YOLOv8-Segment C++
https://github.com/triple-Mu/YOLOv8-TensorRT

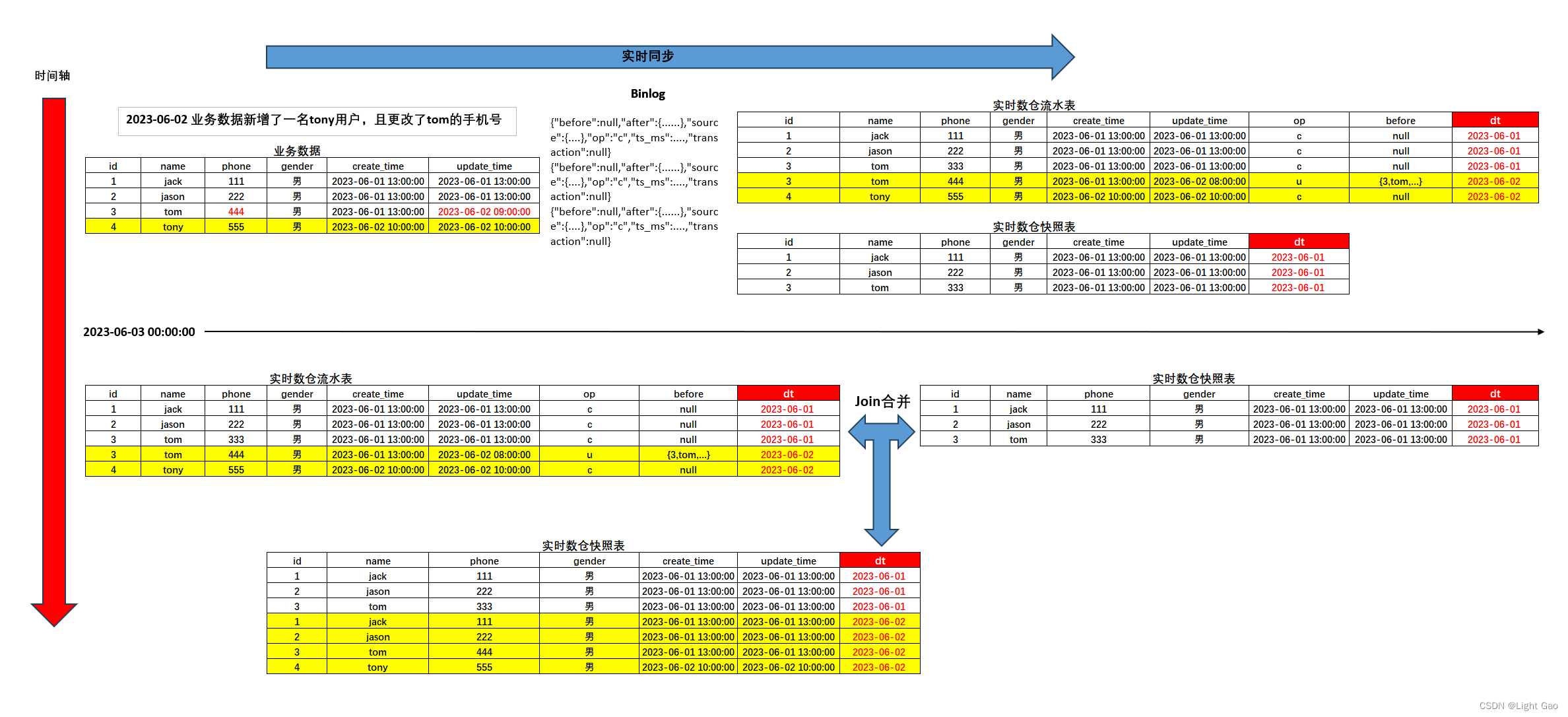
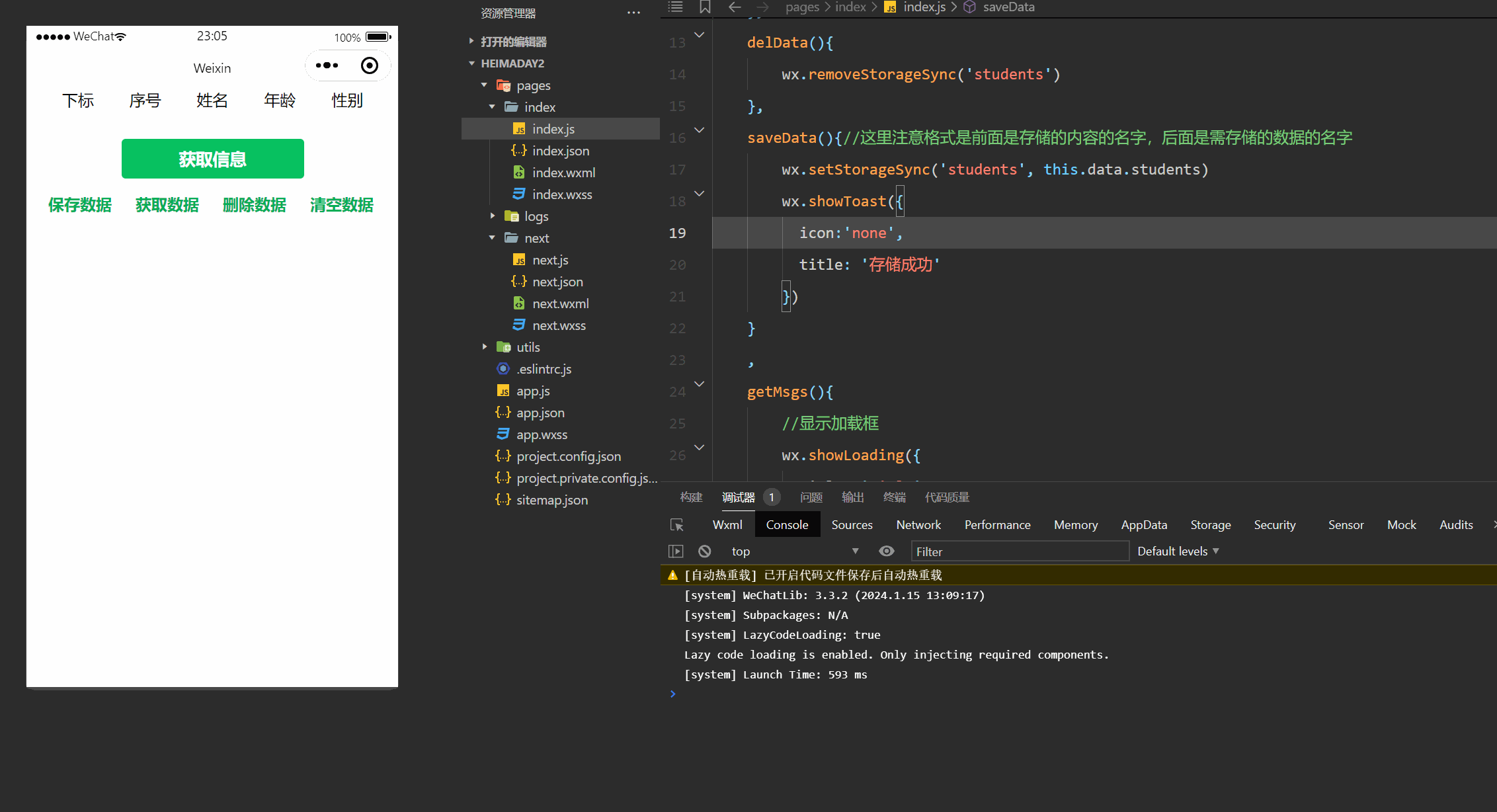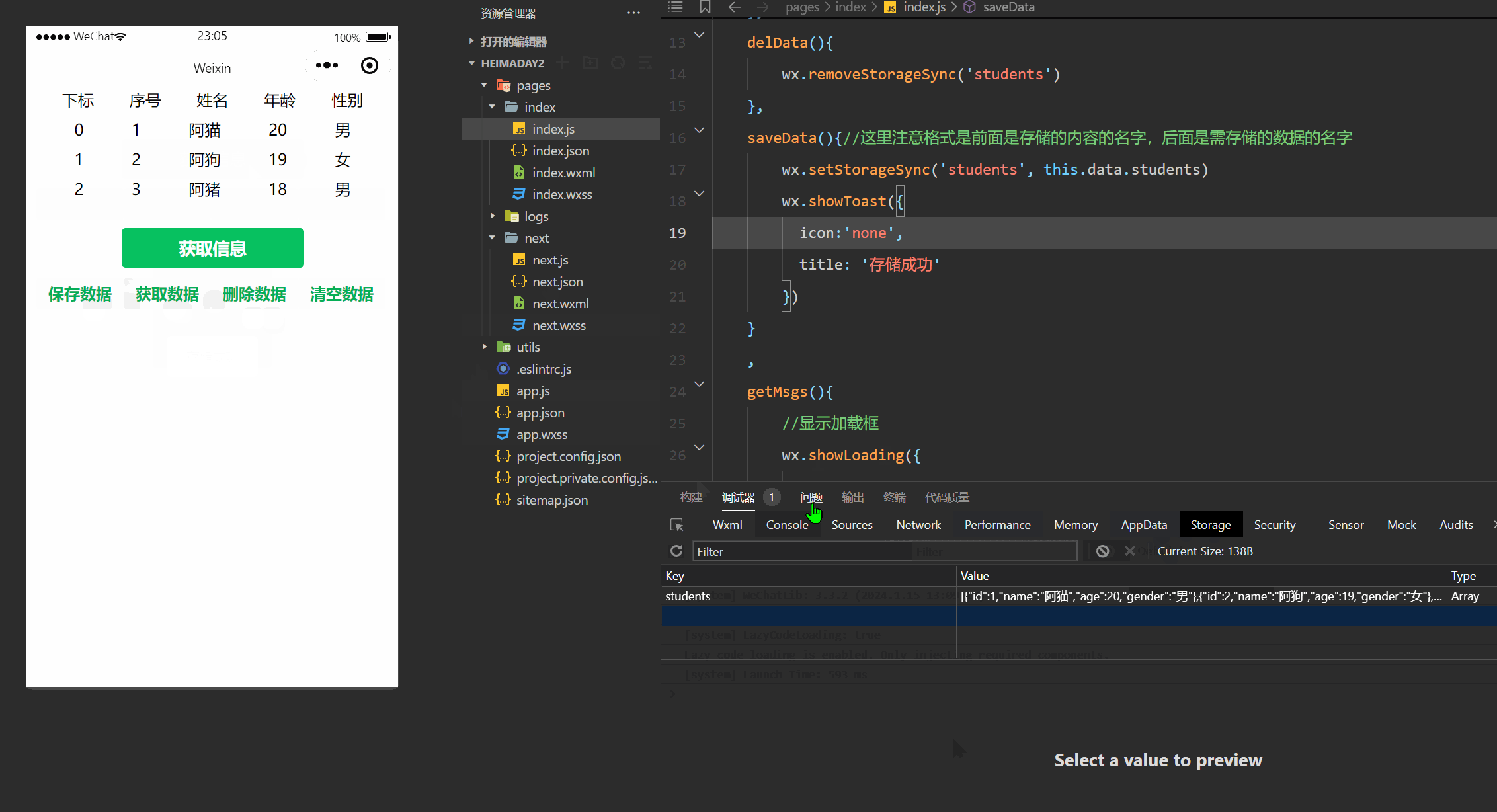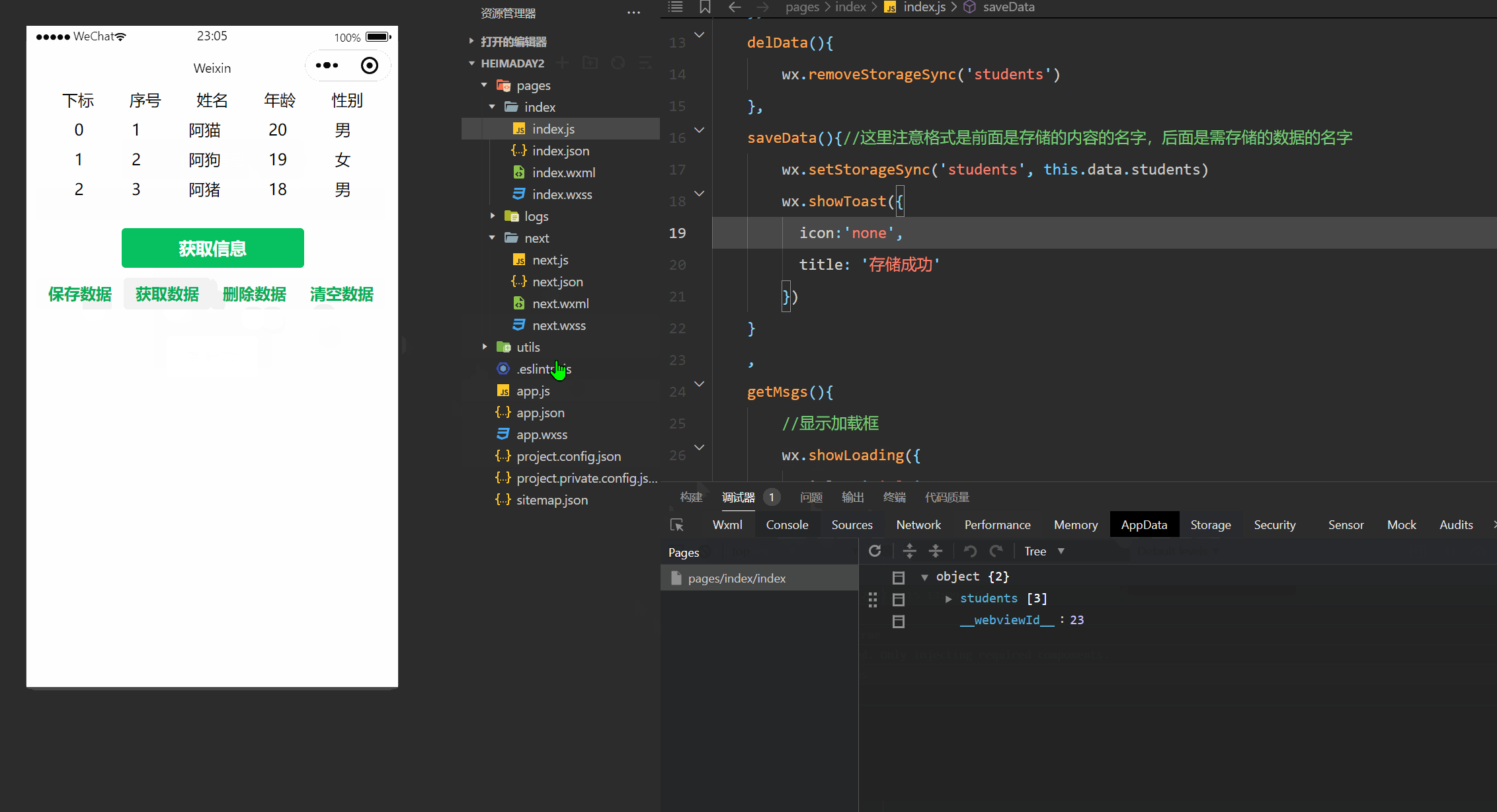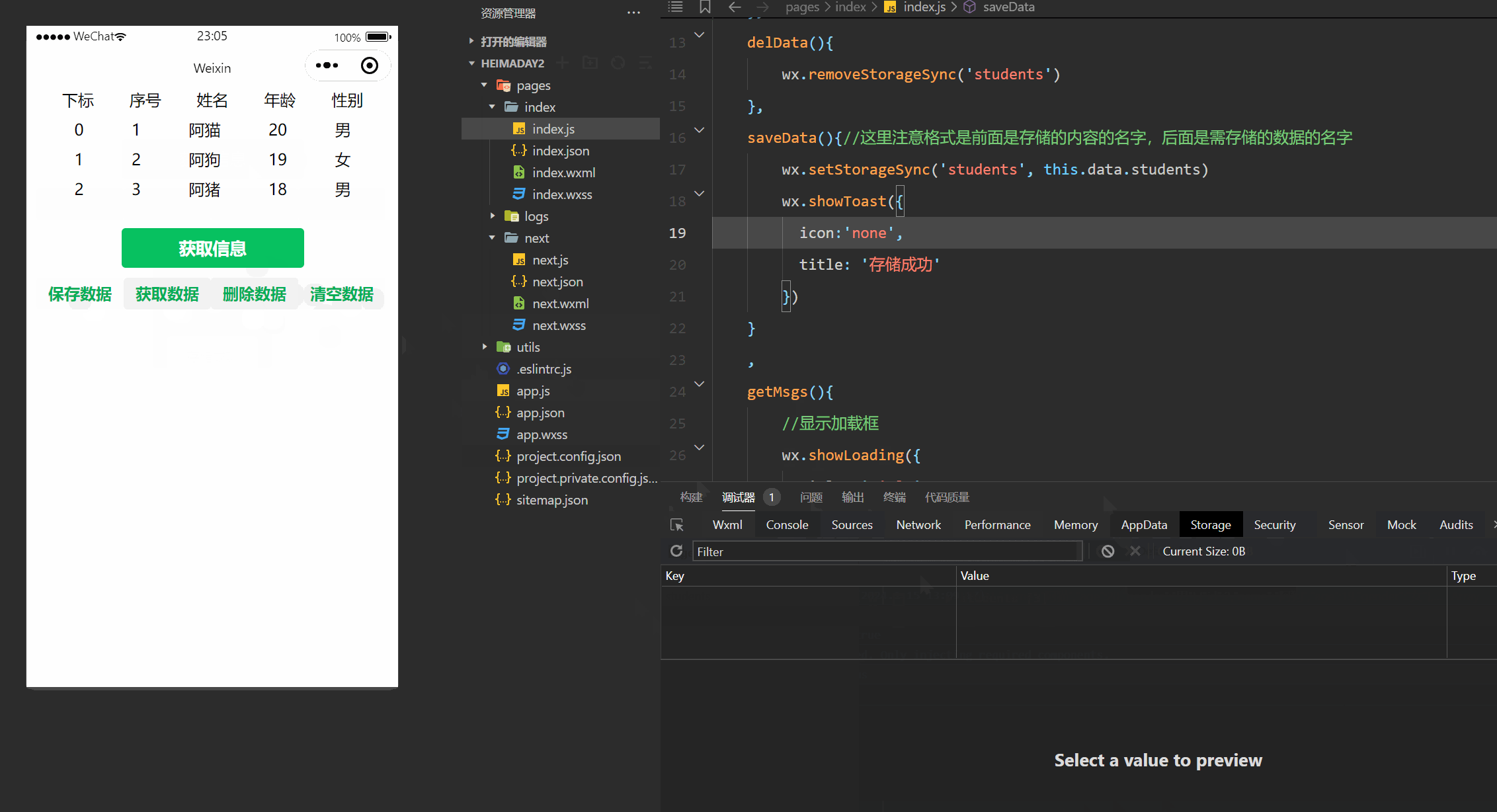
这张图像是运行yolov8-seg程序得到的结果图,首先是检测到了person、bus及skateboard(这个是检测错误,将鞋及其影子检测成了滑板,偶尔存在错误也属正常),然后用方框将他们标出,之后由分割将其轮廓标出。
接下来看看具体怎么实现的,这个程序主要由YOLOv8_seg::infer()与YOLOv8_seg::postprocess()函数实现,之后利用YOLOv8_seg::draw_objects()函数将结果展示在图像中。
segment
接下来分割部分进行解读:
YOLOv8_seg::postprocess()函数得到了objs, 其中包含了检测目标box的尺寸及位置,还包含了目标轮廓数据,在box中是目标的像素块的像素值为255,其余区域均为0。上面结果可以看到目标既被方框标出,又有颜色涂抹,这里其实是利用cv::addWeighted()函数实现的,是将两张图像按照不同权重融合在了一起。
下面这张图像是仅展现出了分割的效果:

所有被检测到的目标均被分割。如果只需要对person分割,由于person的标签序索引0,所以将检测到的目标标签与0作判断即可。
cv::Mat segmask = image.clone();
for (auto& obj : objs) {
int idx = obj.label;
if (idx == 0)
{
cv::Scalar mask_color =
cv::Scalar(MASK_COLORS[idx % 20][0], MASK_COLORS[idx % 20][1], MASK_COLORS[idx % 20][2]);
segmask(obj.rect).setTo(mask_color, obj.boxMask);
}
}
于是就得到了:

看一下objs具体包含了什么样的数据
for (auto& obj : resultObjs)
{
std::cout << "----------------------------------------------" << std::endl;
std::cout << "Rect: " << obj.rect << std::endl;
std::cout << "Label: " << CLASS_NAMES[obj.label] << std::endl;
std::cout << "boxMask: " << obj.boxMask << std::endl;
}
循环中的一次输出:
----------------------------------------------
Rect: [77 x 324 from (2, 545)]
Label: person
boxMask: [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0;
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0;
...
...
...;
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0;
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
从输出结果可以看出这个目标尺寸为77 x 324,从图像中坐标 (2, 545) 开始,目标类别是person,boxMask中的数据为255的则是目标所在的像素,数据为0的则是目标之外的像素。
boxMask的数据可以在yolov8-seg.hpp中找到其赋值语句:
objs[i].boxMask = mask(objs[i].rect) > 0.5f;
可以看出boxMask为什么只有0与255了。
获取坐标
那么根据输出结果我们可以利用rect与boxMask获取目标(这里的目标是person)的坐标,首先可以利用函数cv::findNonZero()找出boxMask中值为255的坐标,然后再加上rect包含的目标框的起点坐标就可以了
// 创建白色画布((1080,810)是图像尺寸,画布要与原图像尺寸一致)
cv::Mat segImg(1080, 810, CV_8UC3, cv::Scalar(255, 255, 255));
std::vector<cv::Point> segpoints;
cv::Mat segmask = image.clone();
for (auto& obj : objs) {
int idx = obj.label;
if (idx == 0)
{
cv::Scalar mask_color =
cv::Scalar(MASK_COLORS[idx % 20][0], MASK_COLORS[idx % 20][1], MASK_COLORS[idx % 20][2]);
segmask(obj.rect).setTo(mask_color, obj.boxMask);
cv::Mat locations;
cv::findNonZero(obj.boxMask == 255, locations);
// 打印位置
std::cout << "值为 255 的位置:" << std::endl;
for (int i = 0; i < locations.rows; ++i) {
std::cout << "(" << locations.at<cv::Point>(i).x << ", " << locations.at<cv::Point>(i).y << ")" << std::endl;
// 这里是目标方框bbox中的坐标,之后需要加上方框起点
cv::Point segpoint = locations.at<cv::Point>(i);
segpoint.x += obj.rect.x;
segpoint.y += obj.rect.y;
// 将所有坐标(x,y)存储在segpoints中
segpoints.push_back(segpoint);
}
}
}
for (const auto& segpoint : segpoints) {
segImg.at<cv::Vec3b>(segpoint) = cv::Vec3b(255, 0, 0);
}
cv::imshow("segImg",segImg);
cv::imwrite("segImg.jpg",segImg);