问题抛出:
1.系统启动时文件系统功能的实现
1.bootloader支持
1.uboot启动
——典型的arm设备的选择。
情景1:使用initrd或initramfs,内核和根文件系统作为不同镜像时,uboot负责提供启动参数;加载根文件系统到内存。
情景2:使用initramfs,内核和根文件系统作为同一个镜像时,uboot负责提供启动参数,其他啥都不管,内核获得启动参数之后,决定使用何种方式挂载何种类型的根文件系统。
2.grub启动
——许多发行版的选择。
在grub下,可以通过菜单选择不同的启动方式,可以选择不同的内核,不同的initramfs,不同的根文件系统。内核和initramfs都放在/boot下,根文件系统放在了哪?
grub启动分为几个步骤:
stage1:mbr
stage1_5:mbr之后的扇区中,让stage1中的bootloader能识别stage2所在的分区上的fs
提供stage2的文件系统所需的驱动
stage2:磁盘分区之上的,提供选择界面,供用户选择os
stage2及内核等通常放置于一个基本磁盘分区
在stage1_5中,grub可以访问文件系统了,grub在/boot中找到内核并启动,并在/boot中找到initramfs,作为初始的根文件系统,启动其init。
真正的根文件系统在某个分区内,需要在initramfs中挂载,在某台工控机中,initramfs的init脚本先挂载根文件系统,再chroot /sysroot,将根目录迁移到/sysroot:
mount /dev/mapper/centos_hikvisionos-root /sysroot
chroot /sysroot
2.内核支持——内核挂载根文件系统
根文件系统在内核角度和用户角度看,不是一个概念。
内核角度的根文件系统是启动时内核负责生成的机制,用于挂载真正的根文件系统。
用户角度的根文件系统就是我们真正需要挂载的根文件系统,一般为一个带有具体文件系统类型的镜像。
1.rootfs的诞生
引言:
Linux一切皆文件的提出:在Linux中,普通文件、目录、字符设备、块设备、套接字等都以文件被对待;他们具体的类型及其操作不同,但需要向上层提供统一的操作接口。
虚拟文件系统VFS就是Linux内核中的一个软件层,向上给用户空间程序提供文件系统操作接口;向下允许不同的文件系统共存。所以,所有实际文件系统都必须实现VFS的结构封装。
矛盾:
Linux系统中任何文件系统的挂载必须满足两个条件:挂载点和文件系统。
直接挂载nfs或flash文件系统有如下两个问题必须解决:
1.谁来提供挂载点?我们可以想象自己创建一个超级块(包含目录项和i节点),这时挂载点不是就有了吗;很可惜,linux引入VFS(一切皆文件,所有类型文件系统必须提供一个VFS的软件层、以向上层提供统一接口)后该问题不能这么解决,因为挂载点必须关联到文件系统、也就是说挂载点必须属于某个文件系统。
2.怎样访问到nfs或flash上的文件系统?我们可以说直接访问设备驱动读取其上边的文件系统(设备上的文件系统是挂载在自己的根目录),不就可以了吗;别忘了还是Linux的VFS,设备访问也不例外。因为访问设备还是需要通过文件系统来访问它的挂载点,不能直接访问(要满足Linux的VFS架构,一切皆文件)。
解决:
如此矛盾,需要我们引入一种特殊文件系统:
1.它是系统自己创建并加载的第一个文件系统;该文件系统的挂载点就是它自己的根目录项。
2.该文件系统不能存在于nfs或flash上,因为如此将会陷入之前的矛盾。那么该文件系统仅仅存在于内存中。
总结:内核角度的rootfs,是一种文件系统类型,和ext4、yaffs一样(都必须按照遵循VFS机制去实现)。目的是提供最原始的挂载点。
2.数据结构
0.当前进程
Linux内核中current指针作为全局变量,使用非常广泛;例如:进程上下文中获取当前进程ID、任务调度,以及open等文件系统调用中路径搜索等;首先介绍下current结构体:
该指针一般定义在具体平台的current.h头文件中,类型为struct task_struct:
#define current (get_current())
static inline struct task_struct *get_current(void)
//#include/linux/sched.h
struct task_struct {
......
struct thread_info *thread_info;
struct list_head tasks;
pid_t pid;
pid_t tgid;
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid;
struct fs_struct *fs; //本节将大量使用这个
struct files_struct *files;
......
}
1.文件系统注册
kernel/include/include/fs.h
struct file_system_type {
const char *name; //文件系统名字;如:rootfs及ext3等
int fs_flags;
#define FS_REQUIRES_DEV 1
#define FS_BINARY_MOUNTDATA 2
#define FS_HAS_SUBTYPE 4
#define FS_USERNS_MOUNT 8 /* Can be mounted by userns root */
#define FS_RENAME_DOES_D_MOVE 32768 /* FS will handle d_move() during rename() internally. */
struct dentry *(*mount) (struct file_system_type *, int,
const char *, void *);
void (*kill_sb) (struct super_block *);
struct module *owner;
struct file_system_type * next; //指向下一个文件系统类型。
struct hlist_head fs_supers; //同一个文件系统类型中所有超级块组成双向链表。
struct lock_class_key s_lock_key;
struct lock_class_key s_umount_key;
struct lock_class_key s_vfs_rename_key;
struct lock_class_key s_writers_key[SB_FREEZE_LEVELS];
struct lock_class_key i_lock_key;
struct lock_class_key i_mutex_key;
struct lock_class_key i_mutex_dir_key;
};
2.文件系统挂载vfsmount(struct vfsmount):
本质上,mount操作的过程就是新建一个vfsmount结构,然后将此结构和挂载点(目录项对象)关联。关联之后,目录查找时就能沿着vfsmount挂载点一级级向下查找文件了。
对于每一个mount的文件系统,都由一个vfsmount实例来表示。
kernel/include/linux/mount.h
struct vfsmount {
int mnt_flags;
struct dentry *mnt_root; //该文件系统对应的设备根目录dentry
struct super_block *mnt_sb; //指向该文件系统对应的超级块
};
3.目录索引节点(struct inode):
kernel/include/linux/fs.h
struct inode {...};
4.目录项对象(struct dentry):
kernel/include/linux/dcache.h
struct dentry {...};
3.rootfs的生产
注册/创建、安装/挂载rootfs,并调用set_fs_root设置系统current的根文件系统为rootfs
第一步:建立rootfs文件系统;
第二步:调用其get_sb函数(对于rootfs这种内存/伪文件系统是get_sb_nodev,实际文件系统比如ext2等是get_sb_bdev)、建立超级块(包含目录项和i节点);
第三步:初始化挂载树(该文件系统的挂载点指向该文件系统超级块的根目录项);
将系统current的根文件系统和根目录设置为rootfs和其根目录。
启动调用过程:
start_kernel
setup_arch(&command_line);//解析uboot命令行,实际文件系统挂载需要
vfs_caches_init(num_physpages);
mnt_init();
init_rootfs(); //向内核注册rootfs
register_filesystem(&rootfs_fs_type);
init_mount_tree();//rootfs根目录的建立以及rootfs文件系统的挂载;
bdev_cache_init(); //块设备文件创建
chrdev_init();//字符设备文件创建
init_mount_tree:
建立rootfs的根目录,并将rootfs挂载到自己的根目录;设置系统current根目录和根文件系统
//kernel/fs/namespace.c
static void __init init_mount_tree(void)
{
struct vfsmount *mnt;
struct mnt_namespace *ns;
struct path root; //root即为建立的根目录
struct file_system_type *type;
type = get_fs_type("rootfs");
if (!type)
panic("Can't find rootfs type");
//创建rootfs的vfsmount结构,建立rootfs的超级块、并将rootfs挂载到自己的根目录。
/*
mnt->mnt_mountpoint = mnt->mnt_root = dget(sb->s_root),而该mnt和自己的sb是关联的;
所以,是把rootfs文件系统挂载到了自己对应的超级块的根目录上。
这里也是实现的关键:一般文件系统的挂载是调用do_mount->do_new_mount而该函数中首先调用do_kern_mount,这时mnt->mnt_mountpoint = mnt->mnt_root;但后边
它还会调用do_add_mount->graft_tree->attach_recursive_mnt如下代码mnt_set_mountpoint(dest_mnt, dest_dentry, source_mnt)改变了其挂载点!!!
*/
mnt = vfs_kern_mount(type, 0, "rootfs", NULL);
put_filesystem(type);
if (IS_ERR(mnt))
panic("Can't create rootfs");
ns = create_mnt_ns(mnt);
if (IS_ERR(ns))
panic("Can't allocate initial namespace");
init_task.nsproxy->mnt_ns = ns;//设置进程的命名空间
get_mnt_ns(ns);
root.mnt = mnt;//文件系统为rootfs
root.dentry = mnt->mnt_root;//目录项为根目录项
mnt->mnt_flags |= MNT_LOCKED;
//设置系统current的pwd目录和文件系统
set_fs_pwd(current->fs, &root);
//设置系统current根目录,根文件系统。
set_fs_root(current->fs, &root);
}
init_mount_tree
vfs_kern_mount
set_fs_pwd
set_fs_root
vfs_kern_mount实现了rootfs在自己根目录上的挂载:
vfs_kern_mount
mount_fs(type, flags, name, data);
type->mount(type, flags, name, data);
刚注册的rootfs就有了用处,type->mount调用的是
rootfs_mount:
static bool is_tmpfs;
static struct dentry *rootfs_mount(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data)
{
static unsigned long once;
void *fill = ramfs_fill_super;
if (test_and_set_bit(0, &once))
return ERR_PTR(-ENODEV);
if (IS_ENABLED(CONFIG_TMPFS) && is_tmpfs)
fill = shmem_fill_super;
return mount_nodev(fs_type, flags, data, fill);
}
mount_nodev如下:
struct dentry *mount_nodev(struct file_system_type *fs_type,
int flags, void *data,
int (*fill_super)(struct super_block *, void *, int))
{
int error;
//获得此文件系统的sb
struct super_block *s = sget(fs_type, NULL, set_anon_super, flags, NULL);
if (IS_ERR(s))
return ERR_CAST(s);
//填充sb
error = fill_super(s, data, flags & MS_SILENT ? 1 : 0);
if (error) {
deactivate_locked_super(s);
return ERR_PTR(error);
}
s->s_flags |= MS_ACTIVE;
//返回此文件系统的dentry
return dget(s->s_root);
}
ramfs类型和tmpfs类型的super_block的填充的方式不一样,其调用的分别是:
ramfs_fill_super,shmem_fill_super,比如ramfs_fill_super,就是初始化sb,让sb的功能可用
int ramfs_fill_super(struct super_block *sb, void *data, int silent)
{
struct ramfs_fs_info *fsi;
struct inode *inode;
int err;
save_mount_options(sb, data);
fsi = kzalloc(sizeof(struct ramfs_fs_info), GFP_KERNEL);
sb->s_fs_info = fsi;
if (!fsi)
return -ENOMEM;
err = ramfs_parse_options(data, &fsi->mount_opts);
if (err)
return err;
sb->s_maxbytes = MAX_LFS_FILESIZE;
sb->s_blocksize = PAGE_SIZE;
sb->s_blocksize_bits = PAGE_SHIFT;
sb->s_magic = RAMFS_MAGIC;
sb->s_op = &ramfs_ops;
sb->s_time_gran = 1;
inode = ramfs_get_inode(sb, NULL, S_IFDIR | fsi->mount_opts.mode, 0);
sb->s_root = d_make_root(inode);
if (!sb->s_root)
return -ENOMEM;
return 0;
}
至此,rootfs文件系统建立、并且挂载于自己超级块(包括目录项dentry和i节点inod)对应的目录项,设置了系统current根目录和根文件系统、pwd的目录和文件系统。
4.实际的rootfs
以上内核就将根文件系统建立好了,现在要将实际的rootfs释放到rootfs。挂载实际文件系统至rootfs,并调用set_fs_root设置为系统current的根文件系统
内核可能支持initrd和initramfs,如下图所示:

对应内核源码:调用过程如下,上节我们讲了vfs_caches_init,现在来到rest_init,启动第一个用户进程kernel_init
start_kernel
vfs_caches_init
rest_init
kernel_thread(kernel_init, NULL, CLONE_FS);
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
cpu_startup_entry(CPUHP_ONLINE);
kernel_init调用如下:
kernel_init
kernel_init_freeable
do_basic_setup
cpuset_init_smp();
shmem_init();
driver_init();
init_irq_proc();
do_ctors();
usermodehelper_enable();
do_initcalls();
do_initcall_level
sys_open((const char __user *) "/dev/console", O_RDWR, 0)
prepare_namespace();
run_init_process(ramdisk_execute_command); //Initramfs从这里启动init
run_init_process(execute_command); //initrd、nfs和磁盘都是从如下启动的init
try_to_run_init_process("/sbin/init") ||
try_to_run_init_process("/etc/init") ||
try_to_run_init_process("/bin/init") ||
try_to_run_init_process("/bin/sh"))
挑几个关心的函数看一下:
(1)do_initcalls调用。会将__initcall_start 到 __initcall_end 之间的 section执行。
跟根文件系统相关的初始化函数都会由rootfs_initcall()所引用。全局搜索一下发现我们关心的函数也不多:populate_rootfs和default_rootfs
static int __init populate_rootfs(void)
{
char *err = unpack_to_rootfs(__initramfs_start, __initramfs_size);
if (err)
panic("%s", err); /* Failed to decompress INTERNAL initramfs */
if (initrd_start) {
#ifdef CONFIG_BLK_DEV_RAM
int fd;
printk(KERN_INFO "Trying to unpack rootfs image as initramfs...\n");
err = unpack_to_rootfs((char *)initrd_start,
initrd_end - initrd_start);
if (!err) {
free_initrd();
goto done;
} else {
clean_rootfs();
unpack_to_rootfs(__initramfs_start, __initramfs_size);
}
printk(KERN_INFO "rootfs image is not initramfs (%s)"
"; looks like an initrd\n", err);
fd = sys_open("/initrd.image",
O_WRONLY|O_CREAT, 0700);
if (fd >= 0) {
ssize_t written = xwrite(fd, (char *)initrd_start,
initrd_end - initrd_start);
if (written != initrd_end - initrd_start)
pr_err("/initrd.image: incomplete write (%zd != %ld)\n",
written, initrd_end - initrd_start);
sys_close(fd);
free_initrd();
}
done:
#else
printk(KERN_INFO "Unpacking initramfs...\n");
err = unpack_to_rootfs((char *)initrd_start,
initrd_end - initrd_start);
if (err)
printk(KERN_EMERG "Initramfs unpacking failed: %s\n", err);
free_initrd();
#endif
/*
* Try loading default modules from initramfs. This gives
* us a chance to load before device_initcalls.
*/
load_default_modules();
}
return 0;
}
rootfs_initcall(populate_rootfs);
就是解压根文件系统。
在这个函数里,对应我们之前分析的三种虚拟根文件系统的情况。一种是跟kernel融为一体的initramfs.在编译kernel的时候,通过链接脚本将其存放在__initramfs_start至__initramfs_end的区域。这种情况下,直接调用unpack_to_rootfs将其释放到根目录.如果不是属于这种形式的。也就是__initramfs_start和__initramfs_end的值相等,长度为零。不会做任何处理。退出.
对应后两种情况。从代码中看到,必须要配制CONFIG_BLK_DEV_RAM才会支持image-initrd。否则全当成cpio-initrd的形式处理。
对于是cpio-initrd的情况。直接将其释放到根目录。对于是image-initrd的情况。将其释放到/initrd.image.最后将initrd内存区域归入伙伴系统。这段内存就可以由操作系统来做其它的用途了。
static int __init default_rootfs(void)
{
int err;
err = sys_mkdir((const char __user __force *) "/dev", 0755);
if (err < 0)
goto out;
err = sys_mknod((const char __user __force *) "/dev/console",
S_IFCHR | S_IRUSR | S_IWUSR,
new_encode_dev(MKDEV(5, 1)));
if (err < 0)
goto out;
err = sys_mkdir((const char __user __force *) "/root", 0700);
if (err < 0)
goto out;
return 0;
out:
printk(KERN_WARNING "Failed to create a rootfs\n");
return err;
}
rootfs_initcall(default_rootfs);
对根文件系统创建几个节点。
(2)sys_open打开"/dev/console"打开控制台
(3)prepare_namespace:
/*
* Prepare the namespace - decide what/where to mount, load ramdisks, etc.
*/
void __init prepare_namespace(void)
{
int is_floppy;
if (root_delay) {
printk(KERN_INFO "Waiting %d sec before mounting root device...\n",
root_delay);
ssleep(root_delay);
}
/*
* wait for the known devices to complete their probing
*
* Note: this is a potential source of long boot delays.
* For example, it is not atypical to wait 5 seconds here
* for the touchpad of a laptop to initialize.
*/
wait_for_device_probe();
md_run_setup();
if (saved_root_name[0]) {
root_device_name = saved_root_name;
if (!strncmp(root_device_name, "mtd", 3) ||
!strncmp(root_device_name, "ubi", 3)) {
mount_block_root(root_device_name, root_mountflags);
goto out;
}
ROOT_DEV = name_to_dev_t(root_device_name);
if (strncmp(root_device_name, "/dev/", 5) == 0)
root_device_name += 5;
}
if (initrd_load())//如果挂载initrd并执行成功,则不再挂载磁盘文件系统
goto out;
/* wait for any asynchronous scanning to complete */
if ((ROOT_DEV == 0) && root_wait) {
printk(KERN_INFO "Waiting for root device %s...\n",
saved_root_name);
while (driver_probe_done() != 0 ||
(ROOT_DEV = name_to_dev_t(saved_root_name)) == 0)
msleep(100);
async_synchronize_full();
}
is_floppy = MAJOR(ROOT_DEV) == FLOPPY_MAJOR;
if (is_floppy && rd_doload && rd_load_disk(0))
ROOT_DEV = Root_RAM0;
mount_root();
out:
devtmpfs_mount("dev");
sys_mount(".", "/", NULL, MS_MOVE, NULL);
sys_chroot(".");
}
rootfs mount ,三种mount方式:
【方式一】:如果root_device_name是mtd或者ubi类型的根设备,则调用mount_block_root()函数挂载文件系统。
【方式二】:调用initrd_load()进行早期根文件系统的挂载,如果mount_initrd为true的情况下,将执行根文件系统挂载操作。在linux内核中包含两种挂载早期根文件系统的机制:初始化RAM磁盘(initrd)是一种老式的机制。而initramfs是新的用于挂载早期根文件系统的机制。设计initrd和initramfs机制的目的:用于执行早期的用户空间程序;在挂载真正(最后的)根文件系统之前加载一些必须的设备驱动程序。
【方式三】:调用mount_root()函数进行文件系统挂载。该种方式是linux内核中比较常用的方式,在这种方式下,又包含三种文件系统挂载操作:1、nfs方式。2、Floppy方式。3、block方式。在平时开发中,常使用nfs进行网络挂载根文件系统,以便进行开发和调试。
void __init mount_root(void)
{
#ifdef CONFIG_ROOT_NFS
if (ROOT_DEV == Root_NFS) {
if (mount_nfs_root()) //如果网络文件系统挂载成功,则nfs作为根文件系统
return;
printk(KERN_ERR "VFS: Unable to mount root fs via NFS, trying floppy.\n");
ROOT_DEV = Root_FD0;
}
#endif
#ifdef CONFIG_BLK_DEV_FD
if (MAJOR(ROOT_DEV) == FLOPPY_MAJOR) {
/* rd_doload is 2 for a dual initrd/ramload setup */
if (rd_doload==2) {
if (rd_load_disk(1)) {
ROOT_DEV = Root_RAM1;
root_device_name = NULL;
}
} else
change_floppy("root floppy");
}
#endif
#ifdef CONFIG_BLOCK
{
在rootfs中建立/dev/root设备文件,也就是/dev/mtdblock0设备。
int err = create_dev("/dev/root", ROOT_DEV);
if (err < 0)
pr_emerg("Failed to create /dev/root: %d\n", err);
mount_block_root("/dev/root", root_mountflags);
}
#endif
}
以上又分为三种挂载方式,我们不管其他(都大同小异),看一下mount_block_root调用:通过mount来将此文件系统挂载到rootfs的“/root”下:
mount_block_root
do_mount_root
sys_mount(name, "/root", fs, flags, data);
挂载完之后:
devtmpfs_mount("dev"); //挂载dev
sys_mount(".", "/", NULL, MS_MOVE, NULL); //挂载当前目录到 /,这句话无关紧要,影响理解;屏蔽不影响功能
sys_chroot("."); //切换当前目录为根目录
(4)run_init_process执行 /init。完结。。。。。
总结:
1.初始化根文件系统
根文件系统注册
2.挂载根目录
3.挂载具体的根文件系统
解压根文件系统包,将其释放到rootfs目录
4.将根文件系统的目录移动到根目录 /
5.执行/init
根据bootloader传参,选定/init,调用run_init_process 执行init
3.根文件系统的init
分析典型的init,以了解init大致会做些什么:busybox的init以及systemd的init(systemd的init将在下一次分享systemd的时候详细介绍)
init程序负责:
init程序{
①:读取配置文件
②:解析配置文件
③:执行(用户程序)
}
busybox->init_main
parse_inittab
file = fopen(INITTAB,"r"); //打开配置文件 /etc/inittab
new_init_action //①、创建一个init_cation结构体,填充
//②、把这个结构体放入init_action_list链表
run_actions(SYSINIT);
waitfor(a,0); //执行应用程序,等待它执行完毕
run(a); //创建process子进程
waitpid(runpid,&status,0); //等待process子进程结束
delete_init_action(); //在init_action_list链表里删除
run_actions(WAIT);
run_actions(ONCE);
while(1){
run_actions(RESPAWN);
run_actions(ASKFIRST);
wpid = wait(NULL); //等待子进程退出
while(wpid > 0){
a->pid = 0; //退出后,就设置pid = 0
}
}
配置根文件系统:
最小根文件系统需要:
①/dev/console、 /dev/null
②init=>busybox
③ /etc/inittab
④配置文件指定的程序
⑤C库
②:busybox源码生成init 内含sbin、bin、linuxrc、usr
①:再添加 /dev/console /dev/null
③:/etc /inittab
⑤:拷贝工具链里的c库(.so)
再制作成yaffs镜像文件,制作工具:mkyaffs2imae (yaffs2 jffs2)
1、额外挂载虚拟文件系统目录
/proc :进程信息使用的挂载虚拟的文件系统
a、手动挂载 :mount -t proc none /proc
b、自动挂载 : 在inittab里加一个配置脚本 ::sysinit:/etc/init.d/rcS
rcS里加上mount -t proc none /proc 或者 mount -a (会去/etc/fstab脚本里去添加挂载)
/etc/fstab文件格式:
#device mount-point type options dump fsck order
proc /proc proc defaults 0 0
tmpfs /tmp tmpfs defaults 0 0
2.initrd 和 initramfs
1.initrd
initrd基于ramdisk,ramdisk是设备,节点为/dev/ramx0~n。initrd文件系统类型可以多样。
ramdisk使用时需要创建文件系统格式:mke2fs /dev/ram0
挂载 /dev/ram0:mount /dev/ram /mnt/test
2.initramfs
initramfs基于tmpfs,文件系统类型只能是tmpfs。
tmpfs使用时:mount tmpfs /mnt/tmpfs -t tmpfs
1.tmpfs使用
是一个将所有文件和文件夹写到虚拟内存中而不是实际写到磁盘中的虚拟文件系统。这意味着tmpfs中所有的内容都是临时的,在tmpfs卸载、系统重启或者电源切断后内容都将会丢失。技术的角度上来说,tmpfs将所有的内容放在内核内部缓存中并且会调整大小来容纳文件,并可从交换空间中交换出不需要的页。由此可见,tmpfs主要存储暂存的文件。
> df -h
文件系统 容量 已用 可用 已用% 挂载点
dev 3.9G 0 3.9G 0% /dev
run 3.9G 656K 3.9G 1% /run
/dev/sda2 58G 12G 43G 22% /
tmpfs 3.9G 1.0G 2.9G 26% /dev/shm
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
tmpfs 3.9G 0 3.9G 0% /tmp
/dev/sdb1 58G 24G 32G 44% /mnt/data
/dev/sda1 488M 26M 463M 6% /boot
tmpfs 791M 0 791M 0% /run/user/1000
把内存当外存用:ramfs(ramfs是在RAM上建立的文件系统,其不会访问swap空间。)
把外存当内存用:swap
存储空间位于VM(Virtual Memory),tmpfs会使用swap空间。tmpfs使用时并不知道使用的是ram空间还是swap空间。
tmpfs的最大可使用空间:RAM + swap
2.tmpfs实现
Tmpfs是linux 系统中基于内存/交换分区作的文件系统,与ramdisk不同的是,ramdisk是作为块设备,基于ext的文件系统,所以不可绕过的是page cache的内存复制,具体可以参考前面写的关于ramdisk, 对tmpfs来说就是直接操作内存做为文件系统的,而不是基于块设备的。
shmem.c
在CONFIG_SHMEM被打开时,使用shmem:
static struct file_system_type shmem_fs_type = {
.owner = THIS_MODULE,
.name = "tmpfs",
.mount = shmem_mount,
.kill_sb = kill_litter_super,
.fs_flags = FS_USERNS_MOUNT,
};
否则使用ramfs:
static struct file_system_type shmem_fs_type = {
.name = "tmpfs",
.mount = ramfs_mount,
.kill_sb = kill_litter_super,
.fs_flags = FS_USERNS_MOUNT,
};
其操作函数如下:
static const struct file_operations shmem_file_operations = {
.mmap = shmem_mmap,
.get_unmapped_area = shmem_get_unmapped_area,
#ifdef CONFIG_TMPFS
.llseek = shmem_file_llseek,
.read_iter = shmem_file_read_iter,
.write_iter = generic_file_write_iter,
.fsync = noop_fsync,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = shmem_fallocate,
#endif
};
对shmem和tmpfs的关系感兴趣的可以看http://hustcat.github.io/shared-memory-tmpfs/。
3.根文件系统切换
在我们的设备中,initramfs是作为真正的根文件系统使用的,其不涉及到跟文件系统的切换。
但是如上文所说,我们还可以将initramfs作为临时根文件系统,需要跳转到真正的根文件系统。那么如何切换根文件系统?
1.busybox中实现了switch_root命令;有些发行版实现了chroot命令(上次分享使用过)。
2.initramfs中的init将执行此命令进行切换。
1.chroot切换
chroot可以在pid非1的情况下使用,也就是可以在用户命令行使用。
比如挂载/boot/下的initrd,chroot切换
2.switch_root使用:
switch_root [-c /dev/console] NEW_ROOT NEW_INIT [ARGUMENTS_TO_INIT]
- 其中NEW_ROOT是实际的根文件系统的挂载目录,执行switch_root命令前需要挂载到系统中;
- NEW_INIT是实际根文件系统的init程序的路径,一般是/sbin/init;
- -c /dev/console是可选参数,用于重定向实际的根文件系统的设备文件,一般情况我们不会使用;
- ARGUMENTS_TO_INIT则是传递给实际的根文件系统的init程序的参数,也是可选的。
switch_root命令必须由PID=1的进程调用,也就是必须由initramfs的init程序直接调用,不能由init派生的其他进程调用,否则会出错,提示: switch_root: not rootfs
也是同样的原因,init脚本调用switch_root命令必须用exec命令调用,否则也会出错,提示: switch_root: not rootfs
切换的文件系统中的init文件必须是普通文件,不能是链接文件
3.switch_root切换
1.nfs文件系统切换
1.做一个最小根文件系统(或者直接用之前的)
库上找到ramdisk.gz_debug_20230315_v1.0.10_51200K_rk3588
2.做一个跳转根文件系统:(以rk设备为例,通过nfs挂载)
1.用之前的根文件系统,添加switch_root功能即可
脚本解包设备的rootfs:prebuilts\rk3588\rootfs\rootfs_debug.cpio_20231101_v1.3.7_51200K_rk3588
#!/bin/sh ROOT_UID=0 echo $UID if [ "$UID" -ne "$ROOT_UID" ];then echo "Must be root to run this script." exit 1 fi if [ $# -ne 1 ];then echo "Useage: `basename $0` <filename>" exit 1 fi file $1 | grep cpio > /dev/null if [ $? -ne 0 ]; then echo "not a cpio file!" exit 1 fi [ -d early_cpio ] || mkdir early_cpio rm -rf early_cpio/* #解包到early_cpio cd early_cpio cpio -idm < ../$1 cd .. mv early_cpio rootfs2.修改buxybox来支持switch_root
从新编译busybox,替换rootfs中的busybox,busybox编译配置支持:
CONFIG_SWITCH_ROOT CONFIG_RUN_INIT3.修改linuxrc脚本用于调用switch_root
加载块设备的根文件系统:
#!/bin/sh hik_echo "======================== exec initramfs init ========================" mount -t proc proc /proc mount -t sysfs sysfs /sys mount -t ramfs udev /dev /etc/rcS.d/S_udev #其中/etc/rcS.d/S_udev用来初始化udev mkdir /mnt/rootfs ifconfig eth0 10.6.147.223 netmask 255.255.255.0 route add default gw 10.6.147.254 mount -t nfs -o rw,nolock,proto=tcp,nfsvers=3 10.1.65.145:/data1/lichao86/nfs /mnt mount /mnt/ramdisk /mnt/rootfs hik_echo "======================== Switch to real rootfs... ========================" exec switch_root /mnt/rootfs /bin/busyboxchmod添加可执行权限
3.mk_ramdisk.sh脚本打包,获得根文件系统
3.替换rootfs并从新编译内核:prebuilts\rk3588\rootfs\rootfs_debug.cpio_20231101_v1.3.7_51200K_rk3588
4.将内核替换到设备中
5.准备好原来的rootfs在nfs环境中:
gunzip解压ramdisk.gz_debug_20230315_v1.0.10_51200K_rk3588
mount ramdisk,打开文件系统,cp /bin/busybox init;rm linuxrc
6.重启设备
2.块设备文件系统切换
和nfs的区别是,跳转脚本不一样:
#!/bin/sh hik_echo "======================== exec initramfs init ========================" mount -t proc proc /proc mount -t sysfs sysfs /sys mount -t ramfs udev /dev /etc/rcS.d/S_udev mkdir /mnt/rootfs mount /dev/sda1 /mnt/rootfs hik_echo "======================== Switch to real rootfs... ========================" exec switch_root /mnt/rootfs /bin/busybox
准备好原来的rootfs在块设备中:
块设备分区后,格式化后,挂载到某个目录下,将原来的rootfs添加到其中。
有俩个要注意的地方,switch_root的根目录下的一号进程一定要叫init
4.switch_root实现
我们从swith_root的实现中,可以瞥见切换根文件系统的一般做法,chroot就不再分析了。
switch_root源码中有以下注释,解释
1.此工具必须在initramfs中使用
2.其功能相当于一个脚本
3.但是此功能不能用脚本实现
If you're _not_ running out of init_ramfs (if for example you're using initrd instead), you probably shouldn't use switch_root because it's the wrong tool.
Basically what the sucker does is something like the following shell script:
find / -xdev | xargs rm -rf
cd "$1"
shift
mount --move . /
exec chroot . "$@"
There are a couple reasons that won't work as a shell script:
1.解析参数获得根目录,init程序
2.chdir切换工作目录到此根目录,判断此根目录为挂载点
3.判断pid为1
4.判断init是否存在,并且是普通类型的文件,不能是链接文件 并且是判断/init文件是否存在,所以这个switch_root的局限还是很多的。
5.判断当前文件系统为ramfs或者tmpfs,除了这两种都不支持
6.挂载此目录
7.chroot切换根目录
8.准备console
9.exec执行init
4.mkfs_ext2实现
文件系统制作过程可以看一下mkfs_ext2源码,busybox中utl-linux/mkfs_ext2.c实现了mkfs_ext2,源码注释比较清晰,本处简单的概括一下源码中文件系统制作过程:
打开块设备
将标准输出重定向到此块设备fd
stat查看此设备是否是块设备
检查此块设备是否被挂载
获得块设备大小
计算块设备的各个数据
建立块设备的superblock
建立块设备的group descriptors
建立块设备的inode
建立块设备的dir
3.mount的实现
1.数据结构
struct vfsmount {
struct dentry *mnt_root; /* 指向这个文件系统的根的dentry */
struct super_block *mnt_sb; /* 指向这个文件系统的超级块对象 */
int mnt_flags; /* 此文件系统的挂载标志 */
}
struct mount {
struct hlist_node mnt_hash; /* 用于链接到全局已挂载文件系统的链表 */
struct mount *mnt_parent; /* 指向此文件系统的挂载点所属的文件系统,即父文件系统 */
struct dentry *mnt_mountpoint; /* 指向此文件系统的挂载点的dentry */
struct vfsmount mnt; /* 指向此文件系统的vfsmount实例 */
union {
struct rcu_head mnt_rcu;
struct llist_node mnt_llist;
};
#ifdef CONFIG_SMP
struct mnt_pcp __percpu *mnt_pcp;
#else
int mnt_count;
int mnt_writers;
#endif
struct list_head mnt_mounts; /* 挂载在此文件系统下的所有子文件系统的链表的表头,下面的节点都是mnt_child */
struct list_head mnt_child; /* 链接到被此文件系统所挂的父文件系统的mnt_mounts上 */
struct list_head mnt_instance; /* 链接到sb->s_mounts上的一个mount实例 */
const char *mnt_devname; /* 设备名,如/dev/sdb1 */
struct list_head mnt_list; /* 链接到进程namespace中已挂载文件系统中,表头为mnt_namespace的list域 */
struct list_head mnt_expire; /* 链接到一些文件系统专有的过期链表,如NFS, CIFS等 */
struct list_head mnt_share; /* 链接到共享挂载的循环链表中 */
struct list_head mnt_slave_list;/* 此文件系统的slave mount链表的表头 */
struct list_head mnt_slave; /* 连接到master文件系统的mnt_slave_list */
struct mount *mnt_master; /* 指向此文件系统的master文件系统,slave is on master->mnt_slave_list */
struct mnt_namespace *mnt_ns; /* 指向包含这个文件系统的进程的name space */
struct mountpoint *mnt_mp; /* where is it mounted */
struct hlist_node mnt_mp_list; /* list mounts with the same mountpoint */
struct list_head mnt_umounting; /* list entry for umount propagation */
#ifdef CONFIG_FSNOTIFY
struct fsnotify_mark_connector __rcu *mnt_fsnotify_marks;
__u32 mnt_fsnotify_mask;
#endif
int mnt_id; /* mount identifier */
int mnt_group_id; /* peer group identifier */
int mnt_expiry_mark; /* true if marked for expiry */
struct hlist_head mnt_pins;
struct fs_pin mnt_umount;
struct dentry *mnt_ex_mountpoint;
}
如上述数据结构所示,文件系统树的位置由这两个确定:
struct dentry *mnt_mountpoint; /* 指向此文件系统的挂载点的dentry */
struct super_block *mnt_sb; /* 指向这个文件系统的超级块对象 */
2.调用过程
SYSCALL_DEFINE5
do_mount
//通过dir_name目录名称,获得path
user_path(dir_name, &path);
user_path_at_empty
filename_lookup
path_lookupat
//将dev_name的设备挂载到path的挂载点上
do_new_mount(&path, type_page, flags, mnt_flags, dev_name, data_page);
path,该结构包含着安装目录的dentry结构以及安装 目录所在文件系统的mount 实例。
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
};
do_new_mount调用关系:
do_new_mount
//它是根据文件系统名称找到对应的已注册的file_system_type,提供mount回调函数。
type = get_fs_type(fstype);
//根据不同的文件系统执行mount操作,获得vfsmount结构。需要type提供的mount回调函数
//vfs_kern_mount 通过 设备名,新建vfsmount
mnt = vfs_kern_mount(type, flags, name, data);
// 将得到的vfsmount结构加入全局目录树,完成挂载
do_add_mount(real_mount(mnt), path, mnt_flags);
vfs_kern_mount调用关系:
vfs_kern_mount
mount_fs(type, flags, name, data);
type->mount(type, flags, name, data);
struct vfsmount *
vfs_kern_mount(struct file_system_type *type, int flags, const char *name, void *data)
{
struct mount *mnt;
struct dentry *root;
if (!type)
return ERR_PTR(-ENODEV);
mnt = alloc_vfsmnt(name); //建立并填充vfsmount
if (!mnt)
return ERR_PTR(-ENOMEM);
if (flags & MS_KERNMOUNT)
mnt->mnt.mnt_flags = MNT_INTERNAL;
//为文件系统建立并填充超级块(主要是其dentry和inode)
root = mount_fs(type, flags, name, data); // 在mount_fs函数里调用特定文件系统的mount回调函数构造一个root dentry,包含特定文件系统的super block信息
if (IS_ERR(root)) {
mnt_free_id(mnt);
free_vfsmnt(mnt);
return ERR_CAST(root);
}
mnt->mnt.mnt_root = root;
mnt->mnt.mnt_sb = root->d_sb;//对mnt_root指向的根目录赋值
mnt->mnt_mountpoint = mnt->mnt.mnt_root;//文件系统挂载点目录,其实就是刚才建立的”/”目录。挂载点就是自己!!!!
mnt->mnt_parent = mnt; //父对象是自己!!!!
lock_mount_hash();
list_add_tail(&mnt->mnt_instance, &root->d_sb->s_mounts);
unlock_mount_hash();
return &mnt->mnt;
}
do_add_mount调用关系:
do_add_mount
//通过挂载点的path,获得mp 挂载点
mp = lock_mount(path);
mountpoint *mp = get_mountpoint(dentry);
graft_tree(newmnt, parent, mp);
static struct mountpoint *lock_mount(struct path *path)
{
struct vfsmount *mnt;
struct dentry *dentry = path->dentry;
retry:
inode_lock(dentry->d_inode);
if (unlikely(cant_mount(dentry))) {
inode_unlock(dentry->d_inode);
return ERR_PTR(-ENOENT);
}
namespace_lock();
mnt = lookup_mnt(path);
if (likely(!mnt)) {
struct mountpoint *mp = get_mountpoint(dentry);
if (IS_ERR(mp)) {
namespace_unlock();
inode_unlock(dentry->d_inode);
return mp;
}
return mp;
}
namespace_unlock();
inode_unlock(path->dentry->d_inode);
path_put(path);
path->mnt = mnt;
dentry = path->dentry = dget(mnt->mnt_root);
goto retry;
}
struct vfsmount *lookup_mnt(struct path *path)
{
struct mount *child_mnt;
struct vfsmount *m;
unsigned seq;
rcu_read_lock();
do {
seq = read_seqbegin(&mount_lock);
child_mnt = __lookup_mnt(path->mnt, path->dentry);
m = child_mnt ? &child_mnt->mnt : NULL;
} while (!legitimize_mnt(m, seq));
rcu_read_unlock();
return m;
}
struct mount *__lookup_mnt(struct vfsmount *mnt, struct dentry *dentry)
{
struct hlist_head *head = m_hash(mnt, dentry);
struct mount *p;
hlist_for_each_entry_rcu(p, head, mnt_hash)
if (&p->mnt_parent->mnt == mnt && p->mnt_mountpoint == dentry)
return p;
return NULL;
}
lock_mount函数就是对当前挂载目录是否已经挂载过其他文件系统进行检查,然后返回一个mountpoint 结构
get_mountpoint为dentry新建挂载点:
static struct mountpoint *get_mountpoint(struct dentry *dentry)
{
struct mountpoint *mp, *new = NULL;
int ret;
if (d_mountpoint(dentry)) {
mountpoint:
read_seqlock_excl(&mount_lock);
mp = lookup_mountpoint(dentry);
read_sequnlock_excl(&mount_lock);
if (mp)
goto done;
}
if (!new)
new = kmalloc(sizeof(struct mountpoint), GFP_KERNEL);
if (!new)
return ERR_PTR(-ENOMEM);
/* Exactly one processes may set d_mounted */
ret = d_set_mounted(dentry);
/* Someone else set d_mounted? */
if (ret == -EBUSY)
goto mountpoint;
/* The dentry is not available as a mountpoint? */
mp = ERR_PTR(ret);
if (ret)
goto done;
/* Add the new mountpoint to the hash table */
read_seqlock_excl(&mount_lock);
new->m_dentry = dentry;
new->m_count = 1;
hlist_add_head(&new->m_hash, mp_hash(dentry));
INIT_HLIST_HEAD(&new->m_list);
read_sequnlock_excl(&mount_lock);
mp = new;
new = NULL;
done:
kfree(new);
return mp;
}
以上过程如图所示:
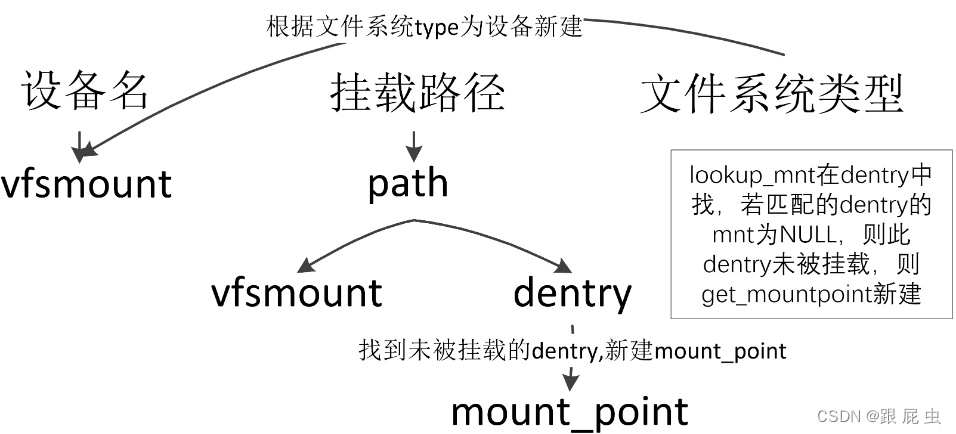
最后调用graft_tree完成挂载,现在mp, parent都有了,我们要做的就是把newmnt和parent,mp构建到一起,比如让newmnt的mnt_parent指向parent,让newmnt的mnt_mountpoint指向mp,用parent和mp计算hash值把newmnt加入到mount_hashtable中。当然还有很多inode, dentry, super_block等等结构之间关系的构建。
graft_tree
attach_recursive_mnt(mnt, nd, NULL);
commit_tree(source_mnt);
static int graft_tree(struct vfsmount *mnt, struct nameidata *nd)
{
/*检查超级块可不可以挂载*/
int err;
if (mnt->mnt_sb->s_flags & MS_NOUSER)
return -EINVAL;
/*检查两个文件系统是不是一致的*/
if (S_ISDIR(nd->dentry->d_inode->i_mode) !=
S_ISDIR(mnt->mnt_root->d_inode->i_mode))
return -ENOTDIR;
err = -ENOENT;
mutex_lock(&nd->dentry->d_inode->i_mutex);
/*dead,死的也不行*/
if (IS_DEADDIR(nd->dentry->d_inode))
goto out_unlock;
/*安全操作*/
err = security_sb_check_sb(mnt, nd);
if (err)
goto out_unlock;
/*如果挂载点是根目录或者在缓存里边*/
err = -ENOENT;
if (IS_ROOT(nd->dentry) || !d_unhashed(nd->dentry))
/*挂载操作*/
err = attach_recursive_mnt(mnt, nd, NULL);
out_unlock:
mutex_unlock(&nd->dentry->d_inode->i_mutex);
if (!err)
security_sb_post_addmount(mnt, nd);
return err;
}
static int attach_recursive_mnt(struct vfsmount *source_mnt,
struct nameidata *nd, struct nameidata *parent_nd)
{
LIST_HEAD(tree_list);
struct vfsmount *dest_mnt = nd->mnt;
struct dentry *dest_dentry = nd->dentry;
struct vfsmount *child, *p;
/*参数检查,是不是合理的,比如要挂载点在目的点的下边*/
if (propagate_mnt(dest_mnt, dest_dentry, source_mnt, &tree_list))
return -EINVAL;
/*是否可分享*/
if (IS_MNT_SHARED(dest_mnt)) {
for (p = source_mnt; p; p = next_mnt(p, source_mnt))
set_mnt_shared(p);
}
/*锁住vfsmount结构体,我们穿入的parent_nd是NULL所以执行else的*/
spin_lock(&vfsmount_lock);
if (parent_nd) {
detach_mnt(source_mnt, parent_nd);
attach_mnt(source_mnt, nd);
touch_mnt_namespace(current->nsproxy->mnt_ns);
} else {
/*dest_dentry的d_mounted++,标记已经挂载,source_mnt结构体填充*/
mnt_set_mountpoint(dest_mnt, dest_dentry, source_mnt);
/*把新的vfsmount提交到全局hash表*/
commit_tree(source_mnt);
}
//attach_recursive_mnt只被调用过2次
//do_move_mount
//graft_tree
//do_move_mount 传的parent_nd不为空,会走以下步骤,这个地方我们不管
list_for_each_entry_safe(child, p, &tree_list, mnt_hash) {
list_del_init(&child->cmnt_hash);
commit_tree(child);
}
spin_unlock(&vfsmount_lock);
return 0;
}
//vfs_kern_mount 将mnt_parent 指向自己,mnt->mnt_parent = mnt,这个地方就真正的将其指向其parent了,也就是我们要挂载的mnt
void mnt_set_mountpoint(struct mount *mnt,
struct mountpoint *mp,
struct mount *child_mnt)
{
mp->m_count++;
mnt_add_count(mnt, 1); /* essentially, that's mntget */
child_mnt->mnt_mountpoint = dget(mp->m_dentry);
child_mnt->mnt_parent = mnt;
child_mnt->mnt_mp = mp;
hlist_add_head(&child_mnt->mnt_mp_list, &mp->m_list);
}
static void commit_tree(struct mount *mnt)
{
struct mount *parent = mnt->mnt_parent; //mnt_set_mountpoint保证其取到的是要挂载的mnt,而不是自己
struct mount *m;
LIST_HEAD(head);
struct mnt_namespace *n = parent->mnt_ns;
BUG_ON(parent == mnt);
list_add_tail(&head, &mnt->mnt_list);
list_for_each_entry(m, &head, mnt_list)
m->mnt_ns = n;
list_splice(&head, n->list.prev);
list_add_tail(&mnt->mnt_hash, mount_hashtable +
hash(&parent->mnt, mnt->mnt_mountpoint)); //根据父挂载点的mount实例和挂载目录的dentry 计算hash 值,链接到mount_hashtable hash表上,至此通过该关系可以从挂载目录找到下级子目录
list_add_tail(&mnt->mnt_child, &parent->mnt_mounts);
touch_mnt_namespace(n);
}
mount的过程就是获得vfsmount,根据path将其添加到全局目录树上的具体位置,链接到mount_hashtable hash表。
4.测试用例
说明系统current的文件系统布局,不管在那个目录、其根都不会改变:
hello.c
#include <linux/syscalls.h>
#include <linux/slab.h>
#include <linux/sched.h>
#include <linux/smp_lock.h>
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/acct.h>
#include <linux/capability.h>
#include <linux/cpumask.h>
#include <linux/module.h>
#include <linux/sysfs.h>
#include <linux/seq_file.h>
#include <linux/mnt_namespace.h>
#include <linux/namei.h>
#include <linux/security.h>
#include <linux/mount.h>
#include <linux/ramfs.h>
#include <linux/log2.h>
#include <linux/idr.h>
#include <asm/uaccess.h>
#include <asm/unistd.h>
//#include "pnode.h"
//#include "internal.h"
#include <linux/init.h>
#include <linux/module.h>
MODULE_LICENSE("Dual BSD/GPL");
static int hello_init(void)
{
printk(KERN_ALERT "Hello, world\n");
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.dentry->d_name.name is %s\n",current->fs->root.dentry->d_name.name);
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.dentry->d_sb->s_type->name is %s\n",current->fs->root.dentry->d_sb->s_type->name);
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_mountpoint->d_name.name is %s\n",current->fs->root.mnt->mnt_mountpoint->d_name.name);
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_mountpoint->d_sb->s_type->name is %s\n",current->fs->root.mnt->mnt_mountpoint->d_sb->s_type->name);
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_root->d_name.name is %s\n",current->fs->root.mnt->mnt_root->d_name.name);
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_root->d_sb->s_type->name is %s\n",current->fs->root.mnt->mnt_root->d_sb->s_type->name);
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_sb->s_type->name is %s\n",current->fs->root.mnt->mnt_sb->s_type->name);
printk("########################################################################################\n");
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.dentry->d_name.name is %s\n",current->fs->pwd.dentry->d_name.name);
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.dentry->d_sb->s_type->name is %s\n",current->fs->pwd.dentry->d_sb->s_type->name);
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_mountpoint->d_name.name is %s\n",current->fs->pwd.mnt->mnt_mountpoint->d_name.name);
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_mountpoint->d_sb->s_type->name is %s\n",current->fs->pwd.mnt->mnt_mountpoint->d_sb->s_type->name);
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_root->d_name.name is %s\n",current->fs->pwd.mnt->mnt_root->d_name.name);
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_root->d_sb->s_type->name is %s\n",current->fs->pwd.mnt->mnt_root->d_sb->s_type->name);
printk("TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_sb->s_type->name is %s\n",current->fs->pwd.mnt->mnt_sb->s_type->name);
return 0;
}
static void hello_exit(void)
{
printk(KERN_ALERT"Goodbye, cruel world\n");
}
module_init(hello_init);
module_exit(hello_exit);
Makefile
ifneq ($(KERNELRELEASE),)
obj-m:=hello.o
else
KERNELDIR:=/home/android2.3/android2.3_kernel/
PWD:=$(shell pwd)
default:
$(MAKE) -C $(KERNELDIR) M=$(PWD) modules
clean:
rm -rf *.o *.mod.c *.mod.o *.ko
endif
1.放入/data/下运行insmod hello.ko rmmod hello.ko
Hello, world
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.dentry->d_name.name is /
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.dentry->d_sb->s_type->name is rootfs
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_mountpoint->d_name.name is /
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_mountpoint->d_sb->s_type->name is rootfs
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_root->d_name.name is /
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_root->d_sb->s_type->name is rootfs
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_sb->s_type->name is rootfs
########################################################################################
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.dentry->d_name.name is /
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.dentry->d_sb->s_type->name is yaffs2
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_mountpoint->d_name.name is data
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_mountpoint->d_sb->s_type->name is rootfs
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_root->d_name.name is /
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_root->d_sb->s_type->name is yaffs2
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_sb->s_type->name is yaffs2
Goodbye, cruel world
2.放在/sdcard/tank/下运行insmod hello.ko rmmod hello.ko
Hello, world
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.dentry->d_name.name is /
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.dentry->d_sb->s_type->name is rootfs
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_mountpoint->d_name.name is /
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_mountpoint->d_sb->s_type->name is rootfs
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_root->d_name.name is /
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_root->d_sb->s_type->name is rootfs
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->root.mnt->mnt_sb->s_type->name is rootfs
########################################################################################
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.dentry->d_name.name is tank
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.dentry->d_sb->s_type->name is vfat
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_mountpoint->d_name.name is sdcard
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_mountpoint->d_sb->s_type->name is rootfs
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_root->d_name.name is /
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_root->d_sb->s_type->name is vfat
TK---->>>>init/main.c>>>kernel_init>>>>current->fs->pwd.mnt->mnt_sb->s_type->name is vfat
Goodbye, cruel world
由此证明;current->fs->root就是系统承认的根文件系统。
参考:
https://blog.csdn.net/tankai19880619/article/details/12093239
https://blog.csdn.net/oqqYuJi12345678/article/details/101681342
https://www.cnblogs.com/arnoldlu/p/10868354.html
http://hustcat.github.io/shared-memory-tmpfs/