前言
在前面的小节中,我们已经给大家介绍了Elasticsearch中文档的相关概念,想必有些同学都已经忘记了,那我们一块儿再来回顾下,文档即索引库中某个类型下的数据,会根据规则创建索引,将来用来搜索。可以类比做数据库中的每一行数据。本章节袁老师继续带领同学们来探索Elasticsearch文档操作的相关内容。

一. 文档增删改查操作
1.新增文档
1.1 新增文档并随机生成id
通过POST请求,可以向一个已经存在的索引库中添加文档数据。
语法格式:
POST /索引库名/类型名
{
"key":"value"
}演示示例:
POST /yx/goods
{
"title": "小米手机",
"images": "http://image.yx.com/12479122.jpg",
"price": 2699.00
}响应结果:
{
"_index": "yx",
"_type": "goods",
"_id": "v0aZtYIBep1a4UbIQ74E",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}上述代码运行结果见下:

另外,需要注意的是,在响应结果中有一个_id字段,这个就是这条文档数据的唯一标识,以后的增删改查都依赖这个id作为唯一标识。
可以看到id的值为v0aZtYIBep1a4UbIQ74E,这里我们新增时没有指定id,所以是ES帮我们随机生成的id。
1.2 新增文档并自定义id
如果我们想要自己新增的时候指定id,可以这么做。
语法格式:
POST /索引库名/类型/id值
{
...
}演示示例:
POST /yx/goods/1
{
"title": "大米手机",
"images": "http://image.yx.com/12479122.jpg",
"price": 2899.00
}响应结果:
{
"_index": "yx",
"_type": "goods",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}上述代码运行结果见下:
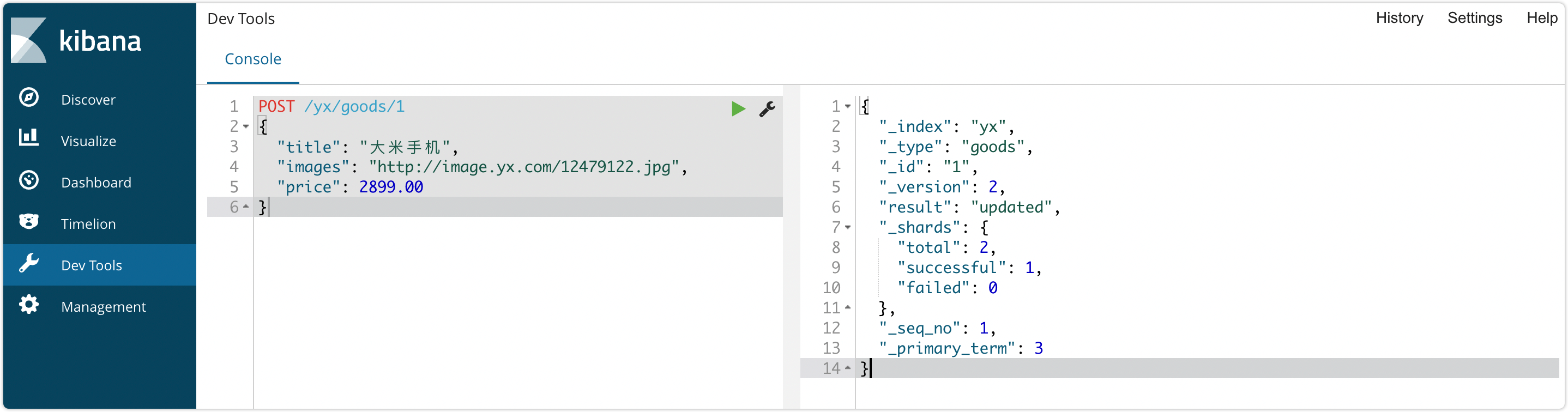
通过运行的响应结果可以看出,新增的文档数据的`_id`字段的取值为1,表明自定义分配id值生效。
2.查看文档
根据Rest风格,新增是POST,查询是GET,不过查询一般都需要条件,这里我们把刚刚生成数据的id带上。
通过Kibana查看数据:
GET /yx/goods/v0aZtYIBep1a4UbIQ74E响应结果:
{
"_index": "yx",
"_type": "goods",
"_id": "v0aZtYIBep1a4UbIQ74E",
"_version": 1,
"found": true,
"_source": {
"title": "小米手机",
"images": "http://image.yx.com/12479122.jpg",
"price": 2699
}
}属性说明:
| 属性 | 描述 |
| _source | 源文档信息,所有的数据都在里面 |
| _id | 这条文档的唯一标识 |
自动生成的id,长度为20个字符,URL安全,Base64编码,GUID(全局唯一标识符)分布式系统并行生成时不可能会发生冲突。
在实际开发中不建议使用ES生成的id,太长且为字符串类型,检索时效率低。建议将数据表中唯一的id,作为ES的文档id。
3.修改数据
PUT表示修改文档。不过修改必须指定id。分为以下两种情况:
- 如果id对应的文档存在,则修改。
- 如果id对应的文档不存在,则新增。
比如我们使用id为2不存在的一个id,则是新增数据:
PUT /yx/goods/2
{
"title": "玉米手机",
"images": "http://image.yx.com/12479122.jpg",
"price": 3899.00,
"stock": 100,
"saleable": true
}响应结果:可以看到输出结果中的result属性的取值为created ,表示是新增数据操作。
{
"_index": "yx",
"_type": "goods",
"_id": "2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}上述代码运行结果见下:

我们再次执行刚才的请求,不过把数据调整一下:
PUT /yx/goods/2
{
"title": "大米手机",
"images": "http://image.yx.com/12479133.jpg",
"price": 4899.00,
"stock": 200,
"saleable": true
}查看结果:可以看到输出结果中的result属性的取值为updated,表示是更新数据操作。
{
"_index": "yx",
"_type": "goods",
"_id": "2",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}上述代码运行结果见下:

4.删除数据
4.1 删除数据操作
删除使用DELETE请求,同样需要根据id进行删除。语法格式:
DELETE /索引库名/类型名/id值演示示例:
DELETE /yx/goods/2响应结果:
{
"_index": "yx",
"_type": "goods",
"_id": "2",
"_version": 3,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}上述代码运行结果见下:

4.2 删除数据出错问题
4.2.1 问题原因
在执行删除数据操纵提示如下错误。
{
"error": {
"root_cause": [
{
"type": "cluster_block_exception",
"reason": "blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"
}
],
"type": "cluster_block_exception",
"reason": "blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"
},
"status": 403
}经查阅资料发现,此问题是由于ES数据存储磁盘剩余空间过少导致的。即ES存在一种flood_stage的机制。默认的磁盘空间设置为95%,当磁盘占用超过此值阈值时,将会触发flood_stage机制,ES强制将各索引index.blocks.read_only_allow_delete设置为true,即ES索引均被设置为仅允许只读只删,不允许新增。
4.2.2 解决方法
1.在kibana中执行以下命令。
PUT /yx/_settings
{
"index.blocks.read_only_allow_delete": null
}说明:执行完以后,无需重启。
2.或者主机上直接执行如下命令。
(1) 在主机上直接执行此命令。
curl -XPUT -H "Content-Type: application/json" http://localhost:9200/_all/_settings -d '{"index.blocks.read_only_allow_delete": null}'(2) 在主机上直接执行此命令。
curl -X PUT "localhost:9200/twitter/_settings?pretty" -H 'Content-Type: application/json' -d'
{
"index.blocks.read_only_allow_delete": null
}
'说明:以上两种方式二选其一。
二. 智能判断
刚刚我们在新增数据时,添加的字段都是提前在类型中定义过的,如果我们添加的字段并没有提前定义过,能够成功吗?
事实上Elasticsearch非常智能,你不需要给索引库设置任何mapping映射,它也可以根据你输入的数据来判断类型,动态添加数据映射。
演示示例:我们额外添加stock库存、saleable是否上架、subTitle副标题这3个字段。
POST /yx/goods/2
{
"title":"IPhone手机",
"images": "http://image.yx.com/12479122.jpg",
"price": 6299.00,
"stock": 200,
"saleable": true,
"subTitle": "IPhone 15 Pro"
}响应结果:
{
"_index": "yx",
"_type": "goods",
"_id": "2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}上述代码运行结果见下:

查询yx索引库:
GET /yx响应结果:
{
"yx": {
"aliases": {},
"mappings": {
"goods": {
"properties": {
"images": {
"type": "keyword",
"index": false,
"store": true
},
"price": {
"type": "float"
},
"saleable": {
"type": "boolean"
},
"stock": {
"type": "long"
},
"subTitle": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"title": {
"type": "text",
"store": true,
"analyzer": "ik_max_word"
}
}
}
},
"settings": {
"index": {
"creation_date": "1660814323683",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "6WjjnjWwSs6HAoN4tM_XnQ",
"version": {
"created": "6020499"
},
"provided_name": "yx"
}
}
}
}通过响应结果可以发现stock、saleable、subTitle字段都被成功添加到了yx索引库中的映射中。
在对subTitle字段做数据初始化的时候,设置的是字符串类型数据,ES无法智能判断,它就会存入两种字段类型。例如:
- subtitle:text类型
- subtitle.keyword:keyword类型
这种智能映射,底层原理是动态模板映射,如果我们想修改这种智能映射的规则,其实只要修改动态模板即可。
三. 动态模板
1.动态模板介绍
动态模板允许您更好地控制Elasticsearch如何在默认动态字段映射规则之外映射数据。通过将动态参数设置为true或runtime,可以启用动态映射。然后,您可以使用动态模板定义自定义映射,这些映射可以应用于基于匹配条件动态添加的字段:
- match_mapping_type:对Elasticsearch检测到的数据类型进行操作。
- match和unmatch :使用模式匹配字段名。
- path_match和path_unmatch:在字段的全点路径上操作。
- 如果动态模板未定义match_mapping_type、match或path_match,则不会匹配任何字段。您仍然可以在批量请求的dynamic_templates部分中按名称引用模板。
在映射规范中使用{name}和{dynamic_type}模板变量作为占位符。
提醒:只有当字段包含具体值时,才会添加动态字段映射。当字段包含null或空数组时,Elasticsearch不会添加动态字段映射。如果在dynamic_template中使用了null_value选项,那么它只会在第一个具有该字段具体值的文档被索引之后才会被应用。
动态模板指定为命名对象数组:
"dynamic_templates": [
{
"my_template_name": {
... match conditions ...
"mapping": { ... }
}
},
...
]1.模板名称可以是任何字符串值。
2.匹配条件可以包括以下任一项:match_mapping_type、match、match_pattern、unmatch、path_match、path_unmatch。凡是符合条件的未定义字段,都会按照这个规则来映射。
3.匹配字段应使用的映射。
2.动态模板案例
举例,我们可以把所有未映射的string类型数据自动映射为keyword类型。
PUT ytr
{
"mappings": {
"goods": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
},
"dynamic_templates": [
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword",
"index": false,
"store": true
}
}
}
]
}
}
}在这个案例中,我们定义了两个映射配置:
- title字段:统一映射为text类型,并制定分词器。
- 其它字段:只要是string类型,统一都处理为keyword类型。
这样,未知的string类型数据就不会被映射为text和keyword并存,而是统一以keyword来处理。我们试试看新增一个数据:
POST /ytr/goods/1
{
"title": "大米手机",
"images": "http://image.yx.com/12479122.jpg",
"price": 3299.00
}上述代码运行结果见下:

我们只对title做了配置,现在来看看images和price会被映射为什么类型。
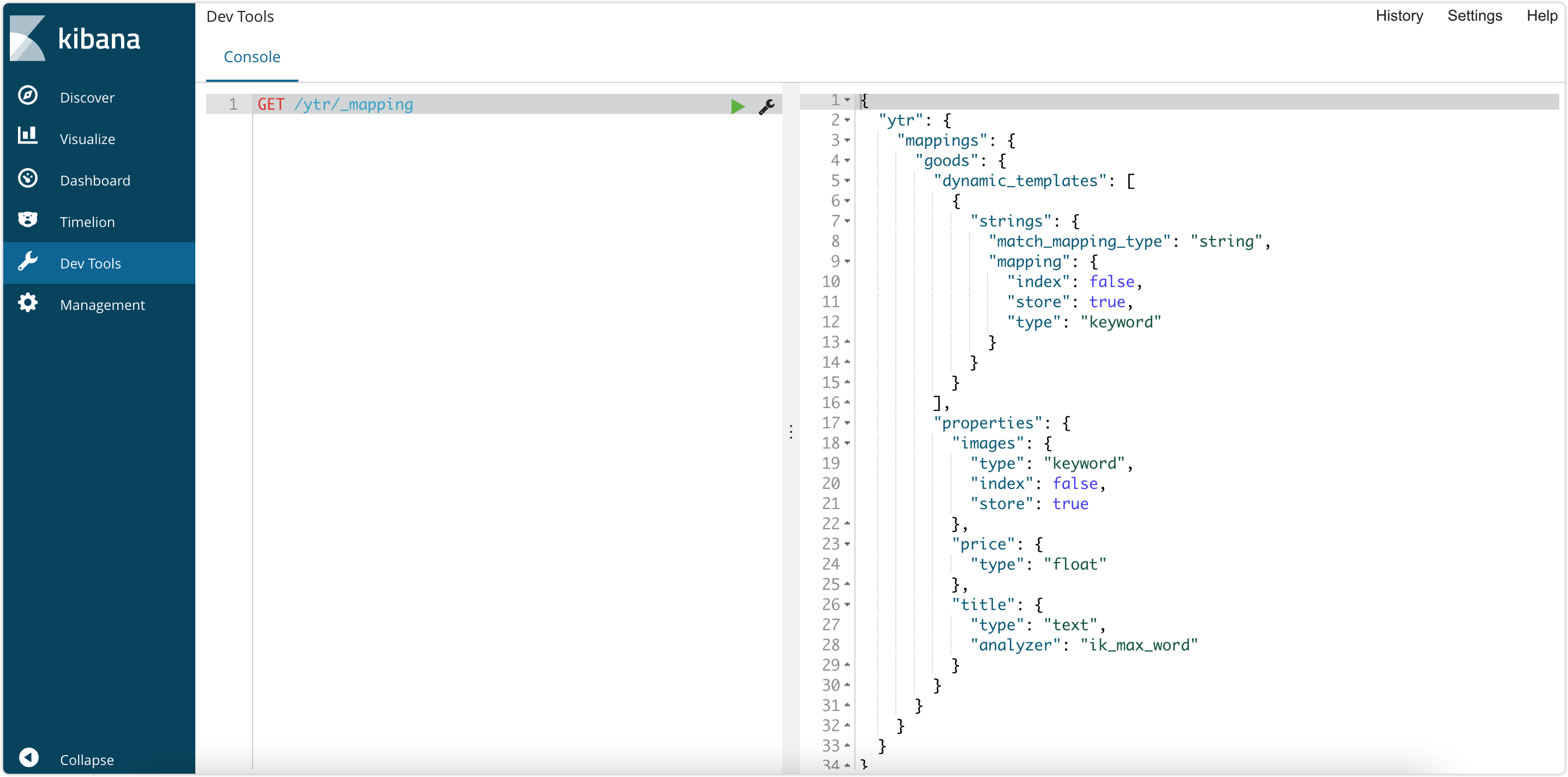
GET /ytr/_mapping响应结果:
{
"ytr": {
"mappings": {
"goods": {
"dynamic_templates": [
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"index": false,
"store": true,
"type": "keyword"
}
}
}
],
"properties": {
"images": {
"type": "keyword",
"index": false,
"store": true
},
"price": {
"type": "float"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
}可以看到images被映射成了keyword,而非之前的text和keyword并存,说明我们的动态模板生效了。
上述代码运行结果见下:
四. 结语
这一章节的内容比较多,赶紧趁热打铁复习下所学的内容。首先,介绍了在ES中文档的增删改查的操作;然后,介绍了ES的智能判断,动态添加数据映射。最后,介绍了ES中的动态模板相关的语法并进行了案例演示。其中,涉及了一些语法和概念,需要去加深记忆和巩固。这一章节的内容,就给大家介绍到这里,那就期待袁老师的下一篇文章吧。
今天的内容就分享到这里吧。关注「袁庭新」,干货天天都不断!