Java 排序
1 Collection 排序
Collections类中的:
- sort方法可以对List对象进行排序,该方法使用自然排序,即根据元素的自然顺序进行排序。
- 如果需要对自定义对象进行排序,需要实现Comparable接口并重写compareTo方法。
- Collections类还提供了一些静态方法,如reverse和shuffle,可以对集合进行反转和随机排序。
import java.util.Arrays;
import java.util.List;
import java.util.Collections;
public class SortListExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5);
// 使用 sort 方法对 List 进行排序
numbers.sort(null); // 默认按照自然顺序排序
System.out.println("Sorted list: " + numbers); // 输出: [1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
// 使用自定义的 Comparator 对 List 进行排序
numbers.sort(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1; // 降序排序
}
});
System.out.println("Custom sorted list: " + numbers); // 输出: [9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1]
}
}
2 Object[] 数据排序
import java.util.Arrays;
import java.util.Comparator;
public class SortExample {
public static void main(String[] args) {
String[] elementData = {"apple", "banana", "cherry", "date", "elderberry"};
int size = 3; // 只排序前三个元素
Arrays.sort(elementData, 0, size, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length() - o2.length(); // 按字符串长度排序
}
});
System.out.println(Arrays.toString(elementData)); // 输出排序后的数组 [apple, cherry, banana]
}
}
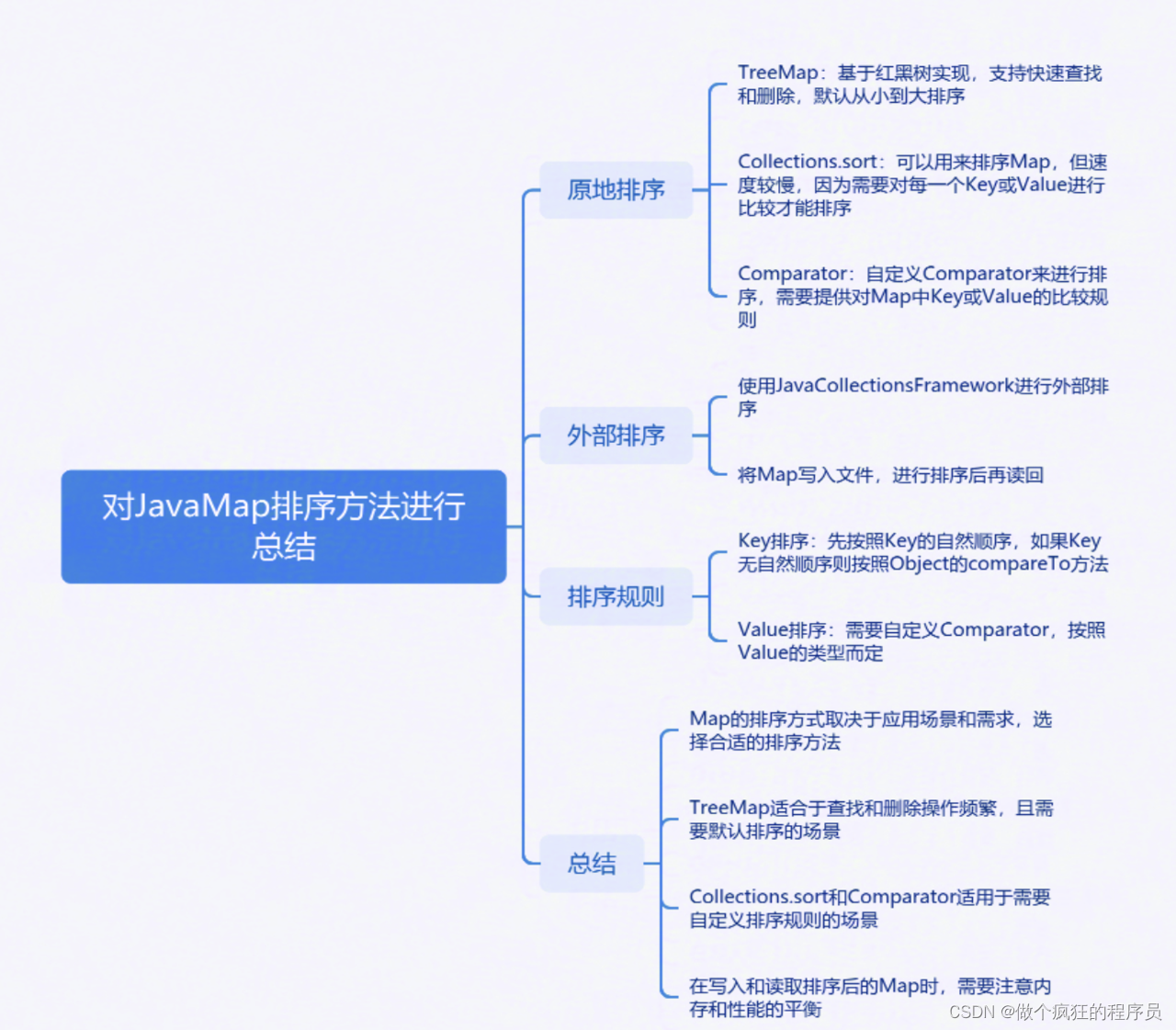
3 Map排序
Map 本身是一种无序的数据结构,因此排序操作通常需要在遍历或转换时进行。
3.1 TreeMap:TreeMap 默认按键(key)的自然顺序进行排序,也可以通过构造器传入自定义的 Comparator 来实现自定义排序。TreeMap 在插入、删除和查找元素时,都会按照键的顺序进行排序。
public static <K, V> Map<K, V> sortByKey(Map<K, V> unsortedMap) {
Map<K, V> sortedMap = new TreeMap<>(unsortedMap);
return sortedMap;
}
3.1.1 使用自定义的Comparator:TreeMap 允许通过提供一个自定义的 Comparator 来对键(key)进行排序。如果希望在 TreeMap 中按键的自定义顺序存储元素,可以在创建 TreeMap 实例时传递一个自定义的 Comparator。
import java.util.Comparator;
import java.util.TreeMap;
public class TreeMapExample {
public static void main(String[] args) {
// 创建一个自定义的 Comparator,用于 TreeMap 中的键排序
Comparator<String> customComparator = new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
// 按照字符串长度进行排序
return o1.length() - o2.length();
}
};
// 使用自定义的 Comparator 创建 TreeMap
TreeMap<String, Integer> treeMap = new TreeMap<>(customComparator);
// 向 TreeMap 中添加元素
treeMap.put("apple", 1);
treeMap.put("banana", 2);
treeMap.put("cherry", 3);
treeMap.put("date", 4);
// 遍历 TreeMap,输出排序后的键值对
for (Map.Entry<String, Integer> entry : treeMap.entrySet()) {
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}
}
}
3.1.2 TreeMap 根据值进行排序
TreeMap 本身并不直接支持根据值(value)进行排序,因为它的设计初衷是按键(key)的自然顺序或提供的 Comparator 进行键排序。如果需要根据值对 TreeMap 进行排序,可以采取以下步骤:
a. 将 TreeMap 转换为一个 List,其中包含键值对(Map.Entry)。
b. 使用 Collections.sort() 方法对这个列表进行排序,并提供一个自定义的比较器(Comparator),该比较器根据值进行比较。
c. 遍历排序后的列表,并根据需要重新构造一个 TreeMap 或其他数据结构。
import java.util.*;
public class TreeMapByValueExample {
public static void main(String[] args) {
// 创建一个 TreeMap
TreeMap<String, Integer> treeMap = new TreeMap<>();
treeMap.put("A", 10);
treeMap.put("B", 5);
treeMap.put("C", 15);
treeMap.put("D", 20);
// 将 TreeMap 转换为 List
List<Map.Entry<String, Integer>> list = new ArrayList<>(treeMap.entrySet());
// 根据值对 List 进行排序
list.sort(Map.Entry.comparingByValue());
// 创建一个新的 LinkedHashMap 来保持排序
Map<String, Integer> sortedMap = new LinkedHashMap<>();
for (Map.Entry<String, Integer> entry : list) {
sortedMap.put(entry.getKey(), entry.getValue());
}
// 输出排序后的 Map
for (Map.Entry<String, Integer> entry : sortedMap.entrySet()) {
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
}
}
}
3.2 LinkedHashMap:LinkedHashMap 是 HashMap 的一个子类,它维护了一个双向链表来记录元素的插入顺序。因此,在遍历 LinkedHashMap 时,元素的顺序就是它们被插入的顺序。虽然 LinkedHashMap 本身不直接提供排序功能,但可以通过在遍历时使用 Collections.sort() 方法对键值对进行排序。
3.3 转换为 List 进行排序:将 Map 的键值对转换为 List,然后对 List 进行排序。这种方法可以自定义排序规则,但需要手动实现比较器(Comparator)。排序完成后,可以再将排序后的 List 转换回 Map。
3.4 使用 Stream API 进行排序:Java 8 引入了 Stream API,可以方便地对集合进行各种操作,包括排序。可以通过将 Map 的键值对转换为 Stream,然后使用 sorted() 方法进行排序。排序完成后,可以再将 Stream 转换回 Map。
import java.util.*;
import java.util.stream.Collectors;
public class MapSortingWithStreamAPI {
public static void main(String[] args) {
// 创建一个 HashMap
Map<String, Integer> map = new HashMap<>();
map.put("A", 10);
map.put("B", 5);
map.put("C", 15);
map.put("D", 20);
// 使用 Stream API 对值进行排序,并收集到 LinkedHashMap 以保持排序
Map<String, Integer> sortedMap = map.entrySet().stream()
.sorted(Map.Entry.comparingByValue()) // 根据值排序
.collect(Collectors.toMap(
Map.Entry::getKey, // 键的映射函数
Map.Entry::getValue, // 值的映射函数
(oldValue, newValue) -> oldValue, // 当键冲突时的合并函数
LinkedHashMap::new // 使用 LinkedHashMap 保持插入顺序
));
// 输出排序后的 Map
sortedMap.forEach((key, value) -> System.out.println("Key = " + key + ", Value = " + value));
}
}
上述代码中:
a. 将Map转换为一个Stream,然后使用sorted()方法对Stream中的元素进行排序。排序的依据是Map.Entry的值。
b. 使用collect()方法和Collectors.toMap()收集器将排序后的Stream转换回Map。使用LinkedHashMap作为结果Map,因为LinkedHashMap会按照插入顺序保持元素的顺序。
c. 如果Map中有多个具有相同值的键,Collectors.toMap()的合并函数将决定保留哪个键。在上述代码中,选择了保留旧的键(oldValue)。
d. Stream API的并行处理能力,这种方法在处理大型数据集时可能比传统的排序方法更高效。是否使用并行流,也取决于具体的数据集和硬件环境。在使用并行流(parallelStream())时,需要注意线程安全问题以及并行处理可能带来的额外开销。
Map的多重排序
对Map进行多重排序(即根据多个条件进行排序),可以使用Stream API结合Comparator.thenComparing()。
import java.util.*;
import java.util.stream.Collectors;
public class MultiLevelMapSorting {
public static void main(String[] args) {
// 创建一个 HashMap
Map<String, Person> map = new HashMap<>();
map.put("A", new Person("Alice", 25));
map.put("B", new Person("Bob", 20));
map.put("C", new Person("Charlie", 30));
map.put("D", new Person("David", 25));
// 使用 Stream API 进行多重排序
List<Person> sortedList = map.entrySet().stream()
.map(Map.Entry::getValue) // 将 Map.Entry 转换为 Person 对象
.sorted(Comparator.comparing(Person::getLastName) // 首先按 lastName 排序
.thenComparing(Person::getFirstName) // 如果 lastName 相同,则按 firstName 排序
.thenComparingInt(Person::getAge)) // 如果 firstName 也相同,则按 age 排序
.collect(Collectors.toList()); // 收集到 List 中
// 如果你想要保持排序后的顺序,可以使用 LinkedHashMap
Map<String, Person> sortedMap = sortedList.stream()
.collect(Collectors.toMap(
person -> String.valueOf(sortedList.indexOf(person)), // 使用索引作为键
person -> person,
(oldValue, newValue) -> oldValue, // 如果键冲突,保留旧值
LinkedHashMap::new // 使用 LinkedHashMap 保持插入顺序
));
// 输出排序后的 Map
sortedMap.forEach((key, person) -> System.out.println("Name: " + person.getFirstName() + " " + person.getLastName() + ", Age: " + person.getAge()));
}
static class Person {
private String firstName;
private String lastName;
private int age;
public Person(String firstName, String lastName, int age) {
this.firstName = firstName;
this.lastName = lastName;
this.age = age;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
public int getAge() {
return age;
}
}
}
在上述代码中:
- 定义了一个Person类,它包含firstName、lastName和age三个属性。通过创建了一个Map,其中键是字符串,值是Person对象。然后,使用Stream API对Map中的Person对象进行多重排序:首先按lastName排序,然后按firstName排序,最后按age排序。排序后的结果收集到一个List中。
- 为了保持排序后的顺序,我们将排序后的List转换回Map,其中键是List中元素的索引,值是原始的Person对象,使用LinkedHashMap来确保插入顺序与排序顺序一致。
- 上述代码中的排序是稳定的,即对于具有相同排序值的元素,它们在排序后的集合中的相对顺序与排序前的相对顺序相同。这是通过Collectors.toMap()的合并函数实现的,该函数保留了旧的值(即先遇到的元素)。
- 对于更复杂的排序场景,可以继续链式调用thenComparing()方法,添加更多的排序条件。


![[设计模式Java实现附plantuml源码~行为型]请求的链式处理——职责链模式](https://img-blog.csdnimg.cn/direct/699aac3ed0c446d088772a0ed4c444ed.png)