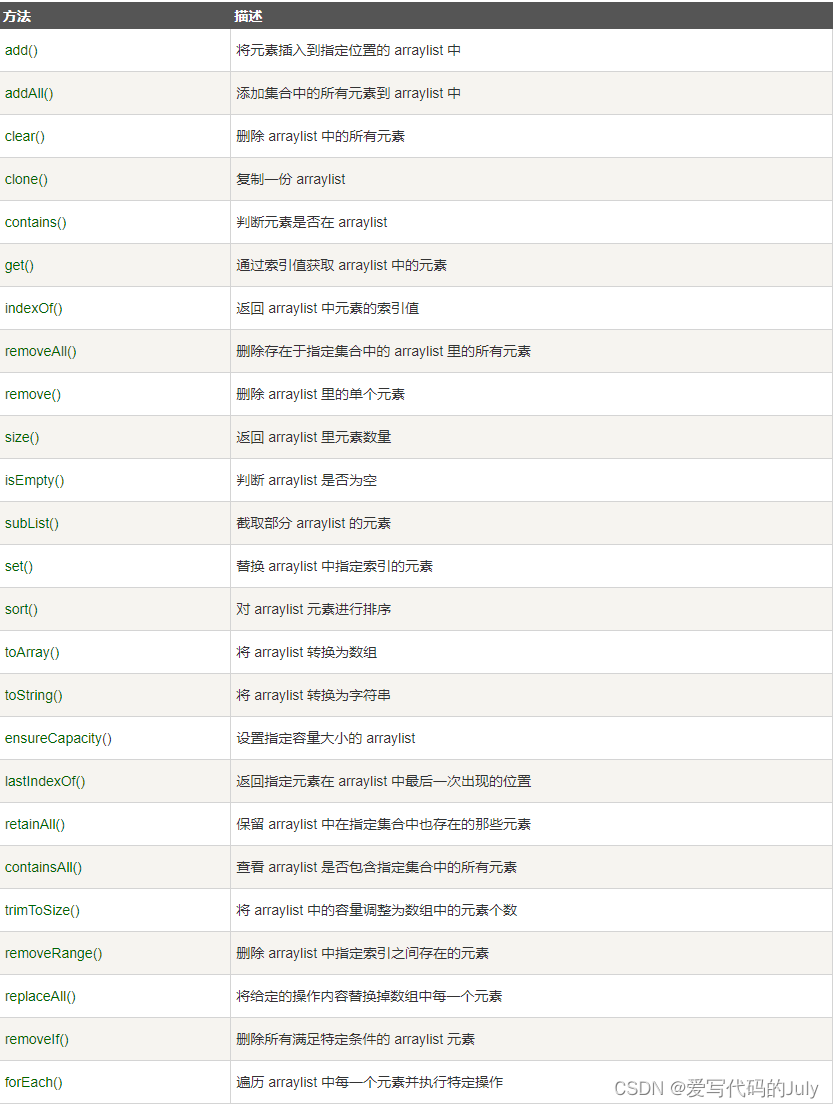
几个常用术语
-
模型=公式+参数
-
K矩阵:字典
V矩阵:关键字的权重数值 -
AGI:通用人工智能
-
分词、词性关联、词性标注、知识图谱。分词操作是AI的开发,但是离AGI越来越远。自注意力机制的核心思想是摒弃分词等操作,面向更通用的场景去实现
-
大模型全称大语言模型:LLM
-
大模型技术:
一阶技术:
二阶技术:向量数据库,向量检索,LangChain,sk,智能体
三阶技术:Fine-tune(模型定制,专业领域,垂直行业等场景) -
GPT1,2,3,3.5 都有一篇论文,4只有一篇技术报告
-
RL :reinforcement learing 强化学习。RLHF:Reinforcement Learning fromHuman Feedback 基于人类反馈的强化学习
-
开源模型:LLama,GLM,百川,羊驼模型
-
midjourney 画图软件;stable diffusion SD
1.GPT定义
GPT是[Generative Pre-trained Transformer]的缩写,意为生成式预训练变换器.
-
G 代表 Generative (生成式): 这是一种机器学习模型,其目标是学习数据的分布,并能生成与训练数据相似的新数据。在自然语言处理 (NLP)领域,生成式模型可以生成类似于人类所写的文本。GPT模型作为一个生成式模型,能够根据给定的上下文生成连贯的文本。
-
P 代表 Pre-trained(预训练): 预训练是深度学习领域的一种常见方法,通过在大规模数据集上进行训练,模型学习到一般的知识和特征。这些预训练的模型可以作为基础模型,针对具体任务进行微调。GPT模型通过预训练,在无标签的大规模文本数据集上学习语言模式和结构,为后续的任务提供基础。
-
T代表Transformer (变换器): Transformer 是一种在自然语言处理中广泛使用的神经网络结构它通过自注意力 (Self-Attention)机制有效地捕捉上下文信息,处理长距离依赖关系,并实现并行计算。GPT模型采用Transformer结构作为基础,从而在处理文本任务时表现出优越性能。
2.注意力机制-Attention Is All You Need
谷歌2017年发表论文《Attention Is All You Need》,在注意力机制的使用方面取得了很大的进步,对
Transformer模型做出了重大改进。

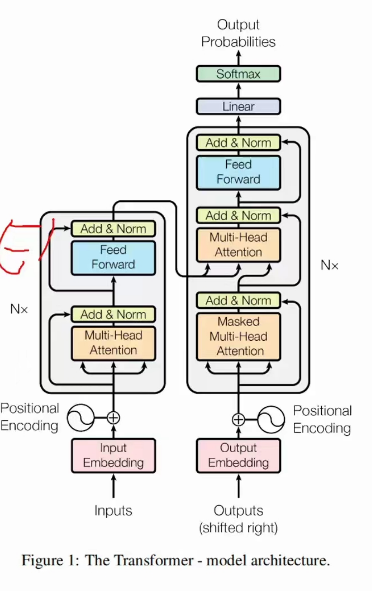
3.Transformer框架
Most competitive neural sequence transduction models have an encoder-decoder structure [5,2,35] .Here, the encoder maps an input sequence of symbol representations (x1,…,xn) to a sequenceof continuous representations z = (z1,…, zn ). Given z, the decoder then generates an outputsequence (y1, …, ym ) of symbols one element at a time. At each step the model is auto-regressive[10], consuming the previously generated symbols as additional input when generating the next.
The Transformer follows this overall architecture using stacked self-attention and point-wise, fullyconnected layers for both the encoder and decoder, shown in the left and right halves of Figure 1 respectively.
模型体系结构最有竞争力的神经序列转导模型的编码器-解码器结构[5,2,35],在这里,编码器映射符号表示的输入序列(X1,…,x)转换成一系列连续表示Z=(z1,…zn)。给定Z,解码器然后生成输出序列(y1,…ym)的符号,一次一个元素。模型在每一步都是自回归的[10],在生成下一个符号时,使用先前生成的符号作为附加输入。Transformer遵循这一总体架构,编码器和解码器都使用堆叠的自我关注和逐点全连接层,分别如图1的左半部分和右半部分所示
Transformer框架,左边是一个编码器模型,右边是一个解码器模型。
4.数据训练
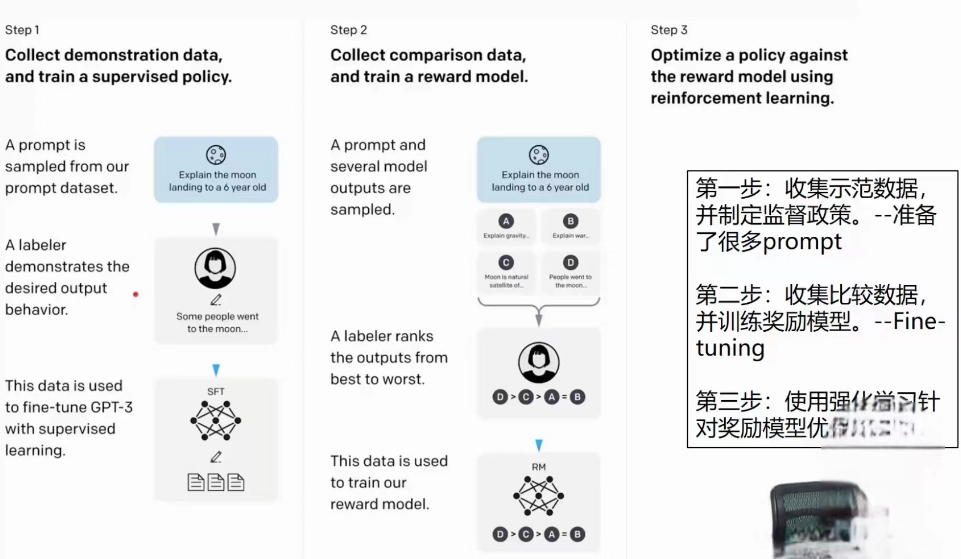
To train the very first InstructGPT models, we asked labelers to write prompts themselves. This is because we needed an initial source of instruction-like prompts to bootstrap the process, and these kinds of prompts weren’t often submitted to the regular GPT-3 models on the API We asked labelersto write three kinds of prompts:
- Plain: We simply ask the labelers to come up with an arbitrary task, while ensuring the tasks had sufficient diversity.
- Few-shot: We ask the labelers to come up with an instruction, and multiple query/response pairs for that instruction.
- User-based: We had a number of use-cases stated in waitlist applications to the OpenAl API. We asked labelers to come up with prompts corresponding to these use cases.
5.LangChain
(1).LangChain是个啥
- 面向大模型的开发框架
- 简单实现复杂功能的AI应用
- 多组件封装
LangChain是一个开源的框架,它可以让AI开发人员把像GPT-4这样的大型语言模型 (LLM)和外部数据结合起来。
用户可以利用LangChain的模块来改善大语言模型的使用,通过输入自己的知识库来“定制化”自己的大语言模型。
(2). LangChain官方教程
- 很好的中文教程:
https://github.com/liaokongVFX/LangChain-Chinese-Getting-Started-Guide - 中文官方:
https://www.langchain.asia - 官方文档:
https://python.langchain.com/docs/get_started/introduction.html - 官方代码:
https://github.com/langchain-ai/langchain
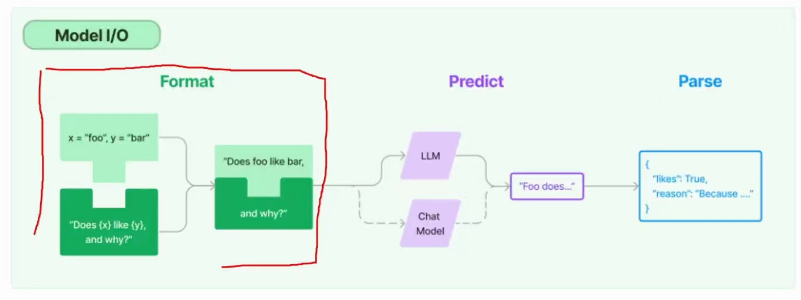
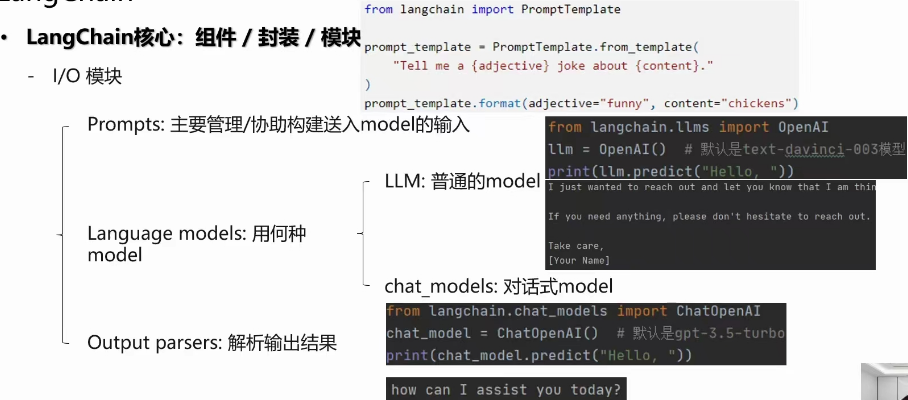
(3). LangChain核心:组件/封装/模块

(4).IO 模块