作者介绍
陕西移动信息技术部 张云川
陕西移动信息技术部 王永强
新炬网络中北三部 张建
随着国家对自主可控战略的深入推进,笔者所在省份聚焦数据库国产化替换,全面加速数据库国产化替换进程。以核心系统带动周边系统,成功在能力运营中心、CRM等核心系统中引入了国产数据库。为确保替换工作万无一失,我们精心制定了渐进式迁移的六步策略,确保每一步都稳健而有序,为数据库的顺利替换提供坚实保障。
一、渐进式迁移方案
第一阶段:部署
目前我们主要采用了AntDB6.3.9版本,操作系统为BC Linux For Euler 21.10,为保障可用性,采用了一主两备架构部署,其中一个副本异机房部署,避免环境因素导致的不可用。
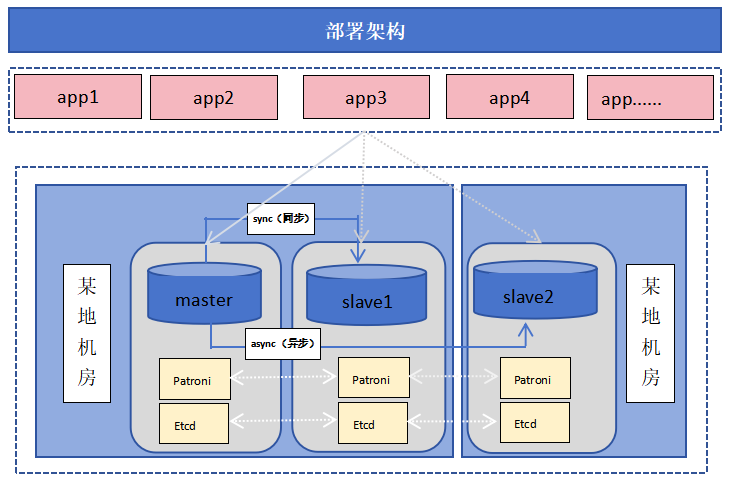
第二阶段:测试
根据应用对数据库高性能、高并发、跨数据中心容灾能力等特性要求,对目标产品进行12大类67项数据库技术特性的多轮交叉测试。测试内容包括但不限于功能验证、兼容性测试、性能测试、压力测试、高可用测试、扩展性测试、灾备测试、运维管理、生态工具、安全管理等。
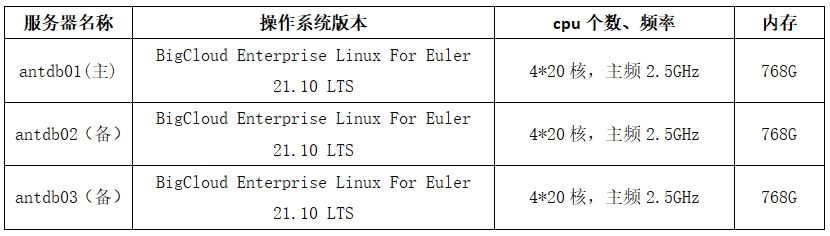
机器配置情况:
1. 压力测试
在笔者的参数配置和硬件环境下测试数据如下:
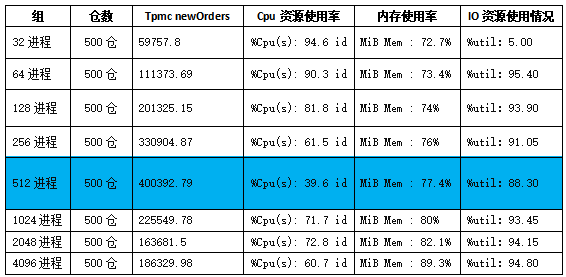
测试结论:
根据测试数据分析,仓数为500仓,进程数在32-512区间,cpu、内存使用率与订单处理量持续增长;进程数达到512时,tpcc orders最高达到400000,达到性能峰值;进程数512-4096时,CPU与内存使用率同步增长,但磁盘IO承载达到上限,可以看到tpmc orders的值持续回落伴随CPU上下文频繁切换,说明负载已经达到测试极限。
基于本次测试的服务器配置及结果分析,我们推荐设置的参数值设定分享如下:
1)shared_buffers 参数
参数说明:
设置数据库服务器使用共享内存缓冲区的大小。
经验参考:
shared_buffers设置为物理内存的40%,同时AntDB同样依赖操作系统的高速缓冲区。
建议设置为shared_buffers = '200GB'
2)effective_cache_size 参数
参数说明:
优化器假设可以用于单个查询的磁盘缓存的有效大小,值越大,使用索引扫描的可能性就越大;值越小,使用顺序扫描的可能性就越大。
经验参考:
-
effective_cache_size = RAM * 0.7
-
这个参数不会影响分配给AntDB的共享内存,也不保留内核磁盘缓存,只是用于优化器的评估目的。
-
参数effective_cache_size通知优化器,系统提供多大的cache,cache包括内存、文件系统、cpu的cache等,是这些cache的总和。
建议设置为effective_cache_size=‘400GB’
3)max_wal_size 参数
参数说明:
设置2个自动checkpoint之间允许增长最大的wal日志的大小,默认为1GB,使用方法依赖checkpoint的操作频率,checkpoint频率太快设置得大一些,会提升性能,但也是会消耗更多空间,同时会延长崩溃恢复所需要的时间。
经验参考:
-
使用select pg_current_wal_lsn()(pg10.x版本)查看实际的WAL位置。
-
启用log_checkpoints=on,然后从服务器日志中提取信息(每个完成的检查点将有详细的统计信息,包括WAL的数量)。
建议设置为max_wal_size = '64GB'
4)checkpoint_completion_target 参数
参数说明:
该参数使AntDB尽可能慢地去写脏数据,在checkpoint_completion_target*checkpoint_timeout。
设置的时间内,使IO操作(写数据到磁盘)的更慢点,同时留给部分IO操作给其他任务。
经验参考:
通常设置0.5-0.9之间,是防止巨大的I/O写入,巨大的IO写入会严重影响并发的查询性能。该参数的设置,主要依赖2个条件,一个是shared_buffer的大小,另外就是磁盘的IO带宽,IO越高该参数设置的越大。同样100G的shared_buffer脏数据在高IO和低IO的场景下,相同的heckpoint_timeout是所设置的checkpoint_completion_target是不一样的,高IO的设置的就大一点,低IO的就设置的小一点缓解checlpoint的时候造成的间歇性的IO波动。
建议设置为checkpoint_completion_target = '0.9'
5)checkpoint_timeout 参数
参数说明:
自动WAL检查点之间的最长时间(默认为5分钟),增加此参数可能会增加崩溃恢复所需的时间。
经验参考:
设置该参数需要评估1分钟产生wal日志尺寸,在结合平均磁盘刷写的IO速度,和磁盘每秒写入次数。
建议设置为checkpoint_timeout = '15min'
6)wal_keep_size 参数
参数说明:
在复制环境中,保存在pg_wal目录中wal日志文件段的数量,以防止stadnby服务器进行流复制所需的wal日志被主库删除。
经验参考:
依赖于wal日志产生的速度和磁盘空间的大小,太大浪费空间,太小wal日志会被删除。
建议设置为wal_keep_size = '512GB'
7)max_parallel_maintenance_workers 参数
参数说明:
数据库执行vacuum、create index时,能够启动的并行worker最大数目。
经验参考:
通常设置低于8,并行worker从max_worker_processes创建的进程池中取出,数量由max_parallel_workers控制,资源限制由maintenance_work_mem控制。
建议设置为max_parallel_maintenance_workers = '8'
8)max_parallel_workers 参数
参数说明:
数据库最大并行worker的数量,不能超过max_worker_processes的数量。
经验参考:
依赖于服务器的cpu资源,不要超过cpu的核心数的一半,尽量使的每个核心都运行一个任务,不能出现cpu资源争抢或者排队的情况。
建议设置为max_parallel_workers = '128'
9)max_parallel_workers_per_gather参数
参数说明:
设置单个Gather或者Gather Merge节点能够工作的workers的最大数量。并行workers会从max_worker_processes建立的进程池中取得,数量由max_parallel_workers限制。
经验参考:
默认为2,开启大表的并行在执行计划中就可以看到Gather或者Gather Merge的节点,同时会占用更多的资源,消耗更多的CPU资源和I/O带宽,建议默认即可。
建议设置为max_parallel_workers_per_gather = '2'
10)maintenance_work_mem参数
参数说明:
维护性操作(例如VACUUM,CREATE INDEX和ALTER TABLE ADD FOREIGN KEY)中使用的最大的内存量。
经验参考:
-
maintenance_work_mem和该参数autovacuum_work_mem很像,没有设置autovacuum_work_mem,默认值是-1,则使用maintenance_work_mem的设置值,maintenance_work_mem的总内存消耗等于maintenance_work_mem*autovacuum_max_workers。
-
该参数为user类型的,全局设置为4GB,满足普通的小表的维护向操作,进行大表的维护性操作,可以进行会话级别的设置,加速大表的维护性操作。
-
该参数最好与autovacuum_work_mem分开设置,避免维护性操作与清理操作共享内存,降低性能。
建议设置为maintenance_work_mem = '4GB'
11)bgwriter_delay参数
参数说明:
将shared_buffers中的脏数据使用bgwriter进程写入磁盘,执行“脏数据”写入时候的延迟值。默认为200ms。即此次写入操作执行完后等待200ms继续下次脏数据写入。
经验参考:
控制Bgwriter进程写入脏数据的频率,IO性能高的设置的小一点,IO性能差的设置大一些,脏数据占用共享缓冲区也多一些。
建议设置为bgwriter_delay = '10ms'
12)autovacuum_max_workers参数
参数说明:
Autovacuum清理的最大进程数,和数据库数目有关系,做到每个库都有一个清理进程去工作,太少的话会在下一个周期去清理没清理的库,每一个autovacuum_max_workers的进程都要消耗maintenance_work_mem的值对应的内存大小,例如maintenance_work_mem = 64MB时,autovacuum_max_workers = 3 需要消耗64*3=192MB内存。autovacuum_max_workers = 4 需要消耗64*3=256MB内存。
经验参考:
如果只有一个活跃业务db,那么不管设定的autovacuum_max_workers多大,永远只会启动一个worker来对该db进行清理。如果有多个活跃业务db,单纯提高autovacuum_max_workers而不提高autovacuum_vacuum_cost_limit(默认值为vacuum_cost_limit,即200)的值也没有用。原因是autovacuum_vacuum_cost_limit对成本的限制是全局的,该参数控制了PostgreSQL实例所有worker在运行时可达到的“成本”上限,其计算公式为:
autovacuum_vacuum_cost_limit/autovacuum_max_workers。一旦达到成本上限,worker就会进入休眠,sleep时间为参数vacuum_cost_delay所设定的值(然后再继续处理)。
建议设置为autovacuum_max_workers = '5'
13)autovacuum_analyze_scale_factor参数
参数说明:
声明在判断是否触发一个ANALYZE时增加到autovacuum_analyze_threshold 参数里面的表尺寸的分数,比如100行的表垃圾数据的行数就是1行。
经验参考:
-
区分小表和大表,小表使用系统级别设置就满足需求,大表则不能依赖这样的设置。大表需要设置单独的表存储参数,来进行垃圾清理,比如:
autovacuum_vacuum_threshold,autovacuum_vacuum_threshold (integer)autovacuum_vacuum_scale_factorautovacuum_vacuum_scale_factorautovacuum_analyze_threshold autovacuum_analyze_scale_factor autovacuum_vacuum_cost_delay, autovacuum_vacuum_cost_delayautovacuum_vacuum_cost_limit, autovacuum_vacuum_cost_limit
-
建议多使用分区表来存储数据,每个分区不要超过32G。
-
业务不繁忙的时候手动进行垃圾清理或者脚本定时任务,设置合理的表的年龄,清理长事务。
建议设置为autovacuum_analyze_scale_factor = '0.01'
14)autovacuum_analyze_threshold参数
参数说明:
声明在任何表里触发ANALYZE所需最小的行插入、更新、删除数量
经验参考:
-
首先autovacuum是一个重IO操作。
-
区分小表和大表,小表使用系统级别设置就满足需求,大表则不能依赖这样的设置。
-
大表需要设置单独的表存储参数,来进行垃圾清理,比如:
autovacuum_analyze_threshold autovacuum_analyze_scale_factor autovacuum_vacuum_cost_delay autovacuum_vacuum_cost_limit
-
经常查看AntDB的CSV日志,如果发现有大量的automatic analyze of table x.x.x.x,需要设置autovacuum_analyze_threshold的参数值。
建议设置为autovacuum_analyze_threshold = '1000'
15)autovacuum_naptime参数
参数说明:
在每次执行完一次自动清理操作后,autovacuum 进程会等待 autovacuum_naptime 指定的时间,然后再开始下一次清理操作。
经验参考:
-
区分大表和小表,在小表比较多的情况下设置1-2min,在大表比较多的时候设置为5min甚至更长。
-
经常查询表pg_stat_progress_analyze/pg_stat_progress_vacuum,了解autovacuum的情况。
建议设置为autovacuum_naptime = '1min'
16)autovacuum_vacuum_cost_delay参数
参数说明:
声明将在自动VACUUM操作里使用的开销延迟数值。
经验参考:
-
首先autovacuum是一个重IO操作。
-
限制清理worker在清理过程中到达最大的清理成本的时候需要将清理worker休息或者暂停一下。
-
可以查询pg_stat_user_tables里面的字段n_dead_tup,如果这个一直在增长,就需要减小该参数的暂停时间,加速清理。
建议设置为autovacuum_vacuum_cost_delay = '10ms'
17)autovacuum_vacuum_cost_limit参数
参数说明:
声明将在自动VACUUM操作里使用的开销限制数值。
经验参考:
-
autovacuum所有清理worker扫描页累计起来的成本。
-
区分普通磁盘和固态磁盘,普通磁盘与固态磁盘在设置该参数的时候有区别,普通磁盘就2000-4000,固态磁盘可以达到20000甚至更高。
-
可以给大表的设置的不同的存储参数,比如autovacuum_vacuum_cost_limit。
建议设置为autovacuum_vacuum_cost_limit = '4000'
18)autovacuum_vacuum_scale_factor参数
参数说明:
声明在判断是否触发一个VACUUM时增加到autovacuum_vacuum_threshold参数里面的表的行数。
经验参考:
-
默认值设置太小,意义对大表来说太大了,清理行数太多,容易造成瞬时IO波动。
-
可以给大表设置的不同的存储参数,比如autovacuum_vacuum_scale_factor。
-
区分普通磁盘和固态磁盘,普通磁盘设置太高,清理垃圾数据多了,IO操作就加重,影响其他任务正常操作,而ssd会设置的比较高,有利于垃圾数据清理。
建议设置为autovacuum_vacuum_scale_factor = '0.01'
19)autovacuum_vacuum_threshold参数
参数说明:
声明在任何表里触发VACUUM所需最小的行更新或删除数量。
经验参考:
-
默认值设置太小,意义对大表来说太大了,清理行数太少,容易触发清理worker启动,表的脏数据有变化,有触发操作,对清理没有意义。
-
可以给大表的设置的不同的存储参数,比如autovacuum_vacuum_threshold。
-
区分普通磁盘和固态磁盘,普通磁盘设置不能抬高,ssd会设置得比较高。
建议设置为autovacuum_vacuum_threshold = '1000'
20)work_mem参数
参数说明:
写到临时磁盘文件之前被内部排序操作和哈希表使用的内存量。
经验参考:
-
对于复杂查询,并行运行好几个排序或者哈希操作,每个操作都会被允许使用这个参数指定的内存量,然后才会开始写数据到临时文件。
-
explian的时候出现quicksort memory,work_mem设置正确。
-
多个正在运行的会话进行并发的操作。被使用的总内存可能是work_mem值的好几倍。
建议设置为work_mem=”16MB”
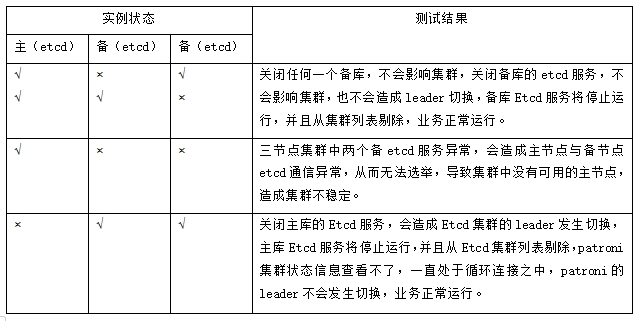
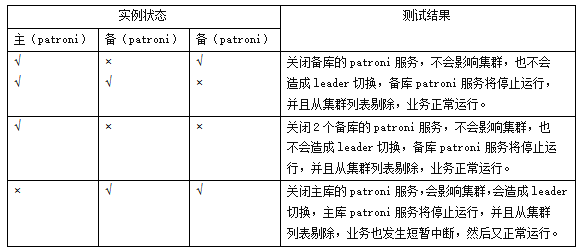
2、高可用测试

3、业务测试
测试环境:BigCloud Enterprise Linux For Euler 21.10 LTS,部署ESB应用进行测试
测试结果统计信息:
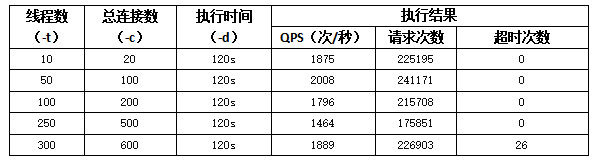
统计业务的成功率:99.99%;及时率:15ms内,26笔超时原因为业务本身接口响应耗时长,超过该业务的接口熔断时间导致,不影响测试结论,符合业务迁移上线条件。
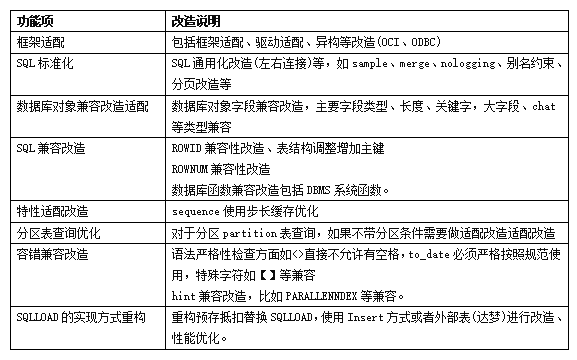
第三阶段:改造
改造的重点工作为应用的SQL代码语法适配改造和存储过程改造,既要兼容原数据库的使用习惯和语法,又要考虑应用的改造成本; 通过兼容性测试输出评估报告,明确改动范围,进行适配改造工作量评估,合理安排工作计划。结合映射指导手册、数据库开发规范,完成SQL、函数、存储过程、视图等适配改造测试验证工作,经业务测试确认符合要求。
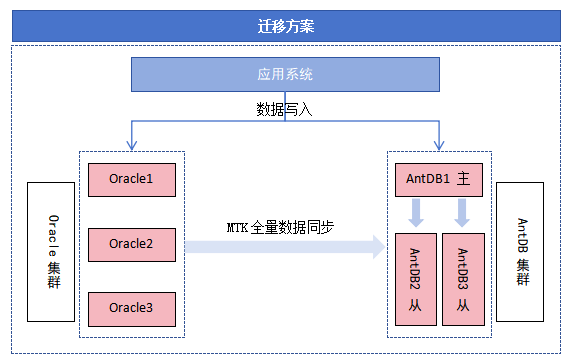
第四阶段:迁移
为了避免对原有生产业务造成影响且保证迁移数据的严格一致性,采用了MTK全量+DSG增量的方式,对于源数据库集群,提前2天启动数据迁移链路,在全量数据迁移之后DSG会启动增量数据拉取模块,拉取源实例的增量更新数据并解析、封装、存储在本地。当全量数据迁移完成后,DSG会启动增量日志回放模块,从增量日志读取模块中获取增量数据,经过反解析、过滤、封装后迁移到目标实例,通过目标端主键保证数据的唯一性。
第五阶段:上线
通过双写机制实现新老数据库之间双向同步,为了降低上线风险,制定了分批流量切换策略,通过F5将业务流量依次放大进行分批切换,依次进行生产应用节点升级加入、滚动替换、分流操作切换到国产数据库中。
在上线后原系统及双写仍然保留一段时间,通过双写实现新系统到原系统的数据单向同步,确保两个系统数据的一致性,具备回切能力。根据业务使用反馈,平稳运行一段时间后,断开双写,下线原系统。
第六阶段:监控
我们也建设了数据库统一运维平台,对新上线的数据库进行统一接入。重点对数据库运行性能进行监控,通过全面的数据库监控以及负载分析能力确保数据库的统一管理和最佳性能。
目前,平台已经提供对Oracle、AntDB、GoldenDB、MySQL、GaussDB、OceanBase等多种数据库统一管理的能力。
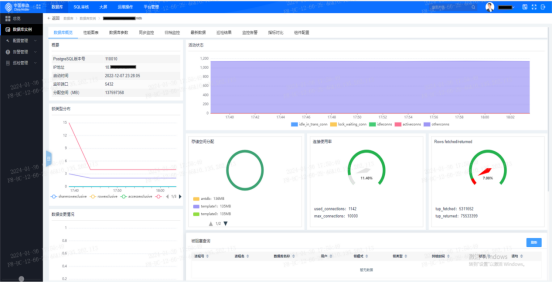
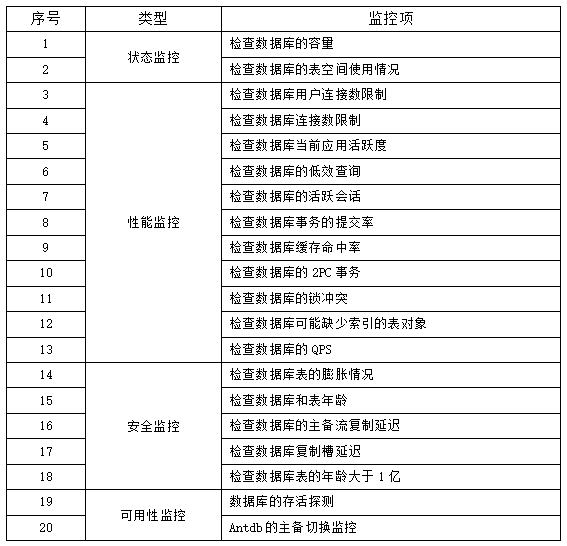
AntDB数据库主要涉及监控点:
二、典型问题及解决办法
1.merge语法不支持
单条SQL语句以Megre关键字开头插入数据的SQL语句,AntDB不支持关键字Megre的写法。
解决办法:使用AntDB的类似语法Insert.......... on conflict do进行SQL语法改写。
2.长连接占用大量内存不释放
AntDB会缓存当前会话访问过对象元数据,如果某个会话从启动以来,对数据库中所有的对象都有过查询的动作,那么这个会话需要将所有的对象定义都缓存起来,将会占用较大的内存。
解决办法1:对于长连接,建议空闲一段时间后,自动释放连接。同时建议提供SQL语法给用户,允许用户自主的释放cache。
解决办法2:优化relcache的管理,为relcache等缓存提供LRU管理机制,限制总的大小,淘汰不经常访问的对象。
3.buff/cache的占用率高
在操作系统层面使用free -g看到buff/cache占用很高,由于参数effective_cache_size设置偏高,导致占用系统内存偏高,对参数effective_cache_size进行调小设置。
解决办法:设置为内存的1/2是比较保守的设置,设置为内存的3/4是推荐的值。
4.Mtk程序出现org.h2jdbc.JdbcSQLTimeoutException: Timeout trying to lock table{0}
源端Oracle表数目过多,Mtk在扫描表时迟迟无法扫描结束,导致其他Mtk进程有访问该表造成死锁;Mtk在遍历Oracle表名时,由于表的数目偏多,在Mtk源代码中关于遍历表的列表或者hash偏小导致的。
解决办法:使用更快的Mtk(antcdc-db-sync.tar)扫描包替换原有Mtk包,重启服务,运行通过。
5.单机多实例的mtk安装问题
安装在不同用户下面存在/tmp/vertx-cache权限拒绝问题,不能临时修改该文件权限。
解决办法:在启动的时候不需要启动kafkasql进程(仅适用于全量迁移)。
6.ERROR:INVALID byte sequence for encoding ""UTF8"": 0X00
Oracle 和 MySQL 支持存储(0x00)字符,但是AntDB-T会报ERROR: invalid byte sequence for encoding."UTF8":0x00..
解决办法1:AntDB-T 字段类型改为bytea,需要业务侧考虑影响。
解决办法2:AntDB-MTK支持使用replaceAll将0x00 即\u0000替换为空字符串,需要在配置文件config/application.properties新增或调整为replace.zero.char=true,重启管理工具使配置生效,任务需要重新配置。
7.Mtk在创建数据迁移时出现错误Ora-00942
在对Oracle 19.7非pdb模式下,使用Antdb Mtk迁移数据时,触发Ora-00942错误,错误信息为表或者视图不存在。
Mtk在对Oracle数据迁移时会对Oracle的一些字典表授权进行查询,比如ALL_TABLES 、ALL_CONSTRAINTS 、ALL_MVIEWS、ALL_VIEWS、ALL_USERS....,但是在19c非pdb版本中,MTK工具目前对权限的管控还有进一步优化提升的地方,使用原有字典表刷权限的方法不能解决该场景问题。
解决办法1:授权dba权限,但权限过大,不符合生产权限管理办法。定为临时解决方案。
解决办法2:协调厂商及时修复,输出最小化权限列表。
8.Pip3 list出现no moudle pip._internal问题
在部署AntDB的高可用组件Etcd和Patroni之后,会使用pip/pip3 list来检查所安装python安装包,在执行pip3 list的时候出现no moudle pip._internal。
在主机服务器入网时,需进行安全基线扫描,其中包含“在/etc/profile 文件尾存在umask 027则合规,否则不合规”。
系统之后创建文件是会有一个默认权限,那么这个权限是怎么来的呢?这就是umask干的事情。umask用于设置用户创建文件或者目录的默认权限,umask设置的是权限的“补码”,而我们常用chmod设置的是文件权限码。
解决办法:在进行安全基线配置的时候着重注意该条目,保证文件和目录的权限不发生变化。
三、总结
目前国产数据库已在多个业务系统上线使用,经过扎实准备和测试验证,迁移过程无一例回切,上线后经受住了业务环节的严苛考验,满足核心生产要求,更加坚定了我们继续前进的信心。另外,我们也通过迁移实践积累了宝贵的数据库替换经验,形成了一套完整且系统化的改造方案,为后续其他业务系统迁移奠定了基础。
关于亚信安慧AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,服务国内24个省市自治区的数亿用户,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行超十年,并在通信、金融、交通、能源、物联网等行业成功商用落地。