项目介绍:
- 使用的数据为采集车辆信号。车辆信息非常多,而且用户路况信息和使用偏好千人千面,很难找到一种准确识别碰撞的方法,希望参赛者通过车联网大数据识别车辆碰撞和碰撞时间。车辆标签信息如下:
| 车号 | Label | CollectTime |
|---|---|---|
| 1 | 1 | 2020/8/30 21:36:09 |
| 2 | 0 | |
| 3 | 1 | 2020/8/12 8:36:46 |
数据集:
https://download.csdn.net/download/qq_38735017/87064869
-
运行环境:
joblib=1.0.1 lightgbm=3.2.0 numpy=1.20.2 pandas=1.2.3 scikit-learn=0.24.1 tqdm=4.60.0
1.原始数据时间缺失值多,存在一定的异常值
2.原始数据特征间的相关性强,原始数据特征与碰撞标签的相关性弱
3.数据严重不均衡
4.精准碰撞时刻的预测存在困难
# 使用pip命令安装指定版本工具包,lightgbm版本对模型结果有影响
!pip install lightgbm==3.2.0 -i https://pypi.doubanio.com/simple/
# !pip install joblib==1.0.1 lightgbm==3.2.0 numpy==1.20.2 pandas==1.2.3 scikit-learn==0.24.1 tqdm==4.60.0import pandas as pd
import numpy as np
from joblib import Parallel,delayed
from tqdm.notebook import tqdm
import os
from lightgbm.sklearn import LGBMClassifier
from sklearn.model_selection import KFold,StratifiedKFold,StratifiedShuffleSplit
from sklearn.metrics import f1_score,precision_score,recall_score
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
import warnings
warnings.filterwarnings("ignore")
print('库导入成功')
库导入成功
# csv文件合并并行设置,请根据CPU支持核数设置,默认4核
jobs = 4
label_path = './datasets/data/train/train_labels.csv'
trn_path = './datasets/data/train'
test_path = './datasets/data/test'
result_path = './work/prediction_result'
if not os.path.exists(result_path): # 如果不存在则创建目录
os.makedirs(result_path) 训练集清洗
- 标签数据特点:
(1) 由于电动车电池具备防短路功能,车辆发生剧烈冲击时,安全气囊控制器会将信号发送给电池管理系统(BMS),BMS通过电池继电器断开高压,防止电池起火。发生碰撞时,电池主负继电器状态由连接变为断开;
(2) 绝大部分数据在碰撞瞬间,电池主负继电器状态处于断开状态;
(3) 发生碰撞时,车辆速度会发生明显的变化;
- 训练集异常标签清洗: 根据业务背景,可以发现训练集数据中部分标注碰撞的标签存在异常,不符合常识,对以下5台车标签进行修正。 |车号|修改原因| |-|-| |5|车辆传感器故障,碰撞前后时刻车速一直为0| |19|没有碰撞时间相关特征数据| |36|碰撞前后时刻继电器一直处于连接状态,车速为20.953km/h未发生变化| |77|碰撞标签附近车速一直为0,而前6分钟车辆继电器由连接到断开的时刻,3s内速度由58km/h变为0| |94|没有碰撞时间相关特征数据|
[33]
df_label = pd.read_csv(label_path)
# 车号5,19,36,94为异常数据,标签修正为0
df_label.loc[4,:] = (5,0,np.NaN)
df_label.loc[18,:] = (19,0,np.NaN)
df_label.loc[35,:] = (36,0,np.NaN)
df_label.loc[93,:] = (94,0,np.NaN)
# 车号77碰撞时间有问题,修正为13:37:12
df_label.loc[76,:] = (77,1,'2020/10/20 13:37:12')
# df_label.to_csv('./原始数据/train_labels_revised.csv',index=False)
df_label.head()[33]
碰撞状态预测模型
在碰撞状态预测模型中,先采用规则预测出发生强烈碰撞的车辆,再利用LightGBM模型对剩余车辆进行预测,该部分模型特征工程和采样有部分重合,因此下面主要介绍特征工程和采样的细节,规则预测模型细节见3.1.4,LightGBM模型细节见3.2.4:
- 特征工程
特征工程主要从状态信息和运动信息两个方面考虑,对于状态信息而言,最重要的是启停状态两个特征,当继电器由连接变为断开时,if_off逐步由-5变为-1,其余时刻均为0,当继电器由断开变为连接时,if_on逐步由-1变为-5,其余时刻均为0。在车辆运动信息中,主要构造了车辆的瞬时加速度,局部加速度,加速度统计几个特征,并对几个主要特征进行了分桶操作。这些新特征与碰撞标签具备较强的相关性,使得后续样本采样以及的模型构造更加容易。

规则预测模型
- 函数说明
csv_finds()函数批处理读csv文件位置,csvs存储了训练集文件下夹车号1-120的csv文件,csvs_test存储了测试集文件夹车号121-260的csv文件;
read_csv()函数对每个csv函数进行数据清洗和特征工程;
applyParallel_concat()函数合并所有清洗后的数据;
col_feature1()函数对数据进行欠采样,供规则预测模型使用;
col_feature2()函数对数据进行欠采样和特征工程,供LightGBM预测模型使用;
文件读取
[34]
def csv_find(parent_path, file_flag):
'''批处理读csv文件位置'''
df_paths = []
for root, dirs, files in os.walk(parent_path): # os.walk输出[目录路径,子文件夹,子文件]
for file in files:
if "".join(file).find(file_flag) != -1: # 判断是否csv文件(files是list格式,需要转成str)
df_paths.append(root + '/' + file) # 所有csv文件
return df_paths
csvs = csv_find(trn_path,file_flag='csv')
csvs_test = csv_find(test_path,file_flag='csv')
csvs.remove(label_path)特征工程
[35]
def read_csv(path):
del_cols = ['车辆行驶里程','驾驶员需求扭矩值']
# '车速'单独考虑
num_cols = [ '低压蓄电池电压','整车当前总电流','整车当前总电压']
'''数据处理'''
# 读取文件
df0 = pd.read_csv(path,index_col=False,low_memory=False)
# 删除缺失值
df = df0.dropna(axis=0,thresh=17)
df = df.rename(columns={'采集时间':'CollectTime'})
df['CollectTime'] = pd.to_datetime(df['CollectTime'],format='%Y-%m-%d %H:%M:%S')
# 去重
df.drop_duplicates(subset=['车号','CollectTime'],keep='first',inplace=True)
# 排序
df = df.sort_values('CollectTime').reset_index(drop=True)
# 删除无效特征
df = df.drop(del_cols,axis=1)
# 档位状态
df['整车当前档位状态'] = df['整车当前档位状态'].replace('驻车','空档')
# 电池包主负继电器状态
df['电池包主负继电器状态'] = df['电池包主负继电器状态'].replace('粘连','断开')
# 主驾驶座占用状态
df = df[df['主驾驶座占用状态'] != '传感器故障']
'''特征构造'''
df['time_delta'] = df['CollectTime'].diff().dt.total_seconds()
df['time_delta_5'] = (df['CollectTime']-df['CollectTime'].shift(5)).dt.total_seconds()
# 特征构造1: 判断数据是启动or停车——162 80(2020-12-02 13:04:13)
a = pd.DataFrame()
b = pd.DataFrame()
df['电池包主负继电器状态cate'] = df['电池包主负继电器状态'].astype('category').cat.codes
for i in np.arange(5):
a['电池状态'+str(i)] = df['电池包主负继电器状态cate']-df['电池包主负继电器状态cate'].shift(i+1)
b['电池状态'+str(i)] = df['电池包主负继电器状态cate']-df['电池包主负继电器状态cate'].shift(-i-1)
df['if_off'] = a.sum(axis=1)
df['if_on'] = b.sum(axis=1)
# 特征构造2: 车速特征
df['v_diff1'] = df['车速'].diff()/df['time_delta']#用于规则分类
df['v_diff2'] = -df['车速'].shift(3).rolling(window=3).mean()/df['time_delta_5']#用于规则分类(前5条数据的3条取平均)
df['v_diff3'] = df['车速'].diff() # 用于规则&LGBM
df['v_diff4'] = df['v_diff1'].shift(-1) # 用于时间预测
df['a_min5'] = df['v_diff1'].rolling(window=3).min() # 用于LGBM模型
df['a_mean5'] = df['v_diff1'].rolling(window=3).mean() # 用于LGBM模型
df['a_max3'] = df['v_diff1'].rolling(window=3).min() # 用于LGBM模型
df = df.iloc[5:,:]
# 删除时间戳太长的数据
df = df[df['time_delta_5']<90]
return df
def applyParallel_concat(paths, func, jobs=4):
ret = Parallel(n_jobs=jobs)(delayed(func)(csv)for csv in tqdm(paths))
return pd.concat(ret)
df_trnall = applyParallel_concat(csvs,read_csv,jobs=jobs)
print('df_trnall',df_trnall.shape)
df_testall = applyParallel_concat(csvs_test,read_csv,jobs=jobs)
print('df_testall',df_testall.shape)
# df_trnall.columnsHBox(children=(FloatProgress(value=0.0, max=120.0), HTML(value='')))
df_trnall (3928449, 29)
HBox(children=(FloatProgress(value=0.0, max=140.0), HTML(value='')))
df_testall (4285948, 29)
- 数据欠采样
根据业务知识,汽车碰撞后电池包主负继电器处于断开状态;其次,训练集的所有标签均分布在继电器断开瞬间附近,即if_off处于-3~-5的区间,考虑到可能的停车时被追尾,我们增加了车速>0的条件,同时增加了条件3,剔除启动阶段出现一部分正常低车速数据。(条件3在col_feature2函数中)

[36]
def col_feature1(df):
# 条件筛选数据
df = df [(df['电池包主负继电器状态cate']==0)] # 停车条件1
# 68的off_or_on==-3
df = df [(df['if_off']<-2) | (df['车速']!=0)] # 停车条件2
return df
df_trnall2 = col_feature1(df_trnall)
df_testall2 = col_feature1(df_testall)
print('trn',df_trnall2.shape)
print('test',df_testall2.shape)trn (9178, 29) test (10772, 29)
集成标签(重采样)
- 数据重采样
考虑到碰撞是一个连续过程,将碰撞时间前后5s时间均标记为碰撞,由此,训练集的碰撞标签由49变为了154个,提高了模型预测的泛化能力。

- 代码思路:依次读取训练集Label==1车号中的时间,增加其上下5s时间,并将其Label赋值为1,然后与训练数据进行合并。
[37]
# 对训练集标签进行重采样
df_label['CollectTime'] = pd.to_datetime(df_label['CollectTime'],format='%Y-%m-%d %H:%M:%S')
# 增加label数量
df_label_new = df_label
df_label1 = df_label[df_label['Label']==1]
for kind,kind_df in df_label1.groupby('车号'):
# 增加上下5s时间的Label
for t in np.arange(5):
new_row1 = pd.DataFrame({'车号': kind, 'Label':1,
'CollectTime': kind_df['CollectTime'].iloc[0] + pd.Timedelta(seconds=t+1)},index=[1])
new_row2 = pd.DataFrame({'车号': kind, 'Label':1,
'CollectTime': kind_df['CollectTime'].iloc[0] - pd.Timedelta(seconds=t+1)},index=[1])
df_label_new = df_label_new.append(new_row1, ignore_index=True)
df_label_new = df_label_new.append(new_row2, ignore_index=True)
# 将筛选过的训练数据和重采样的Label和并
df = pd.merge(df_trnall2,df_label_new, on=['车号', 'CollectTime'], how='left')
df['Label'] = df['Label'].fillna(0)
df1 = df[df['Label']==1]
print('标签1数据量',df1.shape)
print('标签1车辆数量',df1['车号'].nunique())标签1数据量 (154, 30) 标签1车辆数量 49
规则分类
从构造的几个速度相关的特征来看,发生强烈碰撞的标签是比较好区分的,因此首先利用规则模型预测发生强烈碰撞的车辆里考虑到模型的泛化能力将分隔阈值设的很大,以避免过拟合。
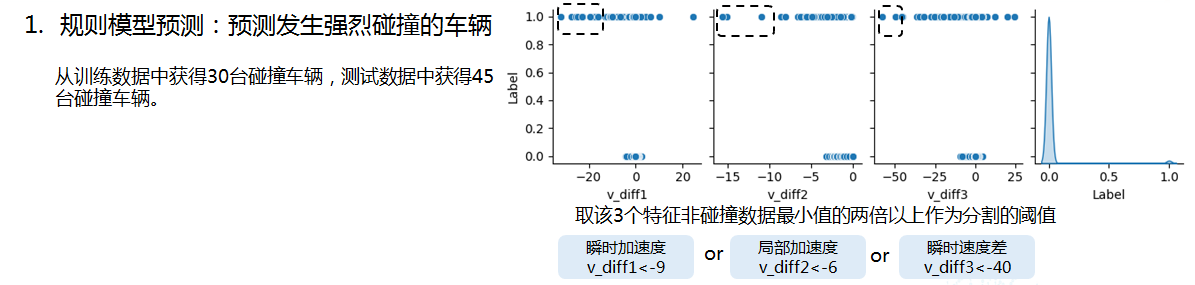
[38]
# 按车速差分类
feat = (df['v_diff1']<-9)|(df['v_diff2']<-6)|(df['v_diff3']<-40)
feat_test = (df_testall2['v_diff1']<-9)|(df_testall2['v_diff2']<-6)|(df_testall2['v_diff3']<-40)
print('trn规则分类车辆数:',df[feat]['车号'].nunique())
print('trn规则分类车辆:',df[feat]['车号'].sort_values().unique())
print('-'*100)
print('test规则分类车辆数:',df_testall2[feat_test]['车号'].nunique())
print('test规则分类车辆:',df_testall2[feat_test]['车号'].sort_values().unique())trn规则分类车辆数: 30 trn规则分类车辆: [ 1 3 12 15 17 35 38 41 44 47 50 56 58 61 62 64 65 68 69 74 76 77 85 98 105 110 112 113 119 120] ---------------------------------------------------------------------------------------------------- test规则分类车辆数: 45 test规则分类车辆: [132 133 135 138 140 147 150 152 154 158 161 163 164 168 170 172 175 176 186 187 193 197 201 202 205 206 207 209 210 212 213 222 223 227 230 231 233 235 244 249 252 253 254 255 260]
结果保存
- 代码思路:提取出训练集中和测试集中label==1的数据(
df_trn_label和df_testall2),按车号进行groupby()操作,取时间最早的数据作为结果,存储到sub_trn和sub_rule中
[39]
## 提取结果
df_trn_label = df[feat] # 预测的车号
sub_trn = pd.DataFrame(columns=['车号','Label_pred','CollectTime_pred'])
sub_trn = pd.merge(df_label,sub_trn,on=['车号'],how='left')
for kind,kind_df in df_trn_label.groupby('车号'):
sub_trn.loc[sub_trn[sub_trn['车号']==kind].index,'Label_pred'] = 1
sub_trn.loc[sub_trn[sub_trn['车号']==kind].index,'CollectTime_pred'] = kind_df['CollectTime'].iloc[0]
sub_trn['CollectTime_pred'] = pd.to_datetime(sub_trn['CollectTime_pred'],format='%Y-%m-%d %H:%M:%S')
print('trn预测最大时间差:',np.abs(sub_trn['CollectTime_pred']-sub_trn['CollectTime']).max())
#提取出还未预测的车辆
cols = ['车号','Label','CollectTime']
trn_for_pred = sub_trn[sub_trn['Label_pred']!=1][cols]
print('trn需预测数据:',trn_for_pred.shape)
# 提交结果
sub_rule = pd.DataFrame(columns=['车号','Label','CollectTime'])
sub_rule['车号'] = np.arange(121,261)
for kind,kind_df in df_testall2[feat_test].groupby('车号'):
sub_rule.loc[sub_rule[sub_rule['车号']==kind].index,'Label'] = 1
sub_rule.loc[sub_rule[sub_rule['车号']==kind].index,'CollectTime'] = kind_df['CollectTime'].iloc[0]
test_for_pred = sub_rule[sub_rule['Label']!=1][cols]
# trn_for_pred.to_csv('./train_label_for_pred.csv',index=False)
# test_for_pred.to_csv('./test_label_for_pred.csv',index=False)
# sub_rule.to_csv('./submit_rule.csv',index=False)trn预测最大时间差: 0 days 00:00:04 trn需预测数据: (90, 3)
LightGBM预测模型
文件读取
由于规则预测模型已经预测出了部分车号,因此LightGBM只需要预测trn_for_pred和test_for_pred中存储的剩余的车号
[40]
csvs_LGB = []
csvs_test_LGB = []
for i in trn_for_pred['车号']:
path = trn_path + '/' + str(i) + '.csv'
csvs_LGB.append(path)
for i in test_for_pred['车号']:
path = test_path + '/' + str(i)+'.csv'
csvs_test_LGB.append(path)
print('训练集csv数:',len(csvs_LGB))
print('测试集csv数:',len(csvs_test_LGB))训练集csv数: 90 测试集csv数: 95
[41]
df_trnall_LGB = applyParallel_concat(csvs_LGB,read_csv,jobs=jobs)
print('df_trnall',df_trnall_LGB.shape)
df_testall_LGB = applyParallel_concat(csvs_test_LGB,read_csv,jobs=jobs)
print('df_testall',df_testall_LGB.shape)
df_trnall_LGB.columnsHBox(children=(FloatProgress(value=0.0, max=90.0), HTML(value='')))
df_trnall (2923559, 29)
HBox(children=(FloatProgress(value=0.0, max=95.0), HTML(value='')))
df_testall (2954171, 29)
[41]
Index(['车号', 'CollectTime', '加速踏板位置', '电池包主负继电器状态', '电池包主正继电器状态', '制动踏板状态',
'驾驶员离开提示', '主驾驶座占用状态', '驾驶员安全带状态', '手刹状态', '整车钥匙状态', '低压蓄电池电压',
'整车当前档位状态', '整车当前总电流', '整车当前总电压', '车速', '方向盘转角', 'time_delta',
'time_delta_5', '电池包主负继电器状态cate', 'if_off', 'if_on', 'v_diff1',
'v_diff2', 'v_diff3', 'v_diff4', 'a_min5', 'a_mean5', 'a_max3'],
dtype='object')
特征工程
LightGBM模型中的特征和规则预测模型中略有不同,这里用col_feature2()函数进行特征工程。
[42]
def col_feature2(df):
cate_cols = ['制动踏板状态', '驾驶员离开提示','主驾驶座占用状态', '驾驶员安全带状态',
'手刹状态', '整车钥匙状态', '整车当前档位状态']
cate_cols2 = []
# 类别特征编码
for col in cate_cols:
df[col+'cate'] = df[col].astype('category').cat.codes
cate_cols2.append(col+'cate')
df_code_dict = {col:{code:cate for code,cate in enumerate(df[col].astype('category').cat.categories)}
for col in cate_cols}
df['整车钥匙状态catestd'] = df['整车钥匙状态cate'].rolling(window=5,center=True).std()
# 条件筛选数据
df = df [(df['电池包主负继电器状态cate']==0)] # 停车条件1
df = df [(df['if_on']==0) | (df['车速']>20)] # 停车条件2 判断是否启动阶段,或者车速过大的异常清空
df = df [(df['if_off']<-3) | (df['车速']!=0)] # 停车条件3 判断是否停车阶段,或者车速异常大于0的情况
# 车速分桶
bin1 = [-0.1,0.01,0.5,1.5,3,100]
df['v_bin'] = pd.cut(df['车速'], bin1, labels=False)
# 加速踏板特征
df['a0'] = df.apply(lambda x: 1 if (x['加速踏板位置']>0) else 0,axis=1)
df['a_min5'] = df['a_min5'] - df['v_bin']*df['v_bin']/2 - df['a0']*1.5
df['a_mean5'] = df['a_mean5'] - df['v_bin']*df['v_bin']/2 - df['a0']*1.5
# df['a_min5'] = df['a_min5'] - df['v_bin']*df['v_bin'] - df['a0']*3
# df['a_mean5'] = df['a_mean5'] - df['v_bin']*df['v_bin'] - df['a0']*3
df['v_diff1'] = df['v_diff1'] - df['v_bin']*df['v_bin'] - df['a0']*3
df['v_diff3'] = df['v_diff3'] - df['v_bin']*df['v_bin'] - df['a0']*3
# 加速度分桶
bin1 = [-100,-15,-10,-6,-3,-0.01,0.1,100]
df['v_diff3_bin'] = pd.cut(df['v_diff3'], bin1, labels=False)
ori_cols = ['加速踏板位置', '电池包主负继电器状态', '电池包主正继电器状态', '制动踏板状态',
'驾驶员离开提示', '主驾驶座占用状态', '驾驶员安全带状态', '手刹状态', '整车钥匙状态', '低压蓄电池电压',
'整车当前档位状态', '整车当前总电流', '整车当前总电压','车速', '方向盘转角']
cate_cols = ['电池包主负继电器状态cate','制动踏板状态cate', '驾驶员离开提示cate','主驾驶座占用状态cate',
'驾驶员安全带状态cate', '手刹状态cate', '整车钥匙状态cate','整车当前档位状态cate',]
choose_cols = ['time_delta', 'time_delta_5','if_on','a0','v_bin','v_diff3','v_diff2','v_diff4']
df = df.drop(ori_cols+cate_cols+choose_cols,axis=1)
return df,df_code_dict
df_trnall2_LGB , df_code_dict1= col_feature2(df_trnall_LGB)
print('trn',df_trnall2_LGB.shape)
df_testall2_LGB, df_code_dict2 = col_feature2(df_testall_LGB)
print('test',df_testall2_LGB.shape)
print(df_trnall2_LGB.columns)
# df_testall2_LGB.to_csv('./test_data.csv',encoding='GBK',index=False)
# df_code_dict1 == df_code_dict2
# df_code_dict1trn (4528, 9)
test (5100, 9)
Index(['车号', 'CollectTime', 'if_off', 'v_diff1', 'a_min5', 'a_mean5', 'a_max3',
'整车钥匙状态catestd', 'v_diff3_bin'],
dtype='object')
集成标签(重采样)
- 代码思路:由于规则预测模型中已经对生成了重采样标签
df_label_new,这里直接用pd.merge()函数进行合并即可
[43]
df_LGB = pd.merge(df_trnall2_LGB,df_label_new, on=['车号', 'CollectTime'], how='left')
df_LGB['Label'] = df_LGB['Label'].fillna(0)
df1_LGB = df_LGB[df_LGB['Label']==1]
print('训练数据label==1数量:',df1_LGB.shape)
print('训练数据label==1车数量:',df1_LGB['车号'].nunique())
# df.to_csv('./train_data.csv',encoding='GBK',index=False)
# df1.to_csv('./train_label_data.csv',encoding='GBK',index=False)训练数据label==1数量: (47, 10) 训练数据label==1车数量: 19
LGBM模型分类
为了增强树模型的预测能力,我们对原始的特征进行了交叉修正,修正后,这几个主要特征与label的相关性更为明显。通过分层抽样、调参获得了状态预测结果,由于重采样预测结果中同一辆车可能有多个邻近的预测时间,取最早的一个时间作为预测结果。

[44]
## 重命名
cols = {'车号':'Num','整车钥匙状态catestd':'key_std',}
df_LGB = df_LGB.rename(columns=cols)
df_test = df_testall2_LGB.rename(columns=cols)
# 训练数据的特征
f_names = [x for x in df_LGB.columns if x not in['Num','CollectTime','Label']]
test_data = df_test[f_names]
print('data',df_LGB.shape)
print('testdata',test_data.shape)
print(df_LGB.columns)data (4528, 10)
testdata (5100, 7)
Index(['Num', 'CollectTime', 'if_off', 'v_diff1', 'a_min5', 'a_mean5',
'a_max3', 'key_std', 'v_diff3_bin', 'Label'],
dtype='object')
- 代码思路:抽样方式按照车号的标签采用了分层抽样,即
split.split()函数中的抽样数据为trn_for_pred,trn_data和val_data是将根据trn_for_pred中抽样的车号数据获得,这样保证了按车数量抽样而不是标签数量。
[45]
split = StratifiedShuffleSplit(n_splits=1,test_size=0.3,random_state=2021)
# 按照label里的车号划分,再进入df中选择对应车号的行,保证trn和val的车号不相同
# 这个地方一定要加.values,并且注意别写错地方了
for trn_idx,val_idx in split.split(trn_for_pred['车号'],trn_for_pred['Label']):
trn_data = df_LGB[df_LGB['Num'].apply(lambda x: x in trn_for_pred.iloc[trn_idx]['车号'].values)].reset_index(drop=True)
val_data = df_LGB[df_LGB['Num'].apply(lambda x: x in trn_for_pred.iloc[val_idx]['车号'].values)].reset_index(drop=True)
trn_x, trn_y = trn_data[f_names], trn_data.loc[:,'Label']
val_x, val_y = val_data[f_names], val_data.loc[:,'Label']
print('trn Label',trn_data['Label'].value_counts())
print('val Label',val_data['Label'].value_counts())
print('trn车数量',trn_data['Num'].nunique())
print('val车数量',val_data['Num'].nunique())trn Label 0.0 3080 1.0 34 Name: Label, dtype: int64 val Label 0.0 1401 1.0 13 Name: Label, dtype: int64 trn车数量 63 val车数量 27
- 代码思路:调参用了贝叶斯优化,由于上分点主要在于数据清洗和特征工程,以及不均衡数据的处理,调参也不是重点,限于篇幅原因不展开了
[46]
# 调参val由0.83到0.93,线上0.85到0.925,对于不均衡样本colsample要尽可能小
model = LGBMClassifier(n_jobs=8,
n_estimators=30000,
objective='binary',
boosting_type='gbdt',
learning_rate=0.104962713,
subsample=0.9,
colsample_bytree=1,
is_unbalance=True,
# scale_pos_weight=30,
reg_lambda=0,
num_leaves=100,
random_state=2021)
model.fit(trn_x,trn_y,
eval_set=[(val_x,val_y)],
eval_metric='logloss',
early_stopping_rounds=2000,
verbose=3000)
# 预测
pred_val = model.predict(val_x)
pred_trn = model.predict(trn_x)
pred_test = model.predict(test_data)
#得分
f1_trn = f1_score(pred_trn,trn_y)
f1_val = f1_score(pred_val,val_y)
print('trn F1',f1_trn)
print('val F1',f1_val)Training until validation scores don't improve for 2000 rounds [3000] valid_0's binary_logloss: 0.000720162 Early stopping, best iteration is: [2028] valid_0's binary_logloss: 0.000716808 trn F1 1.0 val F1 0.962962962962963
结果保存
- 代码思路:和规则预测模型的思路一致,取时间最早的数据作为结果,测试集结果存储到和
sub中,然后将sub_rule和sub合并,得到总预测结果sub_all
[47]
df_test['label_pred'] = pred_test
df_test_sub = df_test[df_test['label_pred']==1]
sub = pd.DataFrame(columns=['车号','Label','CollectTime'])
sub['车号'] = np.arange(121,261)
for kind,kind_df in df_test_sub.groupby('Num'):
sub.loc[sub[sub['车号']==kind].index,'Label'] = 1
sub.loc[sub[sub['车号']==kind].index,'CollectTime'] = kind_df['CollectTime'].iloc[0]
print('submit_pred:',sub[sub['Label']==1].shape)
# sub.to_csv('./submit_pred.csv',index=False)#,encoding='GBK'submit_pred: (19, 3)
[48]
### 提交
# sub_all = pd.read_csv('./submit_rule.csv')
sub_all = sub_rule.copy()
a = sub[sub['Label']==1].index.values
sub_all.iloc[a] = sub[sub['Label']==1]
sub_all['Label'] = sub_all['Label'].fillna(0) #补0
sub_all['Label'] = sub_all['Label'].astype(int)#转int
# sub_all.to_csv('./submit_all.csv',index=False)
print('总提交正样本数:',sub_all[sub_all['Label']==1].shape[0])总提交正样本数: 64
碰撞时间预测模型
碰撞状态预测模型中,由于重采样以及构建的一些局部特征,时间预测并不准确,需要对状态预测模型结果中的时间进行修正。
可以看到绝大部分标签处于if_off=-5的时间点,因此首先将训练集标签中if_off=-5的时间标注为1,其他车辆标注为0,将时间预测转化为一个二分类模型。接下来构建时间预测的瞬时特征,采用可解释程度高并且简单的K近邻算法。获得结果后,将Time_label=0标签中的碰撞时间修正为当前时刻的下个时刻,得到了最终的结果。
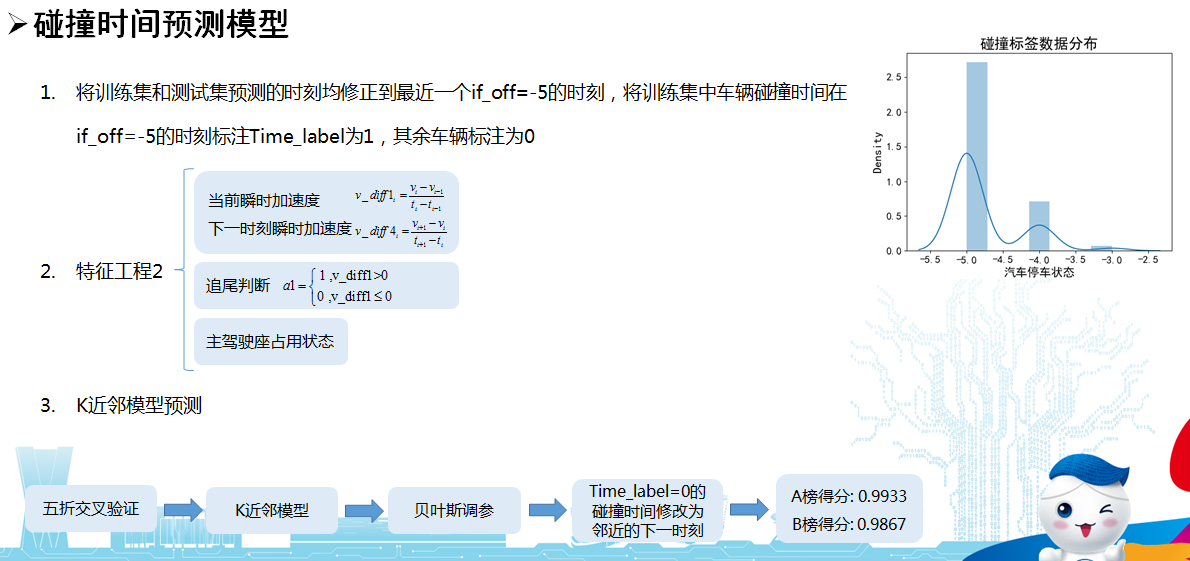
重采样
由于需要对训练集和测试集的预测结果进行修正,因此这里对预测结果进行了重采样(注意前面的重采样是对真实标签重采样,这里是对预测标签,二者不一样)
重采样后和特征数据合并,找到预测结果中附近的if_off==-5数据,对训练集标签进行修正
- 代码思路:对预测结果进行重采样,得到训练集重采样标签时间
time1,测试集重采样时间time1_test,然后和特征数据合并,取出if_off==-5的标签,
[49]
df_test_label = sub_all[sub_all['Label']==1]
df_test_label['CollectTime'] = pd.to_datetime(df_test_label['CollectTime'],format='%Y-%m-%d %H:%M:%S')[50]
def label_resample(df):
df_new = df[['车号','CollectTime']]
for kind,kind_df in df.groupby('车号'):
for t in np.arange(5):
new_row1 = pd.DataFrame({'车号': kind,
'CollectTime': kind_df['CollectTime'].iloc[0] + pd.Timedelta(seconds=t+1)},index=[1])
new_row2 = pd.DataFrame({'车号': kind,
'CollectTime': kind_df['CollectTime'].iloc[0] - pd.Timedelta(seconds=t+1)},index=[1])
df_new = df_new.append(new_row1, ignore_index=True)
df_new = df_new.append(new_row2, ignore_index=True)
return df_new
time1 = label_resample(df_label[df_label['Label']==1])
print('trn',time1.shape)
print('trn车数量:',df_label[df_label['Label']==1].shape)
time1_test = label_resample(df_test_label)
print('test',time1_test.shape)
print('test车数量:',df_test_label.shape)trn (539, 2) trn车数量: (49, 3) test (704, 2) test车数量: (64, 3)
[51]
# 找到预测结果中附近的if_off==-5数据
df_trnall2_time = df_trnall2[df_trnall2['if_off']==-5]
df_trn_time = pd.merge(df_trnall2_time,time1, on=['车号', 'CollectTime'], how='inner')
# 找到Trn中的TimeLabel: 'if_off'==-5时 Time_Label=1
df_trn_time = pd.merge(df_trn_time,df_label[df_label['Label']==1], on=['车号', 'CollectTime'], how='left')
df_trn_time['Label'] = df_trn_time['Label'].fillna(0)
print('Trn Label==1总数量:',df_trn_time.shape)
print('Trn车if_off==-5 的数量:',df_trn_time[df_trn_time['Label']==1].shape)
# Test一样
df_testall2_time = df_testall2[df_testall2['if_off']==-5]
df_test_time = pd.merge(df_testall2_time,time1_test, on=['车号', 'CollectTime'], how='inner')
print('Test Label==1总数量:',df_test_time.shape)Trn Label==1总数量: (49, 30) Trn车if_off==-5 的数量: (38, 30) Test Label==1总数量: (64, 29)
特征工程
由于碰撞时间受限于数据采集精度、传感器延迟、人为标注的影响,本身存在一定的随机误差,因此很难精确到1秒以内,
这里因此仅构造了当前瞬时加速度,下一时刻瞬时加速度,追尾判断,主驾驶座占用状态4个特征
[52]
def col_feature3(df):
cate_cols = ['主驾驶座占用状态']
# 类别特征编码
for col in cate_cols:
df[col+'cate'] = df[col].astype('category').cat.codes
df['a1'] = df['v_diff1'].apply(lambda x: 1 if x>0 else 0)
# df['a2'] = df['v_diff4'].apply(lambda x: 1 if x>0 else 0)
ori_cols = ['加速踏板位置', '电池包主负继电器状态', '电池包主正继电器状态', '制动踏板状态',
'驾驶员离开提示', '主驾驶座占用状态', '驾驶员安全带状态', '手刹状态', '整车钥匙状态', '低压蓄电池电压',
'整车当前档位状态', '整车当前总电流', '整车当前总电压','车速', '方向盘转角']
cate_cols = ['电池包主负继电器状态cate']
choose_cols = ['time_delta', 'time_delta_5','if_on','if_off','v_diff3','v_diff2', 'a_min5', 'a_mean5', 'a_max3']
df = df.drop(ori_cols+cate_cols+choose_cols,axis=1)
return df
df_trn_time2 = col_feature3(df_trn_time)
df_test_time2 = col_feature3(df_test_time)
print(df_trn_time2.columns)Index(['车号', 'CollectTime', 'v_diff1', 'v_diff4', 'Label', '主驾驶座占用状态cate',
'a1'],
dtype='object')
标准化
[53]
# 训练数据的特征
f_names2 = [x for x in df_trn_time2.columns if x not in['车号','CollectTime','Label']]
x_time_data = df_trn_time2[f_names2]
y_time_data = df_trn_time2['Label']
test_time_data = df_test_time2[f_names2]
print(test_time_data.columns)
std = StandardScaler()
x_time_data = std.fit_transform(x_time_data)
test_time_data = std.fit_transform(test_time_data)
print(x_time_data.shape,test_time_data.shape)Index(['v_diff1', 'v_diff4', '主驾驶座占用状态cate', 'a1'], dtype='object') (49, 4) (64, 4)
五折交叉验证
[54]
pred_test_Kfold = pd.DataFrame()
f1_trn,f1_val = [],[]
fold = StratifiedKFold(n_splits=5,shuffle=True,random_state=0)
for iteration ,(trn_idx,val_idx) in enumerate(fold.split(x_time_data,y_time_data)):
# print('------------{} fold -------------'.format(iteration))
x_trn_time,y_trn_time = x_time_data[trn_idx],y_time_data[trn_idx]
x_val_time,y_val_time = x_time_data[val_idx],y_time_data[val_idx]
knn = KNeighborsClassifier(n_neighbors=5,p=1,metric='minkowski')
knn.fit(x_trn_time,y_trn_time)
# 预测
pred_trn = knn.predict(x_trn_time)
pred_val = knn.predict(x_val_time)
pred_test_Kfold['label'+str(iteration)] = knn.predict(test_time_data)
#得分
f1_trn.append(f1_score(pred_trn,y_trn_time))
f1_val.append(f1_score(pred_val,y_val_time))
print('trn F1',f1_trn)
print('val F1',f1_val)
print('trn_F1mean',np.mean(f1_trn))
print('val_F1mean',np.mean(f1_val))trn F1 [0.8695652173913044, 0.8529411764705883, 0.8695652173913044, 0.8857142857142858, 0.8732394366197184] val F1 [0.888888888888889, 0.823529411764706, 0.888888888888889, 0.8235294117647058, 0.8750000000000001] trn_F1mean 0.8702050667174402 val_F1mean 0.859967320261438
[55]
pred_test_Kfold['Time_Pred'] = pred_test_Kfold.mean(axis=1)
pred_test_time = pred_test_Kfold['Time_Pred'].apply(lambda x: 1 if x>0.6 else 0)
df_test_time2['Time_Pred'] = pred_test_time
df_test_time2[df_test_time2['Time_Pred']==0][55]
结果提交
- 代码思路:将预测标签中
Time_Pred=0的数据找到,修正为if_off==-4的标签,作为最终结果提交
[56]
# 找到if_off==-4对应time
df_testall2_time_if_off4 = df_testall2[df_testall2['if_off']==-4]
df_test_time_if_off4 = pd.merge(df_testall2_time_if_off4,time1_test, on=['车号', 'CollectTime'], how='inner')
df_test_time_if_off4['Time_Pred'] = pred_test_time
df_test_time_if_off4.shape[56]
(64, 30)
[57]
Time1_test_sub = df_test_time2.loc[df_test_time2['Time_Pred']==1,['车号','CollectTime']]
Time2_test_sub = df_test_time_if_off4.loc[df_test_time_if_off4['Time_Pred']==0,['车号','CollectTime']]
Time_test_sub = pd.concat([Time1_test_sub,Time2_test_sub])
# 提交最终结果
sub_all_time = pd.merge(sub_all[['车号','Label']],Time_test_sub,on=['车号'], how='left')
sub_all_time.to_csv(result_path+'/result.csv',index=False)
print('Label1数量:',sub_all_time[sub_all_time['Label']==1].shape)
print('-------------------end-------------------')Label1数量: (64, 3) -------------------end-------------------