多线程面试题汇总
一、多线程
1、线程的生命周期
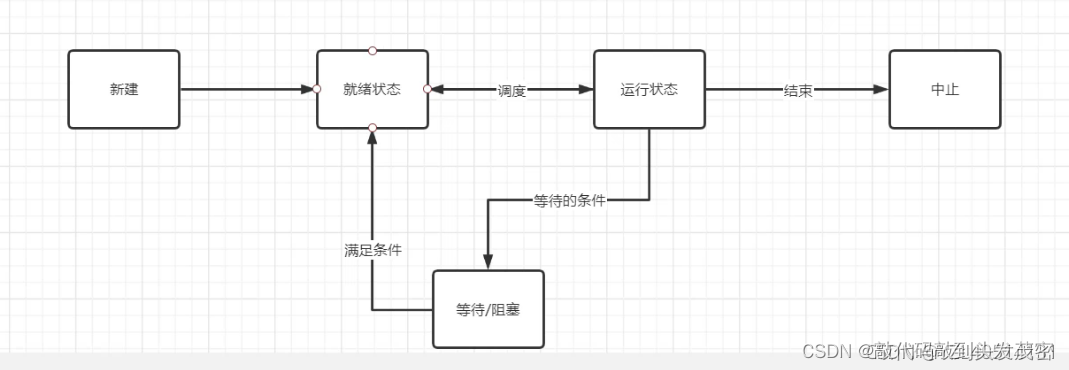
1、线程的创建:t=threading.Thread()
2、就绪状态:已经获得了除CPU之外的其他资源,正在参与调度,等待被执行,当调度完成之后,立即运行
3、启动状态:获得了CPU时间片段,正在运行
4、等待\阻塞状态:遇到time.sleep()时,会阻塞,暂时不参与调度,等待事件发生
5、中止状态:线程运行结束,run函数运行结束,等待系统回收其线程资源。
2、线程的创建(函数创建)
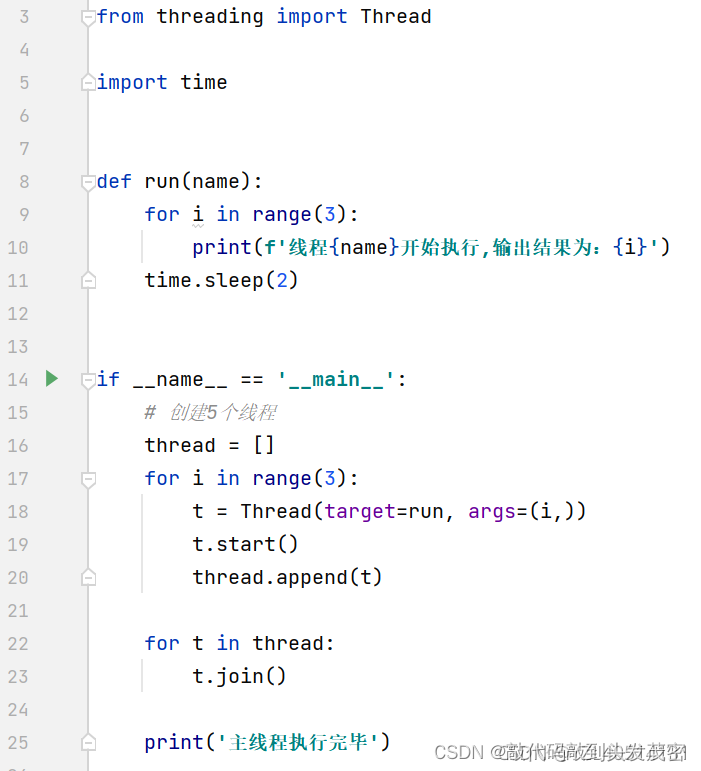

3、线程的创建(使用类)
t=MyThread(name=s[i]) 创建线程,里面的参数代表线程的名字,如果不传,系统会默认有一个名字
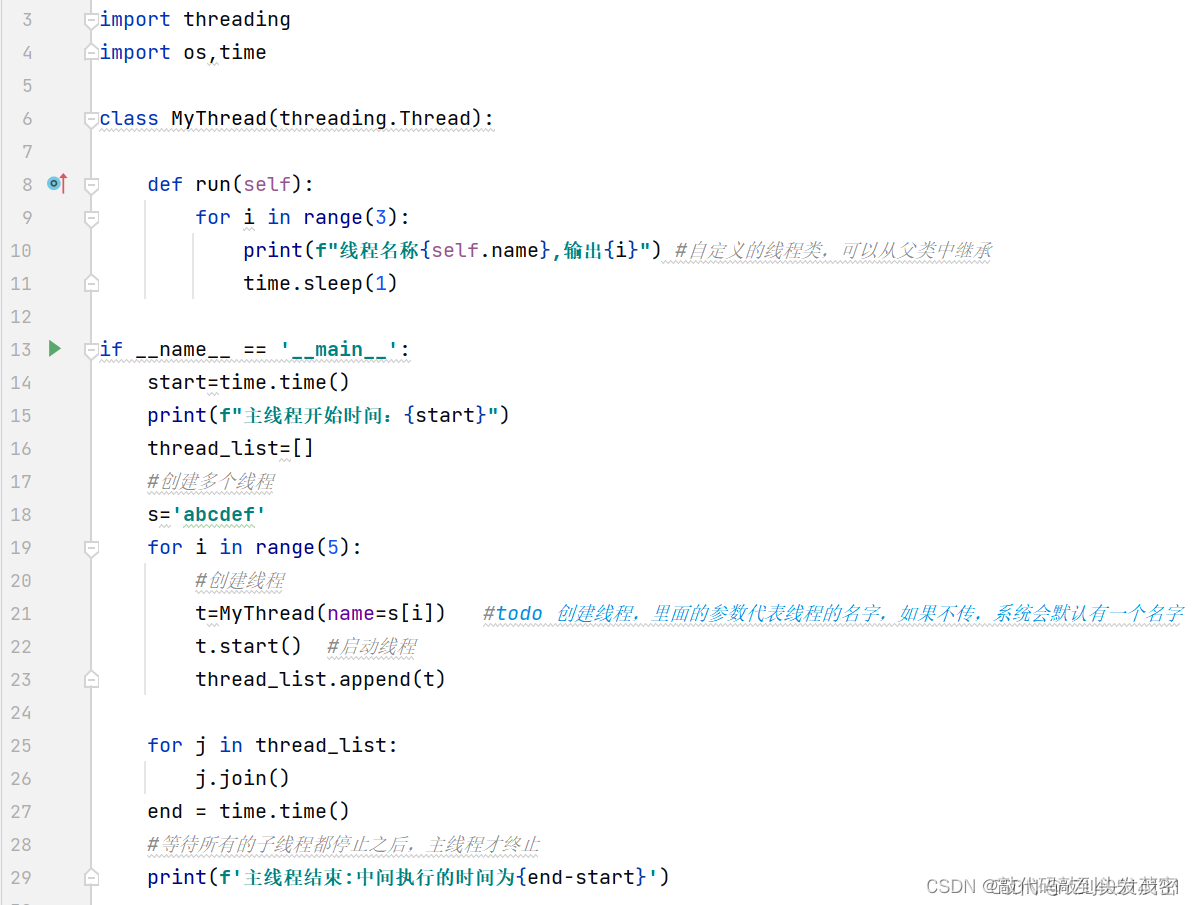
4、守护线程
当我们在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程就分兵两路,分别运行,那么当主线程完成想退出时,会检验子线程是否完成。如果子线程未完成,则主线程会等待子线程完成后再退出。但是有时候我们需要的是只要主线程完成了,不管子线程是否完成,都要和主线程—起退出,这时就可以用setDaemon方法
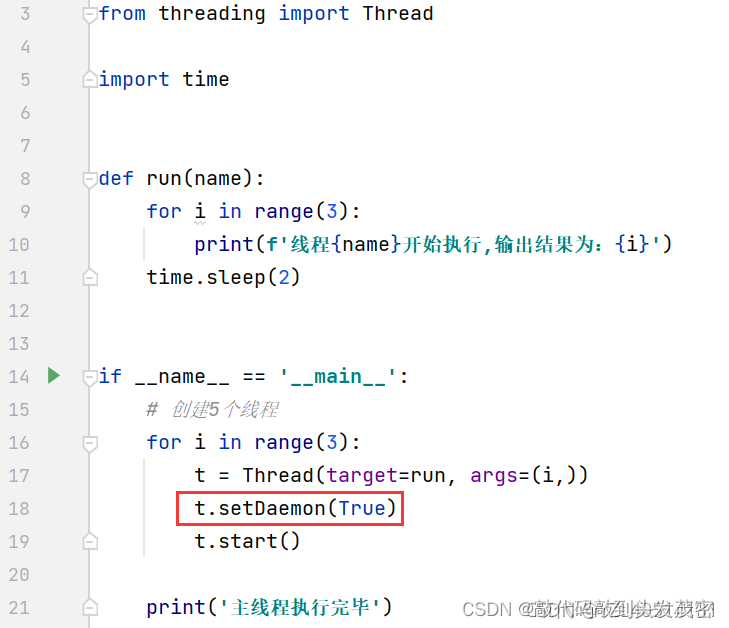
输出结果:线程2还没有完整的执行完毕,遇到守护线程就终止执行了。

t.setDaemon(True) 当前的子线程设置为守护线程
守护线程:随着主线程的终止而终止,不管当前主线程下有多少子线程没有执行完毕,都会终。
二、全局解释器锁
1、GIL锁不是python的特点。而是cpython的特点。
每个线程在执行的时候都需要先获取GIL,保证同一时刻只有一个线程可以执行代码,即同一时刻只有一个线程使用CPU。在CPython中,每一个Python线程执行前都需要去获得GIL锁,获得该锁的线程才可以执行,没有获得的只能等待,当具有GIL锁的线程运行完成后,其他等待的线程就会去争夺GIL锁,这就造成了,在Python中使用多线程,但同一时刻下依旧只有一个线程在运行,所以Python多线程其实并不是「并行」的,而是「并发」。
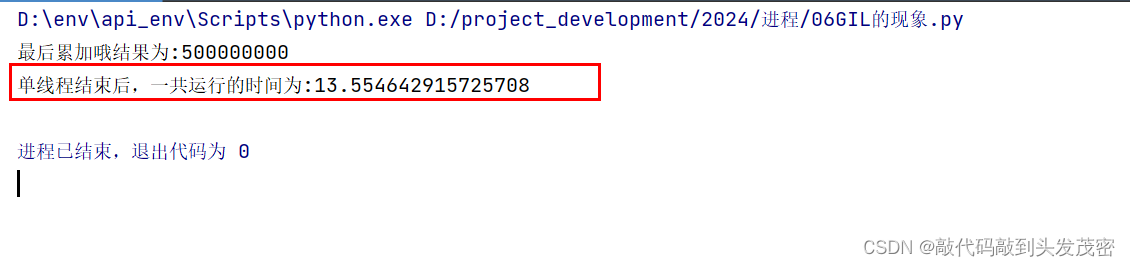
1、使用单线程实现累加到500000000
import time,threading
def task(n):
sum=0
while sum<n:
sum+=1
print(f'最后累加哦结果为:{sum}')
if __name__ == '__main__':
# 单线程
start=time.time()
task(500000000)
end=time.time()
print(f'单线程结束后,一共运行的时间为:{end-start}')
2、使用多线程实现累加到500000000
import time,threading
def task(n):
sum=0
while sum<n:
sum+=1
print(f'最后累加哦结果为:{sum}')
if __name__ == '__main__':
# 多线程
start = time.time()
t1=threading.Thread(target=task,args=(250000000,))
t2=threading.Thread(target=task,args=(250000000,))
t1.start()
t2.start()
t1.join()
t2.join()
end=time.time()
print(f'单线程结束后,一共运行的时间为:{end-start}') # todo 15.777813196182251
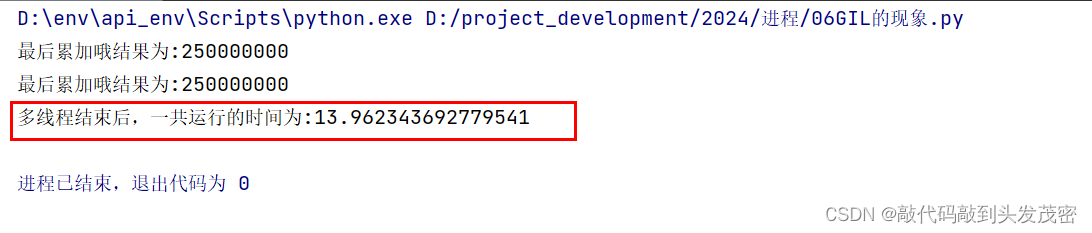
发现问题:两个线程同时执行并不能比单个线程的执行快
由此发现:CPU密集型(计算密集型)任务采用多线程执行并不能提高计算速度
3、总结
GIL解决办法:
- 使用其他语言写的python解析器(不推荐,还是用python官方的CPython好)
- JPython、pypy
- 不使用多线程,使用多进程-进程里面加协程实现多任务来充分利用多核CPU(推荐)
- 即使存在GIL,在有IO等待操作的程序中,还是多线程快;当然没有资源等待的还是使用单线程快(科学计算、累加等等)
但是需要注意的是线程有了GIL后并不意味着使用python多线程时不需要考虑线程安全,GIL的存在是为了方便使用C语言CPython解释器的编写者,而顶层使用python时依旧要考虑线程安全。
三、线程安全
当多个线程同时访问一个对象时,不管如何计算,如果调用这个对象的行为都可以获得正确的结果,那就称这个对象时线程安全的。如果出现了“脏数据”。则线程不安全。
脏数据:产生脏数据的原因是,当一个线程在对数据进行修改时,修改到一半时另一个线程读取了未经修改的数据并进行修改。
如何避免脏数据的产生呢?一个办法就是用join方法,即先让一个线程执行完毕再执行另一个线
程。但这样的本质是把多线程变成了单线程,失去了多线程的意义。另一个办法就是用线程锁。
1、多线程之数据混乱问题
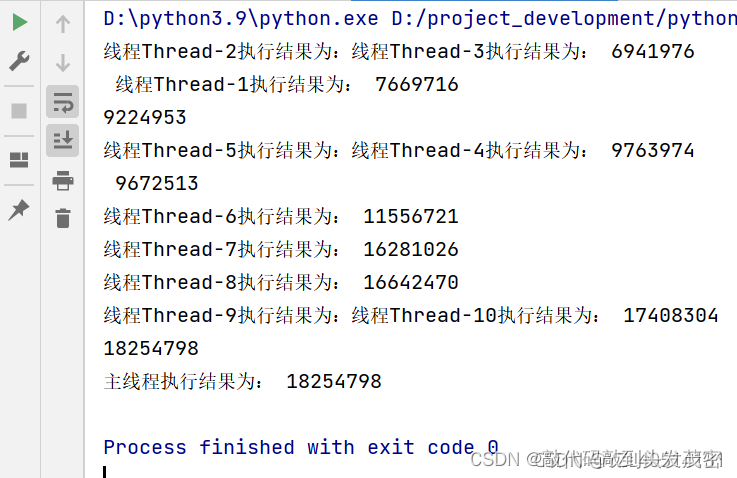
但是当我把累加次数设置小,就不会出现数据混乱问题
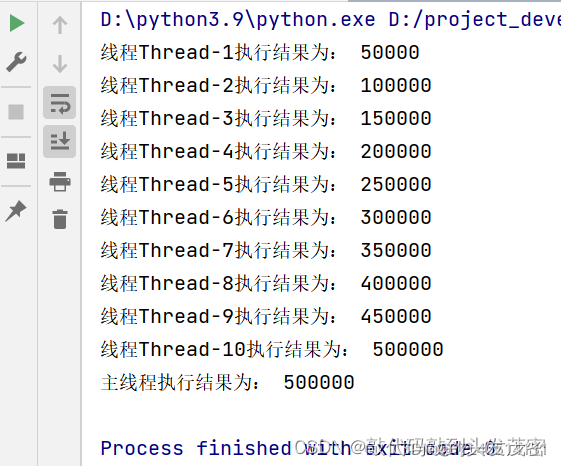
数据混乱的原因:
cpu分成多个时间片段,启动10线程,分配10个cpu时间片段,当我累加数字设置比较小的时候,在单个cpu时间片段内,for循环代码就执行完,就不会产生数据混乱的。当我数据设置的比较大时,在单个cpu时间片段内,for循环代码就执行不完,并且没有分配2个或2个以上的连续的cpu时间片段,导致一个cpu时间片段没有执行完该线程,下一个线程开始执行了
2、有了全局解释器锁(GIL)为什么还需要同步锁?
全局解析器锁(GIL)加在了全局了,没有加到我所想要的位置,加到什么位置不是我们决定的;
包括修改资源的程序和非修改资源的程序,如果出现在修改资源的相关代码上,肯定会出现脏数据。
同步锁:来获取一把互斥锁。互斥锁就是对共享数据进行锁定,保证同一时刻只有一个线程操作数据,是数据级别的锁。
GIL锁是解释器级别的锁,保证同一时刻进程中只有一个线程拿到GIL锁,拥有执行权限。
2个线程执行任务造成数据混乱
import threading
num=0
def work():
global num
for i in range(1000000):
num+=1
print('work',num)
def work1():
global num
for i in range(1000000):
num+=1
print('work1',num)
if __name__ == '__main__':
t1=threading.Thread(target=work)
t2=threading.Thread(target=work1)
t1.start()
t2.start()
t1.join()
t2.join()
print('主线程执行结果',num)
执行结果:明显数据混乱了
work work1 16347351376208
主线程执行结果 1634735
说明:
代码中:num+=1,可以拆解为
num=100
100+1
num=101
同步锁这3行代码执行完毕了才会释放锁
3、同步锁
同一时刻的一个进程下的一个线程只能占用CPU,要确保这个线程下的程序在一段时间内被CPU执行,那么就要用到同步锁,只需要在对公共数据的操作前后加上上锁和释放锁的操作即可。
3.1、加同步锁(with方法)
from threading import Lock
import threading
num=0
def work():
global num
for i in range(1000000):
with lock:
num+=1
print('work',num)
def work1():
global num
for i in range(1000000):
with lock:
num+=1
print('work1',num)
if __name__ == '__main__':
lock=Lock()
t1=threading.Thread(target=work)
t2=threading.Thread(target=work1)
t1.start()
t2.start()
t1.join()
t2.join()
print('主线程执行结果',num)
work 1845334work1 2000000
主线程执行结果 2000000
3.2、加同步锁(acquire方法和release方法)
from threading import Lock
import threading
num=0
def work():
global num
for i in range(1000000):
lock.acquire()
num+=1
lock.release()
print('work',num)
def work1():
global num
for i in range(1000000):
lock.acquire()
num += 1
lock.release()
print('work1',num)
if __name__ == '__main__':
lock=Lock()
t1=threading.Thread(target=work)
t2=threading.Thread(target=work1)
t1.start()
t2.start()
t1.join()
t2.join()
print('主线程执行结果',num)
workwork1 1921583
2000000
主线程执行结果 2000000
四、锁
锁是python提供给我们能够自行操控线程切换的一种手段,使用锁可以让线程的切换变得有序。
一旦线程的切换变的有序后,各个线程之间对数据的访问、修改就变得可控,所以若要保证线程安全,就必须使用锁。
threading模块中提供了5种最常见的锁,下面是按照功能进行划分:
- 同步锁:Lock(一次只能放行一个)
- 递归锁:RLock(一次只能放行一个)
- 条件锁:condition(一次可以放行任意个)
- 事件锁:event(一次全部放行)
- 信号量锁:semaphore(一次可以放行特定个)
1、同步锁
上面已讲解
2、递归同步锁
在同步锁的基础上可以做到连续重复使用多次acquire()后再重复使用多次release()的操作,但是一定要注意加锁次数和解锁次数必须一致,否则也将引发死锁现象。
递归锁RLock:它内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。
3、条件锁
条件锁是在递归锁的基础上增加了能够暂停线程运行的功能。并且我们可以使用wait()和notify()来控制线程执行的个数。
注意:条件锁可以自由设定一次放行几个线程。
lock.notify(number):有条件的唤醒线程
lock.wait() :让当前线程暂停。并等待
但是不能唤醒特定某个线程
from threading import Thread,Condition,current_thread
#全局变量
g_number = 0
#子线程的数量
sub_thread_count=10
#正在运行的线程数量
current_run_thread_count=0
#创建一个条件锁
lock=Condition()
def task():
global g_number,current_run_thread_count
thread_name=current_thread().name #当前线程的名字
with lock:
print(f'{thread_name}线程得到锁,并直接进入等待状态')
lock.wait() #让当前线程暂停。并等待
print(f'{thread_name}线程已经苏醒了,并执行后面的代码')
g_number+=1
current_run_thread_count+=1
if __name__ == '__main__':
thread_list=[]
for i in range(sub_thread_count):
t=Thread(target=task,name=f't{i+1}')
thread_list.append(t)
t.start()
while current_run_thread_count<sub_thread_count:
# 由用户输入
number=int(input("请输入你要唤醒几个线程,数字:"))
with lock:
lock.notify(number)
print('主线程执行结束')
运行代码
每个线程都能得到这把锁,并进入等待状态,此时线程到13行代码已经阻塞了。10个线程都已经调用了wait()函数
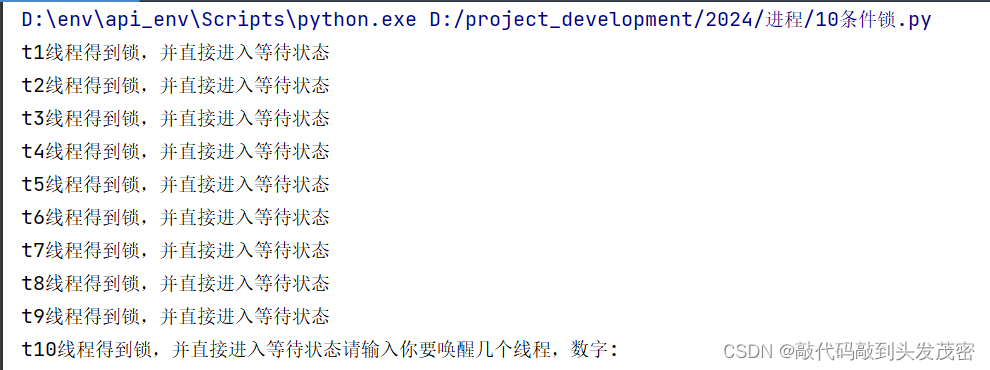
现在需要唤醒4个线程,输入数字4,t1,t2,t3,t4线程被唤醒
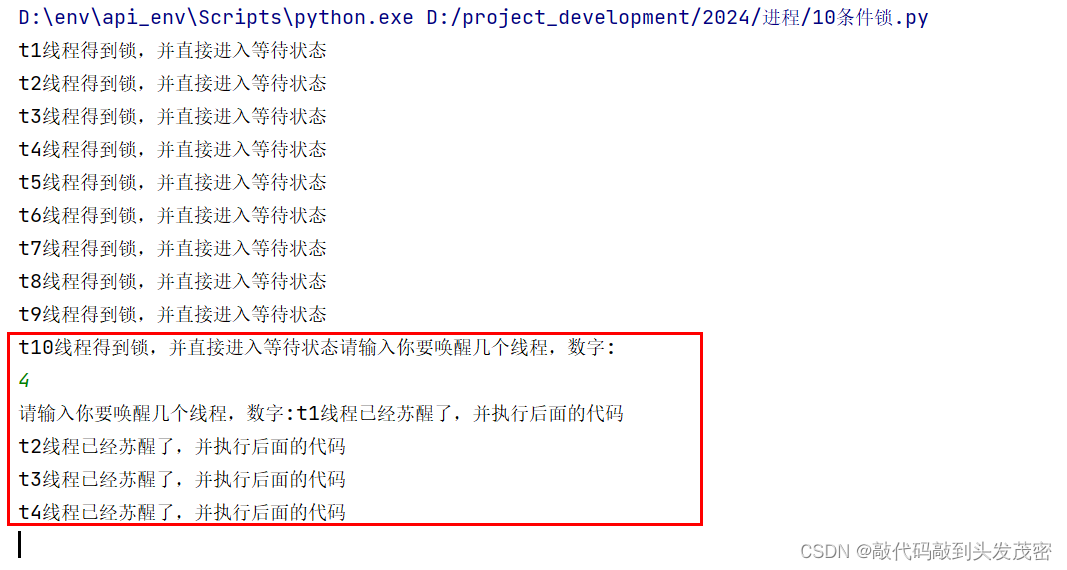
再唤醒4个线程,t5~t8被唤醒

4、事件锁
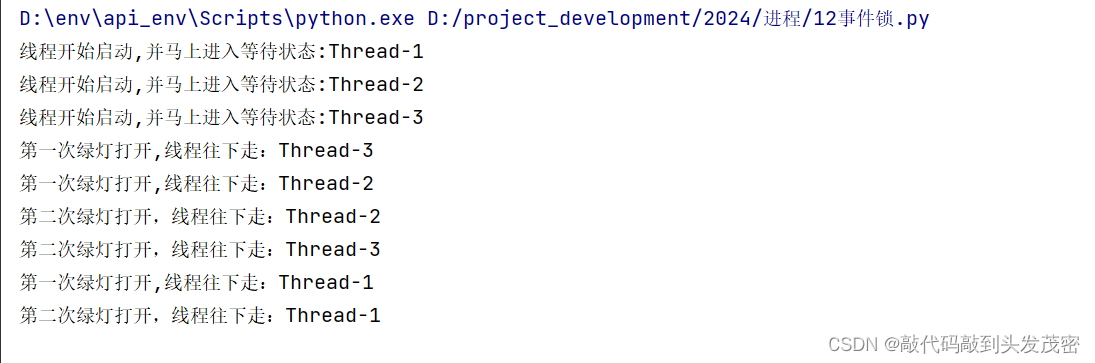
事件锁是基于条件锁来做的,它与条件锁的区别在于一次只能放行全部,不能放行任意个数量的子线程继续运行。
我们可以将事件锁看为红绿灯,当红灯时所有子线程都暂停运行,并进入“等待”状态,当绿灯时所有子线程都恢复“运行”
eventLock.set() 设置绿灯
eventLock.clear() 设置红灯
eventLock.wait() 暂停运行,等待绿灯
import threading
maxSubThreadNumber = 3 #最多子线程为3
def task():
thread_name = threading.current_thread().name #获取当前线程的名字
print("线程开始启动,并马上进入等待状态:%s" % thread_name)
eventLock.wait() # 暂停运行,等待绿灯
print("第一次绿灯打开,线程往下走:%s " % thread_name)
eventLock.wait() # 暂停运行,等待绿灯
print("第二次绿灯打开,线程往下走:%s" % thread_name)
if __name__ == '__main__':
eventLock = threading.Event()
for i in range(maxSubThreadNumber):
subThreadIns = threading.Thread(target=task)
subThreadIns.start()
eventLock.set() #设置绿灯
eventLock.clear() #设置红灯
eventLock.set()
5、信号量锁
Semaphore()
信号量锁也是根据条件锁来做的,它与条件锁的区别如下:
条件锁:一次可以放行任意个处于 “等待” 状态的线程
事件锁:一次可以放行全部的处于 “等待” 状态的线程
信号量锁:通过规定,成批的放行特定个处于 “上锁” 状态的线程
import threading
import time
maxSubThreadNumber = 6
def task():
thread_name = threading.currentThread().name
with semaLock:
print("线程获得锁,开始运行:%s" % thread_name)
time.sleep(3)
if __name__ == '__main__':
semaLock = threading.Semaphore(2)
for i in range(maxSubThreadNumber):
subThreadIns=threading.Thread(target=task)
subThreadIns.start()
五、死锁
在多线程程序中,死锁问题很大一部分原因是由于线程同时获取多个锁造成的。
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
3、尽管死锁很难发生,但一旦发生就会造成应用的停止响应。
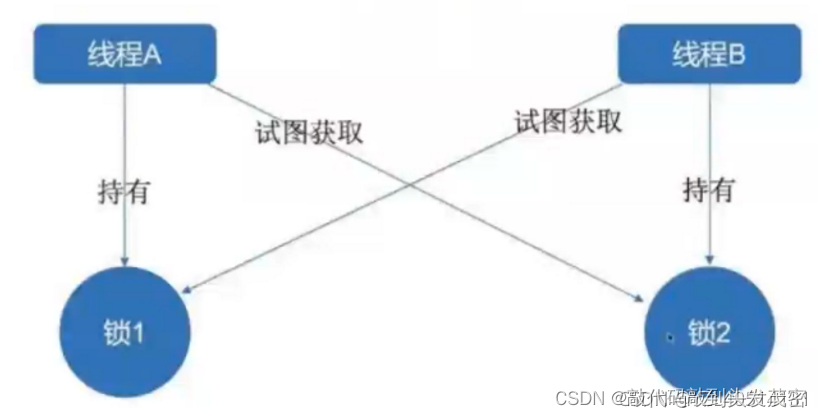
1、案例:鱼和熊掌不可兼得问题
import threading
import time
# 代表鱼的锁
mutex_Yu = threading.Lock()
# 代表熊掌的锁
mutex_Xiongzhang = threading.Lock()
class MyThread1(threading.Thread):
def run(self):
mutex_Yu.acquire() # 得到🐟
print('线程1已经得到鱼了')
time.sleep(1)
mutex_Xiongzhang.acquire()
print('线程1得到熊掌')
mutex_Xiongzhang.release()
mutex_Yu.release()
class MyThread2(threading.Thread):
def run(self):
mutex_Xiongzhang.acquire()
print('线程2已经得到熊掌了')
time.sleep(1)
mutex_Yu.acquire()
print('线程2已经得到🐟了')
mutex_Yu.release()
mutex_Xiongzhang.release()
if __name__ == '__main__':
t1 = MyThread1()
t2 = MyThread2()
t1.start()
t2.start()
解决方法:让多个线程交叉有序的竞争多个资源
#让多个线程交叉有序的竞争多个资源
import threading
import time
# 代表🐟的锁
mutex_Yu = threading.Lock()
# 代表熊掌的锁
mutex_Xiongzhang = threading.Lock()
class MyThread1(threading.Thread):
def run(self):
while True:
mutex_Yu.acquire() # 得到🐟
print('线程1已经得到鱼了')
time.sleep(1)
mutex_Yu.release() #释放鱼对应锁
mutex_Xiongzhang.acquire() # 得到熊掌
print('线程1得到熊掌')
time.sleep(1)
mutex_Xiongzhang.release() #释放熊掌对应锁
class MyThread2(threading.Thread):
def run(self):
while True:
mutex_Xiongzhang.acquire() # 得到熊掌
print('线程2已经得到熊掌了')
time.sleep(1)
mutex_Xiongzhang.release() #释放熊掌对应锁
mutex_Yu.acquire() # 得到🐟
print('线程2已经得到鱼了')
time.sleep(1)
mutex_Yu.release() #释放鱼对应锁
if __name__ == '__main__':
t1 = MyThread1()
t2 = MyThread2()
t1.start()
t2.start()
六、进程与线程的区别
1、进程是操作系统分配任务的基本单位,进程是python中正在运行的程序;当我们打开1个浏览器时就是开启了一个浏览器进程;
线程是进程中执行任务的基本单位(执行指令集),一个进程中至少有一个线程,当只有一个线程时,称为主线程。
2、进程的创建和销毁消耗资源多;
线程的创建和销毁消耗资源少。
3、线程的切换速度比较快。
4、多进程中,进程与进程之间不能进行通信,如果需要通信需要借助Queue、Pipe;
一个进程中有多个线程时:线程之间可以进行直接通信。
5、多进程可以利用多核CPU:多进程的主要目的是充分利用多核CPU资源。
多线程不可以利用多核CPU:多线程的主要目的是充分利用好某一个单核。
6、进程的启动速度要比线程的启动速度慢。
7、进程与进程是不可以共享同一个数据的(同一个全局变量);
两个线程可以共享同一个进程中的一个数据(同一个全局变量)。
8、进程用到了Process类;
线程用到了Thread类。
9、进程可以独立存在;
线程不能独立存在,依赖进程存在。
10、多进程中不会出现数据混乱、死锁的问题;
多线程中会出现数据混乱、死锁的问题。






![BulingBuling - 《大家来写作》 [ Everybody Writes ]](https://img-blog.csdnimg.cn/direct/170f36c7057b436b844a86831ee7c392.png)