一、scrapy爬虫框架介绍
scrapy是一个功能强大的网络爬虫框架,是python非常优秀的第三方库,也是基于python实现网络爬虫的重要技术路线。scrapy不是哟个函数功能库,而是一个爬虫框架。
爬虫框架:是实现爬虫功能的一个软件结构和功能组件集合。
安装:pip install scrapy
安装后小测:scrapy -h
scrapy的组成:

在这五个模块之间,数据包括用户提交的网络爬虫请求以及从网络上获取的相关内容,在这些结构间进行流动,形成了数据流
scrapy框架包含三条主要的数据流路径:
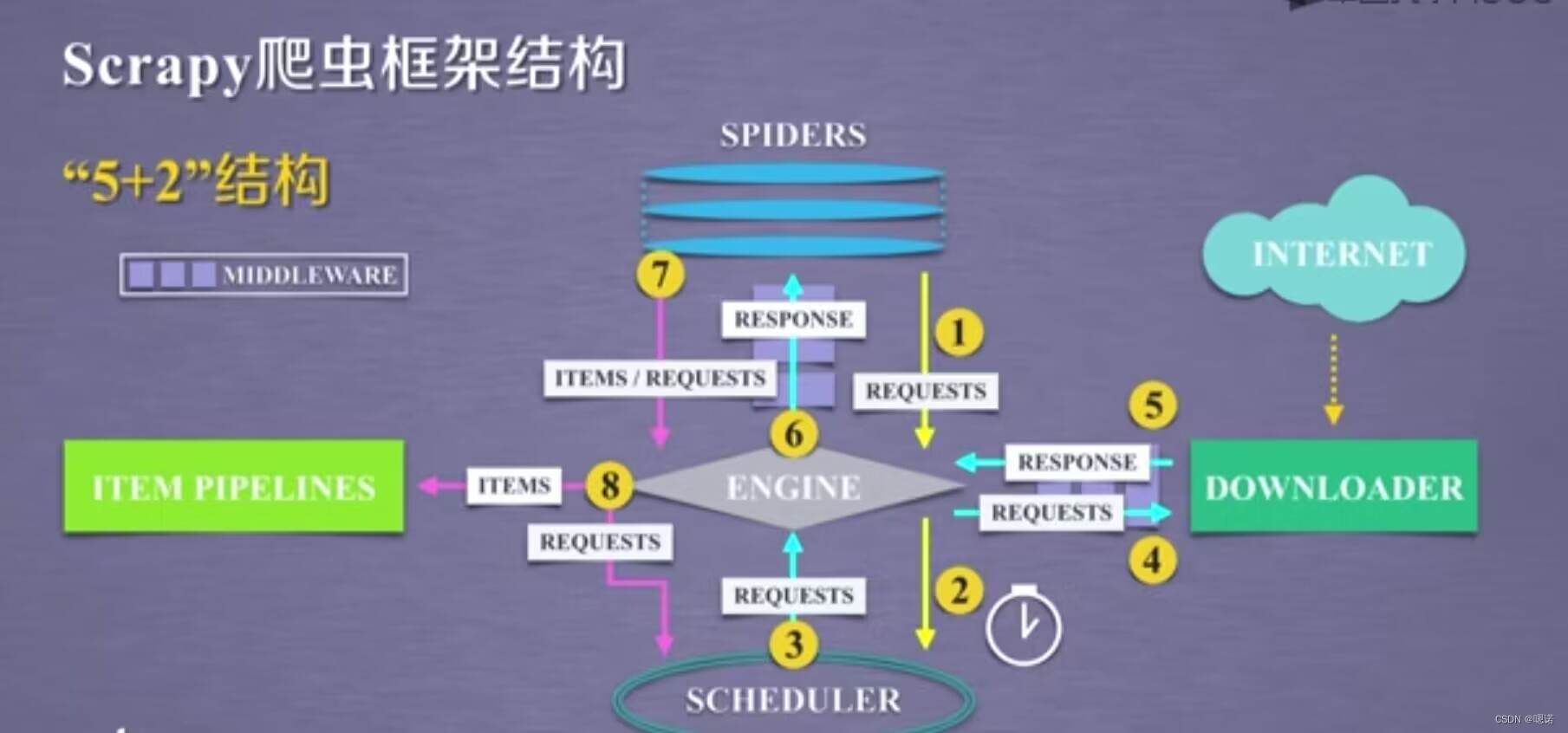
第一条路径(1、2)从spiders到engine的地方获得了爬取用户的请求request,scheduler负责对爬取请求进行调度
第二条路径(3-6),首先engine从scheduler获得下一个要爬取的网络请求,这个时候的网络请求是真实的要去网络上爬取的请求,那么engine获得这样的请求后,通过中间键发送给downloader模块,downloader模块拿到这个请求后,真实的链接互联网并且爬取相关的网页,爬取到网页后downloader模块将爬取的内容形成一个对象,这个对象叫响应response,那么将所有的内容封装成response后,将这个响应再通过中间键engine最终发送给spiders.
第三条路径(7、8)首先spiders处理从downloader获得的响应,它处理之后产生了两个数据类型,一个数据类型叫爬取项item,另外一个数据是新的爬取请求,也就是说我们从网络上获得一个网页后,如果这个网页有其他的链接也是我们十分感兴趣的,那么我们就可以在spiders中增加相关的功能,对新的连接发起再次的爬取。engine模块收到这两类数据之后,将其中的item发送给item pipelines,将其中的request发送给sheduler进行调度,从而为后期的再次处理以及再次启动网络爬虫请求提供新的数据来源。
整个框架的入口的spiders,出口是item pipelines.
其中,engine,downloaders,scheduler已有实现,用户只需编写item pipelines和spiderws。
二、scrapy爬虫框架解析
engine:这个模块是框架的核心。用于控制所有模块之间的数据流和根据条件触发事件进行触发。
downloader:根据用户提供的请求来下载网页。它的功能比较单一,只是获得一个请求并向网络中提交请求,最终获得返回的相关内容。
scheduler:对所有的爬取请求进行调度管理。
downloader middleware(用户可以修改代码):目的为实施engine 、schedu;er、downloder之间进行用户可配置的控制。功能为修改、丢弃、新增请求或响应。
spider(用户主要编写这部分的代码):解析downloader返回的响应(response),产生爬取项(scraped item),并且能产生额外的爬取请求。简单来说,它向整个框架提供了最初始的访问链接,同时对每次返回来的内容进行解析,再次产生新的爬取请求,并且从内容中分析出提取出相关的数据。
item pipelines(需要用户编写配置代码):以流水线方式处理spider产生的爬取项。由一组操作顺序组成,类似流水线,每个操作是一个item pipeline类型。可能操作包括:清理、检验和查重爬取项中的html数据、将数据存储在数据库中。
spider middleware(用户可以编写配置代码):目的为对请求和爬取项进行再处理。功能为修改、丢弃、新增请求或爬取项。
三、requests库与scrapy库的比较
相同点:两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线。两者的可用性都好,文档丰富,入门简单。两者都没有处理js、提交表单、应对验证码等功能(可扩展)的支持。
不同点:爬取某个网页使用requests,爬取大量网页使用scrapy。
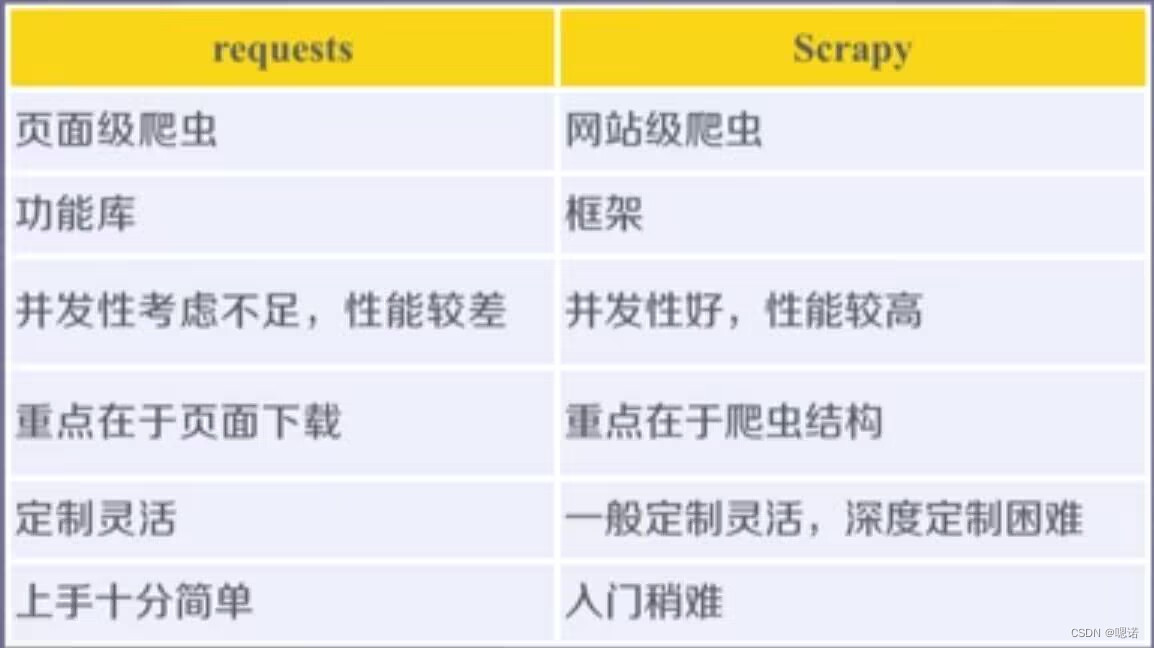
使用建议:非常小的需求使用requests,不太小的需求使用scrapy框架,定制程度很高的需求(不考虑规模)或自搭框架则requests>scrapy。一个爬虫能够持续的,或者不间断的,或者是周期性的爬取一个网站的信息,并且这个数据的想你想我们希望去积累,形成我们之间的爬取库,这种情况适用scrapy框架。
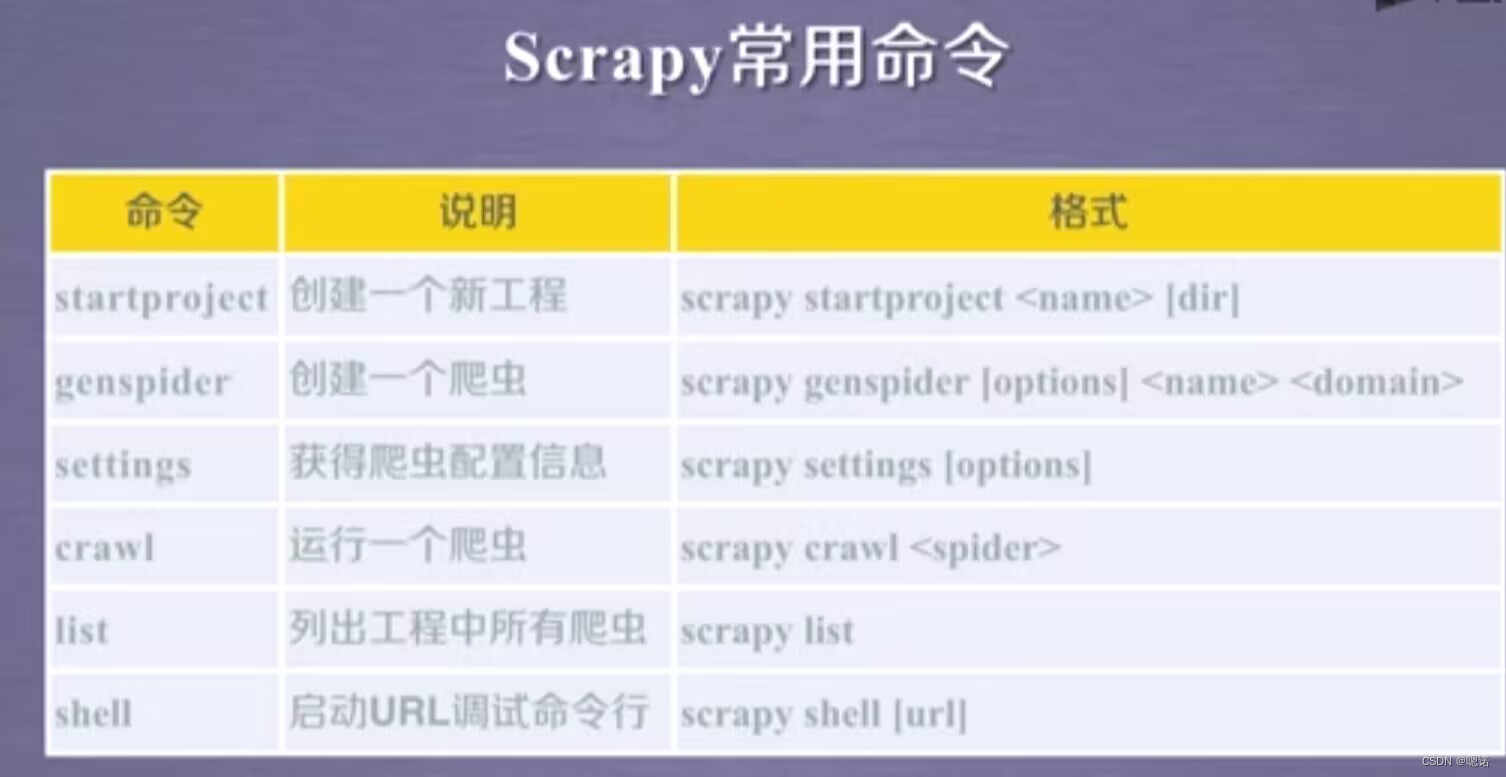
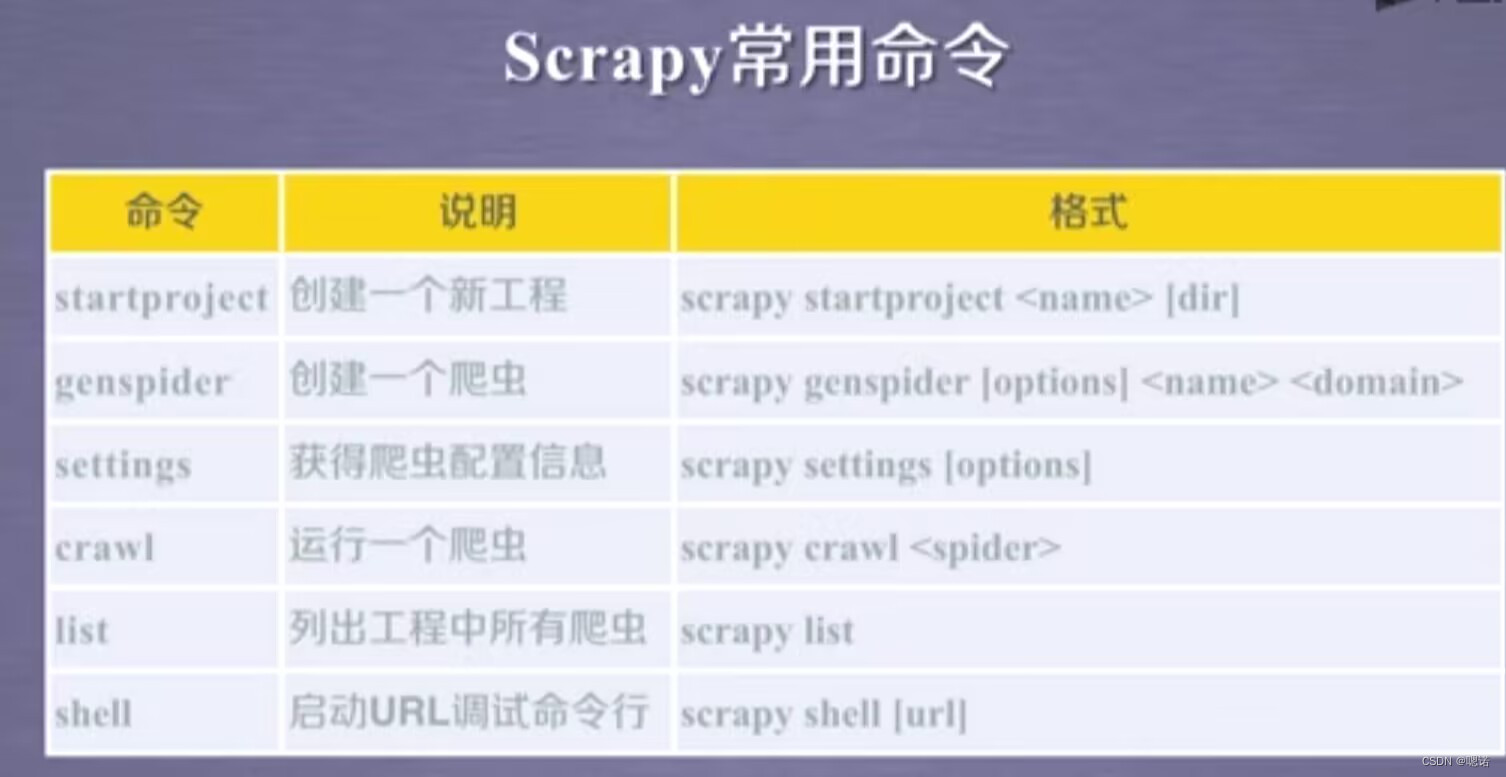
三、scrapy爬虫的常用命令
scrapy是为了持续运行设计的专业爬虫框架,提供操作的scrap用命令行。
工具:在windows下通过command启动命令台(命令行更容易自动化,适合脚本控制,本质上,scrapy是给程序员使用的),并且输入命令scrapy -h
scrapy命令行格式:>scrapy <command> [options] [args]。其中command是scrapy具体命令。
在scrapy框架下一个工程是最大的单元,一个工程可以相当于大的scrapy框架,而在scrapy中,它可以有多个爬虫,每一个爬虫相当于框架中的一个spider模块.
四、scrapy爬虫的第一个实例
演示HTML页面地址:http://python123.io/ws/demo.html
文件名称:demo.html

步骤如下:
1、打开命令行,然后切换到我们需要项目的位置(例如切换到D则输入D:)
2、输入scrapy startproject python123demo,用以创建一个名字为 python123demo的工程。
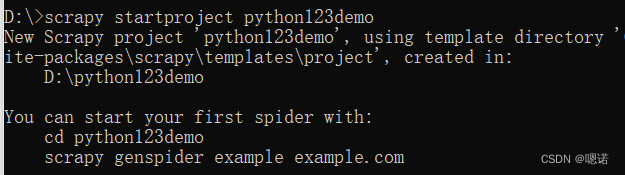

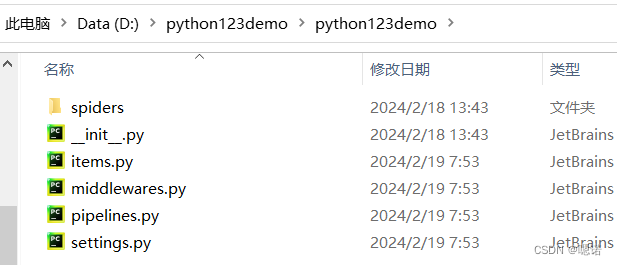

此时生成的工程目录如下:python123demo为外层目录。scrapy.cfg用于部属scrapy爬虫的部属文件,部属的概念是指将这样的爬虫放在特定的服务器上,并且在服务器配置好相关的接口,对于我们本机使用的爬虫来讲,我们不需要改变部属文件。与scrapy/cfg同目录的python123ddemo是指scrapy框架的用户自定义python代码。_init_.py是初始化脚本,用户不需要编写。items.py是items代码模板(继承类),这里也不需要用户编写。middlewares.py指的是middlewares代码模板(继承类),如果用户需要扩展middlewares,那么就需要把这些功能写到这个文件当中。Pipelines.py对应pipelines代码模板(继承类)。seettings.py是scrapy爬虫的配置文件,如果需要修改功能,就需要修改对应的配置项。spiders是spiders代码模板目录(继承类),这个目录下存放的是python123demo这个工程中所建立的爬虫,这些爬虫需要符合爬虫模板的约束。spiders下的_init_.py是初始文件,无需修改,若运行过的项目,spiders下会多一个_pycache_,为缓存目录,无需修改。
3.进入工程,在工程中产生一个scrapy爬虫,命令为scrapy genspider demo python123.io,这条命令的作用是生成一个名称为demo的spider。
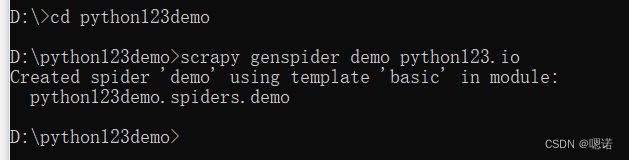
这时候发现 在spider下生成了demo.py
以下为demo.py的内容:
import scrapy
class DemoSpider(scrapy.Spider):
name = "demo" #说明当前爬虫的名字叫demo
allowed_domains = ["python123.io"]#最开始用户提交命令行的域名,指的是这个爬虫在爬取网站的时候,只能爬取这个域名下的相关链接。
start_urls = ["https://python123.io"]#后面以列表形式包含的多个url,事实上就是scrapy框架所要爬取页面的初始页面
def parse(self, response):#解析页面的空的方法,用于处理响应,解析内容形成字典,发现新的url爬取请求,self是面向对象所属关系的标记
pass
4.用idle打开demo,然后配置spiders
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
# allowed_domains = ['python123.io'] 不需要 注释掉
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response):
fname = response.url.split('/')[-1] #这里面我们从响应的url中提取文件的名字,作为我们保存为本地的文件名,然后我们将返回的内容保存为文件
with open(fname,'wb') as f: # 返回的内容保存为文件
f.write(response.body)
self.log('Saved file %s.' % name)
5.执行项目:在命令行输入scrapy crawl demo,捕获的页面将被存储在demo.html文件中

yield关键字的使用
yield与“生成器”息息相关。
生成器是一个不断产生值的函数。包含yild语句的函数是一个生成器。生成器在每次产生一个值(yield语句),函数被冻结,被唤醒后再产生一个值。而唤醒后它所产生的局部变量的值跟之前执行所使用的值是一致的。也就是说,一个函数执行到某个位置,然后它被冻结,再次被唤醒的时候,还是从这个位置继续去执行,那么每次执行的时候,它就可能产生一个数据,这样这个函数就不停的执行。
生成器大部分与循环一起出现,这样我们就可以使用一个for循环调用生成器。
使用生成器的好处:更节省存储空间,响应更迅速,使用更灵活。
五、scrapy爬虫的基本使用
步骤:1.创建一个工程和soider模板 。2、编写spider 。 3、编写item pipeline . 4、优化配置策略。
涉及的三个类:request类、response类、item类
request:class.scrapy.http.Request()。request对象表示一个http请求。由spider生成,由downloader执行。
resopnse:class.scrapy.http.Response()。response对象表示一个http响应。由downloader生成,由spider处理。

item:class.scrapy.http.Item()。Item对象表示一个从HTML页面中提取的信息内容。由spider生成,由item pipeliner处理。item类似字典类型,可以按照字典类型操作。
scrapy爬虫提取信息的方法:beautiful Soup,lxml,re,xpath selector,CSS selector。
CSS selector格式:<html>.css('a::attr(href)').extract()