如果您考虑为您的文件或网站制作一个能够回应您的个性化机器人,那么您来对地方了。我可以帮助您使用Langchain和RAG策略来创建这样一个机器人。
了解ChatGPT的局限性和LLMs
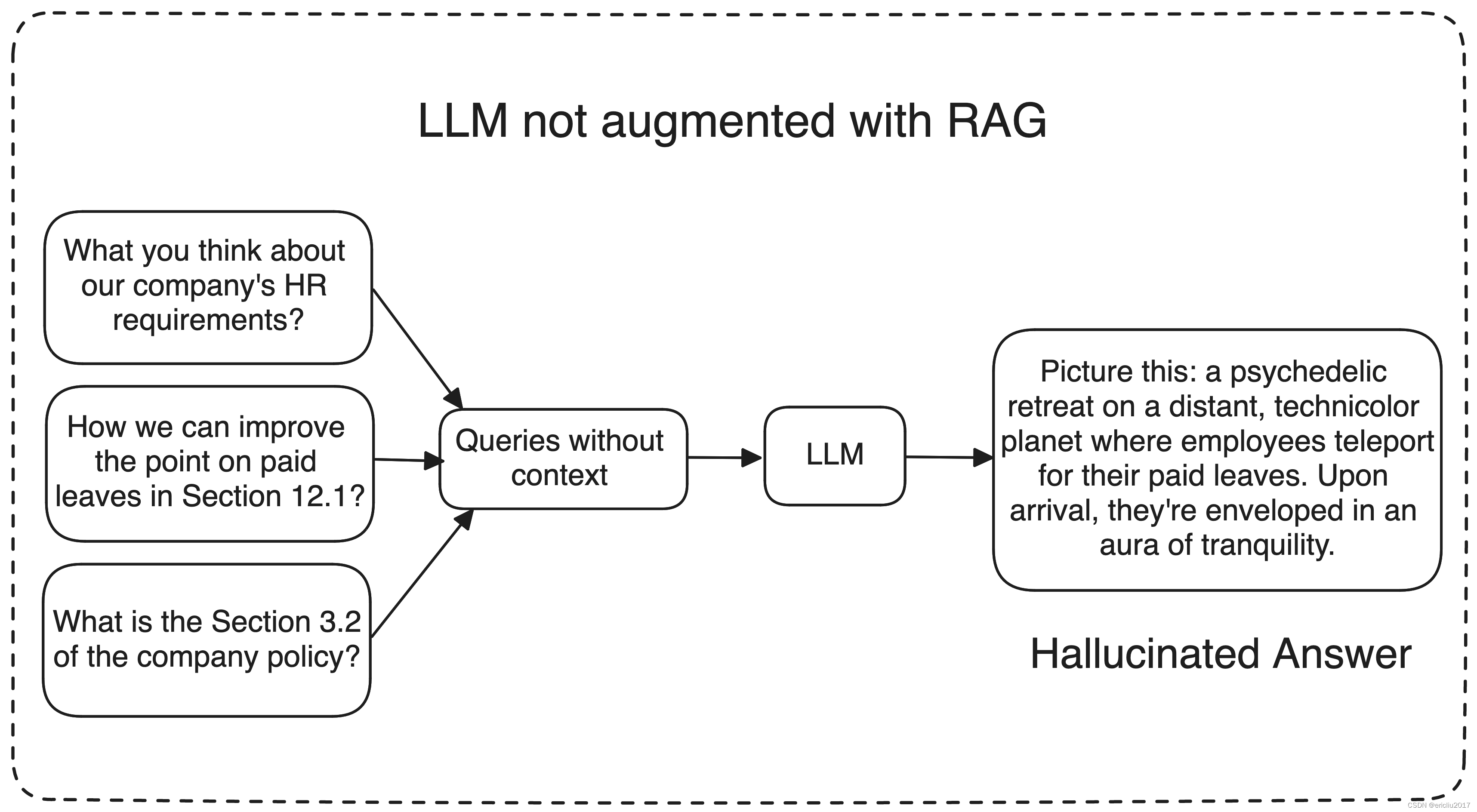
ChatGPT和其他大型语言模型(LLMs)经过广泛训练,以理解语言的语义和连贯性。尽管它们具有令人印象深刻的能力,但这些模型也存在一些限制,需要在特定用例中进行仔细考虑。
一个重要的挑战是可能出现幻觉,模型可能会生成不准确或与上下文无关的信息。
想象一下,要求模型改进您公司的政策;在这种情况下,ChatGPT和其他大型语言模型可能会难以提供准确的回答,因为它们缺乏对您公司数据的训练。
相反,它们可能会生成毫无意义或无关的回复,这可能没有帮助。那么,我们如何确保LLM理解我们的特定数据,并相应地生成回复呢?这就是检索增强生成(RAG)等技术发挥作用的地方。
RAG是什么?
RAG或检索增强生成使用三种主要工作流程来生成并提供更好的响应
-
信息检索:当用户提出问题时,AI系统从维护良好的知识库或外部来源(如数据库、文章、API或文档存储库)中检索相关数据。
这是通过将查询转换为机器可以理解的数字格式或向量来实现的。 -
LLM: 然后将检索到的数据呈现给LLM或大型语言模型,以及用户的查询。 LLM使用这些新知识和其训练数据来生成响应。
-
最终,LLM生成的响应更准确和相关,因为它已经通过检索到的信息进行了增强。
我是说我们从我们的知识库中为LLM提供了一些额外信息,这使得LLMs能够提供更具上下文相关和事实性的回答,解决了模型仅仅是在产生幻觉或提供无关答案的问题。
再举个公司政策的例子。假设你有一个处理与公司政策相关查询的人力资源机器人。
现在,如果有人询问有关政策的具体内容,机器人可以从知识库中提取最新的政策文件,将相关上下文传递给精心设计的提示,然后进一步传递给LLM以生成回应。
为了让事情更简单,想象一个LLM就像你博学的朋友,似乎什么都知道,从地理到计算机科学,从政治到哲学。现在,想象你自己问这个朋友一些问题:
- 周末谁负责洗我的衣服?
- “谁住在我隔壁?”
- 我更喜欢哪个牌子的花生酱?
很可能你的朋友无法回答这些问题。大多数时候是这样。
但假设这位遥远的朋友随着时间变得更加亲近,他经常来你家,很了解你的父母,你们经常一起出去玩,你们一起外出,等等等等.. 你懂的。
我的意思是他正在获取关于你的个人和内部信息。现在,当你提出同样的问题时,他可以以更相关的方式回答这些问题,因为他更适合你的个人见解。
同样,一个LLM在提供额外信息或访问您的数据时,不会猜测或产生幻觉。相反,它可以利用这些访问的数据提供更相关和准确的答案。
具体步骤如下,用于创建任何RAG应用程序..
- 从您的数据来源中提取相关信息。
- 把信息分成小块。
- 将这些块存储为它们的嵌入到一个向量数据库中。
- 创建一个提示模板,该模板将与查询和上下文一起输入到LLM中。
- 使用相同的嵌入模型将查询转换为其相关的嵌入。
- 从向量数据库中获取与查询相关的 k 个相关文档。
- 将相关文件传递给LLM并获取回复。
常见问题解答
-
我们将在这个任务中使用Langchain,基本上它就像一个包装器,让你更好地交流和管理你的LLM操作。请注意,Langchain更新非常快,一些功能和其他类可能会移动到不同的模块中。
所以如果有什么东西不起作用,只需检查一下你是否从正确的来源导入了库! -
我们将使用Hugging Face,这是一个用于构建、训练和部署最先进的机器学习模型的开源库,特别是关于自然语言处理。要使用HuggingFace,我们需要访问令牌,请在这里获取您的访问令牌。
-
对于我们的模型,我们将需要两个关键组件:一个LLM(大型语言模型)和一个嵌入模型。虽然像OpenAI这样的付费来源提供了这些,但我们将利用开源模型,以确保所有人都能够访问。
-
现在我们需要一个向量数据库来存储我们的嵌入。为此,我们有LanceDB——它就像一个超级智能的数据湖,可以处理大量信息。它是一流的向量数据库,使其成为处理向量嵌入等复杂数据的首选。而最棒的部分呢?
它不会在你的口袋里留下一丝痕迹,因为它是开源的,可以免费使用! -
为了简化流程,我们的数据摄取过程将涉及使用一个URL和一些PDF文件。如果需要,您可以整合其他数据源,但目前我们将专注于这两种数据源。
有了Langchain作为接口,Hugging Face用于获取模型,再加上开源组件,我们已经准备就绪!这样一来,我们既能节省一些开支,又能拥有所需的一切。让我们继续下一步。
环境设置
我正在使用 MacBook Air M1,需要注意的是,某些依赖和配置可能会因使用的系统类型而有所不同。现在打开你喜欢的编辑器,创建一个 Python 环境并安装相关的依赖。
# Create a virtual environment
python3 -m venv env
# Activate the virtual environment
source env/bin/activate
# Upgrade pip in the virtual environment
pip install --upgrade pip
# Install required dependencies
pip3 install lancedb langchain langchain_community prettytable sentence-transformers huggingface-hub bs4 pypdf pandas
# This is optional, I did it for removing a warning
pip3 uninstall urllib3
pip3 install 'urllib3<2.0'现在在相同的目录中创建一个 .env 文件,将您的 Hugging Face api 凭据放在其中,就像这样
HUGGINGFACEHUB_API_TOKEN = hf_KKNWfBqgwCUOHdHFrBwQ.....
确保名称“HUGGINGFACEHUB_API_TOKEN”保持不变,因为这对于身份验证至关重要。
如果您喜欢直接的方法,而不依赖外部包或文件加载,您可以在代码中直接配置环境变量,就像这样。
HF_TOKEN = "hf_KKNWfBqgwCUOHdHFrBwQ....."
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HF_TOKEN在项目的根目录中创建一个名为data的文件夹,用于存储PDF文档的中央存储库。您可以添加一些用于测试的示例PDF;例如,我正在使用Yolo V7和Transformers论文进行演示。重要的是要注意,这个指定的文件夹将作为我们数据摄取的主要来源。
好像一切都井井有条,我们已经准备就绪了!
步骤1:提取相关信息
为了让您的RAG应用程序运行起来,我们首先需要做的是从各种数据源中提取相关信息。无论是网页、PDF文件、notion链接、谷歌文档,都需要首先从其原始来源中提取信息。
import os
from langchain_community.document_loaders import WebBaseLoader, PyPDFLoader, DirectoryLoader
# Put the token values inside the double quotes
HF_TOKEN = "hf_*******"
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HF_TOKEN
# Loading the web url and data
url_loader = WebBaseLoader("https://gameofthrones.fandom.com/wiki/Jon_Snow")
documents_loader = DirectoryLoader('data', glob="./*.pdf", loader_cls=PyPDFLoader)
# Creating the instances
url_docs = url_loader.load()
data_docs = documents_loader.load()
# Combining all the data that we ingested
docs = url_docs + data_docs这将摄取URL链接和PDF中的所有数据。
步骤2:将信息分解成较小的部分
我们已经拥有开发RAG应用所需的所有数据。现在,是时候将这些信息分解成更小的部分。之后,我们将利用嵌入模型将这些部分转换为它们各自的嵌入。但为什么这很重要呢?
就像这样想:如果你被要求一次性阅读一本100页的书,然后被问及一个特定的问题,从整本书中检索必要的信息来回答将是具有挑战性的。
然而,如果你被允许将书分成更小、可管理的部分——比如每部分10页——并且每个部分都标有从0到9的索引,那么这个过程就变得简单得多。
当相同问题在此分解后提出时,您可以根据其索引轻松找到相关的块,然后提取需要回答问题的信息。
把这本书想象成你提取的信息,每10页代表一小部分数据,目录页则是嵌入。基本上,我们会对这些部分应用嵌入模型,将信息转化为它们各自的嵌入。
作为人类,我们可能无法直接理解或与这些嵌入产生共鸣,但它们可以作为我们应用程序中块的数值表示。这就是你可以在Python中做到这一点的方式。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1000, chunk_overlap = 50)
chunks = text_splitter.split_documents(docs)现在chunk_size参数指定了一个块可以包含的最大字符数,而chunk_overlap参数指定了相邻两个块之间应该重叠的字符数。
将chunk_overlap设置为50后,相邻块的最后50个字符将彼此共享。
这种方法有助于防止重要信息分散在两个块中,确保每个块包含足够的上下文信息,以便进行后续处理或分析。
相邻块边界共享的信息可以使文本内容更流畅地过渡和理解。
选择chunk_size和chunk_overlap参数的最佳策略很大程度上取决于文档的性质和应用程序的目的。
步骤3:创建嵌入并将其存储到向量数据库中
我们有两种主要方法来为我们的文本块生成嵌入。第一种方法涉及下载模型,管理预处理,并独立进行计算。
我们也可以利用Hugging Face的模型中心,该中心提供了各种预训练模型,用于各种自然语言处理任务,包括嵌入生成。
选择后一种方法可以让我们利用Hugging Face的嵌入模型之一。通过这种方法,我们只需将我们的文本块提供给所选的模型,从而避免在本地机器上进行资源密集型的计算。💀
Hugging Face的模型中心提供了许多嵌入模型的选项,您可以浏览排行榜,选择最适合您需求的模型。目前,我们将继续使用"sentence-transformers/all-MiniLM-L6-v2"。这个模型在我们的任务中非常快速和高效!!
from langchain_community.embeddings import HuggingFaceEmbeddings
embedding_model_name = 'sentence-transformers/all-MiniLM-L6-v2'
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_name, model_kwargs={'device': 'cpu'})这是一种查看每个块嵌入数量的方法
query = "Hello I want to see the length of the embeddings for this document."
len(embeddings.embed_documents([query])[0])
# 384我们已经有了我们块的嵌入,现在我们需要一个向量数据库来存储它们。
说到向量数据库,市面上有很多选项,适合各种需求。像Pinecone这样的数据库提供了足够的性能和先进的功能,但价格昂贵。
另一方面,像FAISS或Chroma这样的开源替代方案可能缺少一些额外功能,但对于那些不需要大规模可扩展性的人来说已经足够了。
但等等,我要来个大新闻,最近我发现了LanceDB,它是一个开源的向量数据库,类似于FAISS和Chroma。LanceDB的独特之处不仅在于它的开源性质,还在于它无与伦比的可扩展性。
其实,仔细一看,我意识到我之前没有充分突出LanceDB的真正价值主张!!
令人惊讶的是,LanceDB是目前最具可扩展性的向量数据库,甚至超过了Pinecone、Chroma、Qdrant等其他数据库。在您的笔记本电脑上本地扩展至十亿个向量,这是只有LanceDB才能实现的壮举。
我的意思是,这种能力是一个改变游戏规则的因素,特别是当你把它与其他向量数据库进行比较时,即使是处理一亿个向量的数据库也会遇到困难。
更令人惊叹的是,LanceDB设法以极低的成本实现了前所未有的可扩展性,我是说,他们提供的实用工具和数据库工具的价格比最接近的竞争对手要便宜得多。
现在,我们将通过调用 lancedb.connect("lance_database") 创建LanceDB向量数据库的实例。这行代码基本上是建立了一个到名为“lance_database”的LanceDB数据库的连接。接下来,我们使用create_table函数在数据库中创建一个名为“rag_sample”的表。
现在我们使用单个数据条目初始化了这个表,其中包括由embed_query函数生成的数值向量。因此,“Hello World”文本首先被转换为它的数值表示(嵌入的花哨名称),然后被映射到 id 号码1。就像一个键值对。最后,mode="overwrite"参数确保如果表"rag_sample"已经存在,它将被新数据覆盖。
所有文本块都会发生这种情况,非常简单。这是在Python中的样子。
import lancedb
from langchain_community.vectorstores import LanceDB
db = lancedb.connect("lance_database")
table = db.create_table(
"rag_sample",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
docsearch = LanceDB.from_documents(chunks, embeddings, connection=table)不是什么高深的科学哈!
第四步:创建一个提示模板,该模板将被提供给LLM
好的,现在是提示模板。当您向ChatGPT提出问题并得到回答时,实际上是在为模型提供提示,以便它能理解问题是什么。
当公司训练模型时,他们决定要使用什么样的提示来调用模型并提出问题。例如,如果您正在使用“Mistral 7B instruct”并且希望获得最佳结果,建议使用以下聊天模板:
<s>[INST] Instruction [/INST] Model answer</s>[INST] Follow-up instruction [/INST]
注意, 和 是特殊标记,用于表示字符串的开头(BOS)和结尾(EOS),而 [INST] 和 [/INST] 则是常规字符串。
就是 Mistral 7B 指令是这样制作的,模型会寻找特殊标记以更好地理解问题。不同类型的 LLMs 有不同类型的指示提示。
现在对于我们的案例,我们将使用huggingfaceh4/zephyr-7b-alpha,这是一个文本生成模型。
只是为了明确,Zephyr-7B-α并没有通过RLHF(强化学习与人类反馈)等技术对其进行人类偏好的调整或格式化,也没有像ChatGPT那样进行响应的过滤,因此该模型可能会产生问题输出(特别是在被提示时)。
我会使用ChatPromptTemplate类来创建聊天模型的提示模板,而不是编写自己的提示。通俗地说,我让ChatPromptTemplate来为我创建指定的提示。
这是一个示例提示模板,是从手动消息中生成的。
from langchain_core.prompts import ChatPromptTemplate
chat_template = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
]
)
messages = chat_template.format_messages(name="Bob", user_input="What is your name?")如果你不想编写手册说明,你可以使用from_template函数来生成一个更通用的提示模板,我在这个项目中使用了这个方法。就是这样。
from langchain_core.prompts import ChatPromptTemplate
template = """
{query}
"""
prompt = ChatPromptTemplate.from_template(template)我们的提示已经设置好了!我们设计了一条单一的消息,假设它是来自一个人类 xD。如果您没有使用from_messages函数,ChatPromptTemplate将通过保留一些额外的系统消息,确保您的提示与语言模型无缝配合。
现在这个设置应该可以运行,但是通过更通用的提示可以实现更好的结果,总是有改进的空间。
第五步:使用相同的嵌入模型将查询转换为其相关的嵌入。
现在,让我们谈谈我们想要问我们的RAG应用程序的查询或问题。我们不能只是将查询传递给我们的模型,并期望得到信息。相反,我们需要通过先前用于块的相同嵌入模型传递查询。为什么这很重要?
嗯,通过嵌入查询,我们使模型能够高效地与先前处理过的文本块进行比较。这使得诸如查找相似文档或生成相关回复之类的任务成为可能。
为了更好地理解,想象一下你和你的朋友说不同的语言,比如英语和印地语,你们需要理解彼此的书写。如果你的朋友递给你一张印地语的页面,你不会直接理解它。
所以,你的朋友先翻译它,将印地语翻译成英语给你。所以现在如果你的朋友用印地语问你一个问题,你可以先把那个问题翻译成英语,然后查找相关的答案。
同样,我们最初将文本信息转换为它们对应的嵌入。现在,当您提出一个查询时,它会经过类似的转换,使用之前应用于处理我们文本块的相同嵌入模型,转换为数字形式。
这一一贯的方法可以有效地检索相关的回答。
第六步:获取K个文档。
现在,让我们来谈谈检索器。它的工作是深入向量数据库并执行搜索,以找到相关的文档。
它返回一组文件编号,我们称之为“k”,这些文件根据它们与您提出的查询或问题的上下文相关性进行排名。您可以将“k”设置为参数,指示您想要多少相关文件-无论是2、5还是10。通常,如果您有较少的数据,最好使用较低的“k”,大约为2。对于较长的文件或更大的数据集,建议将“k”设置在10到20之间。
可以采用不同的搜索技术来更有效快速地从向量数据库中获取相关文档。选择取决于各种因素,如您的具体用例、数据量、所使用的向量数据库类型以及问题的上下文。
retriever = docsearch.as_retriever(search_kwargs={"k": 3})
docs = retriever.get_relevant_documents("what did you know about Yolo V7?")
print(docs)当您运行此代码时,检索器将从向量数据库中获取3个最相关的文档。所有这些文档将成为我们的LLM模型生成查询响应的上下文。
步骤7:将相关文件传递给LLM并获取回应。
到目前为止,我们已要求我们的检索器从数据库中获取一组相关文件。现在,我们需要一个语言模型(LLM)根据这个上下文生成一个相关的回应。
为了确保稳健性,让我们记住在这篇博客的开头,我提到LLMs像ChatGPT这样的模型有时会生成无关的回复,特别是在涉及特定用例或情境时。
然而,这一次,我们将提供我们自己数据的背景作为LLM的参考。因此,它将考虑这个参考以及它的一般能力来回答问题。这就是使用RAG的整个理念!
现在,让我们深入实施我们的RAG设置中的语言模型(LLM)部分。我们将使用Hugging Face Hub中的zephyr模型架构。以下是我们在Python中的操作方式:
from langchain_community.llms import HuggingFaceHub
# Model architecture
llm_repo_id = "huggingfaceh4/zephyr-7b-alpha"
model_kwargs = {"temperature": 0.5, "max_length": 4096, "max_new_tokens": 2048}
model = HuggingFaceHub(repo_id=llm_repo_id, model_kwargs=model_kwargs)在这段代码片段中,我们正在使用Hugging Face Hub 实例化我们的语言模型。具体来说,我们选择了放置在这个存储库ID“huggingfaceh4/zephyr-7b-alpha”中的zephyr 7 billion 模型。选择这个模型并非任意;正如我之前所说,这是基于模型对我们特定任务和需求的适用性。
由于我们已经只实施开源组件,Zephyr 70亿足够好地生成有用的响应,而且开销最小,延迟低。
这个模型带有一些额外的参数来微调其行为。我们将温度设置为0.5,这控制着生成文本的随机性。
较低的温度往往会导致更保守和可预测的输出,当温度设置为最大值1时,模型会尽可能地创造性,因此根据您的用例需要的输出类型,您可以调整此参数。
为了简单起见和演示目的,我将其设置为0.5,以确保我们获得体面的结果。接下来是max_length参数,它定义了生成文本的最大长度,包括您的提示和响应的大小。
max_new_tokens设置了可以生成的最大新标记数量的阈值。一般来说,max_new_tokens应始终小于或等于max_length参数。为什么?想想看。。
第八步:创建一个用于调用LLM的链。
我们的RAG应用程序所需的一切都已准备就绪,我们需要做的最后一件事是创建一个调用查询中的LLM以生成响应的链。
有不同类型的链条适用于不同的使用情况,如果你希望你的 LLM 能够在一段时间内记住聊天的上下文,就像ChatGPT一样,你需要一个可以在多个对话片段之间共享的记忆实例,对于这种情况,有可用的对话链条。
目前我们只需要一个链条,它可以将我们检索到的上下文组合起来,并将其与查询一起传递给LLM以生成响应。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever, "query": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
response = rag_chain.invoke("Who killed Jon Snow?")我们有我们的提示,模型,上下文和查询!它们都被合并成一个单一的链条。这基本上就是所有链条所做的事情!现在在运行最终代码之前,我想快速检查一下这两个辅助函数: RunnablePassthrough() 和 StrOutputParser() 。
在 LangChain 中的 RunnablePassthrough 类用于传递输入,保持不变或带有额外的键。在我们的链中,提示期望以“context”和“question”键的形式接收输入。然而,用户输入只包括“question”或“query”。在这里, RunnablePassthrough 被用来将用户的问题传递到“question”键下,同时使用检索器检索上下文。这只是确保提示的输入符合预期的格式。
通常, StrOutputParser 在RAG链中被用来将模型的输出解析成易于理解的字符串。简单来说,它负责将模型的输出转换成更连贯和语法正确的句子,通常更容易被人类理解阅读!
就是这样!
登陆日

为了确保即使响应被截断,我们也能获取完整的想法,我实现了一个名为 get_complete_sentence() 的函数。基本上,这个函数帮助从文本中提取最后一个完整的句子。因此,即使响应达到我们设定的最大标记限制并在中途被截断,我们仍然能够获得对消息的连贯理解。
为了实际测试,我建议将一些小型PDF存储在项目的数据文件夹中。您可以选择与您希望聊天机器人互动的各种主题或领域相关的PDF。
另外,提供一个URL作为聊天机器人的参考可能有助于测试。例如,您可以使用维基百科页面、研究论文或与您的测试目标相关的任何其他在线文档。
在我的测试中,我使用了包含有关《权力的游戏》中琼恩·雪的信息的网址,以及变形金刚论文和 YOLO V7 论文的 PDF 文件来评估机器人的表现。让我们看看我们的机器人在不同内容中的表现如何。
import os
import time
import lancedb
from langchain_community.vectorstores import LanceDB
from langchain_community.llms import HuggingFaceHub
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import LanceDB
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import WebBaseLoader, PyPDFLoader, DirectoryLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from prettytable import PrettyTable
HF_TOKEN = "hf*********"
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HF_TOKEN
# Loading the web URL and breaking down the information into chunks
start_time = time.time()
loader = WebBaseLoader("https://gameofthrones.fandom.com/wiki/Jon_Snow")
documents_loader = DirectoryLoader('data', glob="./*.pdf", loader_cls=PyPDFLoader)
# URL loader
url_docs = loader.load()
# Document loader
data_docs = documents_loader.load()
# Combining all the information into a single variable
docs = url_docs + data_docs
# Specify chunk size and overlap
chunk_size = 256
chunk_overlap = 20
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
chunks = text_splitter.split_documents(docs)
# Specify Embedding Model
embedding_model_name = 'sentence-transformers/all-MiniLM-L6-v2'
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_name, model_kwargs={'device': 'cpu'})
# Specify Vector Database
vectorstore_start_time = time.time()
database_name = "LanceDB"
db = lancedb.connect("src/lance_database")
table = db.create_table(
"rag_sample",
data=[
{
"vector": embeddings.embed_query("Hello World"),
"text": "Hello World",
"id": "1",
}
],
mode="overwrite",
)
docsearch = LanceDB.from_documents(chunks, embeddings, connection=table)
vectorstore_end_time = time.time()
# Specify Retrieval Information
search_kwargs = {"k": 3}
retriever = docsearch.as_retriever(search_kwargs = {"k": 3})
# Specify Model Architecture
llm_repo_id = "huggingfaceh4/zephyr-7b-alpha"
model_kwargs = {"temperature": 0.5, "max_length": 4096, "max_new_tokens": 2048}
model = HuggingFaceHub(repo_id=llm_repo_id, model_kwargs=model_kwargs)
template = """
{query}
"""
prompt = ChatPromptTemplate.from_template(template)
rag_chain_start_time = time.time()
rag_chain = (
{"context": retriever, "query": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
rag_chain_end_time = time.time()
def get_complete_sentence(response):
last_period_index = response.rfind('.')
if last_period_index != -1:
return response[:last_period_index + 1]
else:
return response
# Invoke the RAG chain and retrieve the response
rag_invoke_start_time = time.time()
response = rag_chain.invoke("Who killed Jon Snow?")
rag_invoke_end_time = time.time()
# Get the complete sentence
complete_sentence_start_time = time.time()
complete_sentence = get_complete_sentence(response)
complete_sentence_end_time = time.time()
# Create a table
table = PrettyTable()
table.field_names = ["Task", "Time Taken (Seconds)"]
# Add rows to the table
table.add_row(["Vectorstore Creation", round(vectorstore_end_time - vectorstore_start_time, 2)])
table.add_row(["RAG Chain Setup", round(rag_chain_end_time - rag_chain_start_time, 2)])
table.add_row(["RAG Chain Invocation", round(rag_invoke_end_time - rag_invoke_start_time, 2)])
table.add_row(["Complete Sentence Extraction", round(complete_sentence_end_time - complete_sentence_start_time, 2)])
# Additional information in the table
table.add_row(["Embedding Model", embedding_model_name])
table.add_row(["LLM (Language Model) Repo ID", llm_repo_id])
table.add_row(["Vector Database", database_name])
table.add_row(["Temperature", model_kwargs["temperature"]])
table.add_row(["Max Length Tokens", model_kwargs["max_length"]])
table.add_row(["Max New Tokens", model_kwargs["max_new_tokens"]])
table.add_row(["Chunk Size", chunk_size])
table.add_row(["Chunk Overlap", chunk_overlap])
table.add_row(["Number of Documents", len(docs)])
print("\nComplete Sentence:")
print(complete_sentence)
# Print the table
print("\nExecution Timings:")
print(table)为了提高可读性并以结构化的表格格式呈现执行信息,我使用了 PrettyTable 库。您可以使用命令 pip3 install prettytable 将其添加到您的虚拟环境中。
所以这是我在不到1分钟内收到的回复,对于初学者来说相当可观。所需时间可能会因系统配置而异,但我相信您只需几分钟就能得到不错的结果。
所以,如果需要更长时间,请耐心等待。
Human:
Question : Who killed Jon Snow?
Answer:
In the TV series Game of Thrones, Jon Snow was stabbed by his
fellow Night's Watch members in season 5, episode 9,
"The Dance of Dragons." However, he was later resurrected by Melisandre
in season 6, episode 3, "Oathbreaker." So, technically,
no one killed Jon Snow in the show.
Execution Timings:
+------------------------------+----------------------------------------+
| Task | Time Taken (Seconds) |
+------------------------------+----------------------------------------+
| Vectorstore Creation | 16.21 |
| RAG Chain Setup | 0.03 |
| RAG Chain Invocation | 2.06 |
| Complete Sentence Extraction | 0.0 |
| Embedding Model | sentence-transformers/all-MiniLM-L6-v2 |
| LLM (Language Model) Repo ID | huggingfaceh4/zephyr-7b-alpha |
| Vector Database | LanceDB |
| Temperature | 0.5 |
| Max Length Tokens | 4096 |
| Max New Tokens | 2048 |
| Chunk Size | 256 |
| Chunk Overlap | 20 |
| Number of Documents | 39 |
+------------------------------+----------------------------------------+
玩得开心,尝试各种数据来源!你可以尝试更改网站地址,添加新的PDF文件,或者稍微改变模板。这些都很有趣,你永远不知道会得到什么!
接下来呢?
这里有很多东西可以调整。
我们可以切换到更有效的嵌入模型以获得更好的索引,尝试不同的检索技术来改进检索器,添加重新排序器以提高文档的排名,或者使用一个上下文窗口更大、响应时间更快的更先进的LLM。
基本上,每个 RAG 应用程序都只是基于这些因素的增强版本。然而,RAG 应用程序的基本工作原理始终保持不变。