Multiview Neural Surface Reconstruction by Disentangling Geometry and Appearance
主页:https://lioryariv.github.io/idr/
论文:https://arxiv.org/abs/2003.09852
代码:https://github.com/lioryariv/idr
效果展示

idr_fountain效果图
摘要
In this work we address the challenging problem of multiview 3D surface reconstruction. We introduce a neural network architecture that simultaneously learns the unknown geometry, camera parameters, and a neural renderer that approximates the light reflected from the surface towards the camera. The geometry is represented as a zero level-set of a neural network, while the neural renderer, derived from the rendering equation, is capable of (implicitly) modeling a wide set of lighting conditions and materials. We trained our network on real world 2D images of objects with different material properties, lighting conditions, and noisy camera initializations from the DTU MVS dataset. We found our model to produce state of the art 3D surface reconstructions with high fidelity, resolution and detail.
译文:
在这项工作中,我们解决了多视图3D表面重建的挑战性问题。我们引入了一种神经网络体系结构,该体系结构同时学习未知的几何形状,相机参数以及神经渲染器,该神经渲染器近似从表面向相机反射的光。几何图形表示为神经网络的零级别集,而从渲染方程导出的神经渲染器能够 (隐式) 对各种照明条件和材料进行建模。我们在DTU MVS数据集中的具有不同材料特性,照明条件和嘈杂相机初始化的对象的真实2D图像上训练了我们的网络。我们发现我们的模型可以产生具有高保真度,分辨率和细节的最先进的3D表面重建。
文章工作
主要贡献是:
- 处理未知几何、外观和相机的端到端架构。
- 表达神经隐式表面对相机参数的依赖性。
- 产生具有广泛外观的不同对象的最先进的3D表面重建,从现实生活中的2D图像,具有精确和嘈杂的相机信息。
算法框架
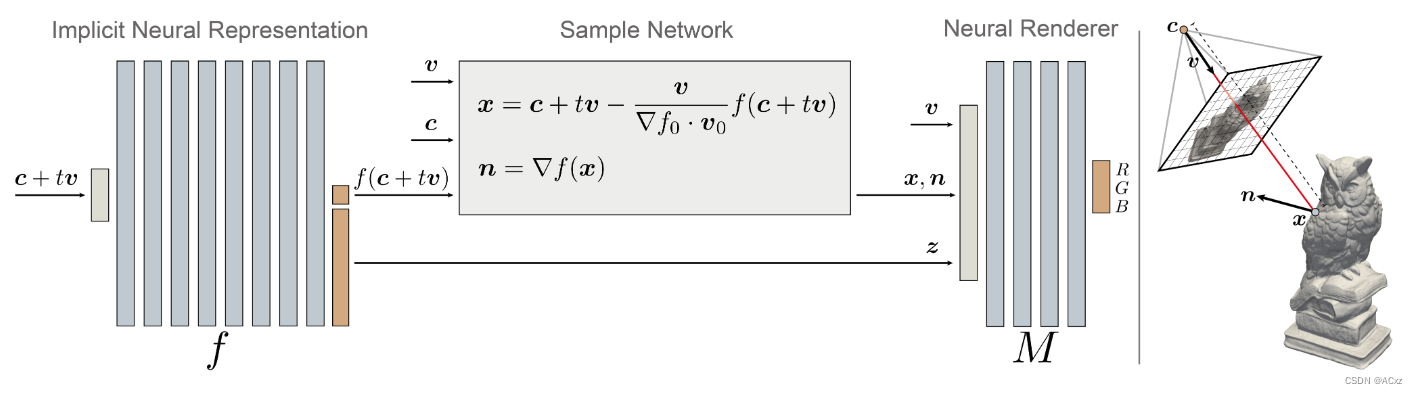
给定一组输入masked- 2D 图像,我们的目标是推断以下三个未知数:
- (i) 场景的几何形状,表示为 MLP f 的零水平集;
- (ii) 场景的光线和反射特性;
- (iii) 未知的相机参数。
为了实现这一目标,我们模拟了受渲染方程启发的隐式神经几何的渲染过程。IDR 正向模型为可学习的相机位置
c
c
c 和一些固定图像像素
p
p
p 生成可微分的
R
G
B
RGB
RGB 值。
如上所示:相机参数和像素定义观察方向
v
v
v,我们用
x
x
x 表示观察光线
c
+
t
v
c+tv
c+tv 与隐式表面。样本网络模块将
x
x
x 和表面
n
n
n 的法线表示为隐式几何和相机参数的可微分函数。从几何体沿方向
v
v
v 向相机
c
c
c 反射的最终辐射率,即
R
G
B
RGB
RGB,由神经渲染器
M
M
M 近似,MLP 将表面点
x
x
x 和法线
n
n
n、观察方向
v
v
v 和全局几何体作为输入特征向量
z
z
z。反过来,将 IDR 模型与地面实况像素颜色进行比较时会产生损失,从而能够同时学习几何形状、外观和相机参数。
Related Work
- 隐式表面可微分射线投射:
- 可微分射线投射主要用于隐式形状表示,体积网格上定义的隐式函数或隐式神经表示,如:
- 隐式函数可以是占用函数 [37,5];
- 有符号距离函数 (SDF) [42] ;
- 任何其他有符号的隐式 [2];
- 相关工作中:
- [20] 使用体积网格来表示SDF并实现射线投射可微分渲染器。它们近似于每个体积单元中的SDF值和表面法线。
- [31] 使用预先训练的DeepSDF模型 [42] 的球体跟踪,并近似深度梯度w.r.t.通过区分球体跟踪算法的各个步骤来确定DeepSDF网络的潜在代码;
- [30] 使用场探测来促进可区分的射线投射。
- 与这些作品相反,IDR利用了精确且可微的表面点和隐式表面的法线,并考虑了更通用的外观模型,并处理了嘈杂的相机。
- 可微分射线投射主要用于隐式形状表示,体积网格上定义的隐式函数或隐式神经表示,如:
- 多视图曲面重建:
- 问题:在图像的捕获过程中,深度信息会丢失。
- 解决:
- 假设已知摄像机,经典的多视图立体 (MVS) 方法 [9,48,3,54] 尝试通过匹配视图中的特征点来再现深度信息。但是,需要进行深度融合的后处理步骤 [6,36],然后是泊松表面重建算法 [24],才能产生有效的3D的水密性的(watertight,个人理解为封闭)表面重建。
- 最近的方法使用场景集合来训练MVS管道的子任务的深度神经模型,例如,特征匹配 [27],或深度融合 [7,44],或端到端MVS管道 [16,56,57]。
- 当相机参数不可用时,并且给定一组来自特定场景的图像,则应用运动结构 (SFM) 方法 [51,47,22,19] 来再现相机和稀疏3D重建。Tang和Tan [53] 使用具有集成的可微束调整 [55] 层的深度神经结构来提取参考帧深度的线性基础,并从附近的图像中提取特征,并优化深度和相机参数在每个前向通过。
- 与这些作品相反,IDR使用来自单个目标场景的图像进行训练,从而产生准确的水密3D表面重建。
- 视图合成的神经表示:
- 最近的作品训练了神经网络,以从一组有限的具有已知相机的图像中预测新颖的视图和3D场景或对象的某些几何表示:
- [50] 使用LSTM对场景几何进行编码,以模拟光线行进过程;
- [38] 使用神经网络来预测体积密度和视图相关的发射辐射度,以从一组具有已知相机的图像中合成新视图;
- [41] 使用神经网络从输入图像和几何图形中学习表面光场,并预测未知视图和/或场景照明。
- 与IDR不同,这些方法不会对场景的几何形状进行3D表面重建,也不会处理未知的相机。
- 最近的作品训练了神经网络,以从一组有限的具有已知相机的图像中预测新颖的视图和3D场景或对象的某些几何表示:
Method
我们的目标是从masked的2D图像中重建对象的几何形状,其中可能包含粗糙或嘈杂的相机信息。我们有三个未知数 :(i) 几何,由参数
θ
∈
R
m
\theta \in R^m
θ∈Rm表示; (ii) 外观,由
γ
∈
R
n
\gamma \in R^n
γ∈Rn表示; (iii) 由
τ
∈
R
k
\tau \in R^k
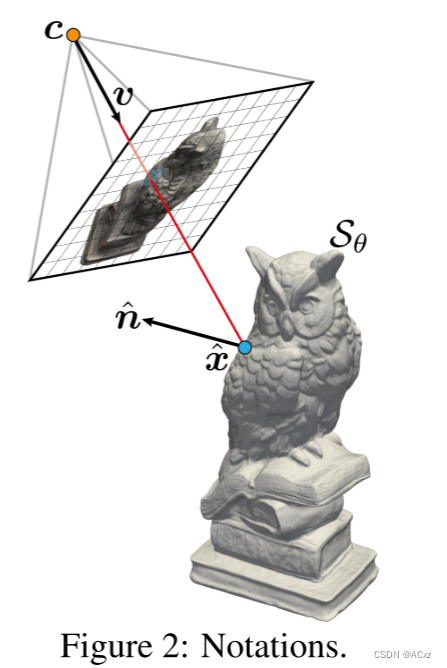
τ∈Rk表示的相机。符号和设置如图2所示:
我们将几何表示为神经网络
(
M
L
P
)
f
(MLP) f
(MLP)f的零级集:
S
=
{
x
∈
R
3
∣
f
(
x
;
θ
)
=
0
}
.
(
1
)
S = \{x ∈ \mathbb{R^3} | f(x;\theta) = 0\} . (1)
S={x∈R3∣f(x;θ)=0}.(1)
具有可学习的参数
θ
∈
R
m
\theta \in R^m
θ∈Rm。为了避免无处不在的0解,
f
f
f通常被正则化 [37,5]。我们选择
f
f
f将有符号距离函数 (SDF) 建模到其零水平集合
S
θ
S_\theta
Sθ[42]。
我们使用隐式几何正则化 (IGR) [11] 实施SDF约束,SDF在我们的上下文中有两个好处:
- 它允许使用球体跟踪算法 [12,20] 进行有效的射线投射;
- IGR享有隐式正则化,有利于平滑和逼真的表面。
IDR forward model
给定与某些输入图像相关联的由p索引的像素,令
R
p
(
τ
)
=
{
c
p
+
t
v
p
∣
t
≥
0
}
R_p(\tau) = \{c_p + tv_p | t ≥ 0\}
Rp(τ)={cp+tvp∣t≥0} 表示通过像素
p
p
p的射线,其中,
c
p
=
c
p
(
τ
)
c_p = c_p(\tau)
cp=cp(τ) 表示各个相机的未知中心,而
v
p
=
v
p
(
τ
)
v_p = v_p(\tau)
vp=vp(τ) 表示光线的方向 (即,从
c
p
c_p
cp指向像素
p
p
p的矢量)。令
x
^
p
=
x
^
p
(
θ
,
τ
)
\hat x_p = \hat x_p(\theta,\tau)
x^p=x^p(θ,τ) 表示射线
R
p
R_p
Rp和表面
S
θ
S_\theta
Sθ 的第一个交点。沿
R
p
R_p
Rp的入射辐射决定了像素
L
p
=
L
p
(
θ
,
γ
,
τ
)
L_p = L_p(\theta,\gamma,\tau)
Lp=Lp(θ,γ,τ) 的渲染颜色,是
x
^
p
\hat x_p
x^p处的表面属性,
x
^
p
\hat x_p
x^p处的入射辐射和观看方向
v
p
v_p
vp的函数。反过来,我们假设表面属性和入射辐射是表面点
x
p
x_p
xp及其相应的表面法线
n
^
p
=
n
^
p
(
θ
)
\hat n_p = \hat n_p(\theta)
n^p=n^p(θ),观察方向
v
p
v_p
vp和全局几何特征向量的函数
z
^
p
=
z
^
p
(
x
^
p
;
Θ
)
\hat z_p =\hat z_p(\hat x_p; \varTheta )
z^p=z^p(x^p;Θ)。因此,IDR正向模型为:
L
p
(
θ
,
γ
,
τ
)
=
M
(
x
^
p
,
n
^
p
,
z
^
p
,
v
p
;
γ
)
,
(
2
)
L_p(\theta, \gamma, \tau) = M(\hat xp, \hat n_p, \hat z_p, v_p; \gamma),(2)
Lp(θ,γ,τ)=M(x^p,n^p,z^p,vp;γ),(2)
其中M是第二神经网络 (MLP)。我们在比较
L
p
L_p
Lp和像素输入颜色
I
p
I_p
Ip的损耗中利用
L
p
L_p
Lp来同时训练模型的参数
θ
,
γ
,
τ
\theta, \gamma, \tau
θ,γ,τ。
Differentiable intersection of viewing direction and geometry
Lemma 1. 令 S θ S_\theta Sθ定义为等式1。射线 R ( τ ) R(\tau) R(τ) 与曲面 S θ S_\theta Sθ的交点可以用公式表示 x ^ ( θ , τ ) = c + t 0 v − v ▽ x f ( x 0 ; θ 0 ) ⋅ v 0 f ( c + t 0 v ; θ ) , ( 3 ) \hat x(\theta,\tau) = c+t_0v-\frac{v}{\bigtriangledown _xf(x_0;\theta_0)\cdot v_0}f(c+t_0v;\theta),(3) x^(θ,τ)=c+t0v−▽xf(x0;θ0)⋅v0vf(c+t0v;θ),(3) 并且在 θ = θ 0 \theta = \theta_0 θ=θ0和 τ = τ 0 \tau = \tau_0 τ=τ0的值和 θ \theta θ 和 τ \tau τ 的一阶导数上是精确的。
此后 (直到第3.4节),我们假设一个固定像素p,并删除下标p符号以简化符号。第一步是将交点
x
^
(
θ
,
τ
)
\hat x(\theta,\tau)
x^(θ,τ) 表示为具有参数
θ
,
τ
\theta,\tau
θ,τ的神经网络。这可以通过对几何网络f进行稍微修改来完成。令
x
^
(
θ
,
τ
)
=
c
+
t
(
θ
,
c
,
v
)
v
\hat x(\theta,\tau) = c + t(\theta,c,v)v
x^(θ,τ)=c+t(θ,c,v)v表示交点。当我们的目标是在类似梯度下降的算法中使用
x
^
\hat x
x^时,我们需要确保我们的导数在当前参数处的值和一阶导数是正确的,由
θ
0
,
τ
0
\theta_0,\tau_0
θ0,τ0表示; 因此,我们表示
c
0
=
c
(
τ
0
)
,
v
0
=
v
(
τ
0
)
,
t
0
=
t
(
θ
0
,
c
0
,
v
0
)
,
x
0
=
x
^
(
θ
0
,
τ
0
)
=
c
0
+
t
0
v
0
c_0 = c(\tau_0),v_0 = v(\tau_0),t_0 = t(\theta_0,c_0,v_0),x_0 = \hat x(\theta_0,\tau_0) = c_0 + t_0v_0
c0=c(τ0),v0=v(τ0),t0=t(θ0,c0,v0),x0=x^(θ0,τ0)=c0+t0v0。
为了证明
x
^
\hat x
x^对其参数的这种函数依赖性,我们使用隐式微分 [1,40],即微分方程
f
(
x
^
;
θ
)
≡
0
w
.
r
.
t
.
v
,
c
,
θ
f (\hat x; \theta) ≡ 0 \ \ w.r.t.\ \ v,c,\theta
f(x^;θ)≡0 w.r.t. v,c,θ并求解t的导数。然后,可以检查公式3中的公式是否具有正确的导数。更多细节在补充中。我们将等式3实现为神经网络,即,我们添加两个线性层 (具有参数
c
,
v
c,v
c,v): 一个在
M
L
P
f
MLP f
MLPf之前和一个在
M
L
P
f
MLP f
MLPf之后。公式3统一了 [1] 中的样本网络公式和 [40] 中的可微深度,并将其推广以说明未知相机。在
x
x
x处
S
θ
S_\theta
Sθ 的法向量可以通过以下方式计算:
n
^
(
θ
,
τ
)
=
▽
x
f
(
x
^
(
θ
,
τ
)
,
θ
)
∣
∣
▽
x
f
(
x
^
(
θ
,
τ
)
,
θ
)
∣
∣
2
\hat n(\theta,\tau) = \frac{\bigtriangledown_xf(\hat x(\theta,\tau),\theta)}{|| \bigtriangledown_xf(\hat x(\theta,\tau),\theta)||_2}
n^(θ,τ)=∣∣▽xf(x^(θ,τ),θ)∣∣2▽xf(x^(θ,τ),θ)
对于SDF,分母为1,因此可以省略。
Approximation of the surface light field
表面光场辐射度
L
L
L是从
S
θ
S_\theta
Sθ 在方向-
v
v
v到达
c
c
c的方向上的
x
x
x处反射的光量。它由两个函数确定: 描述表面的反射率和颜色特性的双向反射率分布函数 (BRDF),以及场景中发出的光 (即,光源)。
BRDF函数
B
(
x
,
n
,
w
o
,
w
i
)
B(x,n,w^o,w^i)
B(x,n,wo,wi) 描述了在某个波长 (即,颜色) 相对于来自方向
w
i
w^i
wi的入射辐射在方向
w
o
w^o
wo处离开具有法线
n
n
n的表面点x。我们让BRDF也依赖于一点上表面的法线
n
n
n。场景中的光源由函数
L
e
(
x
,
w
o
)
L^e(x,w^o)
Le(x,wo) 描述,该函数测量在方向
w
o
w^o
wo上的点x处的某个波长处的光的发射辐射。在方向
v
v
v上到达
c
c
c的光量等于在方向
w
o
=
−
v
w^o =-v
wo=−v上从
x
x
x反射的光量,并且由所谓的渲染方程 [21,17] 描述:
L
(
x
^
,
w
o
)
=
L
e
(
x
^
,
w
o
)
+
∫
Ω
B
(
x
^
,
n
^
,
w
o
,
w
i
)
L
i
(
x
^
,
w
i
)
(
n
^
,
w
i
)
d
w
i
=
M
0
(
x
^
,
n
^
,
v
)
,
(
5
)
L(\hat x,w^o) \\= L^e(\hat x,w^o)+\int_\Omega B(\hat x,\hat n,w^o,w^i)L^i(\hat x,w^i)(\hat n,w^i)dw^i \\=M_0(\hat x,\hat n,v),(5)
L(x^,wo)=Le(x^,wo)+∫ΩB(x^,n^,wo,wi)Li(x^,wi)(n^,wi)dwi=M0(x^,n^,v),(5)
其中,
L
i
(
x
^
,
w
i
)
L^i (\hat x,w^i)
Li(x^,wi) 编码方向
w
i
w^i
wi上的
x
^
\hat x
x^ 处的传入辐射,术语
n
^
⋅
w
i
\hat n\cdot w^i
n^⋅wi 补偿了光没有正交地照射到表面的事实;
Ω
\Omega
Ω是以
n
^
\hat n
n^ 为中心的半球体。函数
M
0
M_0
M0表示作为局部表面几何形状
x
^
、
n
^
\hat x、 \hat n
x^、n^ 和 观察方向
v
v
v 的函数的表面光场。该渲染方程适用于每个光波长度; 如后所述,我们将使用它来表示红色、绿色和蓝色 (RGB) 波长。
我们将注意力限制在可以用连续函数
M
0
M_0
M0表示的光场上。我们用
P
=
{
M
0
}
P = \{M_0\}
P={M0} 表示这种连续函数的集合 (有关
P
P
P的更多讨论,请参见补充材料)。用 (足够大的) MLP近似M (神经渲染器) 代替
M
0
M_0
M0提供了光场近似:
L
(
θ
,
γ
,
τ
)
=
M
(
x
^
,
n
^
,
v
;
γ
)
,
(
6
)
L(\theta,\gamma,\tau) = M (\hat x,\hat n,v; \gamma),(6)
L(θ,γ,τ)=M(x^,n^,v;γ),(6)
几何形状和外观的解缠结要求可学习的M对所有输入
x
,
n
,
v
x,n,v
x,n,v近似于
M
0
M_0
M0,而不是存储特定几何形状的辐射值。给定光场函数
M
0
∈
P
M_0 \in P
M0∈P的任意选择,存在权重
γ
=
γ
0
\gamma = \gamma_0
γ=γ0的选择,因此对于所有
x
,
n
,
v
x,n,v
x,n,v (在某个有界集中),M近似于
M
0
M_0
M0。这可以使用mlp的标准普遍性定理来证明 (在补充中详细信息)。但是,M可以学习正确的光场函数M0的事实并不意味着可以保证在优化过程中学习它。尽管如此,对于任意
x
,
n
,
v
x,n,v
x,n,v能够近似于
M
0
M_0
M0是解开几何 (用f表示) 和外观 (用M表示) 的必要条件。我们将这个必要条件命名为
P
−
u
n
i
v
e
r
s
a
l
i
t
y
P-universality
P−universality.
Necessity of viewing direction and normal
形式为了能够表示从表面点x反射的正确光,即
P
−
u
n
i
v
e
r
s
a
l
P-universal
P−universal,它还必须接收
v
,
n
v,n
v,n作为参数。即使我们期望M为固定的几何形状工作,观察方向
v
v
v也是必需的; 例如,用于模拟镜面。而正常的
n
n
n则可以由
M
M
M作为
x
x
x的函数来记忆。但是,为了解开几何形状,即允许M独立于几何形状学习外观,也必须合并法线方向。这可以在图3中看到: 在没有正常信息的renderer M将产生相同的光估计情况 (a)和 (b),而没有观看方向的渲染器M将在情况 (a) 和 © 中产生相同的光估计。在补充中,我们提供了有关这些渲染器在Phong反射模型下如何无法生成正确的辐射的详细信息 [8]。以前的作品,例如 [40],已经考虑了形式为
L
(
θ
,
γ
)
=
M
(
x
^
;
γ
)
L(\theta,\gamma) = M (\hat x; \gamma)
L(θ,γ)=M(x^;γ) 的隐式神经表示的渲染函数。如上所述,从M中省略n和/或v将导致非
P
−
u
n
i
v
e
r
s
a
l
P-universal
P−universal渲染器。在实验部分中,我们证明了将
n
n
n合并到渲染器
M
M
M中确实可以成功地解开几何形状和外观,而忽略它会损害解开。
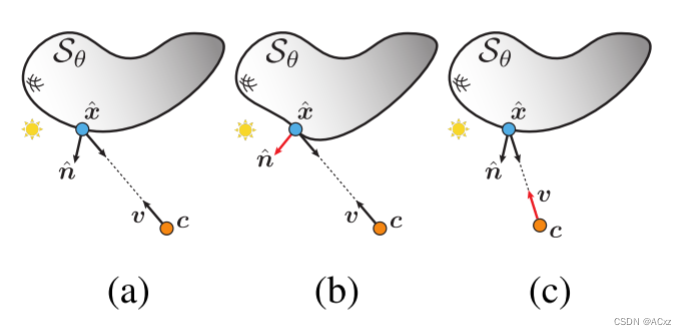
图3: 没有 n n n和/或 v v v的神经渲染器不是通用的
Accounting for global light effects
P − u n i v e r s a l i t y P-universality P−universality是学习可以从集合 P P P中模拟外观的神经渲染器M的必要条件。但是, P P P不包括诸如辅助照明和自阴影之类的全局照明效果。通过引入全局特征向量 z ^ \hat z z^,我们进一步提高了IDR的表达能力。此特征向量允许渲染器全局推理几何 S θ S_\theta Sθ。为了产生向量 z ^ \hat z z^,我们将网络f扩展如下: F ( x ; Θ ) = [ f ( x ; Θ ) , z ( x ; Θ ) ] ∈ R × R ℓ F(x; \Theta) = [f(x; \Theta),z(x; \Theta)] ∈ R × R^\ell F(x;Θ)=[f(x;Θ),z(x;Θ)]∈R×Rℓ。通常, z z z可以相对于曲面样本 x x x对几何 S θ S_\theta Sθ进行编码; z被馈送到渲染器中,为 φ z(θ,τ) = z (φ x;Θ),以考虑与当前感兴趣像素p相关的表面样本 x ^ \hat x x^。我们现在已经完成了IDR模型的描述,在等式2中给出。
Masked rendering
用于重建3D几何形状的另一种有用的2D监督类型是Masked; 蒙版是二进制图像,对于每个像素p,指示感兴趣的对象是否占用该像素。可以在数据中提供掩码 (如我们假设的那样) 或使用例如掩码或分割算法进行计算。我们想考虑以下指示函数来标识某个像素是否被渲染的对象占用 (记住我们假设某个固定像素p):
S
(
θ
,
τ
)
=
{
1
R
(
τ
)
∩
S
θ
≠
0
0
o
t
h
e
r
w
i
s
e
S(\theta,\tau) = \left\{\begin{matrix} \ \ \ \ 1 \ \ \ \ \ \ \ \ R(\tau)\cap S_\theta \ne 0 \\ 0 \ \ \ \ \ \ \ \ \ \ \ otherwise \end{matrix}\right.
S(θ,τ)={ 1 R(τ)∩Sθ=00 otherwise
由于此函数在
θ
\theta
θ 中不是可微的也不是连续的,因此
τ
\tau
τ我们使用了几乎所有地方的可微近似值:
S
α
(
θ
,
τ
)
=
s
i
g
m
o
i
d
(
−
α
min
t
≥
0
f
(
c
+
t
v
;
θ
)
)
,
(
7
)
S_\alpha(\theta,\tau) = sigmoid(-\alpha \min_{t \ge 0}f(c+tv;\theta)),(7)
Sα(θ,τ)=sigmoid(−αt≥0minf(c+tv;θ)),(7)
其中
α
>
0
\alpha \gt 0
α>0是一个参数。由于根据惯例,我们的几何内部
f
<
0
f \lt 0
f<0,外部
f
>
0
f\gt 0
f>0,因此可以验证
S
α
(
θ
,
τ
)
→
S
(
θ
,
τ
)
S_\alpha(\theta,\tau) → S(\theta,\tau)
Sα(θ,τ)→S(θ,τ)。此外,该神经网络在
c
=
c
0
c = c_0
c=c0和
v
=
v
0
v = v_0
v=v0处具有精确值和一阶导数。
Loss
设
I
p
∈
[
0
,
1
]
3
I_p ∈ [0,1]^3
Ip∈[0,1]3,
O
p
∈
{
0
,
1
}
O_p \in \{0,1\}
Op∈{0,1}是与使用相机
c
p
(
τ
)
c_p(\tau)
cp(τ) 和方向
v
p
(
τ
)
v_p(\tau)
vp(τ) 拍摄的图像中的像素p相对应的RGB和掩码值 (resp。),其中
p
∈
P
p \in P
p∈P索引输入图像集合中的所有像素,
τ
∈
R
k
\tau \in R^k
τ∈Rk表示场景中所有摄像机的参数。我们的损失函数的形式为:
l
o
s
s
(
θ
,
γ
,
τ
)
=
l
o
s
s
R
G
B
(
θ
,
γ
,
τ
)
+
p
l
o
s
s
M
A
S
K
(
θ
,
τ
)
+
λ
l
o
s
s
E
(
θ
)
,
(
8
)
loss(\theta,\gamma,\tau) = loss_{RGB}(\theta,\gamma,\tau) +ploss_{MASK}(\theta,\tau) + \lambda loss_E(\theta),(8)
loss(θ,γ,τ)=lossRGB(θ,γ,τ)+plossMASK(θ,τ)+λlossE(θ),(8)
我们在P中的小批量像素上训练这种损失; 为了保持简单的符号,我们用P表示当前的小批量。对于每个
p
∈
P
p\in P
p∈P,我们使用球体跟踪算法 [12,20] 来计算射线
R
p
(
τ
)
R_p(\tau)
Rp(τ)和
S
θ
S_\theta
Sθ的第一个相交点
c
p
+
t
p
,
0
v
p
c_p +t_p,0v_p
cp+tp,0vp。令引脚为已找到相交且
O
p
=
1
O_p = 1
Op=1的像素P的子集。设
L
p
(
θ
,
γ
,
τ
)
=
M
(
x
^
p
,
n
^
p
,
z
^
p
,
v
p
;
γ
)
,
L_p(\theta,\gamma,\tau) = M (\hat x_p,\hat n_p,\hat z_p,v_p; \gamma),
Lp(θ,γ,τ)=M(x^p,n^p,z^p,vp;γ),,其中 “xp,” np定义为在等式3和4中,
z
^
p
=
z
^
(
x
^
p
;
θ
)
\hat z_p = \hat z (\hat x_p; \theta)
z^p=z^(x^p;θ) 定义为在第3.2节和等式2中。RGB损失是
l
o
s
s
R
G
B
(
θ
,
γ
,
τ
)
=
1
∣
P
∣
∑
p
∈
P
i
n
∣
I
p
−
L
p
(
θ
,
γ
,
τ
)
∣
,
(
9
)
loss_{RGB}(\theta,\gamma,\tau) =\frac{1}{|P|}\sum_{p \in P^{in}}|I_p-L_p(\theta,\gamma,\tau)|,(9)
lossRGB(θ,γ,τ)=∣P∣1p∈Pin∑∣Ip−Lp(θ,γ,τ)∣,(9)
其中
∣
⋅
∣
| \cdot |
∣⋅∣ 表示L1范数。
P
o
u
t
=
P
P
i
n
P^{out}=\frac{P}{P^{in}}
Pout=PinP表示mini-batch中没有射线几何相交或Op = 0的索引。MASK损失是
l
o
s
s
M
A
S
K
(
θ
,
τ
)
=
1
∣
α
P
∣
∑
p
∈
P
o
u
t
C
E
(
O
p
,
S
p
,
α
(
θ
,
τ
)
)
,
(
10
)
loss_{MASK}(\theta,\tau) =\frac{1}{|\alpha P|}\sum_{p \in P^{out}}CE(O_p,S_{p,\alpha(\theta,\tau)}),(10)
lossMASK(θ,τ)=∣αP∣1p∈Pout∑CE(Op,Sp,α(θ,τ)),(10)
其中,CE是交叉熵损失。最后,我们强制
f
f
f近似为具有隐式几何正则化 (IGR) [11] 的有符号距离函数,即合并了Eikonal正则化:
l
o
s
s
E
(
θ
)
=
E
x
(
∣
∣
▽
x
f
(
x
;
θ
)
∣
∣
−
1
)
2
,
(
10
)
loss_{E}(\theta) =E_x(||\bigtriangledown_xf(x;\theta) ||-1)^2,(10)
lossE(θ)=Ex(∣∣▽xf(x;θ)∣∣−1)2,(10)
其中x均匀分布在场景的边界框中。
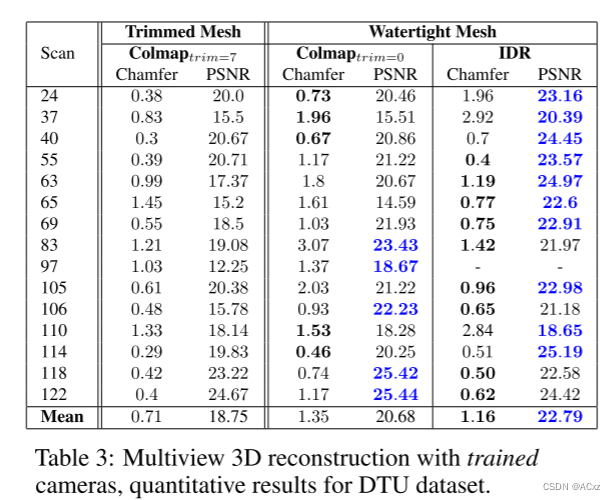
实验结果
总结
我们引入了隐式可微渲染器 (IDR),这是一种端到端的神经系统,可以从掩蔽的2D图像和嘈杂的摄像机初始化中学习3D几何形状,外观和摄像机。仅考虑粗略的相机估计,就可以在无法获得精确相机信息的现实场景中进行可靠的3D重建。我们的方法的一个限制是,它需要一个合理的相机初始化,不能使用,例如随机相机初始化。有趣的未来工作是将IDR与神经网络结合起来,该神经网络直接从图像中预测相机信息。另一个有趣的未来工作是将表面光场 (等式5中的 M 0 M_0 M0) 进一步因子为材料 (BRDF,B) 和场景中的光 ( L i L^i Li)。最后,我们希望将IDR纳入其他计算机视觉和学习应用程序中,例如3D模型生成以及从野外图像中学习3D模型。