2024 年伊始,Kyligence 联合创始人兼 CEO 韩卿在其公司内部的飞书订阅号发表了多篇 Rethink Data & Analytics 的内部信,分享了对数据与分析行业的一些战略思考,尤其是 AI 带来的各种变化和革命,是如何深刻地影响这个行业乃至整个企业运营与管理。
经整理,我们也将向业内分享这一系列的大部分内容,这是该系列的第一篇文章,为技术趋势方面,内容有删减。与面临 AI 转型的各位朋友共勉,也期待大家在评论区分享自己的见解和体会!
各位同学,大家新年好!
2023 年,我的飞书签名是“Rethink Data & Analytics”,我们一直在探索,未来的数据与分析,应该是什么样子,尤其是在 AI 带来巨大变革的时候,更加紧迫地让我们去深入思考,未来的数据和分析,会向什么方向发展?我们,又如何在这一波革命中,抓住机会,为我们的客户提供更好的产品和体验,更好地发展我们的业务。
经过 Kyligence 过去一年的实践,在 AI 加持之下,我们的理念、产品以及实践,逐渐在市场上获得了认可,也获得了越来越多的共鸣,这让我们更加坚定地在这个方向上向前走,尤其是年底来自百胜中国、中控技术、皮爷咖啡等客户订单,我们过去一年多的转型没有白费,我们做对了产品,我们验证了我们的 PMF (Product Market Fit),从现在的 Pipeline 中,我们能够感受到强烈的市场脉搏。
在新年之际,我想借此机会,和大家分享更多我们的一些思考,以及对未来的一些认知,希望大家一起,为这个行业的变革带来贡献。这是这个系列的第一篇,介绍我们对相关趋势的观察和思考。
Apache Kylin 毕业于2015年,Kyligence 公司成立于2016年,在过去几年,我们在技术上不断迭代和更新,以适应新的技术趋势,积累了不少实践和总结。
Open source can't make big money
这是我很不愿意提及的话题,但事实如此。
从商业角度看,开源不是商业模式,只是市场手段。而在商业上,如果没有有效的商业化手段,开源的用户是不会转换成为付费用户,从行业中很多朋友们的实践中可以深刻地感受到。
很多人对我们的认知不够深刻,觉得我们是让用户先用开源 Kylin,然后转换到商业版本,这个误解很多年了。Apache Kylin 在我们离开 eBay 的时候,已经完成了几项重要的社区工作:
-
毕业成为 ASF 顶级项目,建立了品牌和知名度
-
被几大互联网厂商大规模使用,包括百度、网易、头条、美团等,磨炼了技术成熟度
-
作为中国第一个 ASF 顶级开源项目,构建了社区和影响力
因此,在我们创立 Kyligence 公司的时候,即全面开启商业化,几乎所有的客户都是直接谈的企业版,并且在一开始就走商业化合作,这也是这么多头部客户持续合作多年的原因。今天我们积累了这么多企业级客户,只有极个别是使用了 Apache Kylin 之后转换为商业版的,尤其是银行等金融客户,一开始就对企业级特性、安全、资源管理以及服务等提出了苛刻的需求,而这些也是企业版的设计目标。客户要的从来不仅仅只是技术,而是技术背后的产品设计、服务保障以及持续的创新能力。
商业是商业,我们所有人必须要深刻理解客户为什么付钱,为什么愿意付我们这么多钱,底层技术突破很难,但往往在产品上,真正赚钱的不是最高深的技术,我们只需要提升一些用户体验,改变一些工艺流程,只要能够帮助用户节省人力、成本,提升效率,客户都是愿意付费的——每个技术点,都要设计价值主张给到客户,而不是只是说技术很厉害,必须得到客户的认可。这需要我们更多深入客户现场,更多去理解客户的实际需求、痛点、痒点。
当然,我们并不否认开源的价值,包括我们自己,也是从开源技术、社区等获益匪浅,我们也将持续在各个开源项目中持续投入、参与和继续主导。
Hadoop is dead
Hadoop 作为大数据的代表,曾经风光无限,曾经有着巨大的市场机会。可惜在2021年随着 MapR 的出售和 Cloudera 的私有化逐渐没落。这里有太多的原因,但从我的视角,主要来自于社区的分裂和商业策略上的保守。2017年,Doug Cutting 在北京出席我们的 Meetup 的时候,还在畅想未来十年的 Hadoop 生态如何(当时正好是 Hadoop 十周年)。而不到5年,行业已经几乎很少再谈论 Hadoop 的相关技术(有也只是小修改,没有惊艳的项目出现了)。

2017年在 Apache Kylin Meetup 上与 Doug Cutting 合影
在创业的前五年,我们很幸运跟着大数据、数据湖的扩张而扩张,那时候各家银行都在将基于 MPP 数据仓库的应用迁移到基于 Hadoop 的大数据平台,而我们做为大数据平台上最好的 OLAP,吃到了红利。但随着 Hadoop 厂商的没落,我们也明显能感觉到市场的快速变化,同时随着云计算的兴起,云数据仓库、云数据湖又非常快速的在市场上出现,“数据仓库”的技术流派逐渐分裂。而国内更加糟糕,各种定制的 Hadoop、魔改的私有云等等,使得这个市场非常复杂,但却又很难赚到超额利润。
2021年,某银行客户领导联系我们去讲课,直接坦承“Hadoop 已经结束了”,让我们去和他们架构团队探讨 Hadoop 之后的大数据平台应该如何走向,以及现有的架构、应用等如何迁移等。当时我们就非常敏感地意识到必须更快地迭代和转型。
过去的两年多来,我们可以真切地感受到越来越多的客户这里,以 Hadoop 为主的平台正在放缓建设,一部分重新回到了 MPP(以数据仓库为基础,大数据/数据湖支撑部分业务),一部分走向了云原生架构(以数据湖为基础,走向湖仓一体)。未来这种复杂的混部架构应该会持续存在至少5年以上,这其实也是我们的机会,我们可以为客户提供屏蔽底层架构的统一数据层(也就是全场景 OLAP、统一语义层),这方面我们有很大的优势。
BI will be evolved
现代的 BI 工具,几乎都是可视化工具,而之所以需要这么强的可视化,是因为人类无法直接理解数据,给人 0 和 1 是无法直接解读和理解的。而图形可以帮助人类快速理解,某个指标是涨了还是跌了,某个因子比另外一个要影响更大,哪个结果指标是由哪几个过程指标分解等等。优秀的可视化能力,是帮助分析师高效完成分析、总结和探索的的利器。
但今天,当 AI 可以直接读取和分析数据的时候,是不需要前置一个可视化的,直接给 AI 数据 0 和 1,即可让 AI 快速给出分析结论,是涨了跌了,背后是为什么,什么因子影响的,影响有多大,还有什么原因等等,这里的效率提升,是十倍到百倍以上的。相当于 AI 把以前分析师需要做的大部分工作都做了,人类只需要进行选择、判断和稍微修正就行。这是 AI 时代对数据和分析行业带来巨大变化的第一点。
自动化行业有一个非常好的比喻:不要让机器人打算盘。都已经有 AI 了,人类可以问 AI 要结果和建议,而不是依然让 AI 去做低效的工作。

图片来源:ChatGPT 4
我们今天的产品已经做到了这些能力,我们可以更进一步,去改变这个行业。为用户提供一个动态的、聪明的、高效的决策助理/Copilot,而不仅仅只是一个数据呈现工具。
Performance is not the key, Performance will be the new key
我们在 OLAP 的场景中,经常碰到的挑战就是 Performance,虽然性能是我们的强项,但往往我们花费了无数的心血,可能只是为了帮助客户的某条 SQL 提速了几秒钟,或者只是让他们在点开仪表盘的时候少等待几秒。Performance/性能,是在技术 PK 中,最常见的,也是最近很多友商来进攻的一个点。性能良好的系统/OLAP,当然是非常好的,但当大家都到了秒级的时候,其实已经没什么可比的。而往往改变一个数据结构,或者一个数据 Pipeline,就能够以数量级的方式提升性能。
那为什么需要这么好的性能?在 AI 时代,性能依然重要吗?我们认为,之所以需要 OLAP 或者数据仓库端有极好的性能,是因为大量的数据分析工作,依赖于有限的几个分析师或业务用户,而这个人群的业务压力非常大,且往往数据出来后,依然有着非常繁重的任务,比如对比数据、查阅历史、分析原因、重跑各种可能性等等,并要形成报告和决策、行动建议。所以一个非常好用的工具确实是必不可少的。
但在 AI 时代,这里的大量工作其实可以委托给 AI 完成,甚至可以让 AI 提前完成,尤其是固有的、常用分析套路,同时 AI 可以快速给出大致的总结,这已经能够大大节省人力,甚至 AI 可以让各种系统自动化连接起来。
今天我们用 Kyligence Zen 出一个周报或者做一次归因,只要十秒左右即可,而且自带了总结,这比出来结果,再去查资料写报告,已经有了质的提升,性能尤其是查询性能,在这个场景下其实已经没那么严苛了。反而,并发性成了下一个挑战,因为会有越来越多的人来使用系统。而并发,正好也是我们的强项。
而最近,更多的客户已经将关注点,从性能转移到了 Performance 的另外一个含义:绩效。指标平台,本质上是一个 KPI 平台,而 KPI 则是 Key Performance Indicator 的缩写。当我们将关注点从性能转移到绩效的时候,突然发现,这才是客户真正要的产品:仪表盘或者报表从来不是客户要得最终结果,他们要得是基于数据的管理能力。几乎每一个有用的指标/Metric,都展示了某个业务或者管理的结果,而一个公司之所以需要指标,就是为了更好地观测相关业务的进展、健康状态以及及时采取措施来修正组织行为,从而确保公司的整体或者部分绩效能够按照设定的目标行进。
我们最近在一个银行客户这里做的 POC,就是一个绩效管理相关的需求。虽然看上去有非常大的难度,但这个方向确实是我们产品的正确方向,继续突破,我们将能够开拓一个非常大的市场。
我们要跳出技术思维,在 Performance/绩效上打出差异化和壁垒,提升技术投入的 ROI,并快速占据市场。
AI is eating the world

图片来自网络
AI 正在吞噬软件,这是 NVIDIA 黄仁勋在2017年的一篇采访中提到的,到今天,应该没有人再怀疑这个论断。现在的问题是,AI 将如何改变不同领域的软件,在我们自己的行业,就是 AI 将如何改变数据与分析市场。
在数仓领域,这个图已经用了超过30年了,“数据源”—“ETL”—“数据仓库”—“OLAP/数据集市”—“BI/Reporting”顶多再加上“元数据”和“分析预测”。不管是 ELT 还是 ETL,不管是数据湖还是数据仓库,不管是本地部署还是云端部署,这里所有的假设,都是数据需要经过漫长的工程,从原始数据萃集后,整理成星型或雪花模型,从而提供给上层 BI 等使用。作为使用者的最终用户,往往是最后才被赋能,从而导致大量的数据其实今天依然没有被充分利用起来。
图片来自网络
Generative AI(生成式 AI)的出现,使得数据的工艺流程出现了巨大的变革,数据的加工方式发生了革命性的变化。首先,各种复杂的重复性的劳动,尤其是数据的 Pipeline,都将由 AI Agent 来处理。小到行列转换,大到数据治理,未来应该有很多的 AI Agent 来处理这些工作,人类只需要用提示词设计合理的流程就好。这从 ChatGPT 自带的 Advanced Data Analysis 和众多使用 OpenAI’s Code Interpreter 的数据分析工具都可以看到,甚至 GPTs 可以通过几个简单的提示词就可以完成很多数据梳理、分析的工作。
当时我在一个内部的文档中就写到:

其次,人和机器的交互进化到了最自然的方式,数据的消费方式发生了革命性的变化。只要会说话,就能用数据,这是这次 AI 带来的巨大变革。这使得原来只有领导、分析师、专业用户等才能使用的“数据和分析能力”,一下子平民化到了每个人,即使文化水平有限的用户,也能被充分赋能。这将大大改变现在的数据架构、处理模式和消费方式等。
大部分公司现在能够有效使用数据的员工不超过10-15%,而这次 AI 革命,能够让其余 85-90% 的人直接消费数据或者数据产品,可以预见,现有的数据架构是无法满足的。这里的变革才刚开始,我们的实践走在行业最前沿,最近收到很多的市场反馈,都说我们的产品做的非常务实和好用,甚至某头部股份制银行和我谈是不是给他们提供个产品咨询教他们怎么做产品——这说明我们的设计、体验和功能,获得了最终用户的认可,正在影响行业的发展。
当每个人都能、都需要消费数据的时候,传统的数据仓库或者数据湖的架构是否还适用,数据的存储方式将发生什么样的变革?这是一个开放问题,目前我还没有具体的答案,但可以预见,AI 的场景,必然会要求系统处理更多的数据,更灵活地访问数据和更高效地服务更多人。从今天的大部分 MPP 和大数据的架构上看,在这几个方面应该都会很快面临巨大的挑战,当比现在访问量大十倍、百倍甚至万倍的时候,今天任何数据系统要在成本可控的情况下完成都非常困难,这里期待我们未来和客户一起共同研究和探索,一起突破这里的极限。
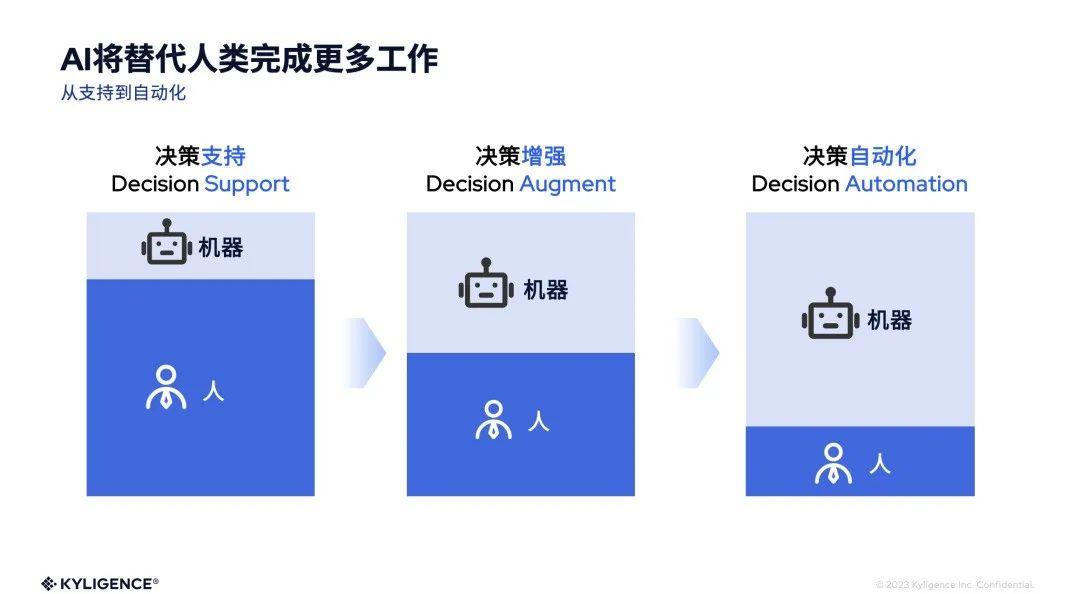
AI 能带来的,将远比这些更多,我们在实践中实现了几个方向,已经产生了巨大的变化和影响,AI 将带来数据和分析的深层次革命。机器将代替人类完成更多的工作,尤其是重复的、可被自动化的。过去数据系统完成数据的加工和指标的统计后,后续需要大量的人工去分析影响相关指标变化的影响要素,探索根因,并根据经验提供相关的决策建议。
而今天,在我们自己的实践中,这部分工作已经可以让 AI 来完成大部分了,结合我们即将发布的一些新能力,将使得未来使用我们系统的用户更加快速地获得分析结果。另外一个实践是我们的产品整合了飞书,今天 Kyligence Zen 可以建议相关行动并通过飞书任务串联执行,未来我们将整合 RPA 等能力,从而让相关的信息流转更加自动化。简单的实践就能看到巨大的变化,这里的潜力无限,希望我们大家发挥想象力,更多地让 AI 来改变数据和分析,甚至是整个企业的经营和管理。
小结
我们一直坚持在技术上持续的进行投入和突破。从 Hadoop 时代开始,我们不断推倒自己的过去,不断迭代自己的产品底座。
-
去掉 HBase 换成 HDFS 存储是 2016 年创业后第一个商业特性
-
从 MapReduce 切换到 Spark 引擎,是在 2017 年左右完成的
-
完全去掉 Hadoop 依赖,彻底跑在公有云上,是 2018 年底完成的
-
完成核心引擎重构,发布 AI 增强引擎,是 2019 年完成的
-
2020 年扩展产品线,从 OLAP 到 Excel 和语义层(和客户共同打磨)
-
2021 年推出分层存储,打造全场景 OLAP
-
2022 我们开始发展向量化 Spark、支持容器化云原生、并推出了指标平台 Zen
-
2023 年,全面集成 AI 能力,推出了 AI Copilot 以及司南大模型(Compass)
理解趋势,快速迭代技术与产品,为市场提供符合发展和客户迫切需求的产品,是一个成功的商业公司应该持续做到的。希望我们大家一起努力,不断领导整个行业的发展,为我们的客户提供更好的产品和服务。
关于 Kyligence
跬智信息(Kyligence)由 Apache Kylin 创始团队于 2016 年创办,是领先的大数据分析和指标平台供应商,提供企业级 OLAP(多维分析)产品 Kyligence Enterprise 和智能一站式指标平台 Kyligence Zen,为用户提供企业级的经营分析能力、决策支持系统及各种基于数据驱动的行业解决方案。
Kyligence 已服务中国、美国、欧洲及亚太的多个银行、证券、保险、制造、零售、医疗等行业客户,包括建设银行、平安银行、浦发银行、北京银行、宁波银行、太平洋保险、中国银联、上汽、长安汽车、星巴克、安踏、李宁、阿斯利康、UBS、MetLife 等全球知名企业,并和微软、亚马逊云科技、华为、安永、德勤等达成全球合作伙伴关系。Kyligence 获得来自红点、宽带资本、顺为资本、斯道资本、Coatue、浦银国际、中金资本、歌斐资产、国方资本等机构多次投资。