 业务数据读写链路从DistributeSQL切换到MySQL | 数据链路切换后,存在读写不一致的可能 | 见下方 |
| 下线 | - 业务数据读写链路:MySQL Write/Read | 下线业务数据同步链路 | - | - |
路由切换导致问题的解决方案:
-
[1] 若业务接受停机,可以短时间停止
DistributeSQL写入,等待最后一次DistributeSQL写入及同步完成立刻全量切MySQL独立读写 -
[2] 若业务不要求数据强一致,可以不用关心写入间隙的不一致问题,全量切
MySQL且同步链路留存数据完成后最终一致 -
[3] 若业务不接受停机且要求数据强一致性,需要增加数据源双读支持,若是单点离散数据可支持,若是分页或全量数据则需要做方案进行兼容或者降级能力挺过路由切换阶段带来的数据延迟风险,这部分需要更为精细化技术方案,充分评估风险并进行报备寻找资源支持
项目思考
在日常的研发工作中除了持续的业务需求迭代,还会伴随衍生出很多技术需求。
面对业务需求,除了端饭碗的技术基本功能让你完成需求任务,还需要一定程度日积月累的业务理解、敏感度甚至专业度,从而让业务需求完成的更合理、成熟,既满足当前业务需求的同时,又能由这个需求点到整个系统面来全盘思考,让一次次的迭代都尽可能完美,保持系统的健壮和稳定。
面对技术需求,情况也许更复杂一些,如果说业务需求是在和业务成本博弈,那技术需求更多的是在和自身技术储备能力博弈,既在对别人或者自身技术实践的反思,也是在对自己技术深度和广度的一次历练和考验。想一想,如果自身或者团队的能力已经用尽十八般武艺来进行技术实践,那么当前的产出物从一定程度上已经代表了最高水平,很难有突破提升的空间。
讲到这里,结合我自身的项目经历的确深有感触,就在大概两年前,我也经历过类似的项目背景,当时能力水平和如今比还是有着很大差距的,因此技术方案在今天看来非常吃力,可那已经代表了当年自身最高水平和能力,想想当年的技术方案实践真是血淋淋的教训,所有一切完全是在应用层处理,开发、上线、出问题、修问题…让人叫苦不迭。相比今日再现类似项目机会,技术思路非常清晰,能够做出合理分层,不仅仅如往日单调的应用层开发,还能引入大数据以及数据能力的开发支持。如今技术方案是有进步的,这完全得益于对数据组件能力的了解和过往实践沉淀的经验,这两年期间悉心拜读了DDI神作,不仅开拓了技术视野,还对系统理解有了新的认知,跳出了舒适区开始吃力啃大数据组件,手里的工具多了,技术方案的选择更合理,一切也就会向好,对项目、对团队、对合作伙伴、更是对自身受益匪浅。
最后想说的是,技术之路漫漫,学习不能停止,提升的过程很孤独甚至是痛苦的,但它会反哺你,让你在工作中特别是遇到困难问题时会毫不费力,不必再像往日那样身陷囹圄、耗时耗力在每一块绊脚石上,为你节省出更多时间来做更有意义的事情,让你的工作、生活变得美好起来,加速你的成长。



![[Effective Objective] 熟悉Objective-C](https://img-blog.csdnimg.cn/98eca70ef3114c42adb9cc327323e6d8.png)






![leetcode 1658. 将 x 减到 0 的最小操作数[python3 双指针实现与思路整理]](https://img-blog.csdnimg.cn/img_convert/877761c9beb16319adb1468ae697b54d.png)