🎈个人主页:甜美的江
🎉欢迎 👍点赞✍评论⭐收藏
🤗收录专栏:机器学习
🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步!
数据清洗之识别缺失点
- 一 缺失值的概念及危害
- 1.1 缺失值的概念
- 1.2 缺失值的危害:
- 二 识别缺失值:
- 2.1 可视化检查:
- 2. 2 统计描述:
- 2.3 编程检查

引言:
在机器学习领域,数据的质量直接关系到模型的性能和可靠性。而在实际应用中,我们往往面临一个普遍存在的问题——缺失值。缺失值可能因为各种原因而产生,如传感器故障、数据采集错误或者主观选择性填写。因此,深入了解并识别缺失值成为数据清洗的重要步骤之一。
本文将探讨缺失值的概念及其危害,并介绍在数据清洗中如何通过可视化检查、统计描述以及编程检查等方法来有效地识别缺失值,从而为后续的数据处理和建模奠定基础。
一 缺失值的概念及危害
当涉及到数据清洗时,缺失值是一个非常重要的概念。缺失值指的是数据集中某些字段或变量中的数据项缺失或未填充的情况。
这些缺失值可能出现在数据收集、传输、存储或处理的任何阶段,其存在可能会带来许多危害。
以下是关于缺失值的概念以及其危害的详细介绍:
1.1 缺失值的概念
定义:
缺失值是指在数据集中某些字段或变量中缺少数据值或者未填充的值。这些缺失值通常用特殊的标识符(如NaN、NULL、NA等)来表示。
类型:
缺失值可以是完全随机的,也可以是有规律的(如某个特定的条件下出现缺失)。常见的缺失值类型包括单个值缺失、整行数据缺失、连续值序列缺失等。
1.2 缺失值的危害:
1 影响数据质量:
缺失值会降低数据集的质量和可用性,使数据分析和建模的结果变得不准确和不可靠。
2 偏倚分析结果:
当数据中存在缺失值时,可能会导致分析结果产生偏差,从而影响对数据的正确理解和决策制定。
3 减少数据样本量:
在数据清洗过程中,删除包含缺失值的数据项或者变量会导致数据样本量减少,进而降低模型的训练效果和泛化能力。
4 失去信息:
缺失值可能包含重要的信息,因此简单地删除缺失值可能会导致信息的丢失,从而影响数据分析的完整性和准确性。
5 影响统计分析:
缺失值会影响统计分析的结果,例如均值、方差等统计指标会因缺失值而产生偏差。
6 导致误解:
缺失值的存在可能导致对数据的误解,使得对现实世界情况的理解出现偏差或错误。
二 识别缺失值:
在处理缺失值之前,我们需要先找出缺失值,而找出缺失值主要有以下三种方法:
2.1 可视化检查:
在数据清洗中,通过可视化方法来识别缺失值是一种直观且有效的方式。
以下是一些常用的可视化检查方法:
1 热力图(Heatmap):
方法:
使用热力图可以直观地显示整个数据集中缺失值的分布情况。通常,热力图中缺失值的部分会以不同颜色或阴影表示。
工具:
可以使用Python中的Seaborn或Matplotlib库来创建热力图。
import seaborn as sns
import matplotlib.pyplot as plt
sns.heatmap(data.isnull(), cbar=False, cmap='viridis')
plt.show()
2 缺失值比例柱状图:
方法:
绘制柱状图,显示每个变量中缺失值的比例。这可以帮助识别哪些变量受到缺失值的影响较大。
工具:
使用Matplotlib或Seaborn库创建柱状图。
import matplotlib.pyplot as plt
missing_percentage = (data.isnull().sum() / len(data)) * 100
missing_percentage = missing_percentage[missing_percentage > 0]
missing_percentage.sort_values(inplace=True)
plt.bar(missing_percentage.index, missing_percentage)
plt.xlabel('Variables')
plt.ylabel('Missing Percentage')
plt.xticks(rotation=45)
plt.show()
3 缺失值的分布直方图:
方法:
对于特定变量,绘制其缺失值的分布直方图,以了解缺失值在该变量上的分布情况。
工具:
使用Matplotlib或Seaborn库创建直方图。
import matplotlib.pyplot as plt
plt.hist(data['Variable_with_missing'], bins=20, color='skyblue', edgecolor='black')
plt.xlabel('Variable_with_missing')
plt.ylabel('Frequency')
plt.title('Distribution of Missing Values')
plt.show()
4 缺失值的模式图:
方法:
绘制缺失值的模式图,以显示数据集中缺失值的模式。
这有助于识别是否存在特定的缺失值模式。
工具:
可以使用Seaborn的clustermap方法。
import seaborn as sns
sns.clustermap(data.isnull(), cmap='viridis')
plt.show()
这些可视化方法能够帮助数据科学家和分析师更好地理解数据集中的缺失值分布情况,从而采取有针对性的数据清洗策略。
示例
代码:
import matplotlib.pyplot as plt
import pandas as pd
# 读取数据集
height_data = pd.read_csv(r"D:\jupter notebook\base\机器学习\数据预处理\数据清洗\data\height_data.csv")
# 打印缺失值的数量
missing_values = height_data['Height'].isnull().sum()
print(f"Total Missing Values: {missing_values}")
# 显示缺失的ID
missing_ids = height_data[height_data['Height'].isnull()]['ID'].tolist()
print(f"Missing IDs: {missing_ids}")
# 创建直方图
plt.hist(height_data['ID'], bins=10, color='skyblue', edgecolor='black', alpha=0.7, label='All IDs')
plt.hist(missing_ids, bins=10, color='red', edgecolor='black', alpha=0.7, label='Missing IDs')
plt.xlabel('ID')
plt.ylabel('Frequency')
plt.title('Distribution of IDs with Missing Values')
plt.legend()
plt.show()
数据集内容如下:
ID,Height
1,170
2,165
3,180
4,NaN
5,175
6,172
7,168
8,NaN
9,185
10,170
运行结果:
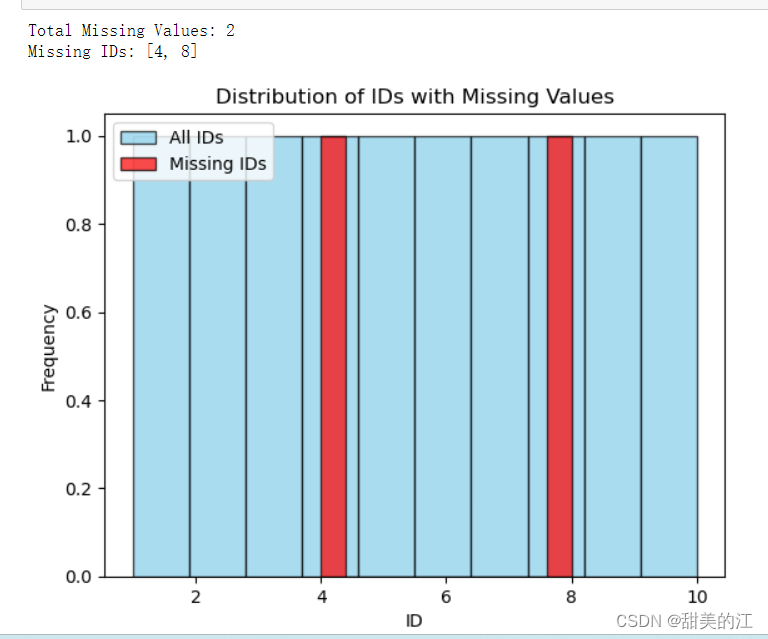
在这个示例中,使用plt.hist()函数分别绘制了所有ID和缺失ID的直方图,并在图例中添加了标签。在图表上,缺失ID的数据用红色表示。此外,代码还打印了缺失值的总数量以及缺失的具体ID,从直方图上可以明显地看出,一共有两个数据缺失,缺失数据的ID分别是4,8。
代码分析:(给小白看的)
import matplotlib.pyplot as plt
导入matplotlib库,用于绘制图表。
import pandas as pd
导入pandas库,用于数据处理。
height_data = pd.read_csv(
r"D:\jupter notebook\base\机器学习\数据预处理\数据清洗\data\height_data.csv")
使用pandas的read_csv()函数从指定路径读取名为height_data.csv的数据集文件,并将其存储在名为height_data的DataFrame中。
missing_values = height_data['Height'].isnull().sum()
使用isnull()函数检查Height列中的缺失值,并使用sum()函数计算缺失值的数量,将结果存储在变量missing_values中。
print(f"Total Missing Values: {missing_values}")
打印缺失值的总数量。
missing_ids = height_data[height_data['Height'].isnull()]['ID'].tolist()
使用布尔索引选择Height列中存在缺失值的行,并提取这些行中的ID列,然后将其转换为列表形式,存储在变量missing_ids中。
print(f"Missing IDs: {missing_ids}")
打印缺失的ID。
plt.hist(height_data['ID'], bins=10, color='skyblue',
edgecolor='black', alpha=0.7, label='All IDs')
使用plt.hist()函数创建一个直方图,绘制所有ID的分布情况
height_data[‘ID’]是要绘制直方图的数据列
bins=10指定直方图的柱子数量为10个
color='skyblue’设置直方图的颜色为天蓝色
edgecolor='black’设置直方图的边框颜色为黑色
alpha=0.7设置透明度为0.7
label='All IDs’设置图例标签为"All IDs"
plt.hist(missing_ids, bins=10, color='red',
edgecolor='black', alpha=0.7, label='Missing IDs')
再次使用plt.hist()函数创建一个直方图,绘制缺失ID的分布情况
missing_ids是要绘制直方图的数据,其余参数设置与上一步类似
label='Missing IDs’设置图例标签为"Missing IDs"
plt.xlabel('ID')和plt.ylabel('Frequency')
分别设置X轴和Y轴的标签。
plt.title('Distribution of IDs with Missing Values')
设置图表的标题为"Distribution of IDs with Missing Values",表示具有缺失值的ID的分布情况。
plt.legend()
添加图例,用于区分不同的直方图。
plt.show()
显示创建的图表。
这段代码的主要功能是可视化身高数据集中ID的分布情况,并通过不同颜色的直方图区分具有缺失值的ID。同时,代码还打印了缺失值的总数量和缺失的ID。
2. 2 统计描述:
在数据清洗过程中,识别缺失值的统计描述方法有助于了解数据集中缺失值的分布、缺失模式和缺失值的数量。以下是一些常用的统计描述方法:
1 缺失值数量统计:
简单地计算每个变量中缺失值的数量,这可以通过使用isnull()和sum()函数实现。
示例代码:
missing_count = data.isnull().sum()
print(missing_count)
2 缺失值比例统计:
计算每个变量中缺失值的比例,通常以百分比的形式呈现。
示例代码:
missing_percentage = (data.isnull().sum() / len(data)) * 100
print(missing_percentage)
3 缺失值的汇总统计:
使用describe()函数生成有关数据集中缺失值的统计摘要,包括均值、标准差、最小值、25th、50th(中位数)、75th百分位数和最大值。
示例代码:
missing_summary = data.describe(include='all', datetime_is_numeric=True)
print(missing_summary)
4 缺失值的累积统计:
对数据集进行累积求和,生成一个累积缺失值的统计图,有助于识别哪些部分的数据更容易受到缺失值的影响。
示例代码:
cumulative_missing = data.isnull().cumsum()
print(cumulative_missing)
5 缺失模式统计:
通过统计不同缺失模式的出现频率,可以发现是否存在某些变量同时缺失的趋势。
示例代码:
missing_pattern_count = data.apply(tuple, axis=1).duplicated().sum()
print(f"Number of rows with the same missing pattern: {missing_pattern_count}")
这些统计描述方法为数据清洗提供了一个全面的视角,使数据科学家能够更好地理解数据集中缺失值的性质,为后续的处理和填充提供指导。
2.3 编程检查
识别缺失值是数据清洗中的一个关键步骤,它有助于我们理解数据集的完整性并采取适当的处理措施。以下是一些常用的编程检查方法:
1 使用isnull()函数:
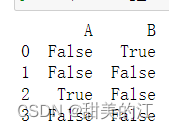
在Python中,我们可以使用isnull()函数来检查数据集中的缺失值。
这个函数会返回一个布尔值的DataFrame,其中缺失值对应的位置为True,非缺失值为False。
示例代码:
import pandas as pd
# 创建一个示例DataFrame
data = pd.DataFrame({'A': [1, 2, None, 4],
'B': [None, 5, 6, 7]})
# 使用isnull()函数检查缺失值
missing_values = data.isnull()
print(missing_values)
运行结果:
2 使用any()函数:
any()函数用于检查DataFrame中每列是否存在至少一个True值,即是否存在缺失值。
示例代码:
# 检查是否存在缺失值
any_missing = missing_values.any()
print(any_missing)
3 使用sum()函数:
sum()函数可以对布尔值的DataFrame进行求和,统计每列中True值(缺失值)的数量。
示例代码:
# 统计每列缺失值的数量
missing_count = missing_values.sum()
print(missing_count)
4 使用info()函数:
info()函数可以提供关于DataFrame的简明摘要信息,其中包括每列的非空值数量。
通过比较非空值数量和数据集总行数,可以快速识别出缺失值的存在。
示例代码:
# 查看DataFrame的摘要信息
data.info()
三 总结
:
数据清洗中的缺失值处理是构建可靠机器学习模型的关键步骤。通过深入了解缺失值的概念及其危害,以及采用可视化检查、统计描述和编程检查等方法,我们能够全面地识别数据中的缺失点。这为后续的数据填充、插补或删除等操作奠定了基础,确保数据的完整性和可靠性,从而提高模型的准确性和鲁棒性。在实际应用中,仔细识别缺失点将为我们构建更加健壮和可信赖的机器学习模型提供重要支持。
这篇文章到这里就结束了
谢谢大家的阅读!
如果觉得这篇博客对你有用的话,别忘记三连哦。
我是甜美的江,让我们我们下次再见