计算的中间结果会写到 HDFS,如果用户写的SQL 有问题。如用户的 SQL 如下:
select * from A join B where a.dt=20230101 and b.dt=20230101,如 A 表 dt=20230101 分区 1000万行,B 表 dt=20230101 有 1万行记录。由于 SQL 没有关联条件,结果有1000亿行。
1.排查过程
1.1 先确定SQL queryId
hadoop fs -du -s -h /tmp/hive/*, 找到哪个用户的SQL 占用的多。
然后一级一级的查询。
如找到以下目录比较大
hdfs://bmr-master-479c2fa:8020/tmp/hive/hive/7809bfaf-c225-4c1d-bb58-1f8913f8a960/hive_2023-01-05_15-10-10_783_5535354154485458824-3
从 hive_2023-01-05_15-10-10_783可以确定这个 SQL 是 2023-01-05 15:10:10 提交的。
2. 根据用户执行的方式,找到对应的 SQL
2.1 jdbc 连接 hive-server 执行的方式
因为不知道连接的哪台 hive-server,所以需要到所有的 hive-server 上查询日志。
cd /mnt/bmr/log/hive
根据任务的时间确定哪个日志文件,当前日志文件为 hiveserver2.log。也有可能日志文件写到阈值,已经压缩为 hiveserver2.log.2023-01-05_${xxx}.gz,其中 KaTeX parse error: Expected group after '_' at position 64: ….log.2023-01-05_̲{xxx}.gz 文件里,拷贝到临时目录,使用 gunzip hiveserver2.log.2023-01-05_${xxx}.gz 进行解压。
根据 hive_2023-01-05_15-10-10_783_5535354154485458824-3,找到以下日志,SQL 为 “select count(1) from store_sales”.
2023-01-05T15:10:12,044 INFO [HiveServer2-Background-Pool: Thread-451]: ql.Driver (:()) - Executing command(queryId=hive_20230105151010_fd576219-fae0-4a48-93bd-eda63a40e3bd): select count(1) from store_sales
2023-01-05T15:10:12,044 INFO [HiveServer2-Background-Pool: Thread-451]: ql.Driver (:()) - Query ID = hive_20230105151010_fd576219-fae0-4a48-93bd-eda63a40e3bd
2023-01-05T15:10:12,044 INFO [HiveServer2-Background-Pool: Thread-451]: ql.Driver (:()) - Total jobs = 1
2023-01-05T15:10:12,044 INFO [HiveServer2-Background-Pool: Thread-451]: ql.Driver (:()) - Launching Job 1 out of 1
2023-01-05T15:10:12,044 INFO [HiveServer2-Background-Pool: Thread-451]: ql.Driver (:()) - Starting task [Stage-1:MAPRED] in serial mode
2023-01-05T15:10:12,049 INFO [HiveServer2-Background-Pool: Thread-451]: ql.Context (:()) - New scratch dir is hdfs://bmr-master-479c2fa:8020/tmp/hive/hive/7809bfaf-c225-4c1d-bb58-1f8913f8a960/hive_2023-01-05_15-10-10_783_5535354154485458824-3
2.2 以 hive-cli 的方式
以 hive 命令执行,则需要到执行的服务器。
cd /mnt/bmr/log/hive/hive
有可能在当前文件 hive.log,也有可能在 hive.log.2023-01-04_${xxx}.gz。和 hive-server 的查找方式一样。
2.3 不知道用户的执行方式,或者不知道在哪台服务器上以 hive 的命令执行
打开 ResourceManager 找到当时时间段执行的任务。如果找不到,则打开 timeline-server 找到当时时间段执行的所有任务。
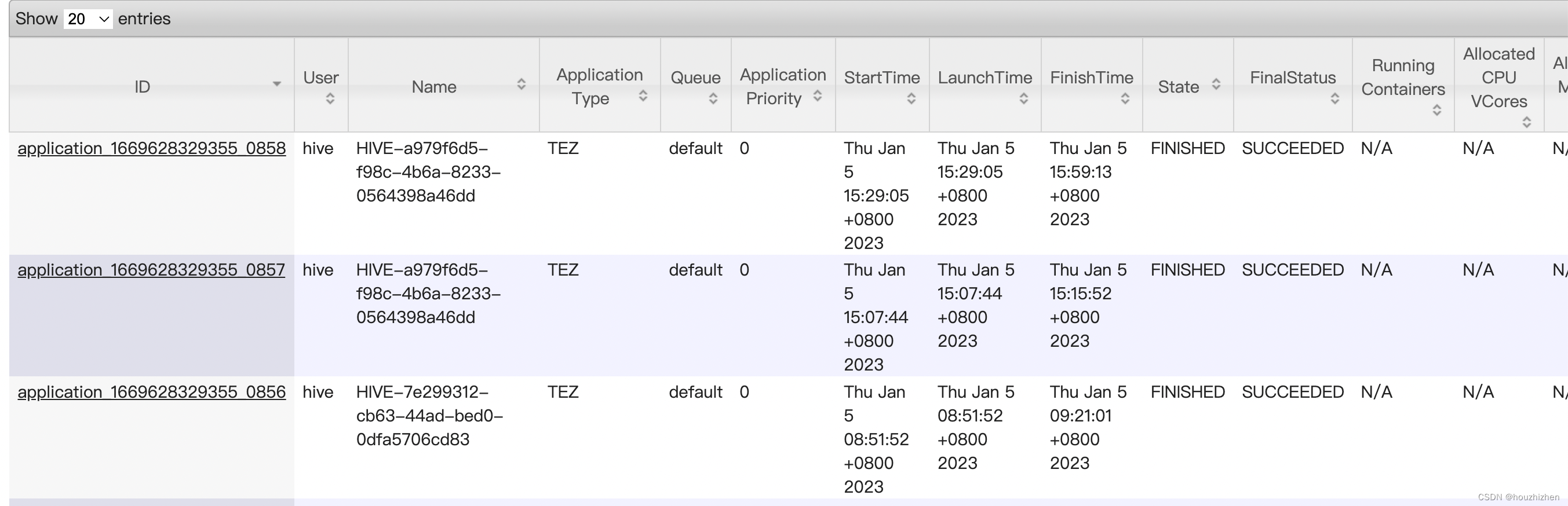
query 对应的时间在开始时间和结束时间之间的 application 都需要查看。点开 application,进入以下界面。
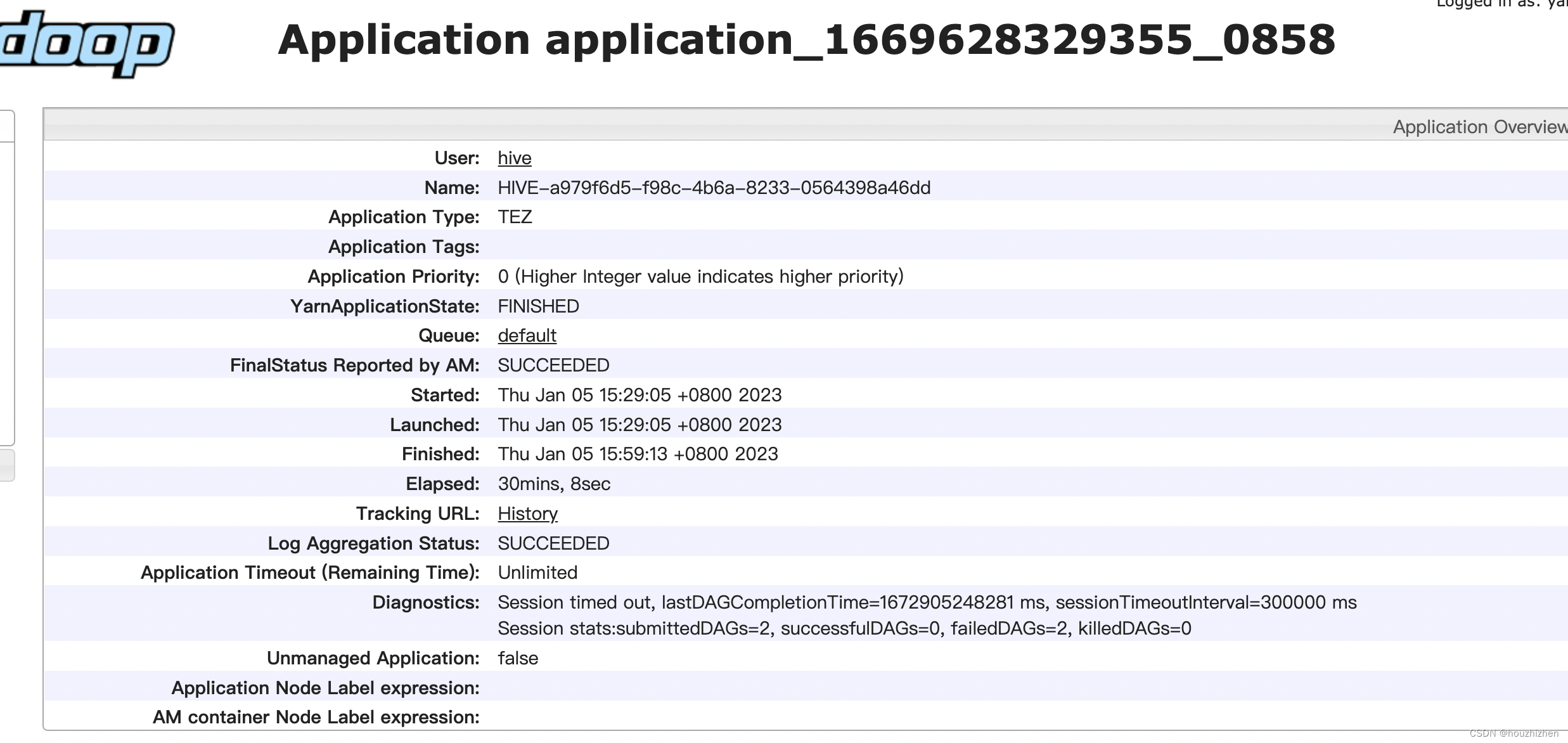
点击 History,进入 tez-ui 界面。
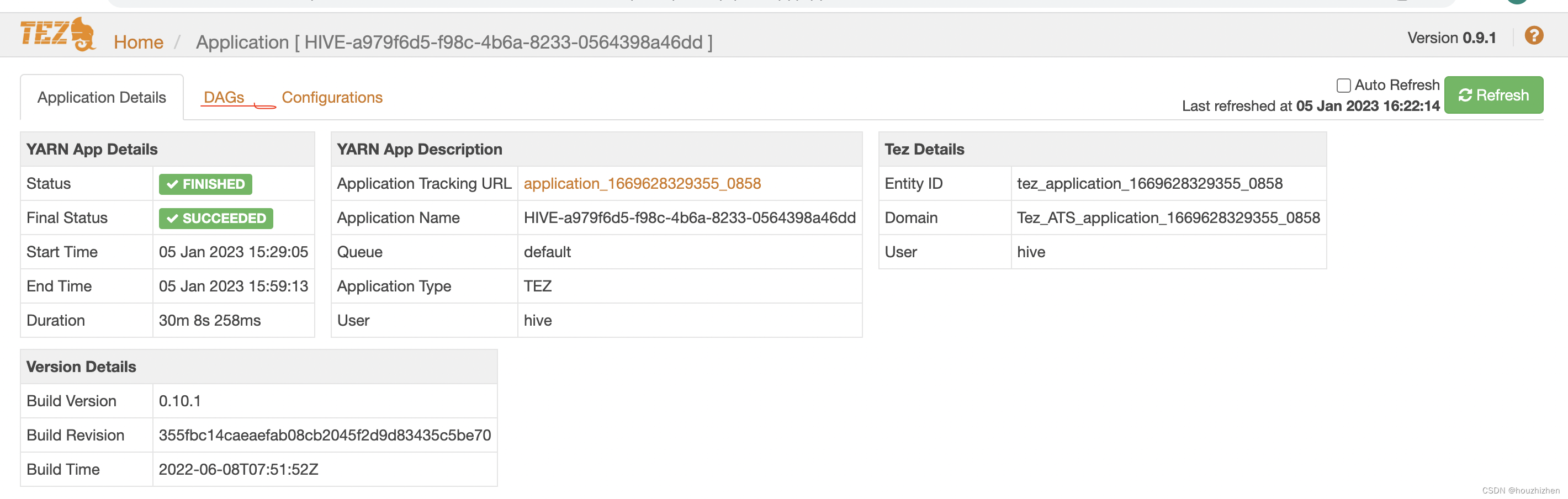
点击 DAGs,进入以下页面。
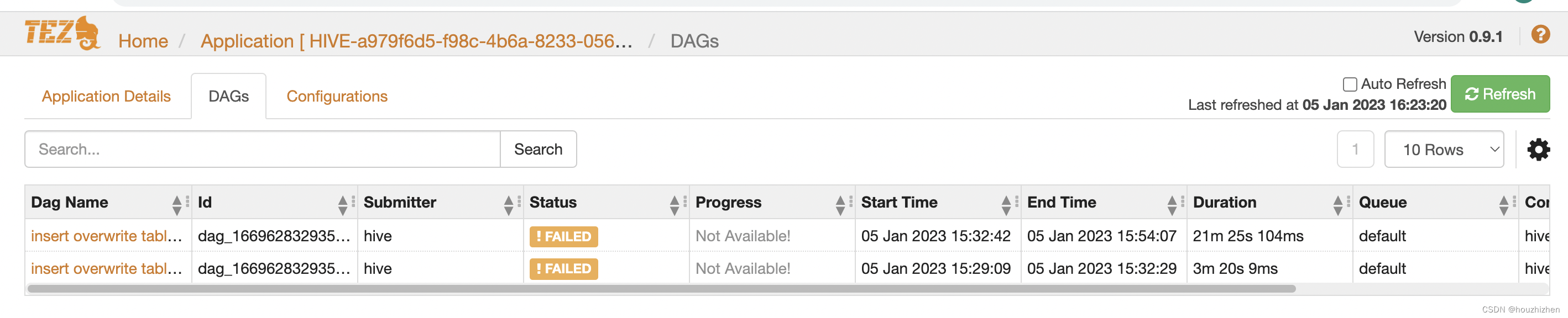
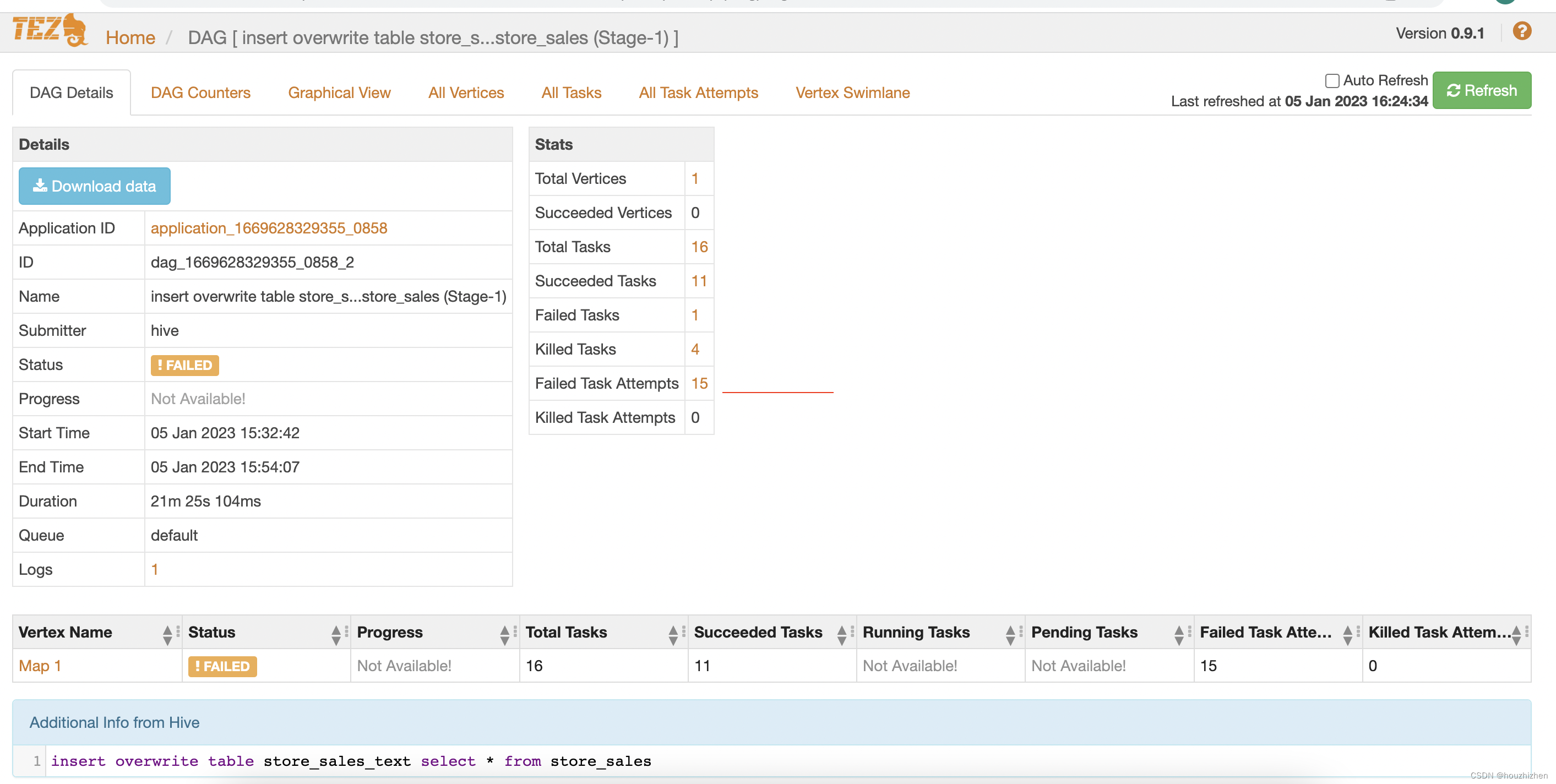
每行都是一个SQL,点击Dag Name 下面的链接,进入页面如下:
最下面 “Additional Info from Hive” 部分,显示完整的 SQL,查看是否有问题。
![[Vue组件及组件之间的通信]一.Vue脚手架的使用;二.Vue的组件和组件之间的通信](https://img-blog.csdnimg.cn/img_convert/3618c9e034e3c89a55050983e72e9ea2.png)