Reference: http://redis.cn
用处
缓存
数据库
分布式锁(Redission的redlock,自定义的lock等)
过滤器(布隆过滤器/增强的带计数的布隆过滤器/布谷鸟过滤器等)
大规模的计算辅助(bitmap)
消息订阅/监听 --> 例如分布式的websocket发送消息时可用Redis消息订阅/监听将消息发到所有实例上进行推送
延时队列 --> 例如email发送服务中同一个email client的多封邮件发送需要一定间隔
Redis介绍及NIO原理
Redis是二进制安全的,在IO时都为字节流形式。
Redis单线程但能支持高并发的原因:多路复用。多路复用通常有epoll,select,poll等方案,默认为epoll。
epoll能大大增加处理效率原因:用户态和内核态之间提供了一个共享空间,主要有两个数据结构,一个红黑树与一个双向链表。在新的fd(file description/文件描述符)请求进来时,会增添进红黑树,处理完成后进入链表。因此在用户态与内核态通信时无需进行fd的复制,且红黑树查询效率高,用户态只需扫描链表中是否还有数据而不用扫描整个fd list。
Reference: Redis IO多路复用技术以及epoll实现原理_觉悟不晚的程序员的博客-CSDN博客_epoll
Redis的类型
共5种类型:string,list,hash,set,sorted list
type命令能根据key获得值的类型,而object encoding命令可获得redis在内部表示形式的类型。例如string类型会让部分数字value的encoding类型改为int以优化计算效率。
bitmap是string类型中的一种非常适合做大数据处理的数据结构,例如做签到统计、登陆天数计算、大量号码去重等。主要思想是利用每一个二进制位的0/1标志及每一位的index实现用最小空间小号完成统计。
可在redis client中使用 help @<数据类型> 命令查看对应的所有方法。例如 help @list
list类型数据结构为双向链表,有正向索引与反向索引。因此可从左右两边push/pop数据以实现FIFO/FILO;能够进行阻塞pop操作,当没有数据出现时阻塞x秒或一直阻塞下去。
sorted set的存储方式是跳跃表(skip list),类似于平衡二叉树,每层节点以双向链表关联,能达到平均CRUD耗时最少。增加元素时的层数为随机造层得到。
Redis的消息订阅与事务
消息订阅的监听方知能收到监听之后过来的消息,之前publish的消息都不会收到。
Redis不支持事物回滚,因为只有当命令错误时才会失败。为了性能考虑,事务失败不回滚而是继续执行余下命令。
Redis过滤器
Redis缓存过滤器为解决缓存穿透问题而生。基础思想是:把系统中已有的数据通过多个映射函数计算出几个值并向bitmap中标记,在请求时使用相同算法去砸后bitmap对应结果的位置。如果都为1则能获得“此数据可能存在”的结论,可以继续向下寻找;如果有一个为0则获得“数据必不存在”的结论。
布隆过滤器优缺点:
优点:占用空间少,使用较简单
缺点:随着数据增加,误判率增加;不能从布隆过滤器中删除元素
增强版计数器布隆过滤器(Counting Bloom Filter)能解决不能删除过滤器中元素的问题。它使用了更多空间记录了每一个位的计数,删除时所有对应位数字减一。消耗空间增加但能实现精准删除。
布谷鸟过滤器:每个元素通过算法得到一组对偶节点,存元素指纹进入其中随机一个空节点。如果都不为空则随机挤走一个,被挤走的重复计算-->挤走操作直到成功进入节点。重复过程有次数阈值限制,达到阈值则自动扩容,所有元素重新计算。布谷鸟过滤器可实现删除,但不同数据在同一节点的指纹有小概率重复,因此删除操作有误删可能。
增强的布谷鸟过滤器:每个节点能存的指纹席位扩大到4个(类似hashmap中数组链表)
Reference: Redis布隆过滤器和布谷鸟过滤器_JavaShark的博客-CSDN博客_布谷鸟过滤器
Redis解决内存空间不足的多种方案
新加数据直接报错;
LRU(Least Recently Used)算法清除最久没有碰的数据 (它又拆分位两种细化方案:从所有的数据中找/只从设置了ttl的数据中找);
LFU(Least Frequently Used)算法清除碰到次数最少的数据(同上,它也拆分位两种细化方案:从所有的数据中找/只从设置了ttl的数据中找);
清除即将过期的数据;
随机清除数据释放空间。
Redis key的过期判定
如果key设置了ttl,不会随着访问延长ttl,但如果发生对此key的写操作,则改为无过期时间;
过期时间判定有两种:
当访问时被动判定,若过期则清除;
主动周期轮询的过期检测。Redis每10秒随机抽取20个keys进行过期检测并删除所有已过期key,若>25%的key过期,再取20个重复操作直到不满足25%。(这是一个平凡的概率算法,意味着在任何给定时刻,最多会清除25%的过期key)。
Redis持久化
两种方式,RDB与AOF。在4.0版本之后AOF中包含RDB,为RDB+增量的AOF写操作记录。
两种方式能同时开启,如果同时开启则使用AOF恢复。
RDB数据恢复速度较快但易丢更多数据,AOF体量岁时间增多变大,数据恢复慢但能丢失更少数据。
RDB:通过SAVE或BGSAVE命令(BGSAVE不阻塞)。使用rdbsave和Linux的fork()方法,底层是copy-on-write导致速度快:创建子进程持久化数据,父子进程公用同一份无力存储空间,只有当数据发生改变时,改变的那个内存页会复制一份,让父子中数据出现差别,因此额外空间开销小。具有时点性,RDB进程创建那一刻的样子就是最后复制出来的样子。后续的数据改变会存入复制缓冲区中。
AOF将redis的写操作存入文件中,保存的是可读的写操作命令。每次达到一定存储量时自动使用BGREWRITEOF命令优化合并AOF命令。
在新版中支持RDB+AOF混合存储方式:老数据RDB生成二进制文件在AOF文件的开头,增量以指令形式Append到AOF文件。
Redis高可用系列
主从,哨兵和集群实现了redis高可用;
Redis每台服务器都有一个唯一的runid来标识对应服务器;
Offset记录了命令的偏移量。
Redis有4类缓冲区增强高可用。
Redis主从
将主节点的数据复制到从Redis服务器。主要为了解决单台Redis读写压力大的问题,实现读写分离(主:读写;从:只读);并达到数据备份的目的。
第一次连接从服务器或从服务器断开后进行重链接都会进行主从复制,从服务器会记录主服务器的runid。
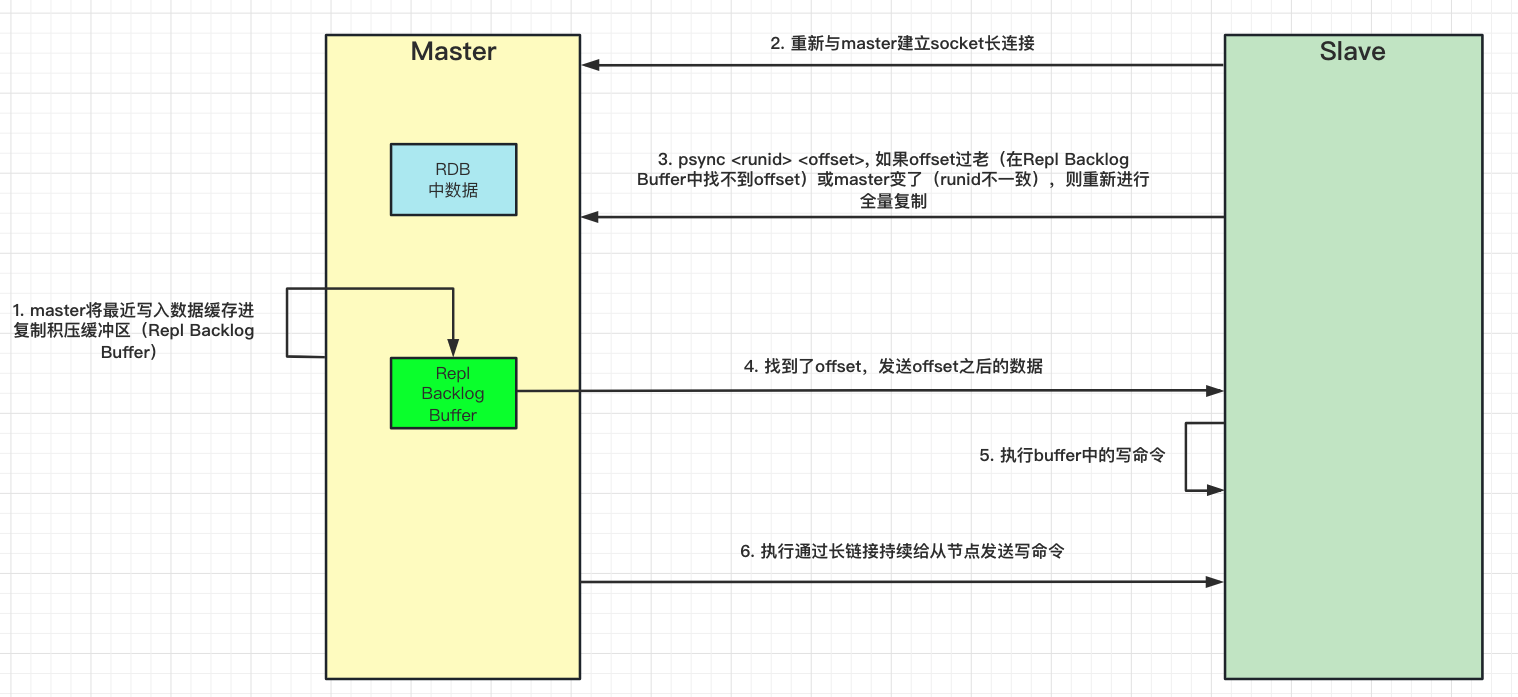
主从复制分为全量复制和增量复制。选择全量/增量复制的流程图如下

全量复制流程:
⚠️Tips: 主节点上会为每个从节点都维护一个复制缓冲区。在全量复制时,主节点在向从节点传输 RDB 文件的同时,会继续接收客户端发送的写命令请求,并保存在复制缓冲区中,等 RDB 文件传输完成后,再发送给从节点去执行。

增量复制流程:
⚠️Tips: 复制积压缓冲区是一个固定长度,先进先出的队列,默认 1MB。当主服务器进行命令传播时,不仅会将命令发送给从服务器,还会发送给这个缓冲区。
Redis的四类缓冲区
客户端输入缓冲区:暂存客户端发送过来的请求数据;Redis 主线程再从输入缓冲区中读取命令进行处理。大量数据高速请求或执行耗时操作会导致生产速度大于消费速度,最终溢出。
客户端输出缓冲区:redis处理后的输出不会直接给客户端而是放进输出缓冲区,防止客户端消费慢阻塞redis。若服务端大量数据快速处理后返回导致消费速度大于客户端接受速度,导致溢出。可以通过`client-output-buffer-limit`参数来调整缓冲区大小。
复制缓冲区:主节点上会为每个从节点都维护一个复制缓冲区。在全量复制时,主节点在向从节点传输 RDB 文件的同时,会继续接收客户端发送的写命令请求,并保存在复制缓冲区中,等 RDB 文件传输完成后,再发送给从节点去执行。若从节点接收和加载 RDB 较慢,同时主节点接收到了大量的写命令则溢出,也可通过`client-output-buffer-limit`参数来调整缓冲区大小。
复制积压缓冲区:为增量主从复制服务。它是一个固定长度,先进先出的队列,默认 1MB。当主服务器进行命令传播时,不仅会将命令发送给从服务器,还会发送给这个缓冲区。不会溢出。可通过`repl_backlog_size`参数调整大小。
Redis哨兵模式
TODO
Redis集群
TODO