大模型
一般指1亿以上参数的模型,目前万亿级参数以上的模型也有了。
参数大小
175B、60B、540B等,这些一般指参数的个数,B是Billion/十亿的意思,175B是1750亿参数,这是ChatGPT大约的参数规模。
显存占用
- 6B的大模型,FP16精度进行微调大约需要14GB显存,而INT4量化后只需要7GB显存。
- 34B的大模型需要20GB以上的显存才能部署和推理,因此34B这个大小差不多是单机能部署的最大上限的模型。
模型精度
| 格式 | 符号位 | 指数位 | 小数位 | 总数位 |
|---|---|---|---|---|
| FP64 | 1 | 11 | 52 | 64 |
| FP32 | 1 | 8 | 23 | 32 |
| TF32 | 1 | 8 | 10 | 19 |
| BF16 | 1 | 8 | 7 | 16 |
| FP16 | 1 | 5 | 10 | 16 |
| FP8 E4M3 | 1 | 4 | 3 | 8 |
| FP8 E5M2 | 1 | 5 | 2 | 8 |
| FP4 | 1 | 2 | 1 | 4 |
- 浮点数精度:双精度(FP64)、单精度(FP32、TF32)、半精度(FP16、BF16)、8位精度(FP8)、4位精度(FP4、NF4)
- 量化精度:INT8、INT4 (也有INT3/INT5/INT6的)
- 多精度:是指用不同精度进行计算,在需要使用高精度计算的部分使用双精度,其他部分使用半精度或单精度计算。
- 混合精度:是在单个操作中使用不同的精度级别,从而在不牺牲精度的情况下实现计算效率,减少运行所需的内存、时间和功耗
大模型综述:
https://arxiv.org/abs/2303.18223
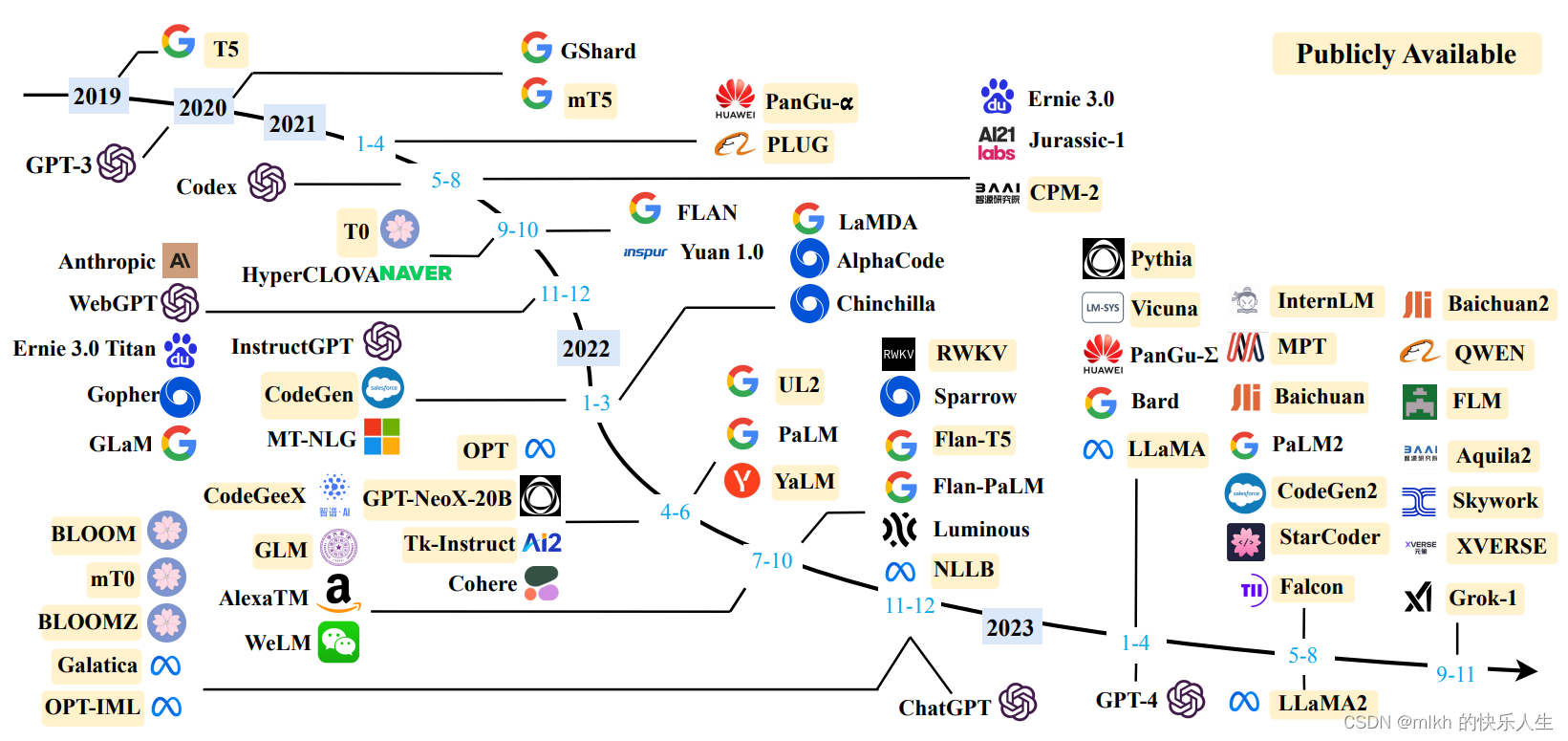
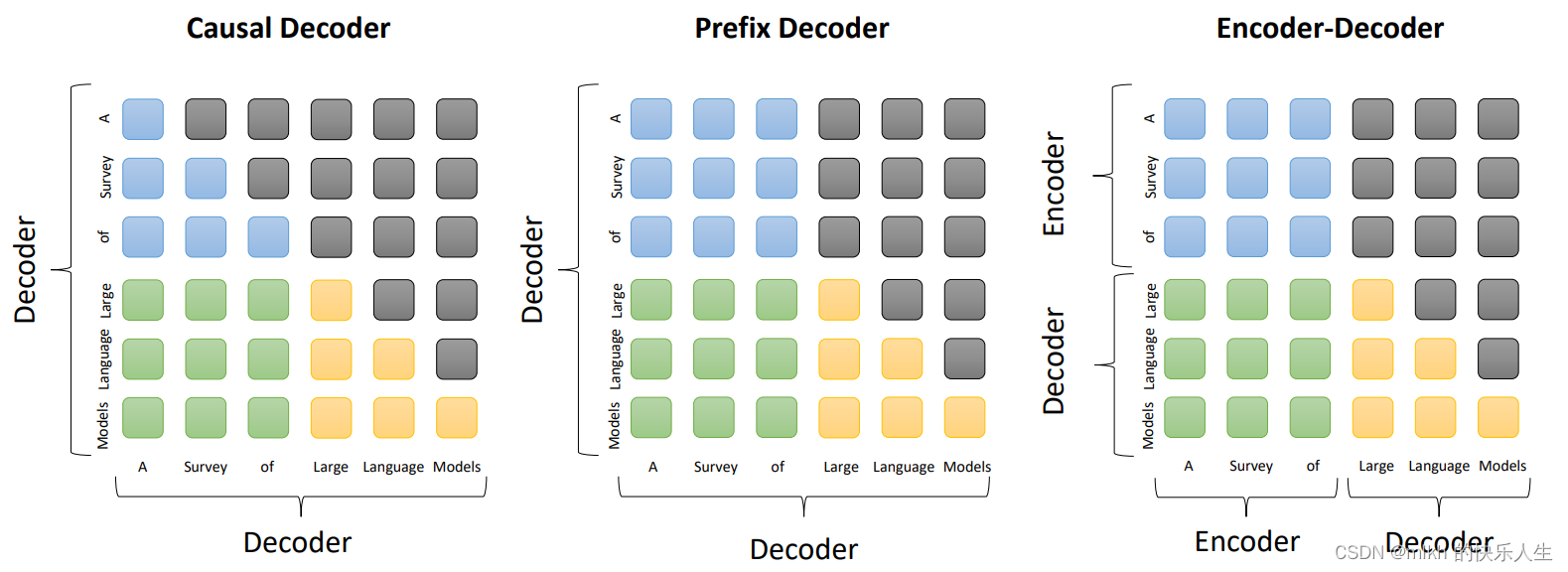
大模型结构
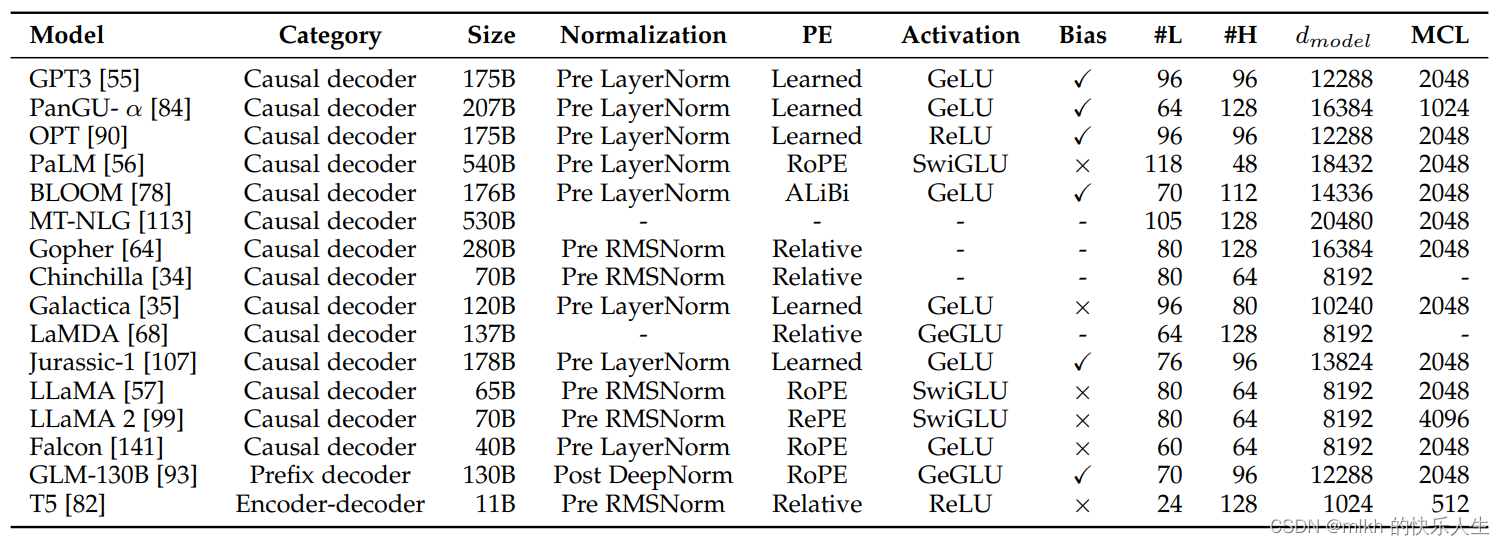
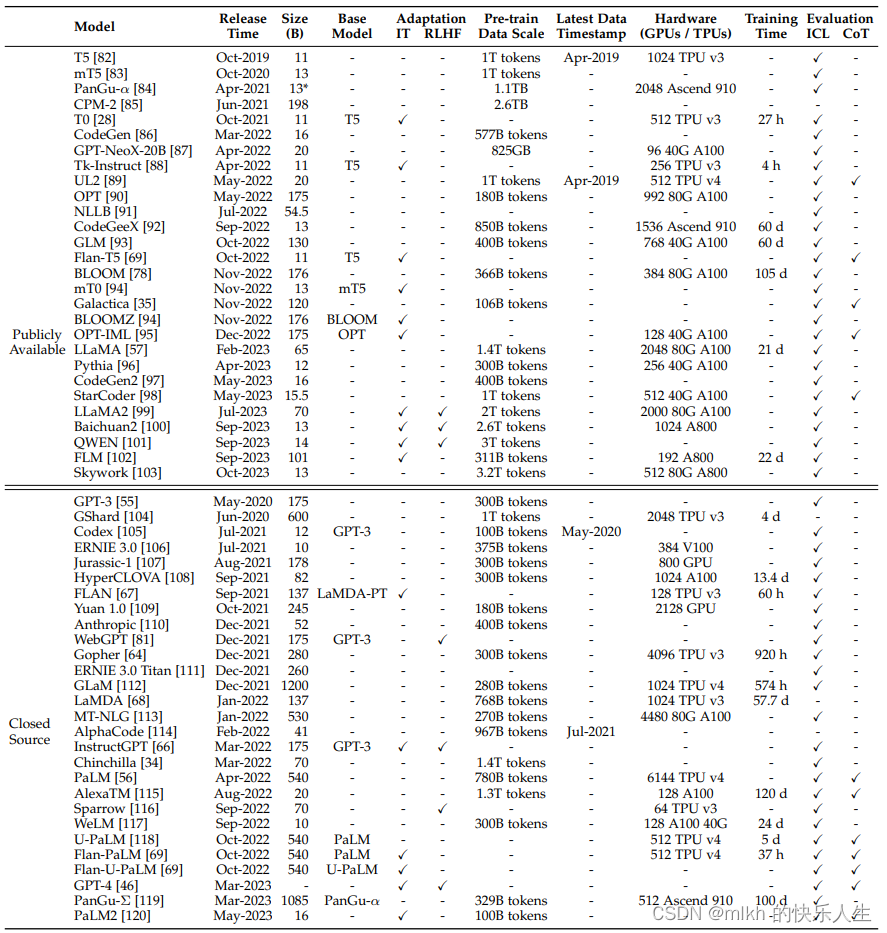
大模型显卡需求
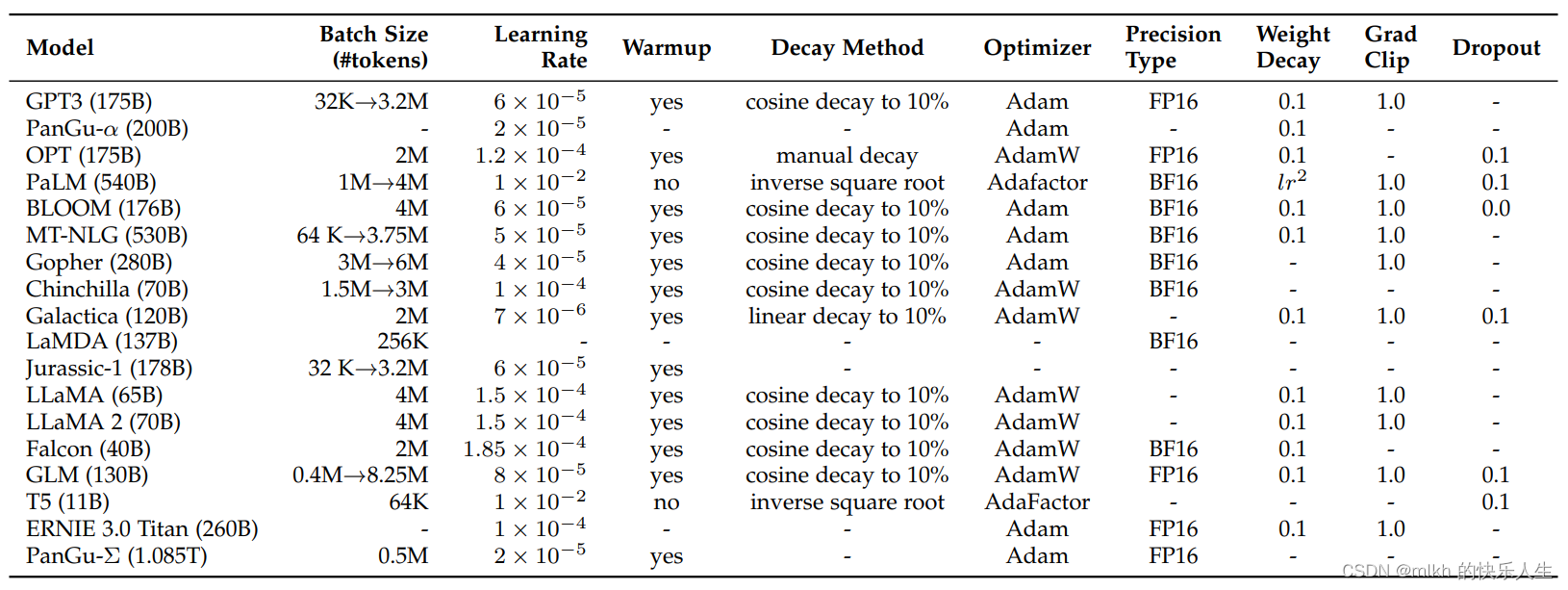
大模型优化参数
LLaMA训练

![[java基础揉碎]二维数组](https://img-blog.csdnimg.cn/direct/b2fc1dd24f664a89b2c7fd1558813c49.png)