一,RSI策略
数据:
代码
import pandas as pd
# 读取贵州茅台股票历史交易数据
df = pd.read_csv('贵州茅台股票历史交易数据.csv')
missing_values = df.isnull().sum()
# print("缺失值数量:")
# print(missing_values)
# 计算RSI指标
def calculate_rsi(data, window=14):
delta = data['Close'].diff()
gain = delta.copy()
loss = delta.copy()
gain[gain < 0] = 0
loss[loss > 0] = 0
avg_gain = gain.rolling(window).mean()
avg_loss = abs(loss.rolling(window).mean())
rs = avg_gain / avg_loss
rsi = 100 - (100 / (1 + rs))
return rsi
# 调用calculate_rsi函数计算RSI指标
df['RSI'] = calculate_rsi(df)
# print(df)
# 交易信号生成
df['Signal'] = 0
df.loc[df['RSI'] > 70, 'Signal'] = -1
df.loc[df['RSI'] < 30, 'Signal'] = 1
# 打印df对象
# print(df)
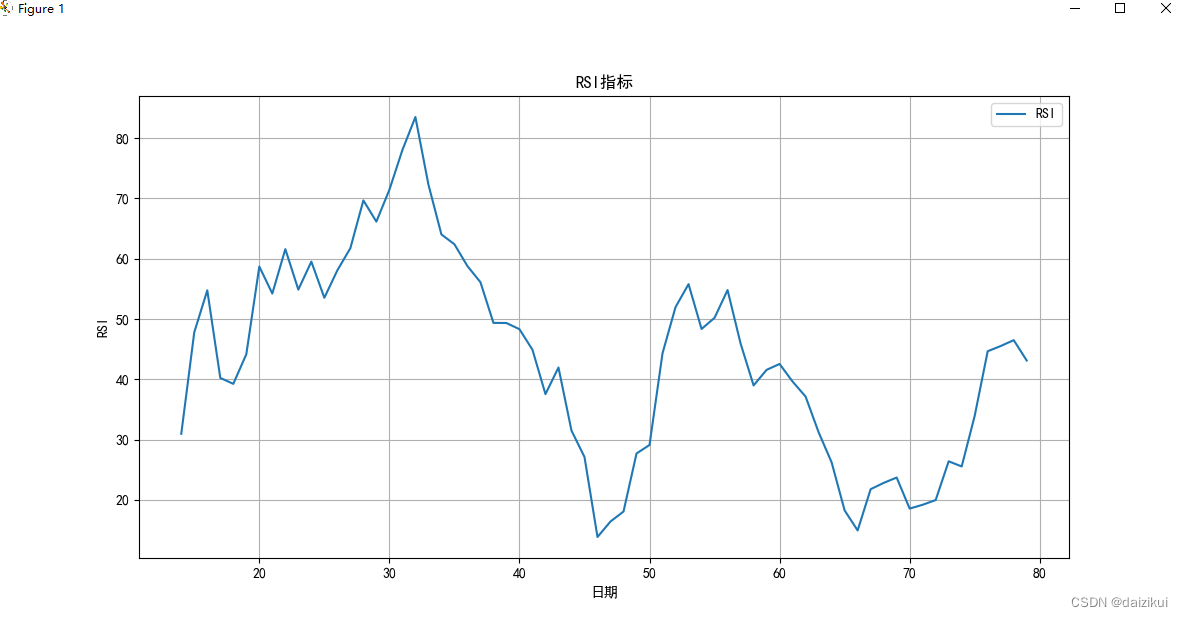
### 绘制RSI指标曲线
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 设置负号显示
rsi = calculate_rsi(df) # 计算RSI指标
plt.figure(figsize=(12, 6))
plt.plot(df.index, rsi, label='RSI')
plt.title('RSI指标')
plt.xlabel('日期')
plt.ylabel('RSI')
plt.legend()
plt.grid(True)
plt.show()
### 绘制K线图
import mplfinance as mpf
plt.rcParams['font.family'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 设置负号显示
# 重新加载数据
df = pd.read_csv('贵州茅台股票历史交易数据.csv')
# 创建日期索引
df['Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True)
market_colors = mpf.make_marketcolors(up='red', down='green')
my_style = mpf.make_mpf_style(marketcolors=market_colors)
# 绘制K线图
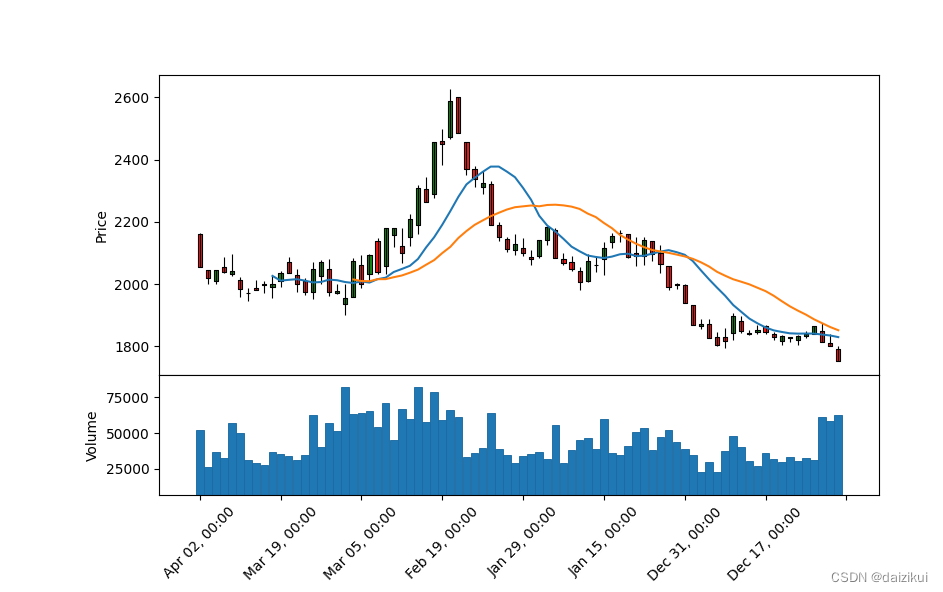
mpf.plot(df, type='candle',
figsize=(10, 6),
mav=(10, 20),
volume=True,
style=my_style)
### 绘制价格和交易信号图表
plt.rcParams['font.family'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 设置负号显示
# 读取贵州茅台股票历史交易数据
df = pd.read_csv('贵州茅台股票历史交易数据.csv')
# 创建日期索引
df['Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True)
# 计算RSI指标
def calculate_rsi(data, window=14):
delta = data['Close'].diff()
gain = delta.copy()
loss = delta.copy()
gain[gain < 0] = 0
loss[loss > 0] = 0
avg_gain = gain.rolling(window).mean()
avg_loss = abs(loss.rolling(window).mean())
rs = avg_gain / avg_loss
rsi = 100 - (100 / (1 + rs))
return rsi
# 计算RSI指标
df['RSI'] = calculate_rsi(df)
# 交易信号生成
df['Signal'] = 0
df.loc[df['RSI'] > 70, 'Signal'] = -1
df.loc[df['RSI'] < 30, 'Signal'] = 1
# 绘制价格和交易信号图表
plt.figure(figsize=(12, 6))
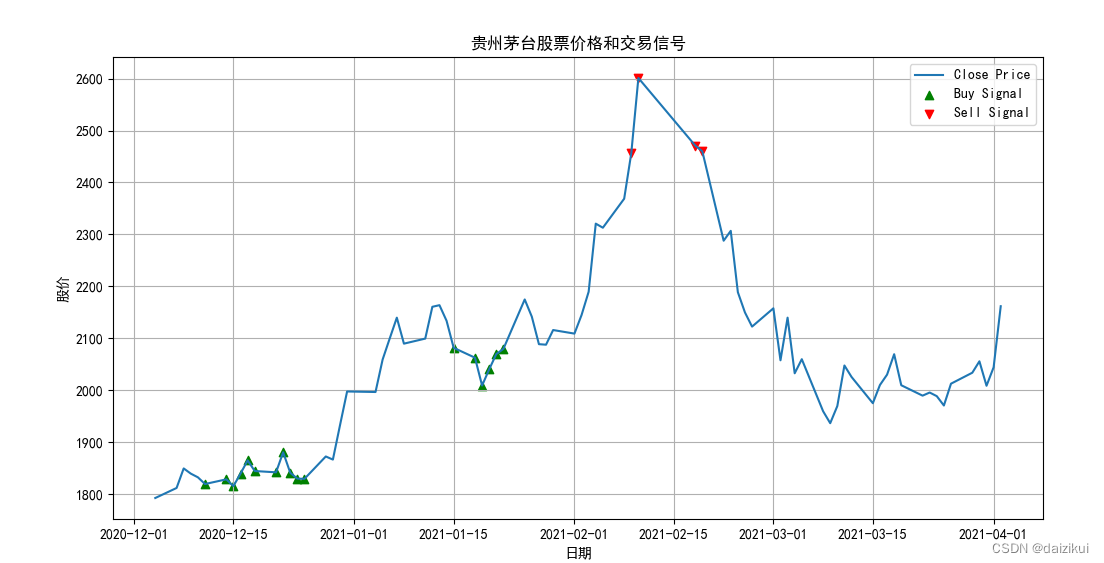
plt.plot(df.index, df['Close'], label='Close Price')
plt.scatter(df[df['Signal'] == 1].index, df[df['Signal'] == 1]['Close'], color='green', marker='^', label='Buy Signal')
plt.scatter(df[df['Signal'] == -1].index, df[df['Signal'] == -1]['Close'], color='red', marker='v', label='Sell Signal')
plt.title('贵州茅台股票价格和交易信号')
plt.xlabel('日期')
plt.ylabel('股价')
plt.legend()
plt.grid(True)
plt.show()图表
二,RSI策略
数据
0601857股票历史交易数据.csv
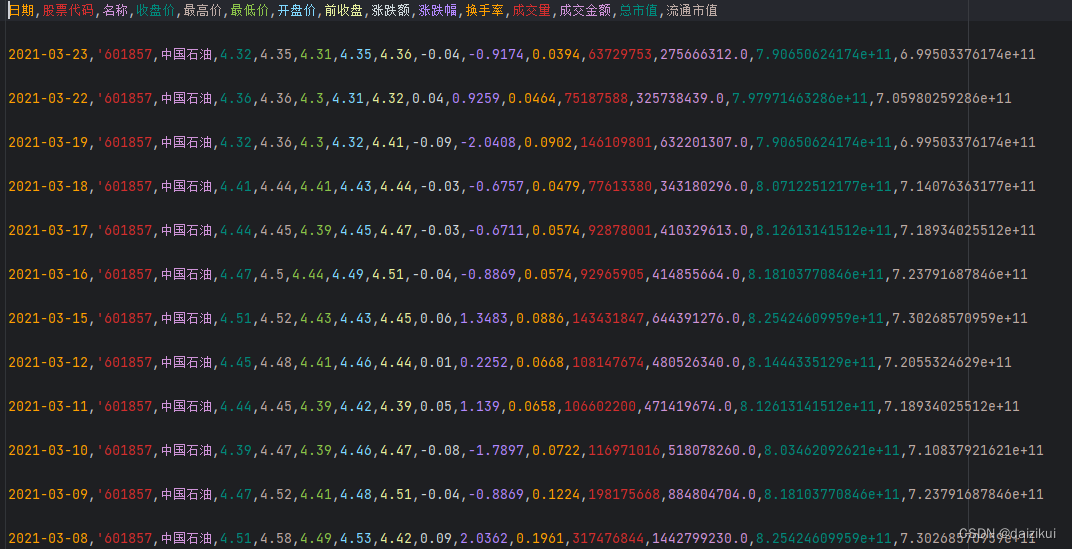
代码
import pandas as pd
import numpy as np
# ================================数据处理============================================
# 原始文件
inputfile = '0601857股票历史交易数据.csv'
# 目标文件
outfile = '0601857股票历史交易数据(清洗后).csv'
# 打开原始文件和目标文件
with open(inputfile, 'r') as input_file, open(outfile, 'w') as output_file:
# 逐行读取原始文件
for line in input_file:
# 去除行末的换行符
line = line.rstrip('\n')
# 判断是否为空行
if line:
# 写入非空行到目标文件
output_file.write(line + '\n')
print('处理完成。')
# 数据文件
f = '0601857股票历史交易数据(清洗后).csv'
# 读取股票历史交易数据
df = pd.read_csv(f, encoding='gbk', index_col='日期', parse_dates=True)
# 移除“股票代码”和“名称”列
df = df.drop(['股票代码', '名称'], axis=1)
# 筛选出2021年的数据
df = df.query('日期.dt.year == 2021')
# 打印前10条数据
# print(df.head(10))
# 重新命名列名
column_mapping = {
'日期': 'Date',
'收盘价': 'Close',
'最高价': 'High',
'最低价': 'Low',
'开盘价': 'Open',
}
df = df.rename(columns=column_mapping)
# 打印前10条数据
# print(df.head(10))
# ===================================海龟策略===================================================
# 设置移动平均线窗口期
ma_short_window = 20
ma_long_window = 50
# 计算移动平均线
df['MA20'] = df['Close'].rolling(window=ma_short_window, min_periods=1).mean()
df['MA50'] = df['Close'].rolling(window=ma_long_window, min_periods=1).mean()
# 移除NaN值
df.dropna(subset=['MA50'], inplace=True)
# 定义海龟策略函数
def turtle_trading_strategy(df):
# 从策略参数
initial_capital = 1000000 # 初始资金
unit_size = 100 # 每次交易量
# 确定买入和卖出信号
df['Buy_Signal'] = df['Close'].gt(df['MA20']) & df['Close'].shift(1).lt(df['MA20'].shift(1))
df['Sell_Signal'] = df['Close'].lt(df['MA20']) & df['Close'].shift(1).gt(df['MA20'].shift(1))
# 计算持仓量和资金曲线
df['Position'] = 0
df.loc[df['Buy_Signal'], 'Position'] = unit_size
df.loc[df['Sell_Signal'], 'Position'] = -unit_size
df['Total_Value'] = df['Position'] * df['Close'].shift(-1)
# 计算每日盈亏和总盈亏
# df['Daily_Return'] = df['Total_Value'].pct_change()
df['Daily_Return'] = df['Total_Value'].pct_change(fill_method=None)
# 清除NaN和inf值
df['Daily_Return'].replace([np.inf, -np.inf], np.nan, inplace=True)
df['Daily_Return'].fillna(0, inplace=True)
df['Cumulative_Return'] = (df['Daily_Return'] + 1).cumprod()
# 计算总收益和平均收益
cumulative_returns = df['Cumulative_Return'].iloc[-1] * initial_capital - initial_capital
total_trades = df[df['Position'] != 0].shape[0]
average_return = cumulative_returns / total_trades
return cumulative_returns, average_return
print(df)
# 调用turtle_trading_strategy函数
total_profit, average_return = turtle_trading_strategy(df)
print(f"总交易次数:{df[df['Position'] != 0]['Position'].count()}")
print(f"总盈利:{total_profit:.2f}元")
print(f"平均收益:{average_return:.2f}元/交易")
# 绘图
import mplfinance as mpf
import matplotlib.pyplot as plt
# ==================绘制K线图和移动平均线图========================
plt.rcParams['font.family'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 设置负号显示
# 添加移动平均线参数
ap0 = [
mpf.make_addplot(df['MA20'], color="b", width=1.5),
mpf.make_addplot(df['MA50'], color="y", width=1.5),
]
market_colors = mpf.make_marketcolors(up='red', down='green')
my_style = mpf.make_mpf_style(marketcolors=market_colors)
# 绘制K线图
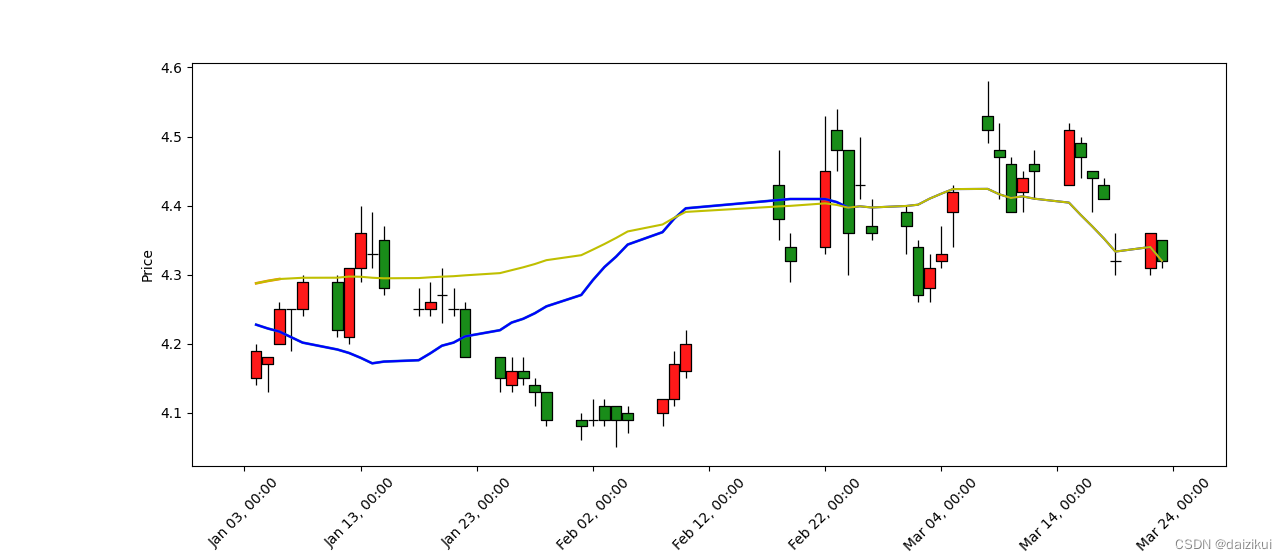
mpf.plot(df, type='candle',
figratio=(10, 4),
mav=(ma_short_window, ma_long_window),
show_nontrading=True,
addplot=ap0,
style=my_style)
mpf.show()
# ==================绘制交易信号图========================
# 设置图表大小
plt.figure(figsize=(10, 6))
plt.rcParams['font.family'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 设置负号显示
plt.plot(df['Close'], label='收盘价')
plt.plot(df.loc[df['Buy_Signal'], 'Close'], 'o', markersize=8, color='green', label='买入信号')
plt.plot(df.loc[df['Sell_Signal'], 'Close'], 'o', markersize=8, color='red', label='卖出信号')
plt.title('交易信号')
plt.xlabel('日期')
plt.ylabel('价格')
plt.legend()
# 调整 x 轴标签倾斜
plt.xticks(rotation=45)
plt.grid(True)
plt.show()
图表

三,scikit-learn 使用分类策略预测苹果股票走势
新数据
新数据.csv
Date,Close,Volume,Open,High,Low
2023/6/1,$186.68,53117000,$185.55,$187.56,$185.01
2023/6/2,$187.00,51245330,$183.74,$187.05,$183.67
2023/6/3,$183.96,49515700,$184.90,$185.41,$182.59
2023/6/4,$185.01,49799090,$184.41,$186.10,$184.41
2023/6/5,$184.92,101256200,$186.73,$186.99,$184.27
2023/6/6,$186.01,65433170,$183.96,$186.52,$183.78
2023/6/7,$183.95,57462880,$183.37,$184.39,$182.02
2023/6/8,$183.31,54929130,$182.80,$184.15,$182.44
2023/6/9,$183.79,54755000,$181.27,$183.89,$180.97
2023/6/10,$180.96,48899970,$181.50,$182.23,$180.63
2023/6/11,$180.57,50214880,$177.90,$180.84,$177.46
2023/6/12,$177.82,61944620,$178.44,$181.21,$177.32
2023/6/13,$179.21,64848370,$179.97,$180.12,$177.43
2023/6/14,$179.58,121946500,$182.63,$184.95,$178.04
2023/6/15,$180.95,61996910,$181.03,$181.78,$179.26
2023/6/16,$180.09,68901810,$177.70,$180.12,$176.93
2023/6/17,$177.25,99625290,$177.33,$179.35,$176.76
2023/6/18,$177.30,55964400,$176.96,$178.99,$176.57
2023/6/19,$175.43,54834980,$173.32,$175.77,$173.11
2023/6/20,$172.99,56058260,$172.41,$173.90,$171.69
代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.metrics import accuracy_score
import joblib
# 数据准备和处理
data = pd.read_csv('AAPL.csv')
data['Close'] = data['Close'].str.replace('$', '').astype(float)
data['Open'] = data['Open'].str.replace('$', '').astype(float)
data['High'] = data['High'].str.replace('$', '').astype(float)
data['Low'] = data['Low'].str.replace('$', '').astype(float)
# 创建标签列
data['Label'] = data['Close'].diff().gt(0).astype(int)
# 提取特征和目标变量
X = data[['Volume', 'Open', 'High', 'Low']]
y = data['Label']
# 划分训练集测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# 构建Pipeline
pipe = Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler()),
('model', LogisticRegression())
])
# 模型训练
pipe.fit(X_train, y_train)
# 保存模型
joblib.dump(pipe, 'model.pkl')
# 测试集预测
y_pred = pipe.predict(X_test)
# 准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"准确率: {accuracy}")
import pandas as pd
import joblib
# 加载模型
loaded_model = joblib.load('model.pkl')
# 新数据准备
new_data = pd.read_csv('新数据.csv')
new_data['Close'] = new_data['Close'].str.replace('$', '').astype(float)
new_data['Open'] = new_data['Open'].str.replace('$', '').astype(float)
new_data['High'] = new_data['High'].str.replace('$', '').astype(float)
new_data['Low'] = new_data['Low'].str.replace('$', '').astype(float)
# 删除Close和Date特征列
new_data.drop('Close', axis=1, inplace=True)
new_data.drop('Date', axis=1, inplace=True)
# 预测结果
predicted_labels = loaded_model.predict(new_data)
# 输出预测结果
for i, label in enumerate(predicted_labels):
print(f"样本{i+1}的预测结果:{label}")预测结果
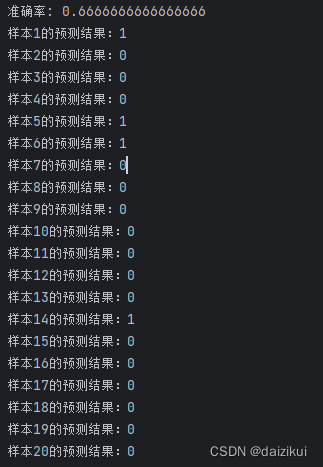
四,scikit-learn 使用回归策略预测苹果股票走势
代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import joblib
# 1. 数据准备和处理
data = pd.read_csv('AAPL.csv')
data['Close'] = data['Close'].str.replace('$', '').astype(float)
data['Open'] = data['Open'].str.replace('$', '').astype(float)
data['High'] = data['High'].str.replace('$', '').astype(float)
data['Low'] = data['Low'].str.replace('$', '').astype(float)
# 提取特征和目标变量
X = data[['Volume', 'Open', 'High', 'Low']]
y = data['Close']
# 划分训练集测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# 2. 模型训练
model = LinearRegression()
model.fit(X_train, y_train)
# 3. 测试集预测
y_pred = model.predict(X_test)
# 4. 模型评估
mse = mean_squared_error(y_test, y_pred)
print(f"均方误差 (MSE): {mse}")
# 保存模型数据
joblib.dump(model, 'model2.pkl')
# =======================预测股票走势=====================
# 加载模型
loaded_model = joblib.load('model2.pkl')
# 新数据准备
new_data = pd.read_csv('HistoricalData_1687681340565.csv')
new_data['Close'] = new_data['Close'].str.replace('$', '').astype(float)
new_data['Open'] = new_data['Open'].str.replace('$', '').astype(float)
new_data['High'] = new_data['High'].str.replace('$', '').astype(float)
new_data['Low'] = new_data['Low'].str.replace('$', '').astype(float)
# 删除或保持"Volume"特征列为空值
# new_data.drop('Volume', axis=1, inplace=True)
new_data.drop('Close', axis=1, inplace=True)
new_data.drop('Date', axis=1, inplace=True)
predicted_labels = loaded_model.predict(new_data)
# 输出预测结果
for label in predicted_labels:
print("预测结果:", label)
预测结果