作者 | Sunnyyyyy
整理 | NewBeeNLP
https://zhuanlan.zhihu.com/p/668698204
后台留言『交流』,加入 NewBee讨论组
LLaMA 是Meta在2023年2月发布的一系列从 7B到 65B 参数的基础语言模型。LLaMA作为第一个向学术界开源的模型,在大模型爆发的时代具有标志性的意义。
为了更深入地理解LLaMA的技术特点,特地在此整理了LLaMA 1 模型架构、预训练、部署优化特点。话不多说,我们仔细看看吧。

LLaMA简介
论文:https://arxiv.org/abs/2302.13971
Github:https://github.com/facebookresearch/llama
Meta 训练这些模型使用了数万亿个 token,并且 证明了完全可以只使用公开可得的数据集来训练最先进的模型,而无需使用专有和不可获取的数据集 。特别是,LLaMA-13B 在大多数基准测试中表现优于GPT-3(175B),而 LLaMA-65B 在竞争中与最佳模型 Chinchilla70B 和PaLM-540B 持平。
Meta在训练这些模型时,也同时考虑到了模型在推理部署时的性能和要求 - 在大规模提供语言模型时,推理速度和推理性能变得至关重要。因此, LLaMA选择用更小的模型,以及更多的数据集来进行预训练。
(Hoffmann等人的最新工作显示, 在给定的计算预算下,最佳性能并不是由最大的模型实现的,而是由更多数据训练的较小模型实现的 。
在这种情况下,考虑到推理运算以及目标性能水平, 首选模型不是训练速度最快的,而是推理速度最快的 。虽然训练一个大型模型达到一定性能水平可能更便宜,但训练时间更长的较小模型在推理阶段最终会更经济。例如,虽然Hoffmann等人建议在 200B 标记上训练 10B 模型,但 Meta 发现 7B 模型的性能在 1T token 后仍在持续提高。)
具体方法
预训练数据
LLaMA的预训练数据大约包含1.4T个token。其训练数据集是几个来源的混合,涵盖了不同的领域。
表1所示是 LLaMa 预训练数据的含量和分布:
表1:训练数据组成
| 数据集 | 样本比例 | Epochs | 所占磁盘大小 |
| CommonCrawl | 67.0% | 1.10 | 3.3 TB |
| C4 | 15.0% | 1.06 | 783 GB |
| Github | 4.5% | 0.64 | 328 GB |
| Wikipedia | 4.5% | 2.45 | 83 GB |
| Books | 4.5% | 2.23 | 85 GB |
| ArXiv | 2.5% | 1.06 | 92 GB |
| StackExchange | 2.0% | 1.03 | 78 GB |
1. English CommonCrawl [67%]
对五个 CommonCrawl 数据集进行预处理,时间跨度从2017年到2020年,使用 CCNet 来进行文本数据的预处理。
该过程先进行文本内容分片,然后进行段落归一化,并在此基础上在行级别进行数据去重;使用 fastText 线性分类器进行语言识别,以删除非英语页面;使用 n-gram 语言模型过滤低质量内容。
此外,还训练了一个线性模型,用于将页面分类为 Wikipedia 中的引用页面与随机抽样页面,并丢弃未被分类为引用的页面。(CCNet可参考LLM Data Pipelines: 解析大语言模型训练数据集处理的复杂流程 - 掘金[1])
2. C4 [15%]
C4也是属于Common Crawl数据集的一个经过粗略预处理的子集。在探索性实验中,研究团队观察到使用不同的预处理CommonCrawl数据集可以提高性能。因此,在数据中包含了公开可用的C4数据集。对于C4的预处理与 CCNet 的主要区别在于质量过滤,对于C4的预处理主要依赖于标点符号的存在或网页中的词语和句子数量等启发式方法。
3. Github [4.5%]
使用 Google BigQuery 上可用的公共 GitHub 数据集。此外,使用基于行长度或字母数字字符比例的启发式方法过滤低质量文件,并使用正则表达式删除了诸如header之类的内容。最后,对生成的数据集进行了文件级别的去重,使用完全匹配的方法。
4. Wikipedia [4.5%]
添加了截至2022年6月至8月的 Wikipedia 数据,涵盖20种语言。预处理包括:去除超链接、评论和其他格式样板。
5. Gutenberg and Books3 [4.5%]
添加了两个书籍类的数据集,分别是 Gutenberg 以及 ThePile (训练 LLM 的常用公开数据集) 中的 Book3 部分。预处理包括重复数据删除,删除内容重叠超过 90% 的书籍。
6. ArXiv [2.5%]
处理了arXiv Latex文件,以添加学术文本到数据集中。预处理包括:移除第一节之前的所有内容,以及参考文献;移除了.tex文件中的注释,并且内联展开了用户编写的定义和宏,以增加论文之间的一致性。
7. Stack Exchange [2%]
这是一个涵盖各种领域的高质量问题和答案网站,范围从计算机科学到化学(类似知乎)。研究团队从 28 个最大的网站保留数据,从文本中删除 HTML 标签并按分数对答案进行排序。
笔者NOTE:对于LLM的训练,数据的质量是基础。对于这部分感兴趣的小伙伴,可以仔细看下LLaMA训练时对于不同数据集的处理方式。
Tokenizer
使用字节对编码(BPE)算法对数据进行分词,使用 SentencePiece 的实现。值得注意的是,作者 将所有数字分割成单个数字 。
对于BPE的详细解释,可参考BPE 算法原理及使用指南【深入浅出】 \- 知乎[2]
模型架构
LLaMa 的网络还是主要基于 Transformer 架构。研究团队根据不同模型(如PaLM)的改进,从而利用了这些改进,来进一步提高LLaMA的训练稳定性、上下文长度性能。
以下是与原始架构的主要区别,以及从哪里得到了这种变化的灵感(括号中)。
Pre-normalization [受 GPT3 的启发] :为了提高训练稳定性,LLaMa 对每个 Transformer 子层的输入进行归一化,而不是对输出进行归一化。LLaMa 使用了 RMSNorm 归一化函数。
(关于Pre-norm vs Post-norm,可参考为什么Pre Norm的效果不如Post Norm?\- 科学空间|Scientific Spaces[3])
2. SwiGLU 激活函数 [受 PaLM 的启发]: LLaMa 使用 SwiGLU 激活函数替换 ReLU 以提高性能,维度从 4d
变为 。SwiGLU是一种激活函数,它是GLU的一种变体, 它可以提高transformer模型的性能。SwiGLU的优点是它可以动态地调整信息流的门控程度,根据输入的不同而变化,而且SwiGLU比ReLU更平滑,可以带来更好的优化和更快的收敛。
(关于SwiGLU激活函数,可参考激活函数总结(八):基于Gate mechanism机制的激活函数补充\(GLU、SwiGLU、GTU、Bilinear、ReGLU、GEGLU\)\_glu激活-CSDN博客[4])
3. Rotary Embeddings [受 GPTNeo 的启发]: LLaMa 没有使用之前的绝对位置编码,而是使用了旋转位置编码(RoPE),可以提升模型的外推性。它的基本思想是通过一个旋转矩阵来调整每个单词或标记的嵌入向量,使得它们的内积只与它们的相对位置有关。旋转嵌入不需要预先定义或学习位置嵌入向量,而是在网络的每一层动态地添加位置信息。旋转嵌入有一些优点,比如可以处理任意长度的序列,可以提高模型的泛化能力,可以减少计算量,可以适用于线性Attention等。
(关于 RoPE 的具体细节,可参考十分钟读懂旋转编码(RoPE) \- 知乎[5])
笔者NOTE:LLM的架构是实现LLM基础性能的基石,对于这部分,各位小伙伴还是需要深入地了解一下各种架构的原理,以及其优劣势。
优化器
LLaMA使用了AdamW优化器进行训练,优化器的超参数为 =0.9, =0.95
(关于AdamW这个大模型训练的优化器,可参考当前训练神经网络最快的方式:AdamW优化算法+超级收敛 | 机器之心[6])
下表为LLaMA不同参数大小模型的具体设置:
表2: LLaMA不同参数大小模型的具体设置
| 参数 | 维度(dim) | head个数 | layer层数 | 学习率 | batch size | token数量 |
| 6.7B | 4096 | 32 | 32 | 3.0e−4 | 4M | 1.0T |
| 13.0B | 5120 | 40 | 40 | 3.0e−4 | 4M | 1.0T |
| 32.5B | 6656 | 52 | 60 | 1.5e−4 | 4M | 1.4T |
| 65.2B | 8192 | 64 | 80 | 1.5e−4 | 4M | 1.4T |
训练结果
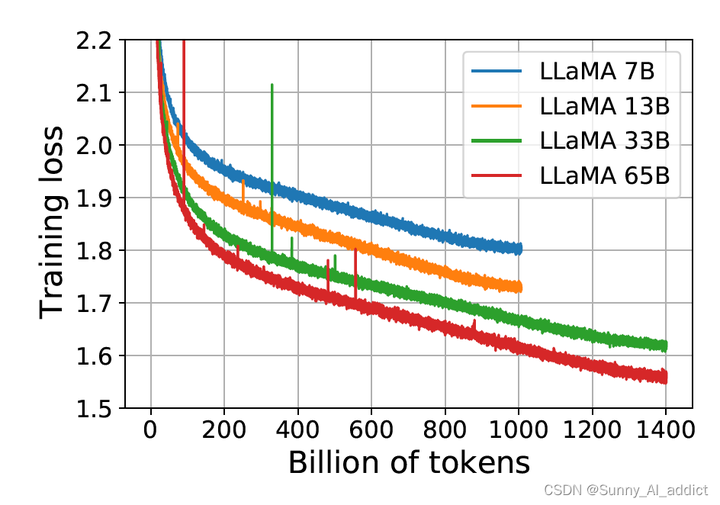
如下图所示,7B、13B、33B和65模型的训练损失均呈下降趋势,且在所有token上训练完后,loss仍没有收敛的趋势。因此,在此时,增加训练的token数量,仍然可以使模型继续学习。
(LLaMA2就是在此结论的基础上,使用了更多的token进行训练)
高效部署
研究团队做了一些优化来提高模型的训练速度:
因果多头注意的有效实现:使用因果多头注意的有效实现来减少内存使用和运行时间。该实现可在xformers库中获得,其灵感来自于固定激活值显存优化和FlashAttention。这是通过不存储注意力权重和不计算由于语言建模任务的因果性质而被掩盖的key/query分数来实现的。
激活重计算:为了进一步提高训练效率,通过检查点减少了在向后传递过程中重新计算的激活量。更准确地说,节省了计算成本高的激活,比如线性层的输出。这是通过手动实现transformer层的backward函数来实现的,而不是依赖于PyTorch的autograd。
模型并行和序列并行:为了从这种优化中充分受益,需要通过使用模型和序列并行来减少模型的内存使用。此外,还尽可能地重叠激活的计算和gpu之间通过网络的通信。
笔者NOTE:LLM的高效训练是LLM工程实现的基础,对于这部分,各位小伙伴还是需要深入地了解一下各种并行策略、因果多头注意的有效实现、 激活重计算、混合精度训练。
基于LLaMA的衍生模型(概述)
笔者NOTE:由于篇幅太长,因此在这篇里仅进行基于LLaMA的衍生模型的概述,之后也会出详细介绍各个衍生模型的文章
Alpaca
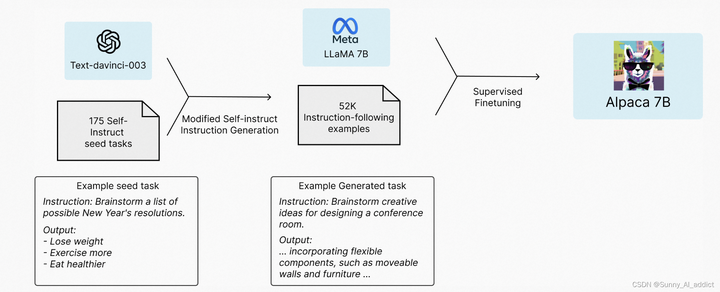
Alpaca是斯坦福在LLaMa-7B的基础上监督微调出来的模型,斯坦福是用OpenAI的Text-davinci-003 API配合self-instruct技术,使用175个提示语种子自动生成了52K条提示-回复的指示数据集,在LLaMa-7B上微调得到的模型,在8张80G的A100上训练了3小时。
可以说是以极低的成本生成了高质量的指令数据,并进行了指令微调,最终可以达到媲美GPT3.5的水平。
Vicuna
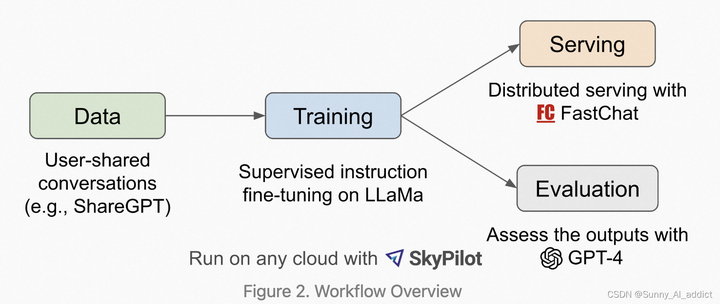
Vicuna是在LLaMa-13B的基础上使用监督数据微调得到的模型,数据集来自于http://ShareGPT.com[7] 产生的用户对话数据,共70K条。使用Pytorch FSDP在8张A100上训练了一天。相较于Alpaca,Vicuna在训练中将序列长度由512扩展到了2048,并且通过梯度检测和flash attention来解决内存问题;调整训练损失考虑多轮对话,并仅根据模型的输出进行微调。通过GPT4来打分评测,Vicuna可以达到ChatGPT 90%的效果。并且还提供了可调用的分布式聊天服务FastChat[8]。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

本文参考资料
[1]
LLM Data Pipelines: 解析大语言模型训练数据集处理的复杂流程 - 掘金: https://juejin.cn/post/7259385807550087226
[2]BPE 算法原理及使用指南【深入浅出】 - 知乎: https://zhuanlan.zhihu.com/p/448147465
[3]为什么Pre Norm的效果不如Post Norm?- 科学空间|Scientific Spaces: https://kexue.fm/archives/9009
[4]激活函数总结(八):基于Gate mechanism机制的激活函数补充(GLU、SwiGLU、GTU、Bilinear、ReGLU、GEGLU)_glu激活-CSDN博客: https://blog.csdn.net/qq_36758270/article/details/132174106
[5]十分钟读懂旋转编码(RoPE) - 知乎: https://zhuanlan.zhihu.com/p/647109286
[6]当前训练神经网络最快的方式:AdamW优化算法+超级收敛 | 机器之心: https://www.jiqizhixin.com/articles/2018-07-03-14
[7]http://ShareGPT.com: https://ShareGPT.com
[8]FastChat: https://github.com/lm-sys/FastChat
[9]LLaMa-1 技术详解 - 知乎: https://zhuanlan.zhihu.com/p/648774481
[10]LLaMA及其子孙模型概述 - 掘金: https://juejin.cn/post/7220985690795851836
[11]https://www.cnblogs.com/jiangxinyang/p/17310398.html: https://www.cnblogs.com/jiangxinyang/p/17310398.html