目标检测是CV中的重要场景。
在图像中定位感兴趣的目标,准确判断每个目标的类别,并给出每个目标的边界框。
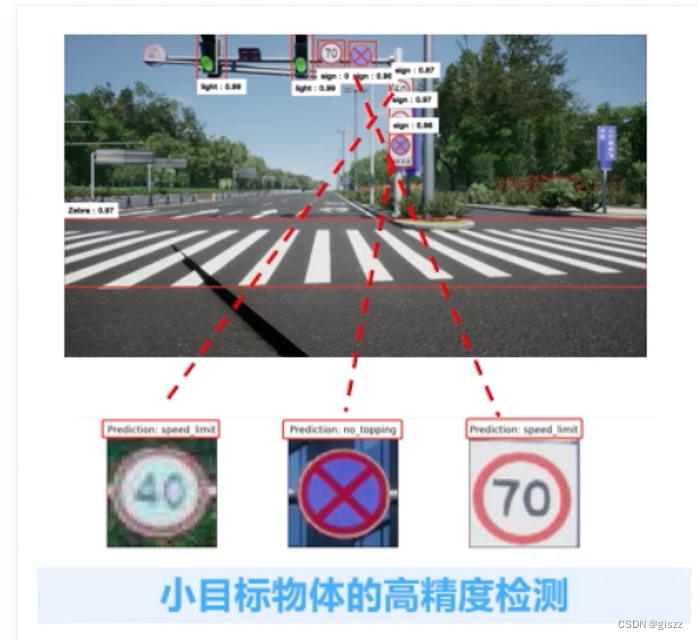
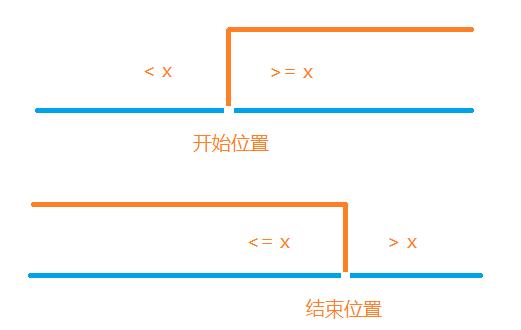
上图是目标检测的典型应用案例。
目标检测的难点是小目标的高精度检测。
目前主要的应用领域是机器人导航、自动驾驶、智能视频监督、工业检测、人脸识别等。
目标检测(Object Detection)在计算机视觉(CV)中的深入剖析
一、定义
目标检测是计算机视觉领域中的一个核心任务,旨在让计算机能够自动识别和定位图像或视频中的目标对象。不同于图像分类任务只需识别出图像的整体类别,目标检测需要更精细地处理图像,确定目标对象的具体位置和范围,通常用边界框(bounding box)来标示。
二、关键技术
目标检测的关键技术主要包括特征提取、区域提议、分类与定位以及后处理。
-
特征提取:传统的目标检测方法依赖于手工设计的特征,如SIFT、HOG等。然而,随着深度学习的发展,卷积神经网络(CNN)已成为特征提取的主流方法。CNN能够自动学习图像中的层次化特征,为后续的分类和定位提供丰富的信息。
-
区域提议:区域提议算法负责在图像中生成可能包含目标的候选区域。传统的区域提议方法如Selective Search计算量大且速度慢。近年来,基于深度学习的区域提议网络(RPN)在速度和准确性上都有了显著提升,RPN与后续的分类网络共享卷积层,大大提高了检测效率。
-
分类与定位:在得到候选区域后,需要对这些区域进行分类和精确定位。这通常通过一个分类器(如SVM、Softmax等)和一个回归器(用于调整边界框的位置和大小)来实现。在深度学习方法中,这些步骤通常被整合到一个端到端的网络中,如Faster R-CNN、YOLO、SSD等。
-
后处理:后处理包括非极大值抑制(NMS)等步骤,用于去除重叠的边界框,确保每个目标只被检测一次。
三、应用场景
目标检测的应用场景非常广泛,几乎涵盖了所有需要自动识别和定位图像中目标的领域。以下是一些主要的应用场景:
-
自动驾驶:在自动驾驶系统中,目标检测用于识别和定位车辆、行人、交通标志等关键目标,以确保安全驾驶。
-
安防监控:在安防领域,目标检测可以实时检测监控视频中的异常事件,如入侵者、火灾等。
-
智能零售:在零售场景中,目标检测可用于商品识别、库存管理和顾客行为分析。
-
医学诊断:在医学图像分析中,目标检测可以帮助医生自动识别和定位病变区域,如肺结节、肿瘤等。
-
人脸识别与身份验证:在人脸识别系统中,目标检测用于准确定位人脸区域,为后续的人脸识别提供基础。
-
野生动物保护:在生态学和野生动物保护领域,目标检测可用于自动识别和跟踪野生动物。
四、具体实现方法的种类
目标检测的实现方法主要可以分为两大类:两阶段方法和一阶段方法。
-
两阶段方法:以R-CNN系列为代表,首先通过区域提议网络(RPN)生成候选区域,然后对这些区域进行分类和精确定位。这类方法准确率高但速度相对较慢。典型代表有R-CNN、Fast R-CNN、Faster R-CNN等。
-
一阶段方法:以YOLO和SSD为代表,这类方法将区域提议和分类定位整合到一个网络中,直接输出边界框和类别概率。这类方法速度较快但准确率可能略低于两阶段方法。YOLO通过划分网格并在每个网格上预测固定数量的边界框来实现目标检测;SSD则结合了YOLO的回归思想和Faster R-CNN的锚点机制,在多尺度特征图上进行预测。
五、开源或商业化比较好的相关产品
-
OpenCV:OpenCV是一个开源的计算机视觉库,提供了丰富的图像处理和目标检测算法。它支持多种编程语言,包括Python和C++,是研究和开发目标检测系统的常用工具。
-
TensorFlow Object Detection API:TensorFlow是谷歌开源的深度学习框架,其Object Detection API提供了预训练的目标检测模型和易于使用的接口,方便开发者快速构建和部署目标检测系统。
-
Detectron2:Detectron2是Facebook开源的目标检测框架,基于PyTorch实现。它提供了丰富的预训练模型和灵活的配置选项,支持多种目标检测算法。
-
Amazon Rekognition:Amazon Rekognition是亚马逊提供的商业化图像和视频分析服务,包括目标检测、人脸识别、文本识别等功能。它提供了易于使用的API和可扩展的云服务,适用于各种应用场景。
-
Google Cloud Vision:Google Cloud Vision是谷歌提供的云端图像分析服务,包括目标检测、图像分类、文本识别等功能。它基于谷歌强大的图像识别技术,提供了高度准确和可靠的分析结果。
六、应用比较多的领域
除了之前提到的自动驾驶、安防监控、智能零售和医学诊断等领域外,目标检测在以下领域也有广泛的应用:
-
智能家居:在智能家居系统中,目标检测可以用于识别家庭成员的行为和姿态,实现智能灯光控制、智能安防等功能。
-
航空航天:在航空航天领域,目标检测可用于卫星图像中的目标识别和跟踪,如军事目标、自然灾害监测等。
-
农业智能化:在农业领域,目标检测可以帮助实现自动化种植、病虫害识别和作物产量估计等功能。
-
体育竞技分析:在体育领域,目标检测可用于实时跟踪和分析运动员的动作和轨迹,为训练和比赛提供数据支持。
七、核心算法的Python代码片段示例(以YOLOv3为例)
YOLOv3是一种流行的目标检测算法,以下是一个简化的YOLOv3模型加载和推理的Python代码片段示例:
import torch
from torchvision.models.detection import yolov3_resnet50_fpn
from PIL import Image
import torchvision.transforms as T
# 加载预训练的YOLOv3模型
model = yolov3_resnet50_fpn(pretrained=True)
model = model.eval() # 设置为评估模式
# 图像预处理
def preprocess_image(image_path):
image = Image.open(image_path).convert('RGB')
transform = T.Compose([
T.Resize((800, 800)), # YOLOv3通常需要固定大小的输入
T.ToTensor(), # 将PIL图像转换为PyTorch张量
])
image_tensor = transform(image).unsqueeze(0) # 添加批次维度
return image_tensor
# 目标检测推理
def detect_objects(image_path):
image_tensor = preprocess_image(image_path)
with torch.no_grad():
predictions = model(image_tensor) # 进行推理
return predictions
# 假设我们有一个名为"example.jpg"的图像文件
image_path = "example.jpg"
predictions = detect_objects(image_path)
# 处理预测结果(这里只是打印出来,实际应用中可能需要绘制边界框等)
for i in range(predictions[0]['labels'].size(0)):
label = predictions[0]['labels'][i].item()
score = predictions[0]['scores'][i].item()
bbox = predictions[0]['boxes'][i].tolist()
print(f"Detected object {label} with confidence {score} at bbox {bbox}")
# 注意:上述代码片段是一个简化的示例,实际应用中还需要处理不同大小的输入图像、非极大值抑制(NMS)等步骤。
# 此外,YOLOv3的输出通常包括边界框坐标、类别标签和置信度得分。这里只是简单地打印了这些信息。请注意,上述代码片段是一个高度简化的示例,仅用于说明如何使用预训练的YOLOv3模型进行目标检测。在实际应用中,还需要考虑更多的细节和优化,如调整模型参数、处理不同尺寸的输入图像、后处理步骤(如非极大值抑制)、以及将检测结果可视化等。此外,对于特定的应用场景和数据集,可能还需要对模型进行微调或重新训练以获得更好的性能。


![[设计模式Java实现附plantuml源码~行为型]请求的链式处理——职责链模式](https://img-blog.csdnimg.cn/direct/699aac3ed0c446d088772a0ed4c444ed.png)