聊天补全模型调用函数
这个笔记包含怎样使用聊天补全API结合外部的函数调用来扩展GPT模型的能力
tools在聊天补全API中是一个可选的参数,可以定义指定的函数调用。目的是能使模型生成遵循指定规范的函数参数。请注意:API实际上不执行任何的函数调用。由开发者使用模型输出时执行函数调用。
在tools参数内部,如果提供了functions参数,那么在默认情况下,模型来决定何时使用其中一个适合的函数。API可通过设置tool_choice参数{“name”: “”},强制调用一个指定的函数。也可以设置tool_choice参数为none,强制不调用任何函数。如果使用了函数,则输出将在响应中包含"finish_reason": “function_call”,以及包含函数名称和生成的函数参数的tool_choice对象。
1. 概述
这个笔记包含下面两部分:
- 怎样生成函数参数 指定一组函数并使用模型API生成函数参数。
- 怎样使用模型生成的参数调用函数 通过实际执行带有模型生成参数的函数来关闭循环。
1.1 怎样生成函数参数
安装依赖包
pip install scipy -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tenacity
pip install tiktoken
pip install termcolor
pip install openai
# 导入依赖库
import json
from tenacity import retry, wait_random_exponential, stop_after_attempt
from termcolor import colored
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
# 加载 .env 文件中定义的环境变量
_ = load_dotenv(find_dotenv())
GPT_MODEL = "gpt-3.5-turbo-0613"
# 初始化 OpenAI 客户端
client = OpenAI() # 默认使用环境变量中的 OPENAI_API_KEY 和 OPENAI_BASE_URL
1.2 实用函数
首先定义几个公用的函数,以调用聊天补全API,维护和保持对话记录状态。
@retry(wait=wait_random_exponential(multiplier=1, max=40), stop=stop_after_attempt(3))
def chat_completion_request(messages, tools=None, tool_choice=None, model=GPT_MODEL):
"""封装OpenAI API调用"""
try:
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools,
tool_choice=tool_choice,
)
return response
except Exception as e:
print("Unable to generate ChatCompletion response")
print(f"Exception: {e}")
return e
def pretty_print_conversation(messages):
"""格式化控制台输出"""
role_to_color = {
"system": "red",
"user": "green",
"assistant": "blue",
"function": "magenta",
}
for message in messages:
if message["role"] == "system":
print(colored(f"system: {message['content']}\n", role_to_color[message["role"]]))
elif message["role"] == "user":
print(colored(f"user: {message['content']}\n", role_to_color[message["role"]]))
elif message["role"] == "assistant" and message.get("function_call"):
print(colored(f"assistant: {message['function_call']}\n", role_to_color[message["role"]]))
elif message["role"] == "assistant" and not message.get("function_call"):
print(colored(f"assistant: {message['content']}\n", role_to_color[message["role"]]))
elif message["role"] == "function":
print(colored(f"function ({message['name']}): {message['content']}\n", role_to_color[message["role"]]))
1.3 基本概念
让我们创建一些特定函数规范与假定的天气API进行交互。我们要传递这些函数规范到聊天补全API,以便生成遵循指定规范函数参数
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "返回实时天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "河北省承德市双桥区",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "使用本地区常用的温度单位计量",
},
},
"required": ["location", "format"],
},
}
},
{
"type": "function",
"function": {
"name": "get_n_day_weather_forecast",
"description": "返回近几天的天气预报",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "河北省承德市双桥区",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "使用本地区常用的温度单位计量",
},
"num_days": {
"type": "integer",
"description": "预报的天数",
}
},
"required": ["location", "format", "num_days"]
},
}
},
]
如果我们询问模型关于当前的天气,它会给出消息让你指定具体的区域
messages = []
messages.append({"role": "system", "content": "不要假设应该把什么值代入函数中。如果用户的请求模棱两可,要求对方澄清。"})
messages.append({"role": "user", "content": "今天的天气怎样?"})
chat_response = chat_completion_request(
messages, tools=tools, tool_choice="none"
)
assistant_message = chat_response.choices[0].message
messages.append(assistant_message)
assistant_message

一旦你提供了缺失的消息,模型将为我们生成适合的参数。
messages.append({"role": "user", "content": "我在河北省承德市双桥区"})
chat_response = chat_completion_request(
messages, tools=tools
)
assistant_message = chat_response.choices[0].message
messages.append(assistant_message)
assistant_message
由于提示词的不同,可以获得我们已经告诉模型的目标函数:

继续:
messages = []
messages.append({"role": "system", "content": "不要假设应该把什么值代入函数中。如果用户的请求模棱两可,要求对方澄清。"})
messages.append({"role": "user", "content": "接下来北京、上海、承德的天气将会怎样?"})
chat_response = chat_completion_request(
messages, tools=tools, tool_choice="none"
)
assistant_message = chat_response.choices[0].message
messages.append(assistant_message)
assistant_message

模型又一次要求我们要明确的指出几天,因为我们没有给出足够的信息。这个例子已经知道要询问地区的天气,但需要指出几天的
messages.append({"role": "user", "content": "5天"})
chat_response = chat_completion_request(
messages, tools=tools
)
chat_response.choices[0]

强制使用规范函数或不使用
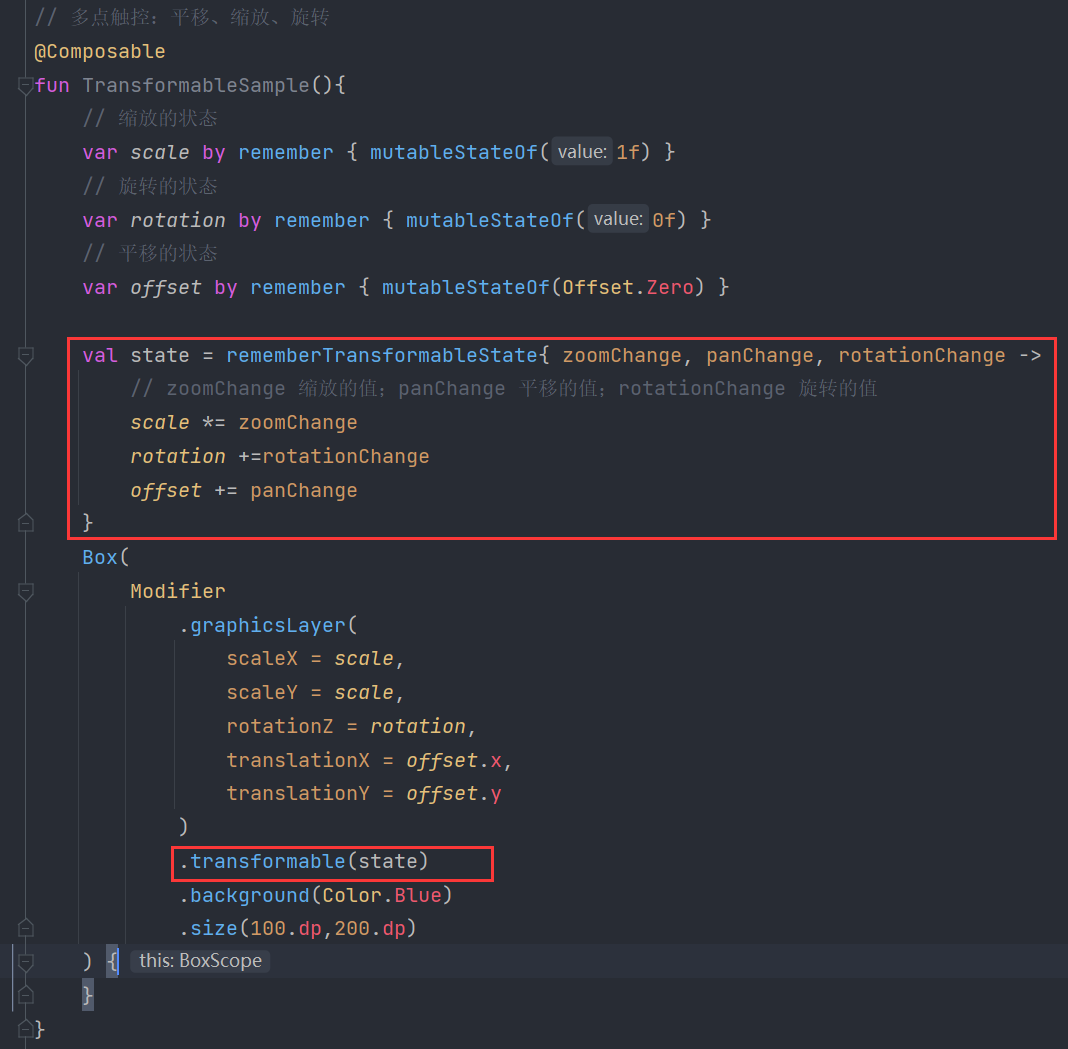
我们可以强制模型使用指定规范的函数,例如:get_n_day_weather_forecast被用作function_call参数。这样做会强制模型使用指定的函数
messages = []
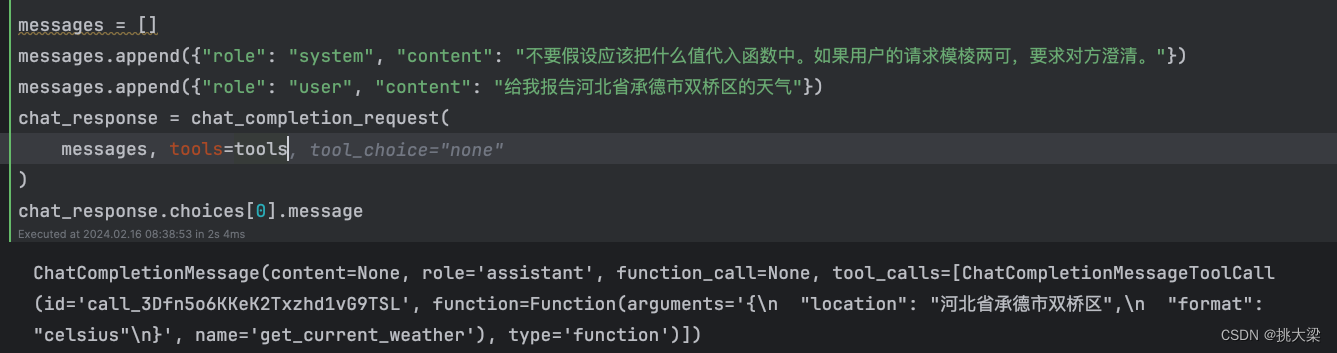
messages.append({"role": "system", "content": "不要假设应该把什么值代入函数中。如果用户的请求模棱两可,要求对方澄清。"})
messages.append({"role": "user", "content": "给我报告河北省承德市双桥区的天气"})
chat_response = chat_completion_request(
messages, tools=tools, tool_choice={"type": "function", "function": {"name": "get_n_day_weather_forecast"}}
)
chat_response.choices[0].message

1.4 并行函数调用
最新的模型像:GPT-4-1106或GPT-3.5-turbo-1106一次可以调用多个函数:
messages = []
messages.append({"role": "system", "content": "不要假设应该把什么值代入函数中。如果用户的请求模棱两可,要求对方澄清。"})
messages.append({"role": "user", "content": "北京、上海接下3的天气是怎样的?"})
chat_response = chat_completion_request(
messages, tools=tools, model='gpt-3.5-turbo-1106'
)
assistant_message = chat_response.choices[0].message.tool_calls
assistant_message

2. 怎样使用模型生成的参数调用函数
在接下来的案例中,我们将演示怎样执行函数调用,且输入是由模型产生,实现一个代理,能回答关于数据库的相关问题。为简单起见,使用chinook音乐案例数据库。SQLITE
注意:生成SQL在生产环境会造成高风险,由于模型在生成完全可靠的正确SQL上还不完善。
2.1 指定执行SQL查询的函数
首先,定义一些公用的函数,从SQLite数据库获得数据

def get_table_names(conn):
"""返回所有表名."""
table_names = []
tables = conn.execute("SELECT name FROM sqlite_master WHERE type='table';")
for table in tables.fetchall():
table_names.append(table[0])
return table_names
def get_column_names(conn, table_name):
"""返回所有列名."""
column_names = []
columns = conn.execute(f"PRAGMA table_info('{table_name}');").fetchall()
for col in columns:
column_names.append(col[1])
return column_names
def get_database_info(conn):
"""
返回一个包含数据库中每个表的名字和列的字典列表。
"""
table_dicts = []
for table_name in get_table_names(conn):
columns_names = get_column_names(conn, table_name)
table_dicts.append({"table_name": table_name, "column_names": columns_names})
return table_dicts
现在可以使用这些公用的函数获取数据库的模式定义
database_schema_dict = get_database_info(conn)
database_schema_string = "\n".join(
[
f"Table: {table['table_name']}\nColumns: {', '.join(table['column_names'])}"
for table in database_schema_dict # 构造表名和列名字符数组
]
)
和之前一样,我们为函数调用定义一个函数规范,让模型API生成参数。请注意:我们要插入数据库的模型到函数规范中。让模型知道这一点很重要:
tools = [
{
"type": "function",
"function": {
"name": "ask_database",
"description": "使用这个函数回答用户关于音乐的问题. 输入为格式化好的SQL语句.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": f"""
通过SQL查询提取用户问题的答案。
SQL语句应该使用这个数据库模式:
{database_schema_string}
查询结果应该以纯文本形式返回,而不是JSON格式。
""",
}
},
"required": ["query"],
},
}
}
]
2.2 执行SQL查询
现在让我们实现函数真正的执行数据库查询
messages = []
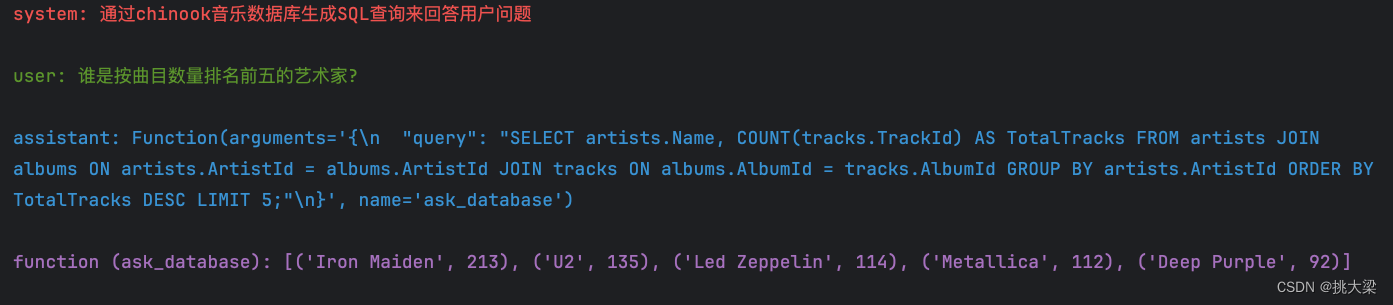
messages.append({"role": "system", "content": "通过chinook音乐数据库生成SQL查询来回答用户问题"})
messages.append({"role": "user", "content": "谁是按曲目数量排名前五的艺术家?"})
chat_response = chat_completion_request(messages, tools)
assistant_message = chat_response.choices[0].message
assistant_message.content = str(assistant_message.tool_calls[0].function)
messages.append({"role": assistant_message.role, "content": assistant_message.content})
if assistant_message.tool_calls:
results = execute_function_call(assistant_message)
messages.append({"role": "function", "tool_call_id": assistant_message.tool_calls[0].id, "name": assistant_message.tool_calls[0].function.name, "content": results})
pretty_print_conversation(messages)
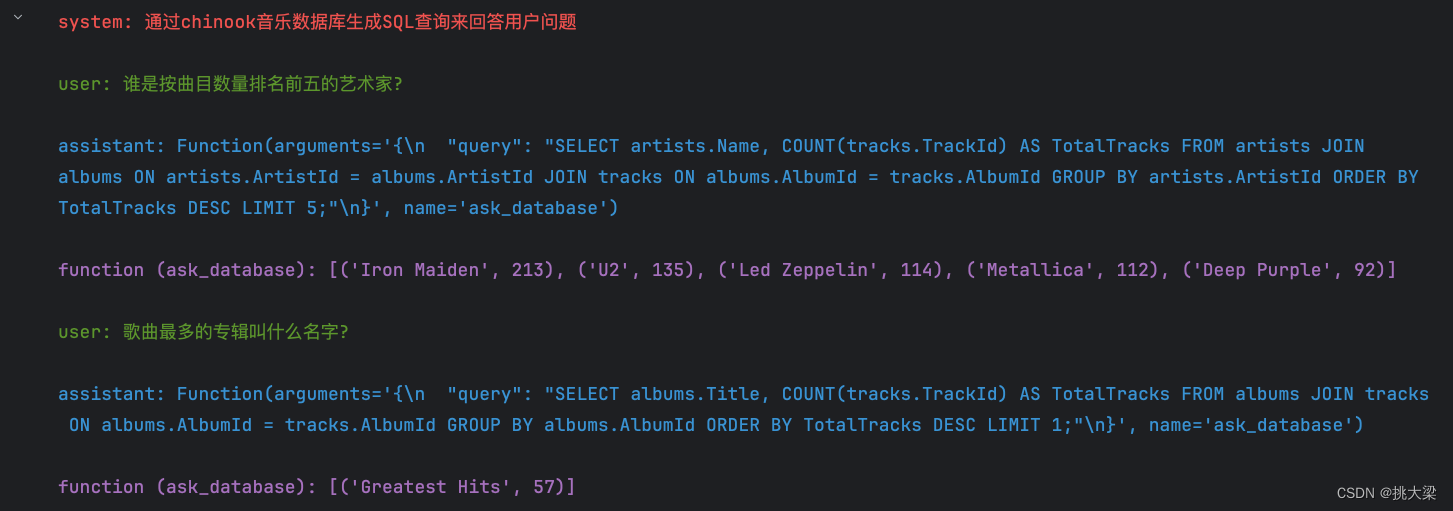
messages.append({"role": "user", "content": "歌曲最多的专辑叫什么名字?"})
chat_response = chat_completion_request(messages, tools)
assistant_message = chat_response.choices[0].message
assistant_message.content = str(assistant_message.tool_calls[0].function)
messages.append({"role": assistant_message.role, "content": assistant_message.content})
if assistant_message.tool_calls:
results = execute_function_call(assistant_message)
messages.append({"role": "function", "tool_call_id": assistant_message.tool_calls[0].id, "name": assistant_message.tool_calls[0].function.name, "content": results})
pretty_print_conversation(messages)


![[java基础揉碎]二维数组](https://img-blog.csdnimg.cn/direct/b2fc1dd24f664a89b2c7fd1558813c49.png)