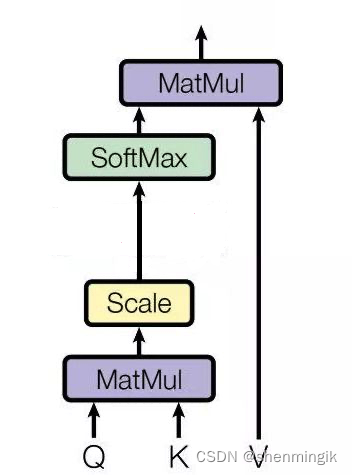
注意力机制
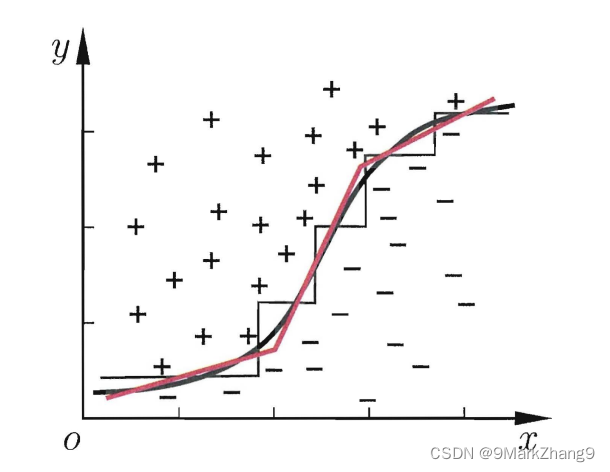
Transformer的注意力机制借鉴了人类的注意力机制。人类通过眼睛的视觉单元去扫描图像,其中的重点区域会被大脑的神经元处理从而获得更多的信息,这是人类长期精华所获得的一种能力。
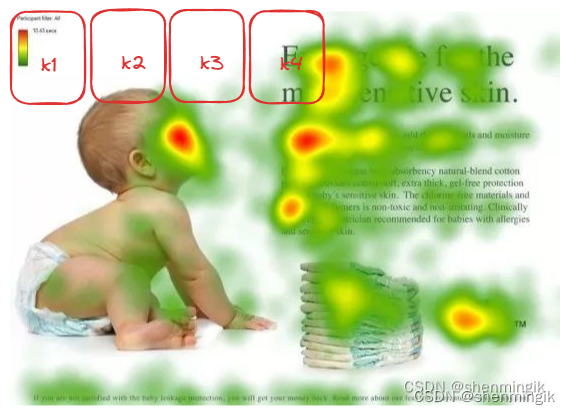
以论文中的例子来看,红色区域表示我们人脑视觉更为关注的区域。而Attention 机制则是模拟这一人脑机制,让计算机能够正确的从总舵信息中选择出对当前任务更为重要的信息。

Attention 机制原理
人类视觉注意力机制的原理为:从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略不重要的信息。
计算机的注意力机制模型就是从大量信息(Values)中筛选出少量的重要信息,这个重要信息对于另外一个信息(Query)是重要的。即注意力模型的主要作用就是通过Query从Values中筛选出重要信息。
结合下图,Attention可以翻译为如下的描述,其将Query和KV(把value拆分为key-value信息,这两个值看作等同的)映射到输出上。其中Q(query)、K(key)、V(value)都是一个向量,输出
V
,
V^,
V,则是所有value的加权,其中权重是由Q和每个K计算出来的。
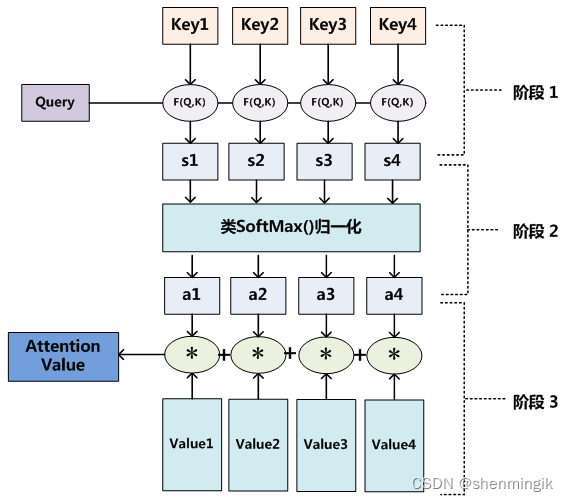
KV 是怎么来的?
对于上述图像来说,我们将其分割为不同的小块,其中每个块的向量化表示则是向量K
详细计算过程
刚刚提到,输出 V , V^, V,是对所有value的加权,是由 Query 和每个 key 计算出来的,计算方法分为三步:
- 第一步:计算Q和K的相似度,可以用
F
F
F来表示:
f
(
Q
,
K
i
)
,
i
=
1
,
2
,
.
.
.
,
n
f(Q,K_i),i=1,2,...,n
f(Q,Ki),i=1,2,...,n
- 计算方法一般分为四种:
- 点乘: f ( Q , K i ) = Q T K i f(Q,K_i)=Q^TK_i f(Q,Ki)=QTKi
- 权重: f ( Q , K i ) = Q T K i W f(Q,K_i)=Q^TK_iW f(Q,Ki)=QTKiW
- 拼接权重: f ( Q , K i ) = [ Q T K i ] W f(Q,K_i)=[Q^TK_i]W f(Q,Ki)=[QTKi]W
- 感知器: f ( Q , K i ) = V T t a n h ( W Q + U K i ) f(Q,K_i)=V^Ttanh(WQ+UK_i) f(Q,Ki)=VTtanh(WQ+UKi)
- 计算方法一般分为四种:
- 第二布:将第一步得到的相似度进行SoftMax操作,进行归一化:
α
i
=
s
o
f
t
m
a
x
(
F
(
Q
,
K
i
)
d
k
)
\alpha_i=softmax(\frac{F(Q,K_i)}{\sqrt{d_k}})
αi=softmax(dkF(Q,Ki))
- 这一步进行归一化是避免得到的相似度
F1 = 50和F2 = 1之间的差值多大影响模型效果,归一化之后相似度可能就会变成F1 = 0.8和F2 = 0.1。
- 这一步进行归一化是避免得到的相似度
- 第三步:针对计算出来的权重 α i \alpha^i αi,对V中的所有values进行加权求和计算,得到Attention 向量: A t t e n t i o n = ∑ i = 1 m α i V i Attention=\sum_{i=1}^{m}\alpha_iV_i Attention=∑i=1mαiVi
注1:softmax函数原理:https://zhuanlan.zhihu.com/p/503321685
注2:为什么要除 d k \sqrt{d_k} dk:softmax函数的输入由key向量和query向量之间的点积组成,key向量和query向量的维度 越大,点积往往越大, 原文论中12个head对应的大小是64,作者在原论文中采用的补救措施,是将点积除以key和query维度的平方根
Attention计算实战
假设我们现在有下面这么一组数据,现在我们的问题是:腰围57其对应的体重是多少(query)
| 腰围(key) | 体重(value) |
|---|---|
| 51 | 40 |
| 56 | 43 |
| 58 | 48 |
对于单维度场景,我们认为57 腰围所对应的体重在43~48之间,同时考虑到51 腰围这个key,所以我们的公式可以表示为如下的形式:
f
(
57
)
=
∑
i
=
1
3
α
i
V
i
=
α
(
57
,
51
)
∗
40
+
α
(
57
,
56
)
∗
43
+
α
(
57
,
58
)
∗
48
f(57) =\sum_{i=1}^{3}\alpha_iV_i= \alpha(57,51)*40+\alpha(57,56)*43+\alpha(57,58)*48
f(57)=i=1∑3αiVi=α(57,51)∗40+α(57,56)∗43+α(57,58)∗48
注: 同样的,对于多维向量,我们采用点乘的方式依然可以得到 f f f
Self-Attention 自注意力机制
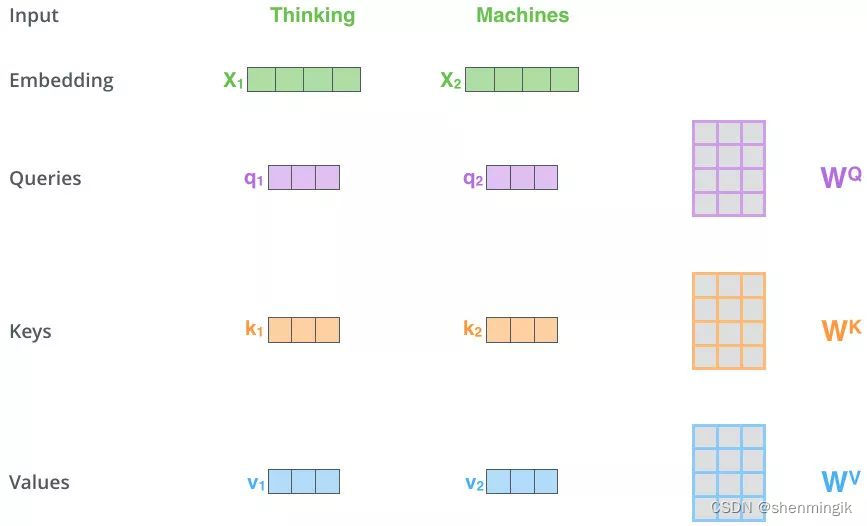
Self-Attention是Attenion机制的特化。Self-Attention 同样也有着三个输入Q、K、V:对于Self-Attention,Q、K、V均来自句子X的词向量
x
x
x的线性转化。
我们这里采用Thinking Machines这里来举例:
- 第一步:两个单词 Thinking 和 Machines。通过线性变换,即
x
1
x_1
x1和
x
2
x_2
x2 这两个向量分别和
W
Q
,
W
K
,
W
V
W^Q,W^K,W^V
WQ,WK,WV 三个矩阵点乘得到
q
1
,
q
2
,
k
1
,
k
2
,
v
1
,
v
2
q_1,q_2,k_1,k_2,v_1,v_2
q1,q2,k1,k2,v1,v2一共六个向量,两两拼接形成对应的QKV矩阵。
- 第二步,MatMul:向量
q
1
,
k
1
q_1,k_1
q1,k1 做点乘得到得分 112,
q
1
,
k
2
q_1,k_2
q1,k2 做点乘得到得分96。
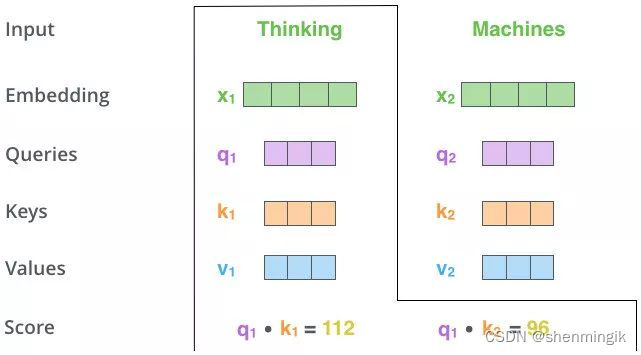
注:这里是通过 q 1 q_1 q1这个信息找到原始输入 x 1 , x 2 x_1,x_2 x1,x2中的重要信息
- 第三步和第四步,Scale + Softmax:对该得分进行规范,除以
d
k
=
8
\sqrt{d_k}=8
dk=8
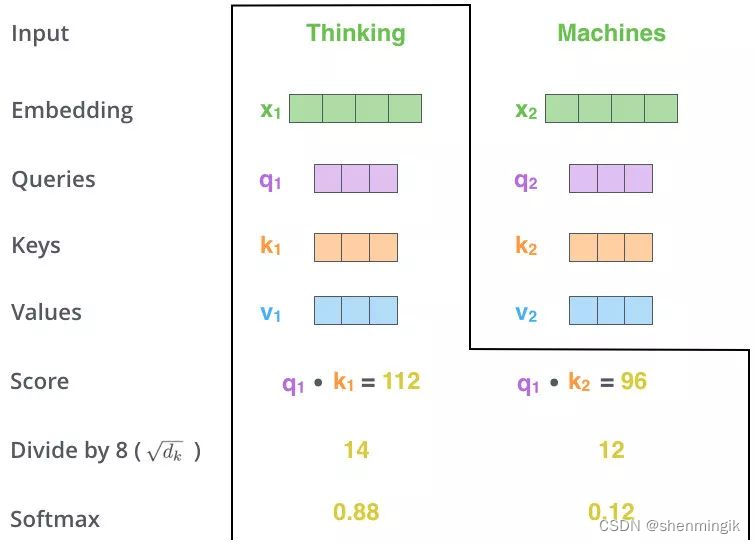
- 第五步,MatMul:用得分比例 [0.88,0.12] 乘以
[
v
1
,
v
2
]
[v_1,v_2]
[v1,v2]
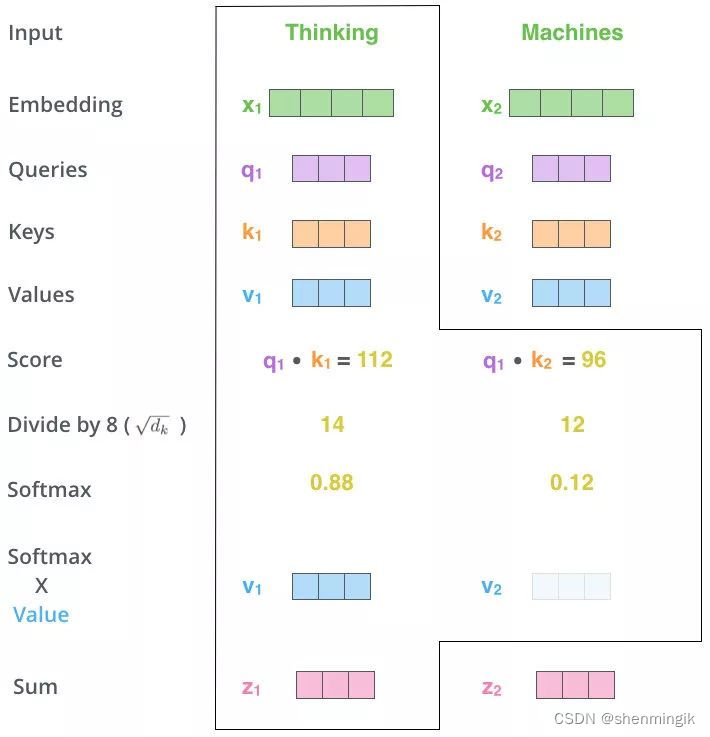
值得到一个加权后的值,将这些值加起来得到 z 1 z_1 z1,拼接 z 1 , z 2 z_1,z_2 z1,z2得到Attention的值 Z = [ z 1 , z 2 ] Z=[z_1,z_2] Z=[z1,z2]。