目标检测论文总结
【RCNN系列】
RCNN
Fast RCNN
Faster RCNN
【YOLO系列】
YOLO V1
文章目录
- 目标检测论文总结
- 前言
- 一、Pipeline
- 二、模型设计
- 1.训练阶段
- 2.损失函数
- 2.1.框回归损失
- 2.2.置信度损失
- 2.3.分类损失
- 总结
前言
一些经典论文的总结。
一、Pipeline
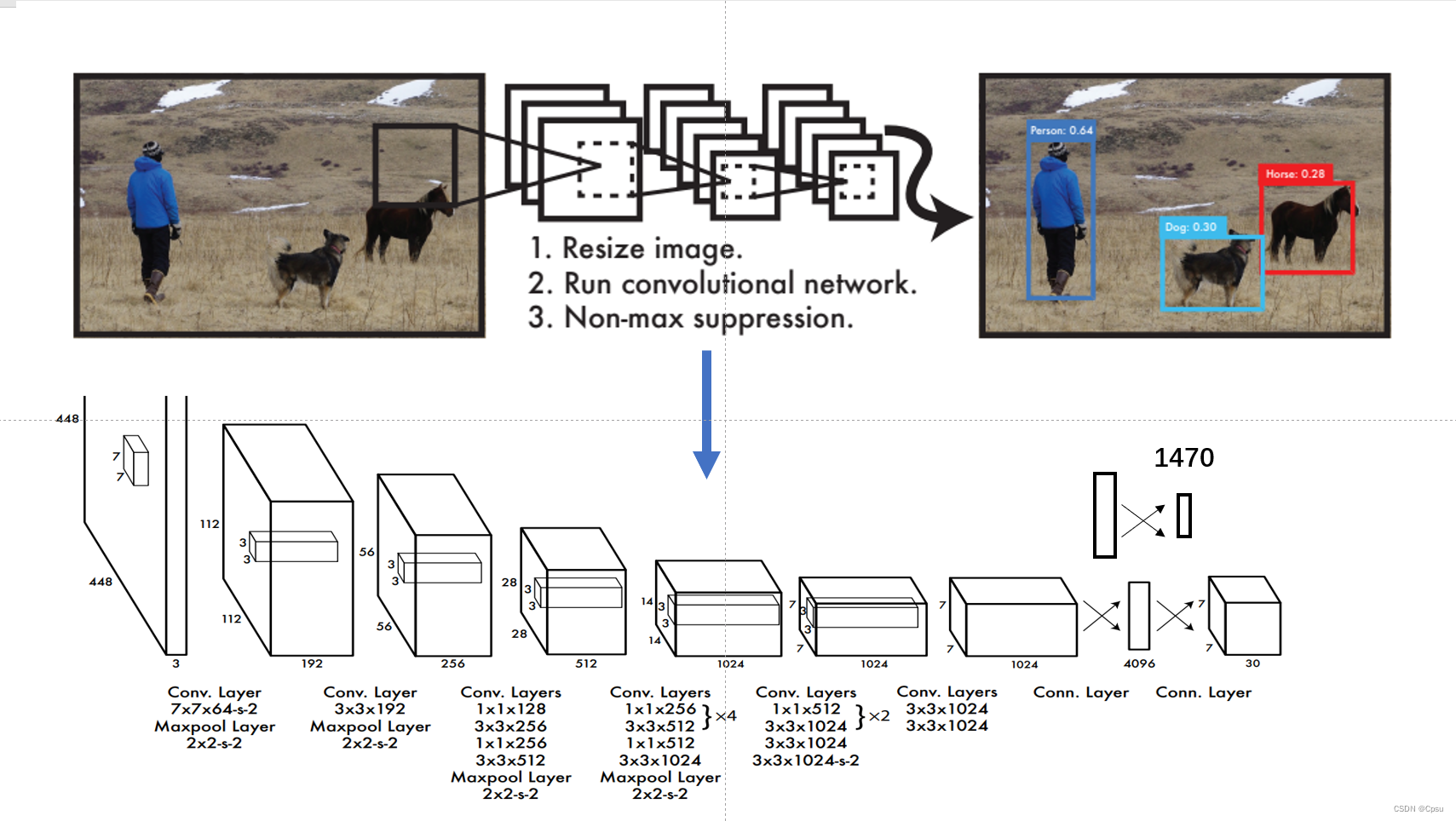
YOLO的pipeline很简单,将一张图片reshape后送入卷积网络,根据卷积网络最后得到的一个三维张量进行目标预测(越觉得和Faster RCNN的RPN网络很类似)。
RCNN系列都是要先获取可能的目标区域(region proposals),把这些可能的区域送进卷积网络进行检测。也就是two-stage检测器。YOLO不同于RCNN系列,它是one-stage检测器,直接根据input得到目标预测。
二、模型设计
1.训练阶段
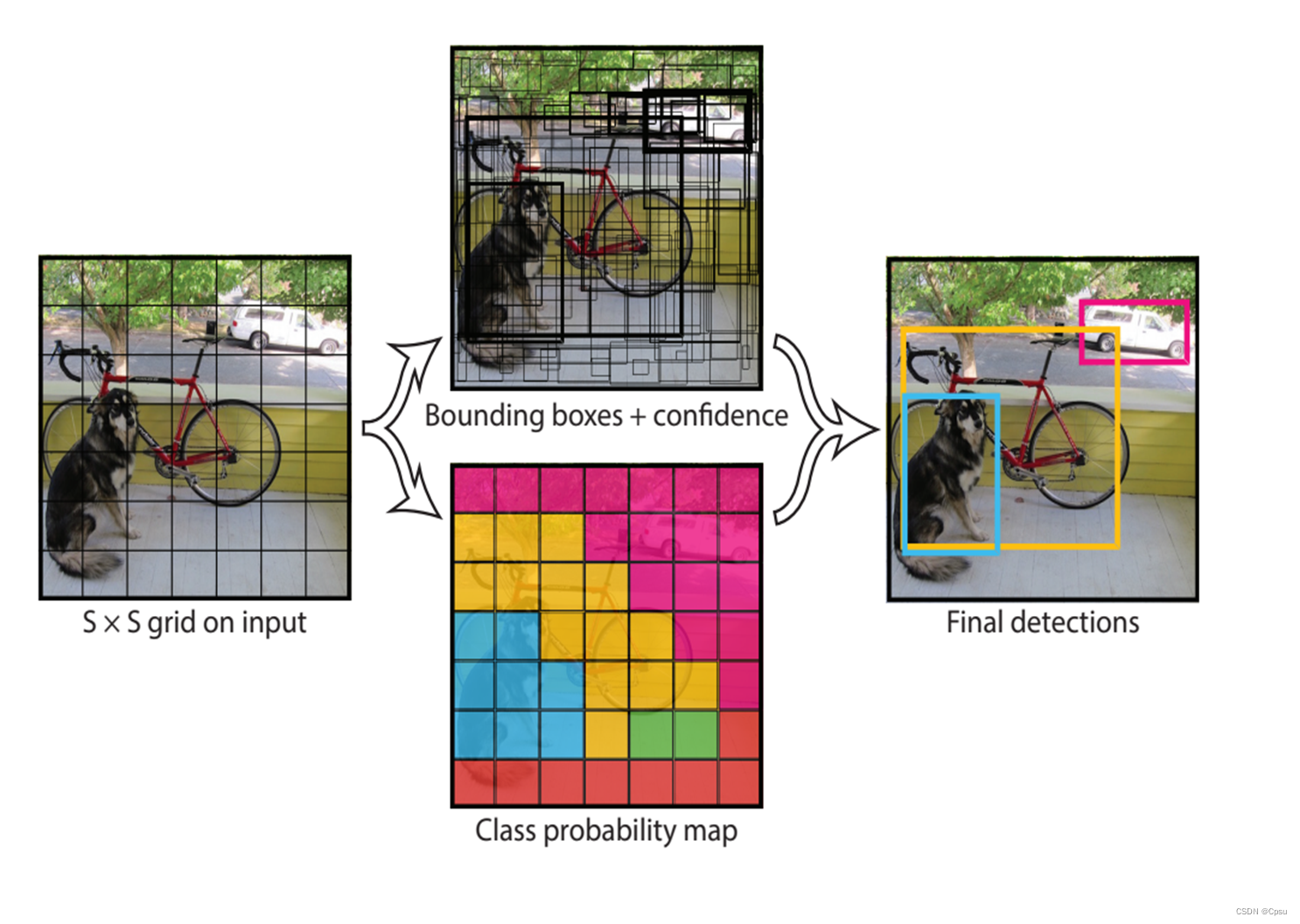
首先,YOLO把一张图片分成SxS个网格,论文中S取7。也就是一张图片有49个网格,每个网格都会生成2个预测框,通过训练让模型能够生成准确的预测框,将目标标注出来。
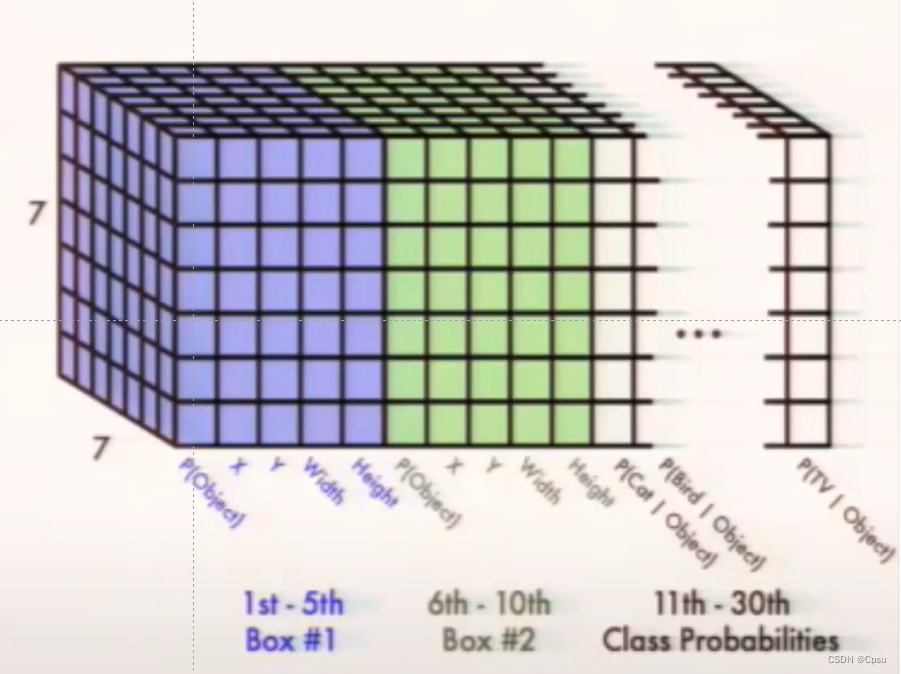
回到pipeline,将一张图片送入卷积网络后,卷积网络最后得到的一个[30,7,7]三维张量即30个通道7*7的大小。30通道分别表示2个预测的box的信息(一个box5个:4个偏移+1个置信度),20分类的条件类别概率,即2*5+20=30。
2.损失函数

YOLO损失函数分为三部分,中心损失和宽高损失都是框回归损失(坐标回归损失)、置信度损失(即预测的框包含物体的概率)、分类损失。
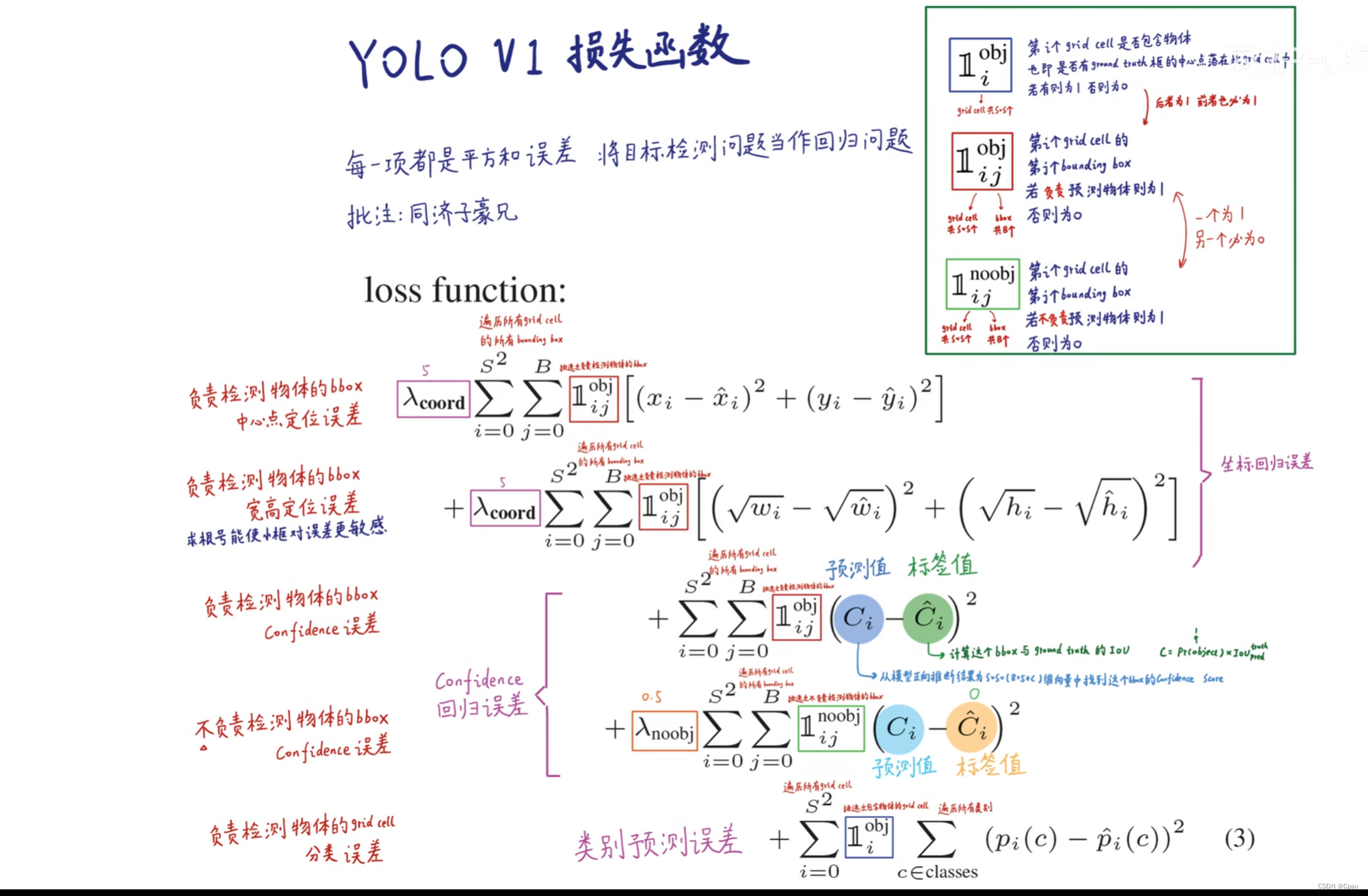
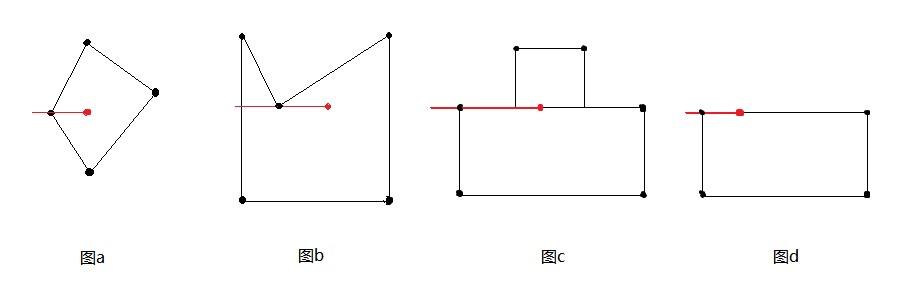
图来自B站同济子豪兄。
2.1.框回归损失
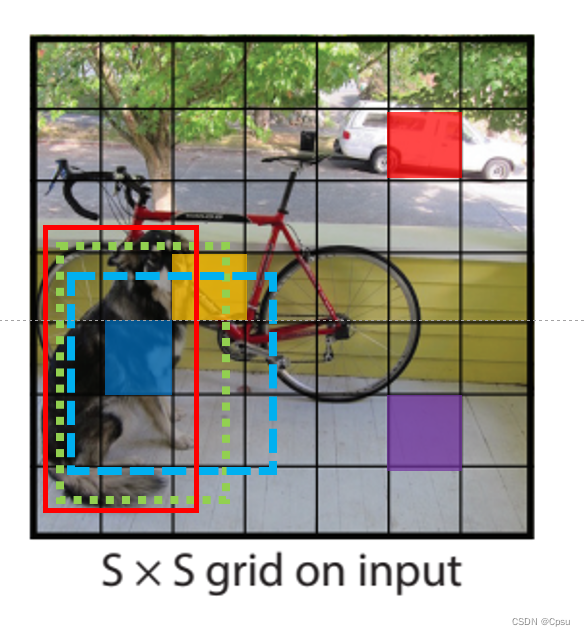
总共49个网格,共生成98个框。98个框要确定哪些是正样本也就是哪些是要计算框回归损失的,没有物体的负样本没有定位框自然不用计算框回归损失。
下图标注了四个颜色(蓝色、黄色、红色、紫色)的方框,分别表示狗的中心、自行车的中心、汽车的中心、背景。YOLO预测的98个框中,只有物体中心生成的框,且与GT有最大IOU的框才能作为正样本。比如,蓝色方框是狗的中心,那么这个网格会预测两个框(蓝蓝色虚线框和绿色虚线框),绿色的框与GT(红色)框的IOU最大,所以正样本只有绿色虚线框。也就是只有绿色的框会计算框回归损失。图中只有三个物体,意味着98个框中只有3个框是正样本,参与计算框回归损失。
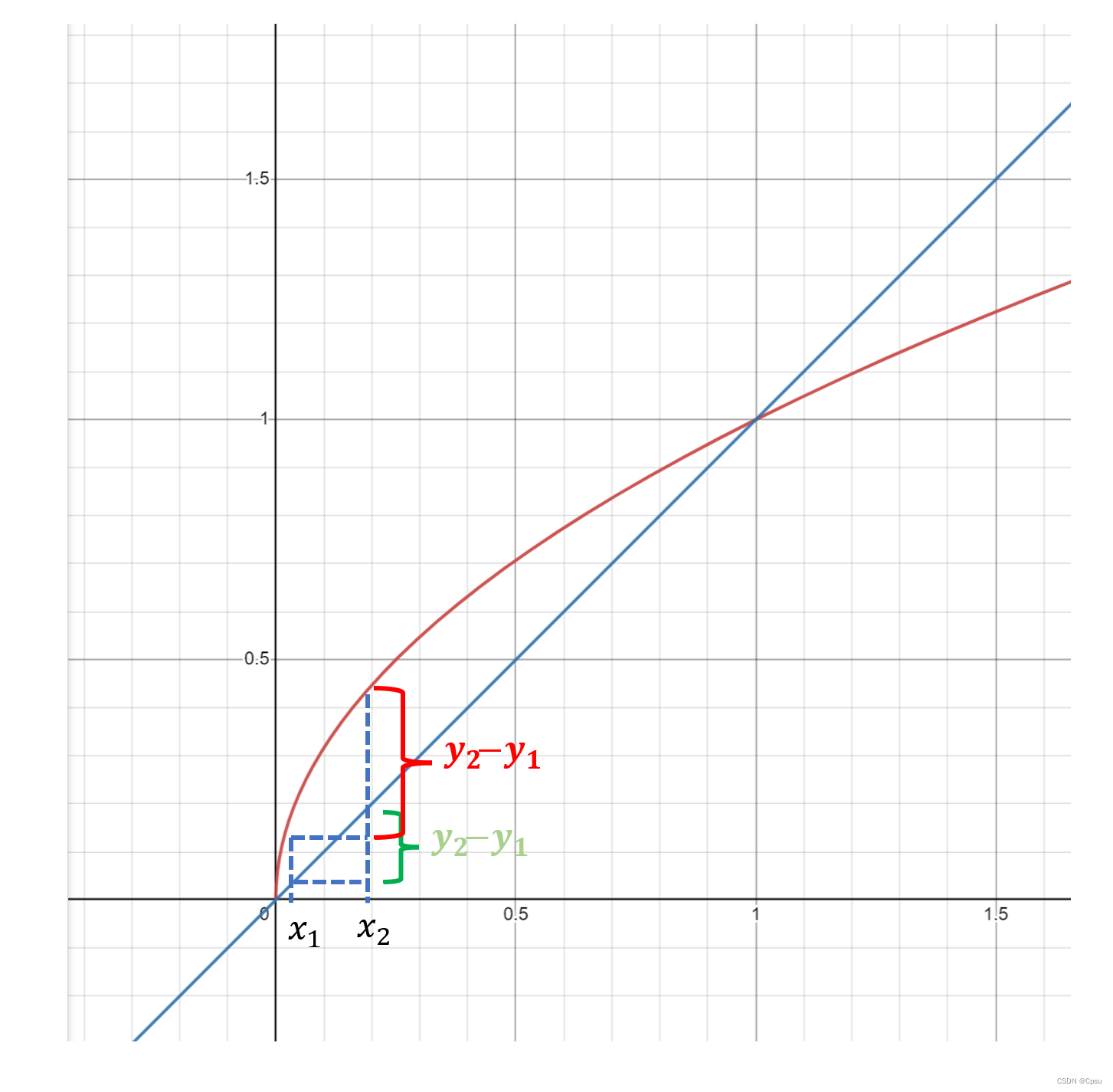
宽高损失取了根号,作者说大框对小偏移不敏感,即使偏移了也能保持较大的IoU,但小框对偏移很敏感。所以通过取根号来减少这种影响。目的就是要放大小预测框的损失,让小框的损失占比能比原来大一些,更好地反向传播。从图像也可以看出在自变量比较小时,两个自变量x1,x2,由于根号的斜率更大的,y2-y1 的差值也会被放大,即放大了小框的误差。
x
(红色曲线)和
x
的图像
\sqrt{x}(红色曲线)和x的图像
x(红色曲线)和x的图像
2.2.置信度损失
置信度损失是是遍历98个框,每个框是否包含物体,如果包含那么这个框的置信度(图中的标签值)应该为1,如果不包含这个框的置信度应该为0。比如,蓝色方框是狗的中心,那么这个网格会预测两个框(蓝蓝色虚线框和绿色虚线框),这两个预测框的P(object)即置信度应该不断训练往1靠近。其他虽然也有包含狗的网格,但是这些网格生成的预测框都被视为不包含物体。汽车、自行车同理。也就是说只有物体中心在的Grid Cell才会被视为有目标,图中只有三个物体,意味着98个框中只有6个框的置信度标签值为1,其他都是0。
2.3.分类损失
卷积网络最后得到的一个[30,7,7]三维张量即30个通道7*7的大小。30通道分别表示2个预测的box的信息(一个box5个:4个偏移+1个置信度),20分类的条件类别概率,即2*5+20=30。卷积网络输出的是条件类别概率(即表示在包含物体的情况下属于某一类的概率),所以代入全概率公式,用预测框的置信度乘以条件类别概率计算分类损失。
类被损失是是遍历49个Grid Cell(网格),只有物体中心所在的Grid Cell才有分类损失。
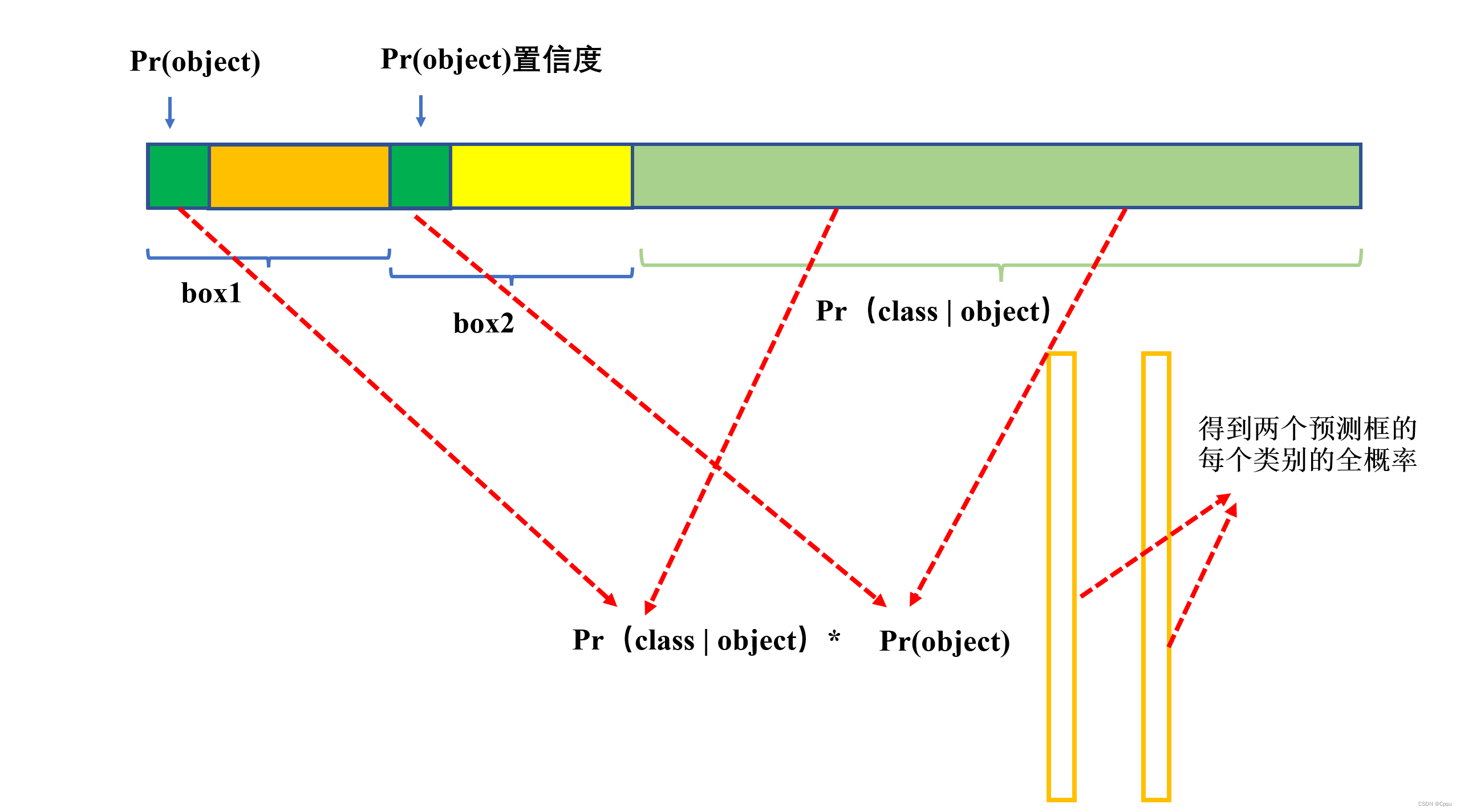
这个设计也是YOLO的缺点所在,由于两个预测框共用一个条件类别概率,所以导致结果一个Grid Cell只能预测一个类别。如果一个Grid Cell里面出现两类物体,即使有两个预测框,但是也只会输出条件概率最大的那一类。这也是YOLO在小目标检测上不好的原因。不过后续的YOLO版本改进了这个缺点,每个预测框都单独有一个类别概率。
总结
You Only Look Once!
![[Vue组件及组件之间的通信]一.Vue脚手架的使用;二.Vue的组件和组件之间的通信](https://img-blog.csdnimg.cn/img_convert/3618c9e034e3c89a55050983e72e9ea2.png)