相信看过ClickHouse性能测试报告的同学都很震惊于他超高的OLAP查询性能。于是下一步开始搜索“ClickHouse性能为什么高”看到了例如:列存储、数据压缩、并行处理、向量化引擎 等等一些关键词,对于我们一般人来说,并没有解答心中的疑惑:ClickHouse性能为什么高? 于是想写几篇博文,用通俗、简单的实例和大家一起探讨一下这个问题,希望能通过博文和大家的探讨解答这个疑惑! 针对OLAP类的查询最简单的优化方式就是减少数据扫描范围,故而我们以此作为开篇。
问题: 有一个表(tab01)有10个int类型的字段(col1,col2,col3...col10),这个表中有十亿条数据。
[
{176, 35, 27, 82, 65, 75, 20, 25, 92, 35},
{322, 42, 33, 12, 82, 77, 65, 22, 98, 12},
...
]为了简单假定该表没有主键和索引,在本篇中也不考虑任何的数据压缩。
需要完成如下查询:
SELECT avg(col1),avg(col2) FROM tab01 WHERE col3 > 500方案一:行存储
如果该表以行存储的方式存储为一个文件:tab01.dat , 每条数据40字节,那么整个文件大小为40GB,完成上述问题的代码逻辑如下:
long cnt = 0;
long totalCol1 = 0;
long totalCol2 = 0;
for(iter = begin(); iter != end(); iter++)
{
if (iter[col3] > 500)
{
cnt++;
totalCol1 += iter[col1];
totalCol2 += iter[col2];
}
}
if (cnt > 0)
{
// totalCol1 / cnt;
// totalCnt2 / cnt;
}在这个方案中,我们需要从头到尾读取文件所有数据,也就是需要从磁盘读取40GB的内容。显然行存储方案对于处理这类问题来说并不高效。
方案二:列存储
如果我们将该表的数据以列存储,即:将所有数据存储为10个文件,col1.dat 存储col1列所有的10亿条数据,依此类推,我们得到了10个数据文件,每个数据文件存储十亿个数据,大小为4GB。 那么完成上面的查询,只需要读取col1.dat 、 col2.dat 、 col3.dat 三个文件,总共12GB。 读磁盘的大小仅为方案一的30%。 现在我们就通过减少数据扫描范围达到了提升性能的目的。这也是列存储广泛应用在OLAP场景中的原因。
方案三: 将数据分块
在列存储的基础上,如果按照8192条数据进行分块,比如:col1.dat 的前 8192条数据是数据块1,接下来8192条数据是数据块2。所有数据文件都是如此,数据的逻辑组织如下所示:
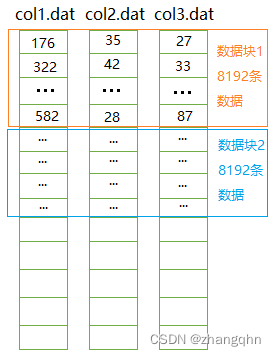
执行过程:以数据块为单位依次读取col3列的所有数据块,取得数据块中所有符合条件(col3 > 500)的数据下标。
-
如果在该数据块中有符合条件的数据,则从col1.dat和col2.dat中读取对应位置的数据块,并取出对应位置的数据。
-
如果在该数据块中没有符合条件的数据,则不需要读取col1.dat和col2.dat中对应位置的数据块。
在这个优化中,我们只需要读取col3.dat全部数据和部分或全部col1.dat和col2.dat的数据,数据扫描范围相比于上一个方案进一步缩小。 这也就是ClickHouse中PreWhere所作的优化。
方案四: 数据块索引
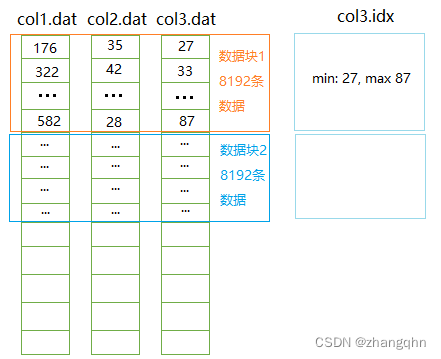
执行过程:首先读取col3数据块索引,判断该列存储的数据是否满足条件[27,87] 与 (500,) 是否有交集。
-
如果有交集则继续上一个方案的步骤。
-
如果没有交集则不需要读取任何数据块。
在这个优化中,需要读取col3.idx所有的数据,以及col1, col2, col3 的部分数据块。与上一个方案相比,扫描到的数据量进一步缩小。