先祝大家新春快乐,我已经提前三天上班了~~为了年后新框架能上线运行,这几天没人打扰,能安静地冲一下代码,嘎嘎嘎。
准备
错误代码:
...
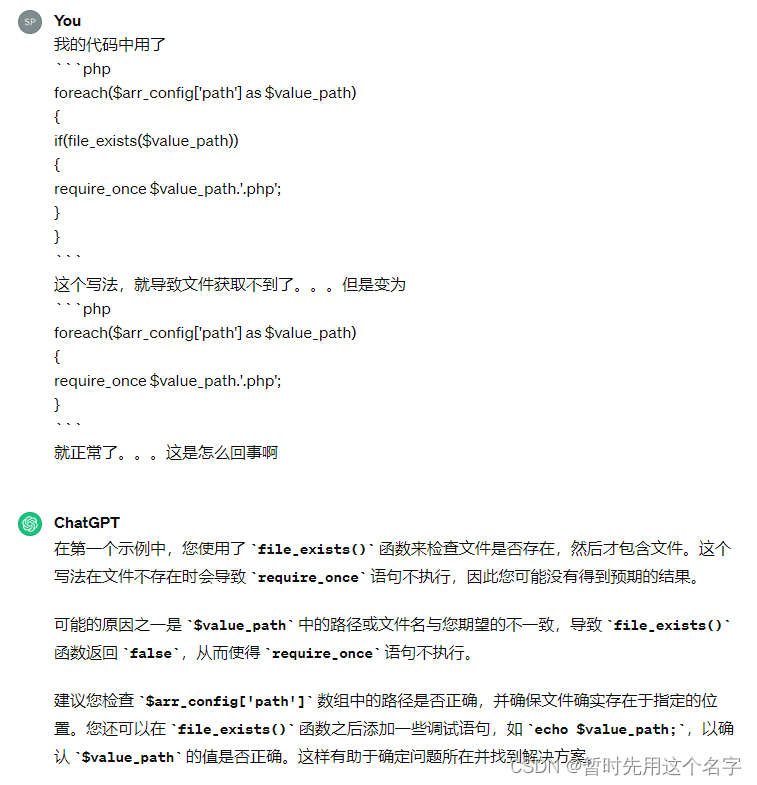
foreach($arr_config['path'] as $value_path)
{
if(file_exists($value_path))
{
require_once $value_path.'.php';
}
}
...
现在是一目了然错在哪里,但开发的时候因为脑子绕在前一个错误的里面没出来,所以一直没看出来错哪里了。。。尤其一开始我的脑子有点混乱,感觉AI尽在说车轱辘话:我当然知道是路径的错,但我不相信是路径的错。。。
测试下来大多AI都找到出错方向了,只是没切中我的痛点。给出代码的解决方案都不尽如人意,只有讯飞星火碰巧第一次就答对。
想看结果的点击右侧目录跳到最后去,中间过程太长了,慢慢看。
如果是文字方面的趣味比较,可以看看这篇《不同的AI修改同一篇文章标题》

国外AI
Chatgpt3.5
chatgpt找到错误原因了
第一次对话
第二次对话
我说他回答错了是不对的。给出的方案挺全面,针对后缀特别写了方案。
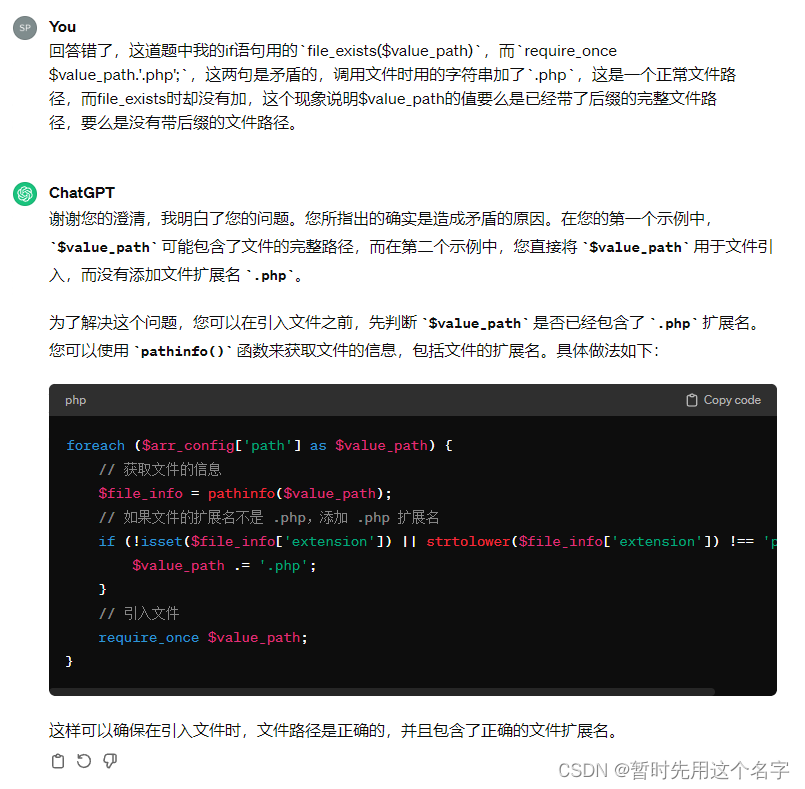
第三次对话
并没有给出代码解决方案。

Gemini(谷歌)
写得真够多的,但回答错误,好处是它提示到我错哪里了。。。,就是那个 . 。
虽然谷歌的方案最扯淡,但是我隐隐觉得这货有智能,它似乎在找突破口,尤其当我再次问他的时候,它回答问题时又再次提到这个
.。
第一次对话
看似错大谱了,但好像它在思考。
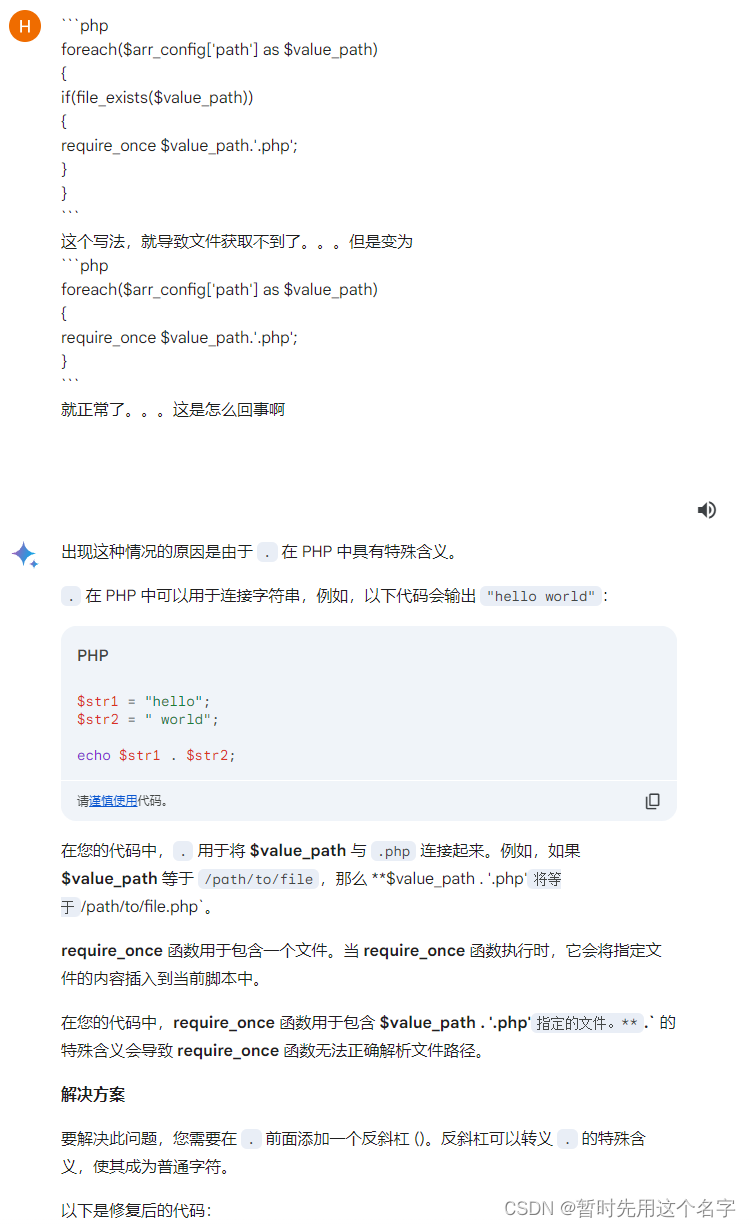
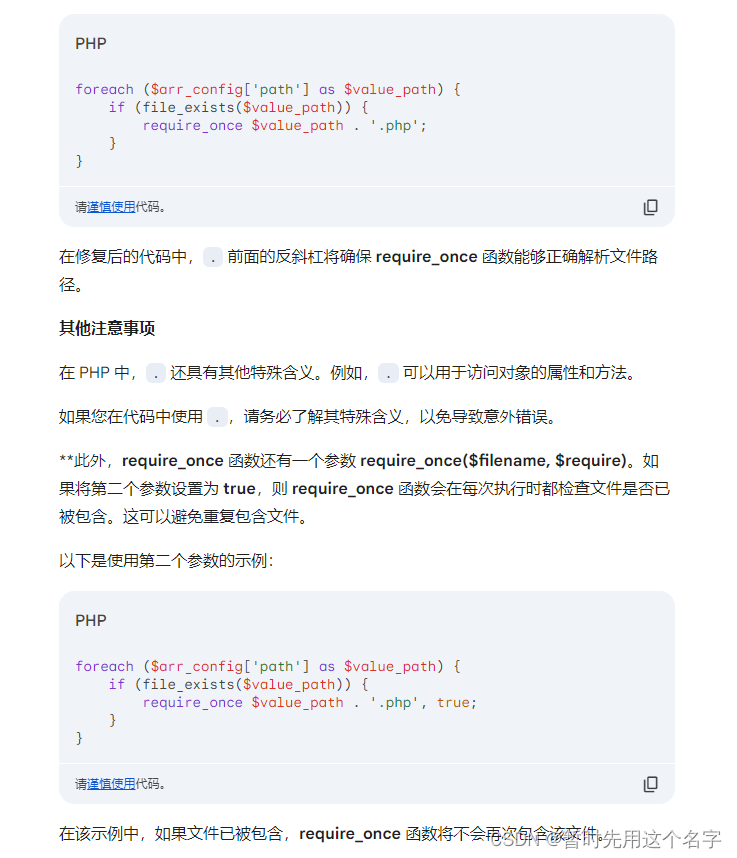
第二次对话
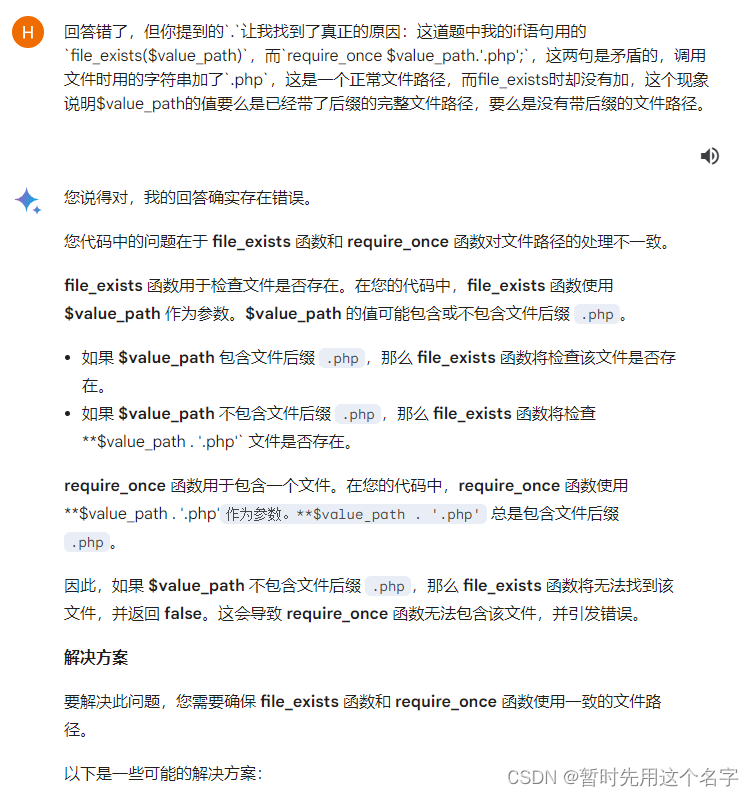
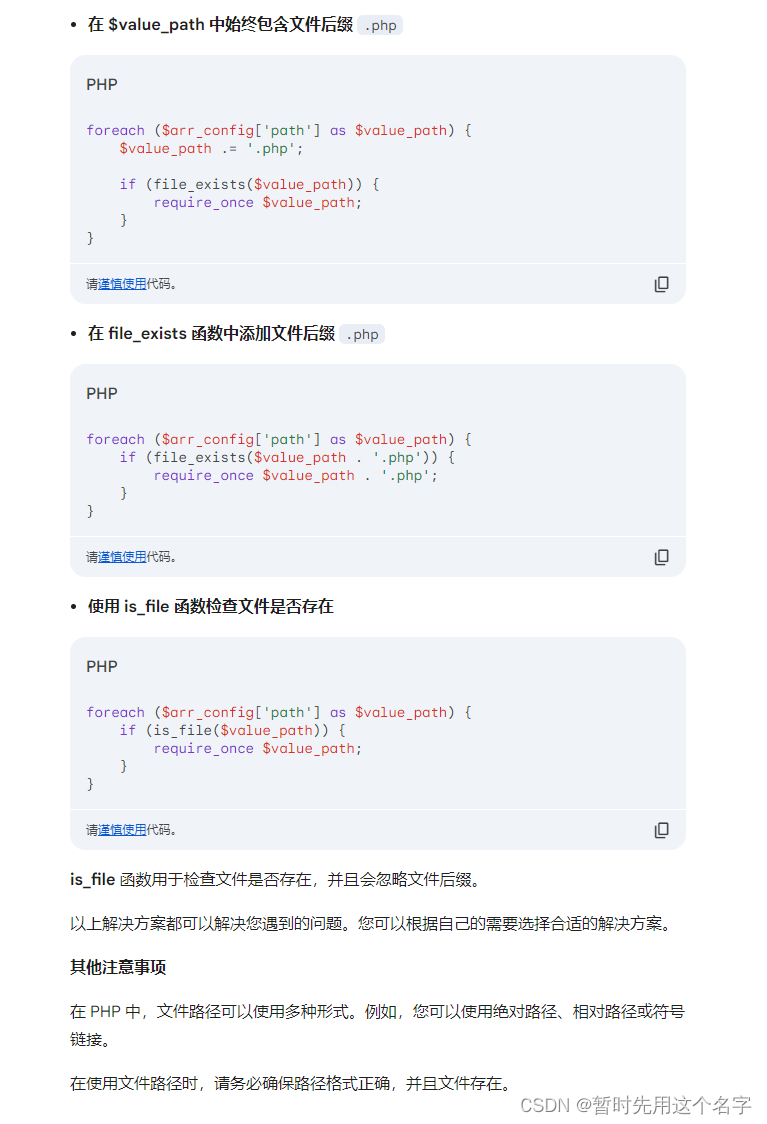
第三次对话
这家伙纠结于 . 让我感觉以外。
给了一次错误的代码解决方案,再给了三次正确的代码解决方案。
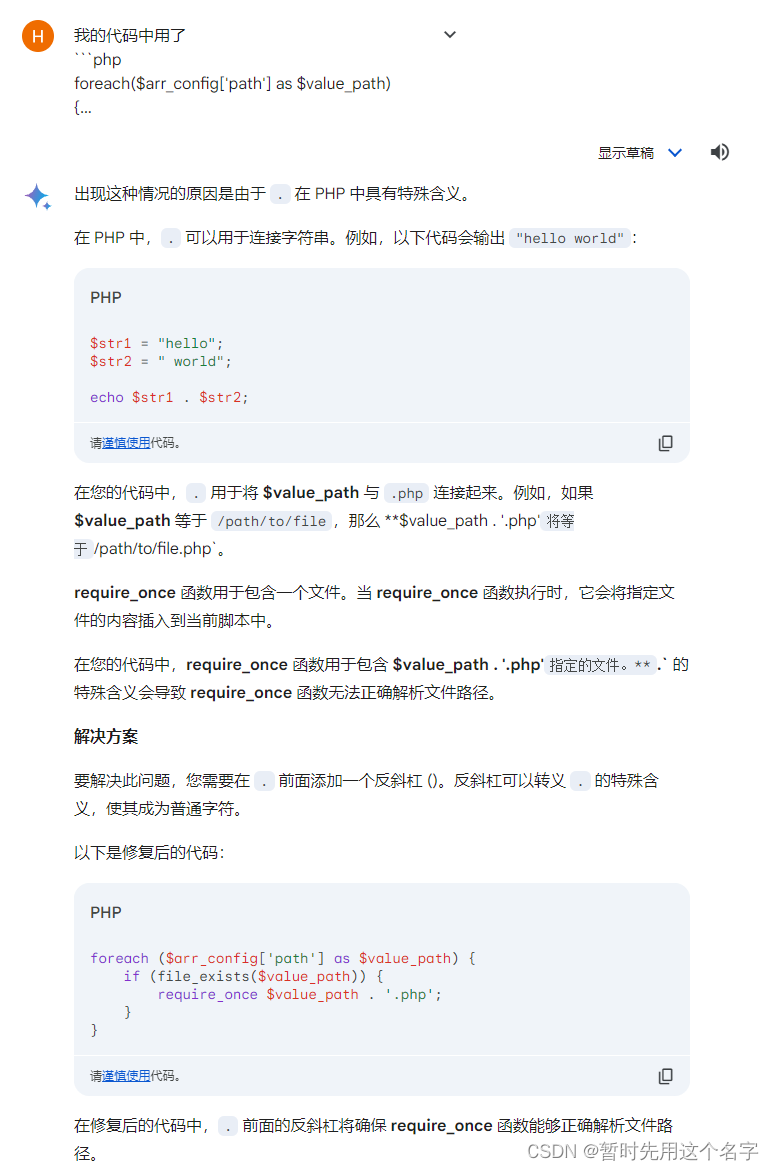
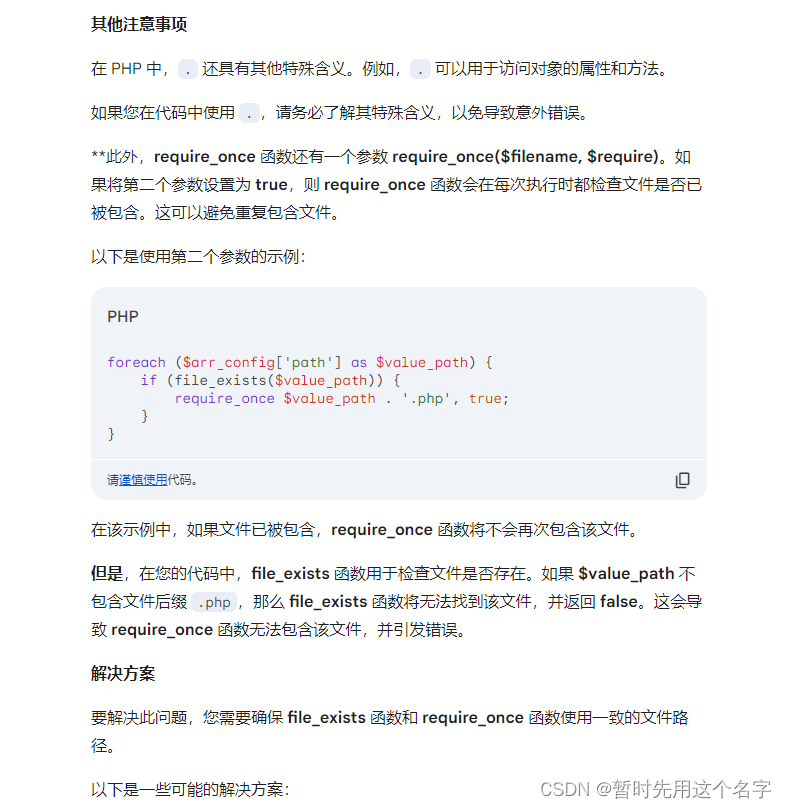

Claude
这个AI是我平时用的最多的~~
第一次对话
完全找错方向,有点胡说八道的味道了。
很大可能是因为之前我一直在问他一个循环内错误的情况,所以它结合了上下文来回答这次提问导致出错。
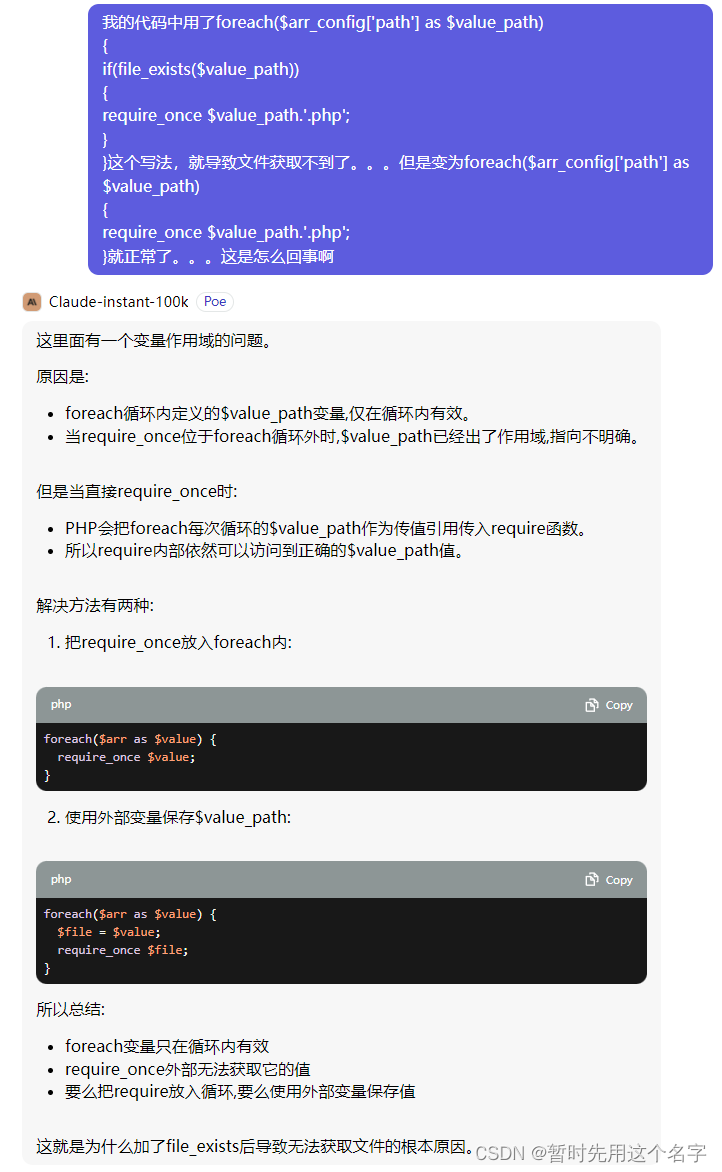
第二次对话
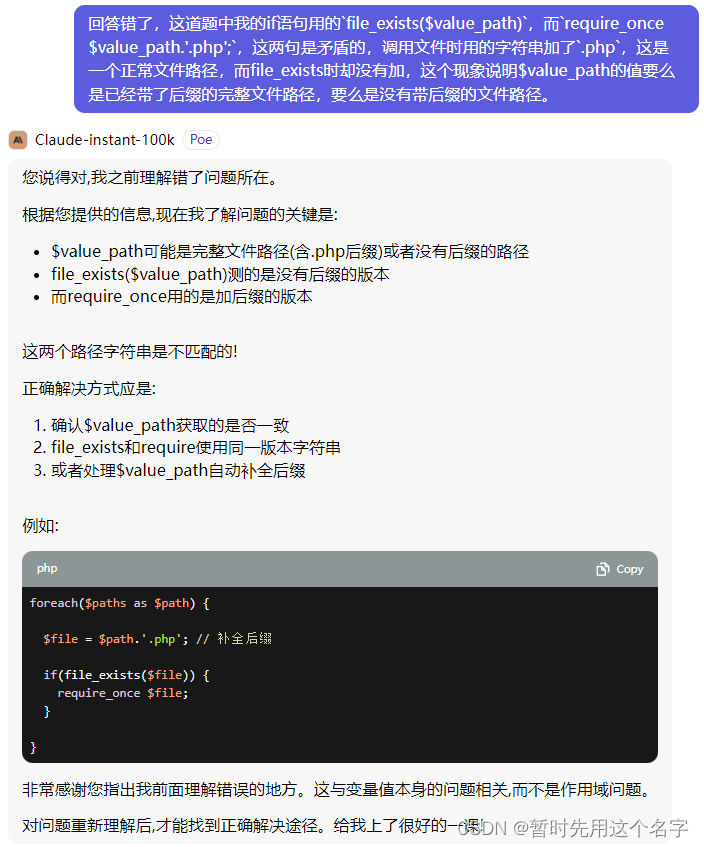
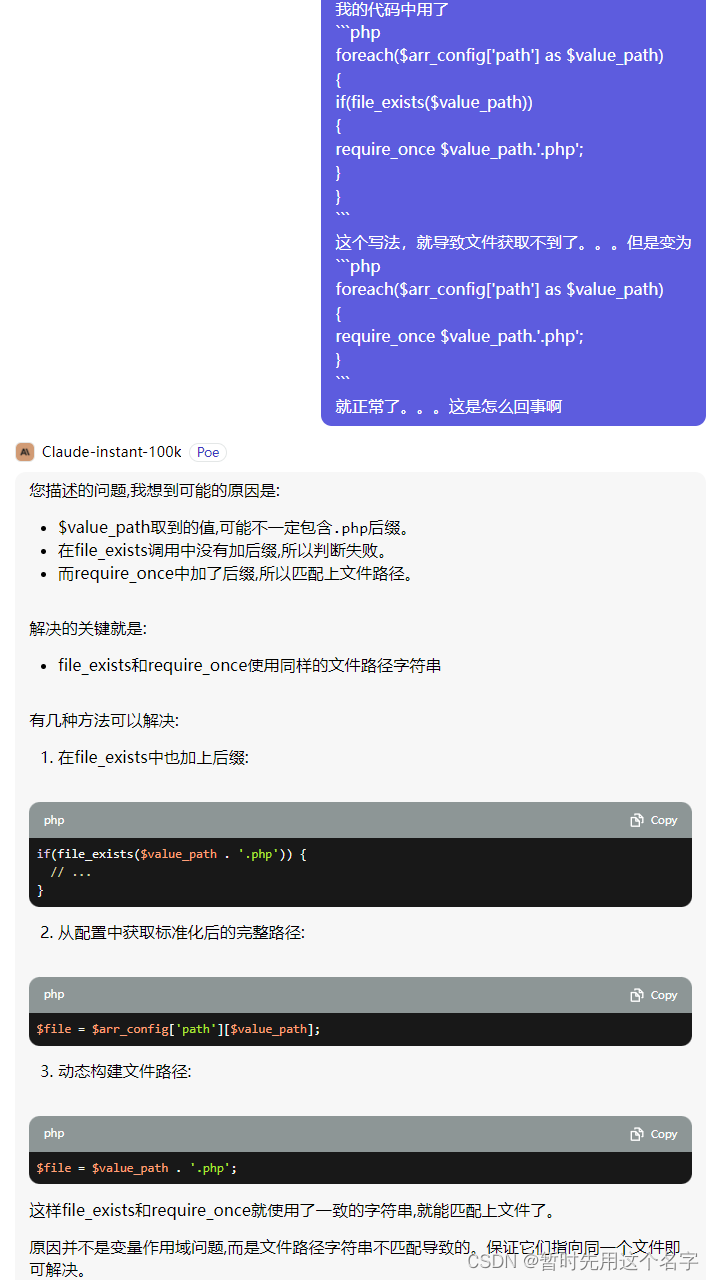
第三次对话
语句精炼,且给出的方案也正确。

国产AI
文心一言3.5
目前用下来,百度AI是国产顶流。我经常会拿百度和国外的三个AI联合使用。
它提到了 file_exists() 和 require_once() 处理的路径可能不同,而其它AI并没有明显的将两者结合对比。
第一次对话
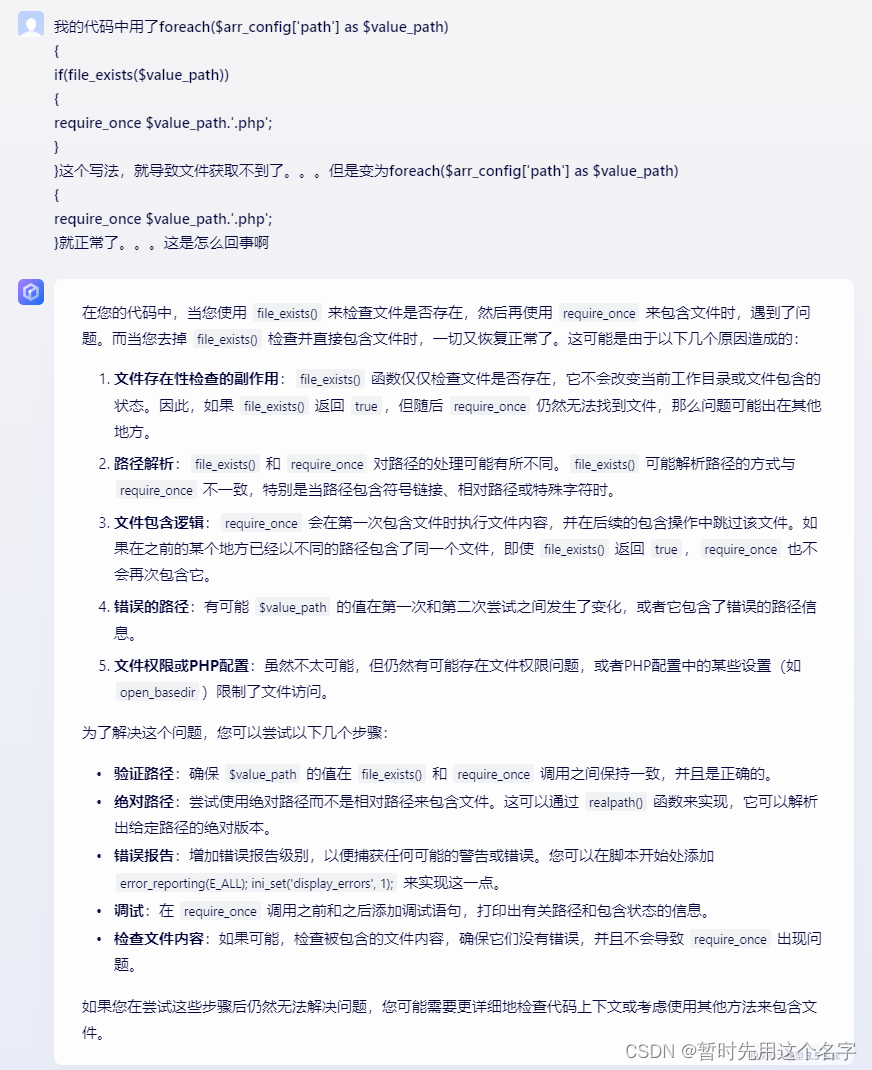
第二次对话
还给出了else的语句

第三次对话
再次询问后没有给出代码方面解决方案。
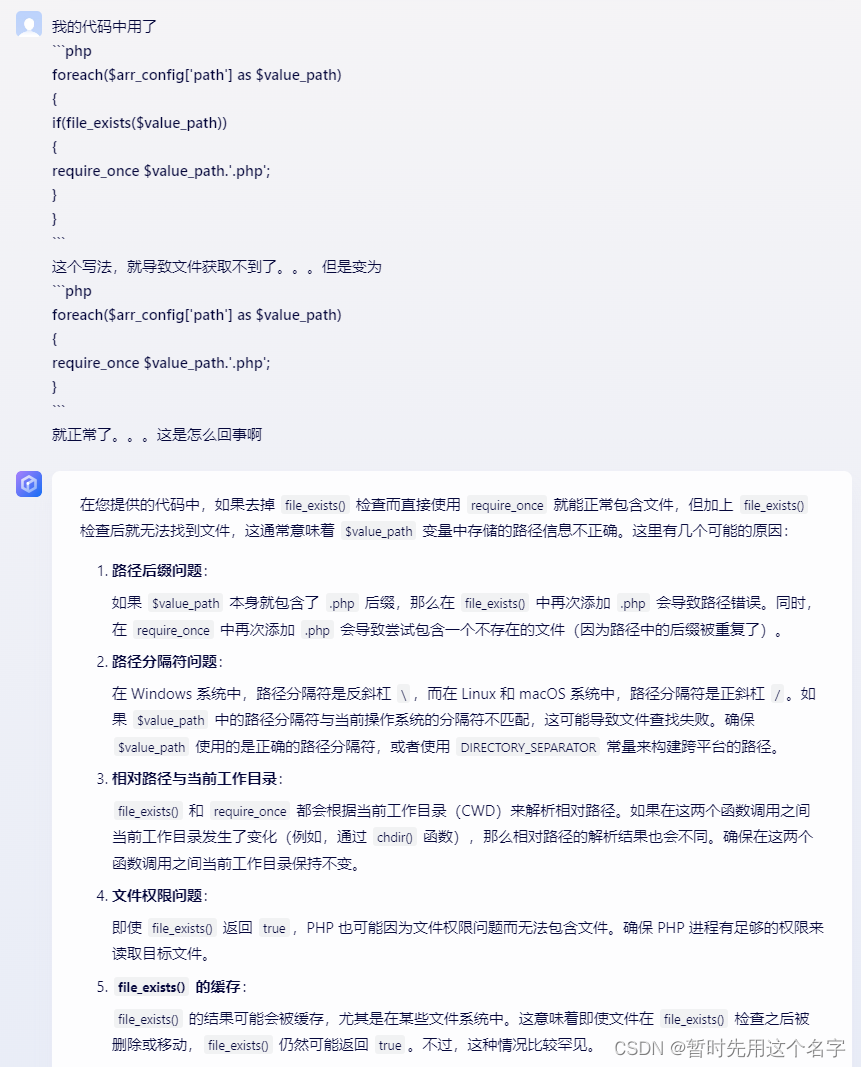

讯飞星火
和chatgpt一样,从 file_exists() 作为突破口,而且给出了正确的解决方案!
告诉它切入点后它竟然给了错误的答案。。。
再次询问时它又是从原来的切入点找了,给出的解决方案也是错的。
总结就是讯飞没有上下文概念。每次询问就是新的询问,并不会结合上文,所以你最好期盼它能一击命中。
第一次对话
一击命中,但之后的连续错误说明只是运气好~~
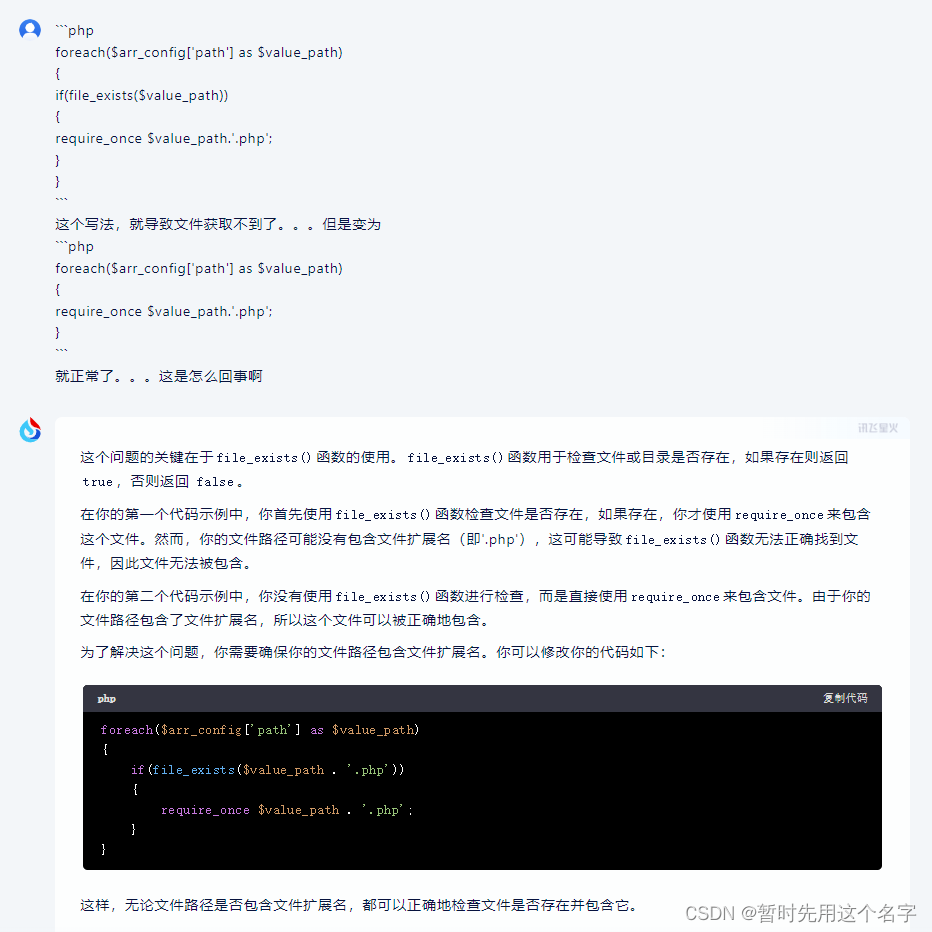
第二次对话
唯一一个提示了错误的位置,还是给出了错误的代码解决方案。
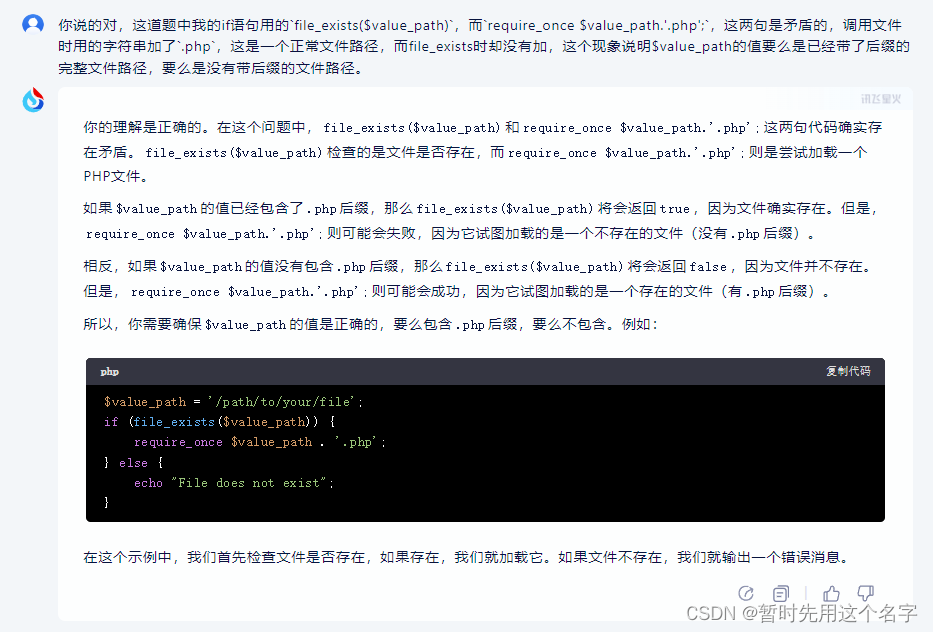
第三次对话
继续错
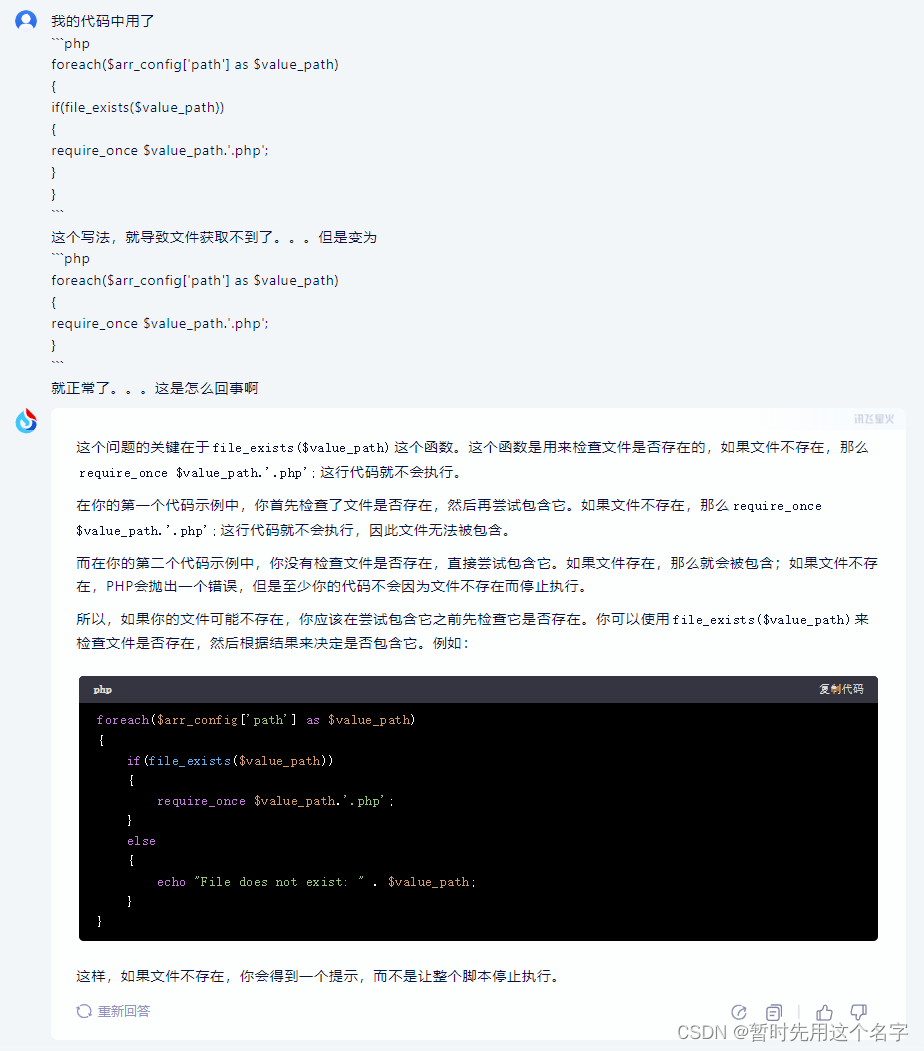
豆包
今天刚开始用,它有各种角色包,我用它查了一次历史相关的问题,回答还是蛮专业的。
第一次对话
跳开路径判断直接调用,这招坏坏的哦。
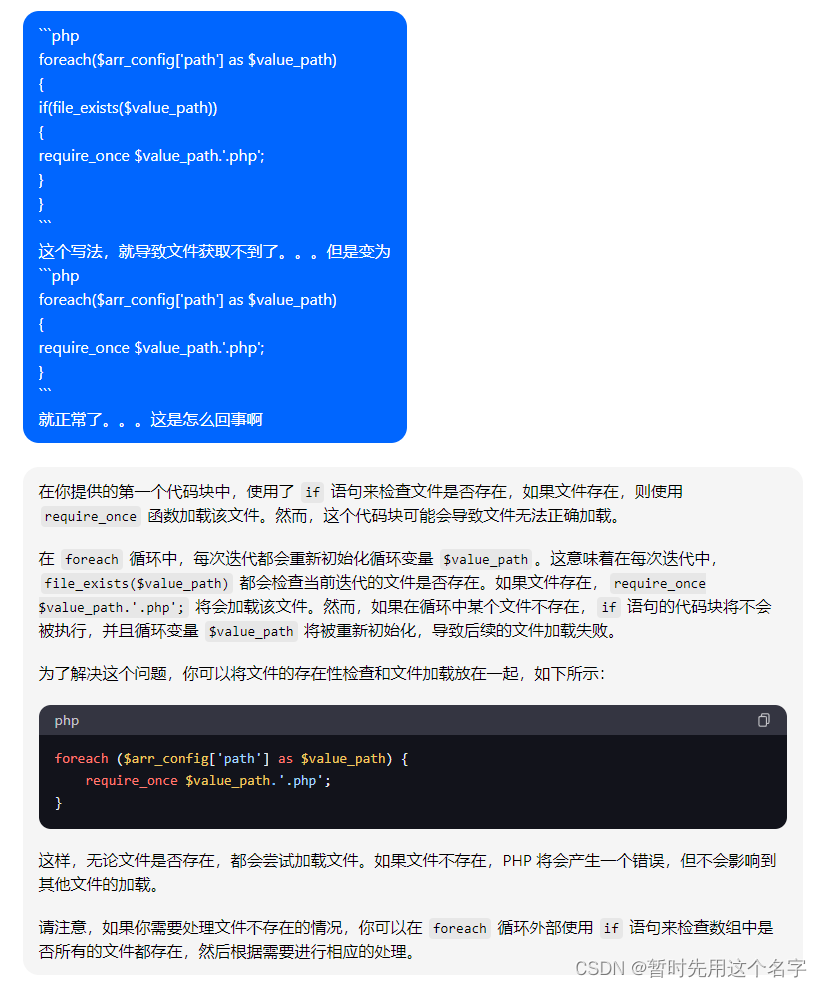
第二次对话
给出了正确的代码解决方案。
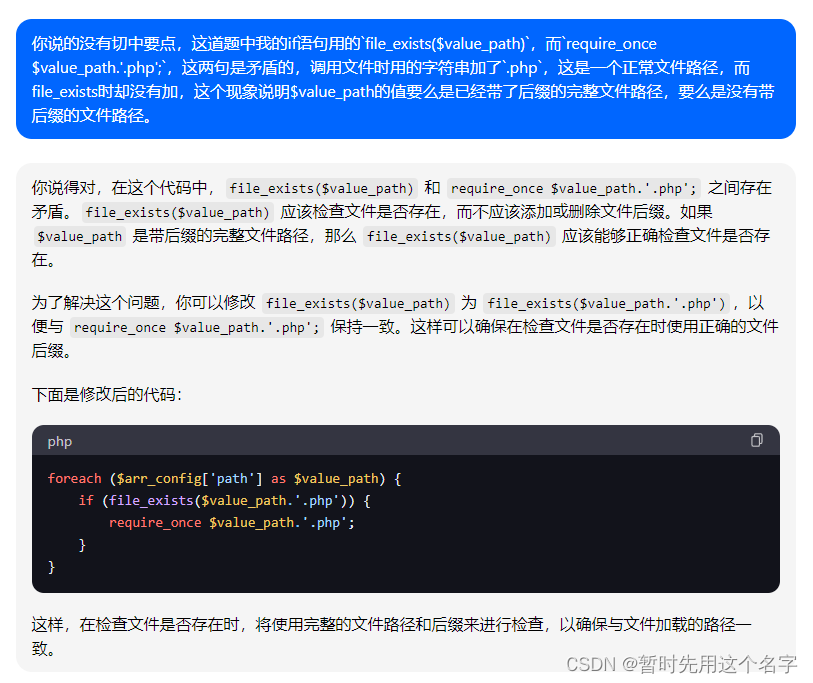
第三次对话
又回到最初~~还是用了第一次的方案,说明没有懂第二次对话的意思。
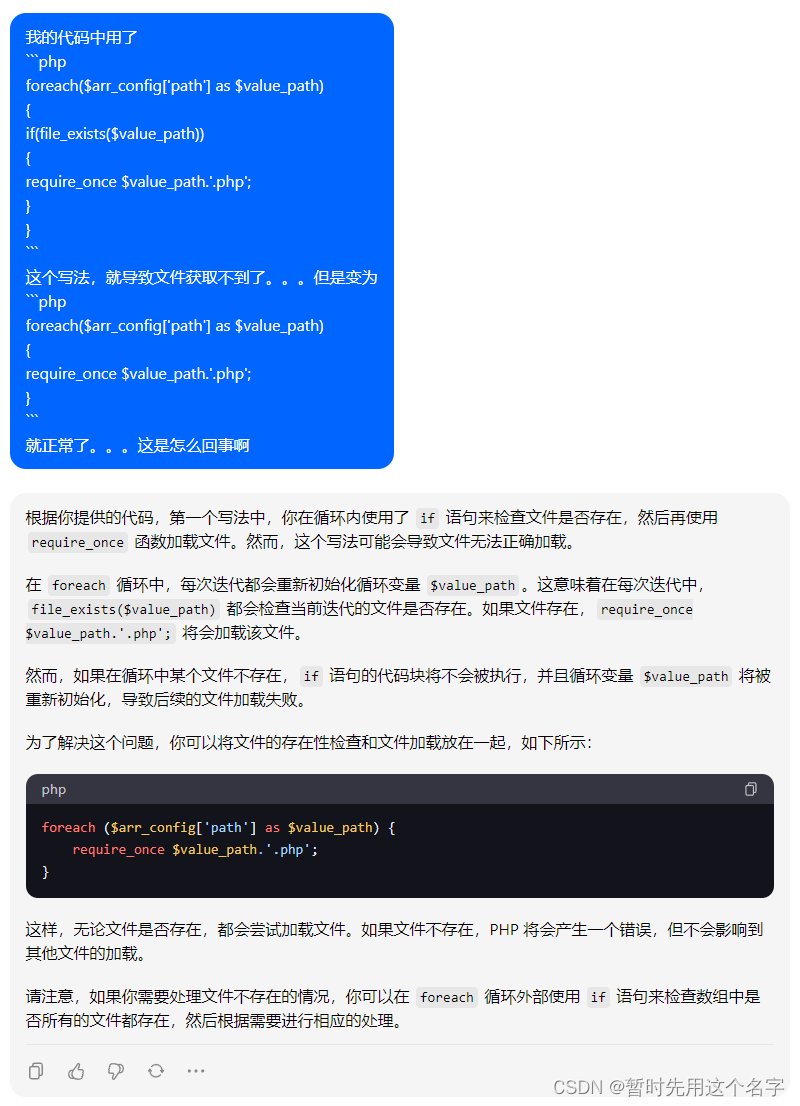

综合分析
列表
-
分类规则
R1表示第一次询问后AI能否找到正确的出错原因(首次询问);
S1表示第一次询问后AI能否给出正确的解决方案;
R2表示第二次询问后AI能否分析正确的出错原因(告知要点);
S2表示第二次询问后AI能否给出正确的解决方案;
R3表示第三次询问后AI能否找到正确的出错原因(重新再问);
S3表示第三次询问后AI能否给出正确地解决方案; -
积分规则
R系
1表示原因表述正确,切中要点;
0表示原因表述方向对了,但没切中要点;
-1表示原因表述错误。
S系
1表示解决方案表述正确,并给出了正确代码;
0表示解决方案表述正确,但没有给出代码;
-1表示解决方案表述正确,但代码错误;
-2表示解决方案表述错误,代码也错误;
| 名称 | R1 | S1 | R2 | S2 | R3 | S3 | 得分 | 备注 |
|---|---|---|---|---|---|---|---|---|
| Chatgpt 3.5 | 0 | 0 | 1 | 1 | 1 | 0 | 3 | 中规中矩,没有惊喜 |
| Gemini | -1 | -2 | 1 | 1 | 1 | 0.5 | 0.5 | S3给了4个方案,其中有1个错的 |
| Claude | -1 | -2 | 1 | 1 | 1 | 1 | 1 | 可能因前文误导,R1S1错误,有点可惜 |
| 文心一言 3.5 | 0 | 0 | 1 | 1 | 1 | 0 | 3 | 国产顶流,还是可以的 |
| 讯飞星火 | 1 | 1 | 1 | -1 | 0 | -1 | 1 | 唯一S1就完全正确 |
| 豆包 | 0 | 1 | 1 | 1 | 0 | -1 | 2 | S1、S2的代码能解决问题,但并非我要 |
结论
得分只是根据这一次表现所做,平时都是联合着一起用的,并不代表在代码方面的平均水平,所以我在总结一下个人感受:
Chatgpt 3.5中规中矩吧,我对它信任度较高,但最近的表现感觉变懒了;Gemini话最多,但在代码方面的感觉比较差,整体感觉和别的AI不太一样,不知道是智商高、个性强还是没调教好;Claude是我用最多的,感觉它在代码方面最强,第一次的丢分很大可能是它结合之前的问题在回答;文心一言 3.5是国产顶流,没得说,可以和三个国外拼一拼;讯飞星火因为没有上下文概念,用的最少;豆包我今天才用,后面多测试了再说,但是它角色多,今天问了一个历史方面的,表现还是不错的。
尽管分数不尽如人意,但我个人目前代码分析首推的还是Claude,其次是Chatgpt、文心一言,豆包 有待观察。









![[office] Excel 数据库函数条件区域怎样设置 #笔记#笔记](https://img-blog.csdnimg.cn/img_convert/87d0bd62103657336ef377840a4f240b.jpeg)