原文链接:
A Gentle Introduction to Graph Neural Networks (distill.pub)
我们不仅仅关系整个图的架构,其实我们更关心的是每个顶点每条边和整个图所表示的信息。

我们如何把我们想要的信息表示成以上这些向量,以及这些向量是否能够通过数据来学到。
这也是整个图神经网络要关注的重点。
一、数据如何表示成图
如何把一张图片表示成图,假如我们有一张图,其高宽都是244.然后有三个通道(RGB),一般来说我们会把他表示为有三个维度的Tensor。我们在输入我们的神经网络的时候用的是一个Tensor,但是从另外一个角度来说,我们可以将其当做是一个图,其每一个像素,是一个点,如果一个像素跟其是邻接关系的话,我们就连条边。

上边这个图片就是我们如何把一张图片表示成一个图。
左边是我们的图片,右边是我们表示成的邻接矩阵,(0-0)表示的图的第0列第0行,图上对应也是(0-0)。第二列第二行(2-2)对应的图上也是第二列第二行(2-2)。这样我们把图片上的每一个像素都映射成了图上面的一个点。

我们点一下像素会发现,左边右边对角线认成了自己的邻居

中间的话,有八个邻居

中间的这个图是邻接矩阵,每一行和每一列都是一个顶点,如果第i行和第j列之间,值为1的话,记为蓝色,白色没有边。
那我们如何把文本表示成图呢?
文本可以认为是一条序列,我们可以把其中每一个词,表示成一个顶点,一个词和下一个词之间有一条有向边

我们把数据表示成图之后, 我们在图上可以定义什么样的问题?
主要有三大类问题,一个是在图层面的,一个顶点层面,一个是边层面。
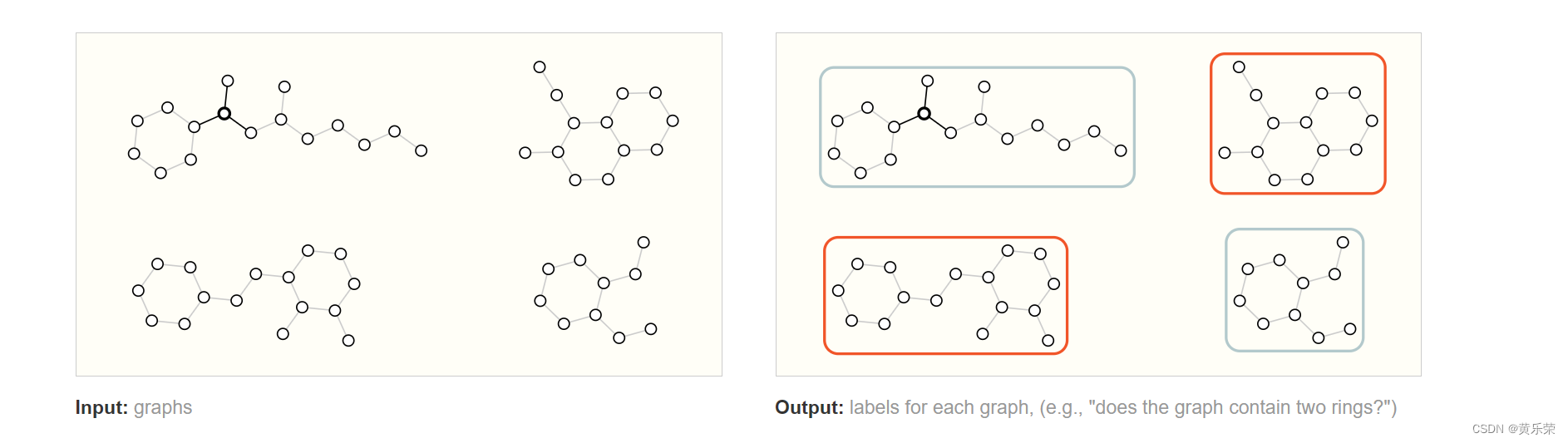
图层面
给我们一个图,我们对图进行分类。
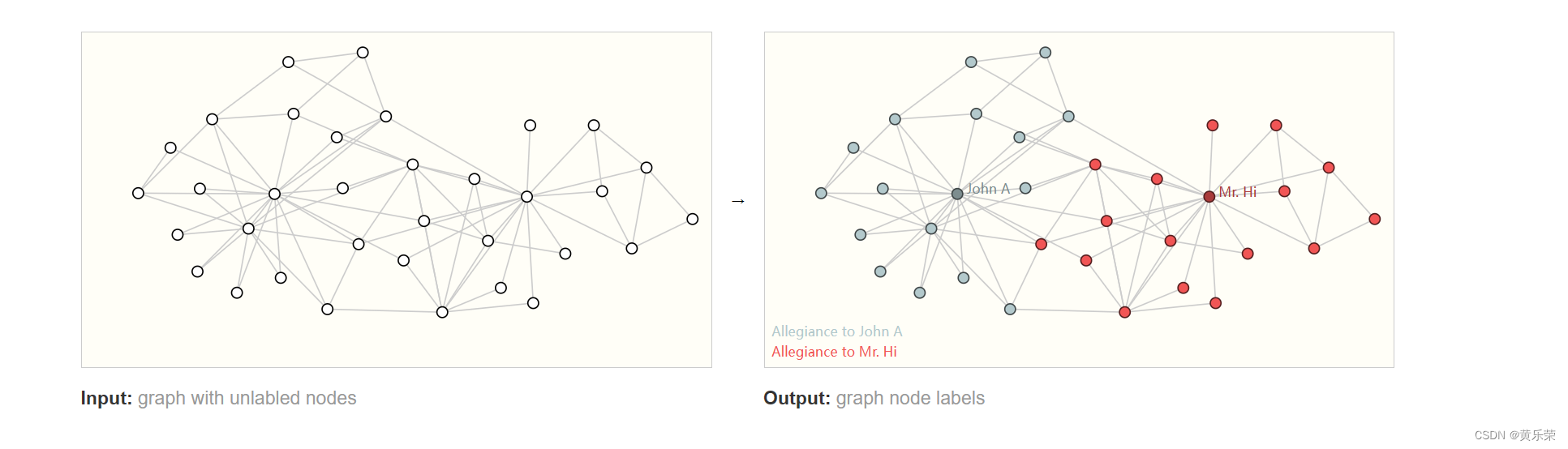
顶点层面:
一个俱乐部的A和B老师决裂了,分成了两大派系,各个顶点是站队A还是站队B。
 边层面
边层面
给一个图片,我们首先通过语义分割把图片里面的人物,背景都拿出来之后,然后这个人物之间是什么关系,顶点有了,我们主要学习顶点之间边的属性是什么。

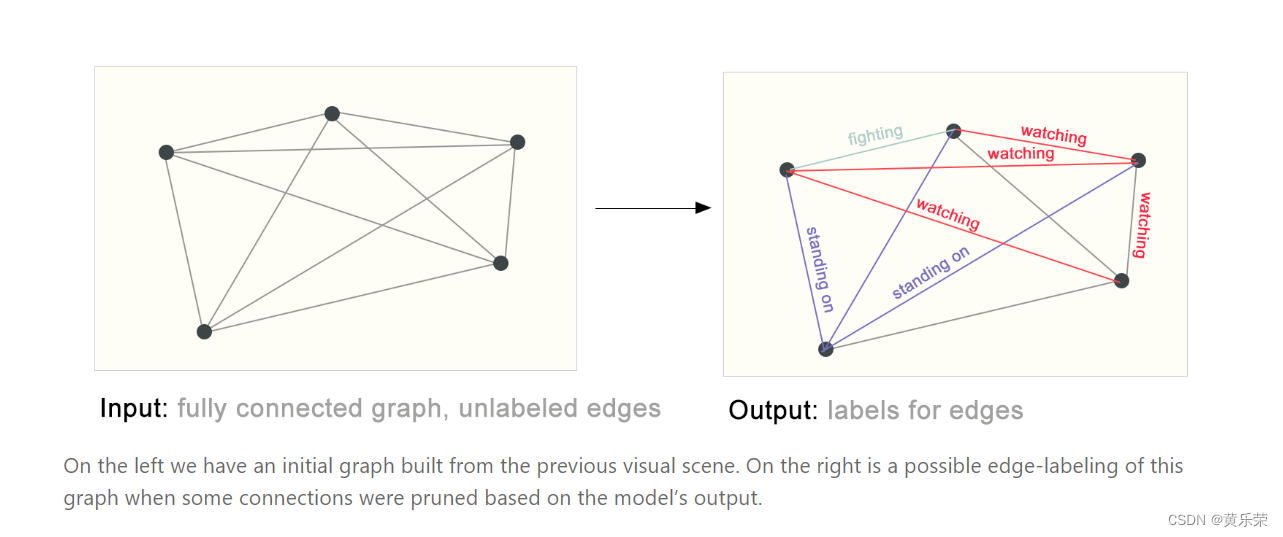
将机器学习用在图上会遇到什么样的挑战?
核心问题是:如何表示我们的图使得它可以和我们的神经网络是兼容的。
图上有四种信息:顶点的属性、边的属性、全局的一些信息、以及连接性(每条边连接的是哪两个点)
前三个我们都可以使用向量来表示。问题在于我们表示连接性?
连接性我们当然可以使用我们之前提到的邻接矩阵来表示,但是,可能会有问题:
第一个问题:这个矩阵可能会非常的大,当然我们可以使用稀疏矩阵,但是稀疏矩阵进行高效计算是一个比较难的事情。特别是将稀疏矩阵用在GPU上面。一直是一个比较难的基础问题。
第二个问题:我们的邻接矩阵,我们把任意行和任意列的顺序进行交换,都不会影响到它。

视觉上看着是不一样,但是实际表示同一个东西。
这意味着我们如果设计一个神经网络,不管是用左边的还是右边的,放弃神经网络之后,我们都需要保证我们最后得到的结果是一样的,因为其表示的是同一张图片。
如果我们又想要存储高效,又想我们整个排序不会影响到我们的话,我们可以使用下面这个存储方法。
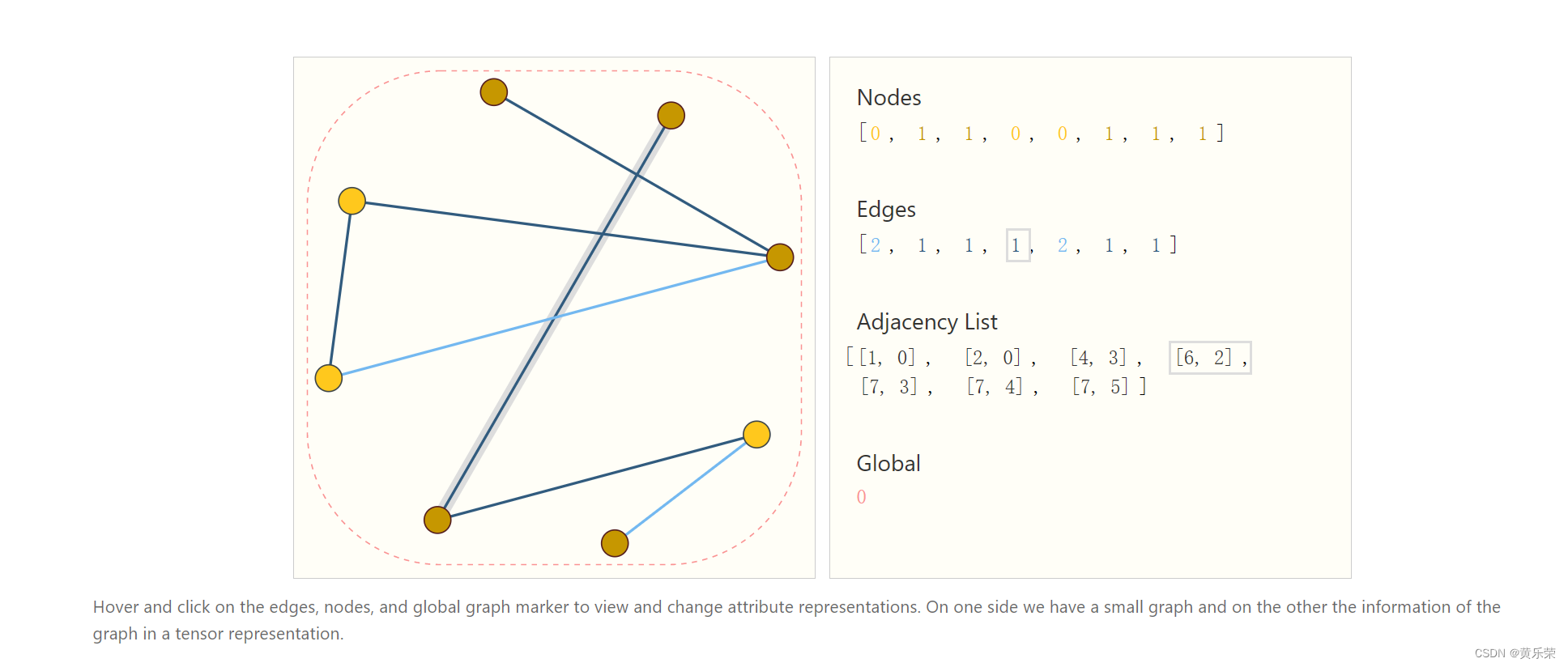
我们有8个顶点,7条边,每个点的属性用的是一个标量来表示,我们换成向量也并不影响,每条边也是用一个标量来表示,也可以用向量,全局信息Global同理。
维护一个邻接列表,其长度和我们的边数是一样的,它的第i项表示的是第i条边它连接的哪两个节点。在存储上,只有把边和所有的属性存储下来,所以存储是高效的。且对于顺序是不在意的,我们可以把边的顺序任意打乱,只要我们把邻接列表的顺序也相应的变了就可以。顶点也可以打乱,同理对邻接列表进行相应更新即可。
这样,存储高效且对顺序无关。
我们给这样一个输入的形式,我们如何用神经网络对其进行处理?
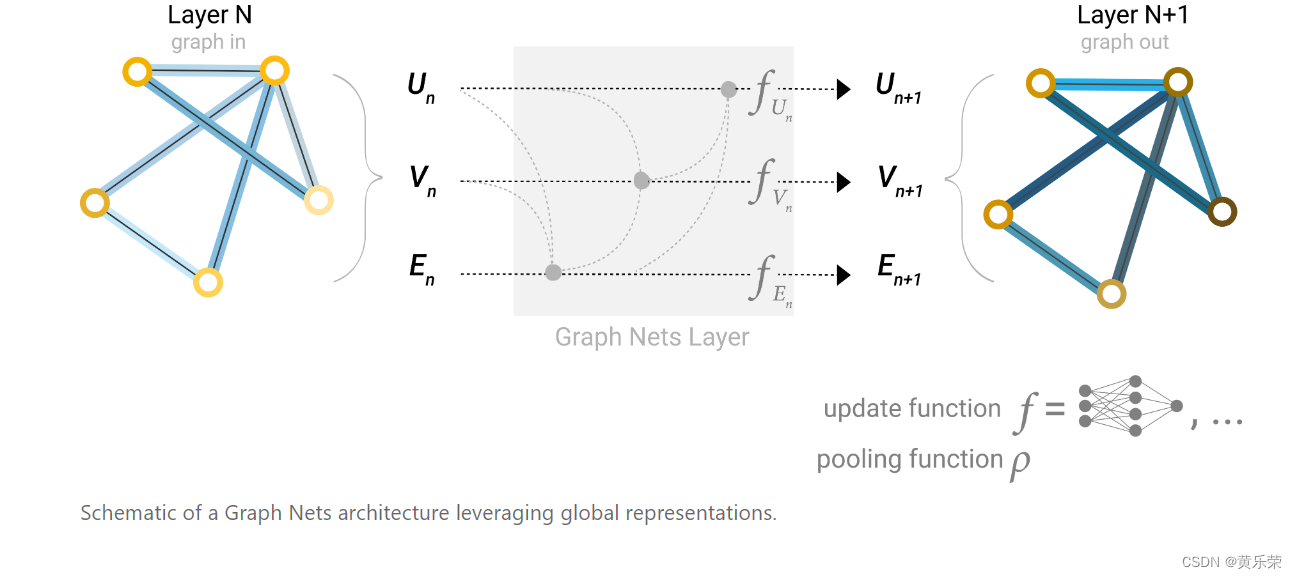
Graph Neural Networks(GNN)
GNN是一个对图上所有的属性,包括顶点、边和全局的上下文,进行一个可以优化的变换。这些变化可以保持住图的对称信息。所谓对称信息是,我们把顶点进行另外的排序之后,整个结果不会改变。GNN输入是一个图,输出也是一个图,会对属性(顶点、边和全局的向量)进行变换,但是不会改变图的连接性。
假设我们想对一个顶点做预测,但是这个顶点我们并没有他的向量,这个时候我们会用到一个技术叫做pooling(汇聚)。

以上图片便是最简单的GNN,给我们一个输入的图,首先进入一系列的GNN层,每一个层里有三个有三个MLP,对应三中不同的属性,逐一过去最后的输出会得到保持整个图结果的输出,但是里面所有的属性已经发生变化,然后根据我们要对哪些属性做预测,添加合适的输出层,缺失信息的话我们加入合适的汇聚层,便可以完成我们需要的一个预测。
虽然简单,但是有局限性,主要问题是GNN blocks步,我们并没有对其使用图的结构信息,我们对每个属性做变换的时候,是每个属性自己进入自己的MLP,并没有看到这个顶点是跟哪条边进行相连或者顶点相连,没有考虑到连接信息,没有将图的信息更新到我们的图里面,导致我们最后的结果可能是并不能够充分利用我们图的信息。
改进使其能够将图的信息放入进去
用到的技术是信息传递
假设我们需要对一个顶点的向量进行更新,之前我们的做法是把其向量直接拿过来进入到MLP,进行变换之后得到我们更新的向量。
但在信息传递里,我们将其向量和它邻居的向量都加在一起,得到一个汇聚的向量,把汇聚的向量再进入MLP就会得到我们一个点的向量的更新。
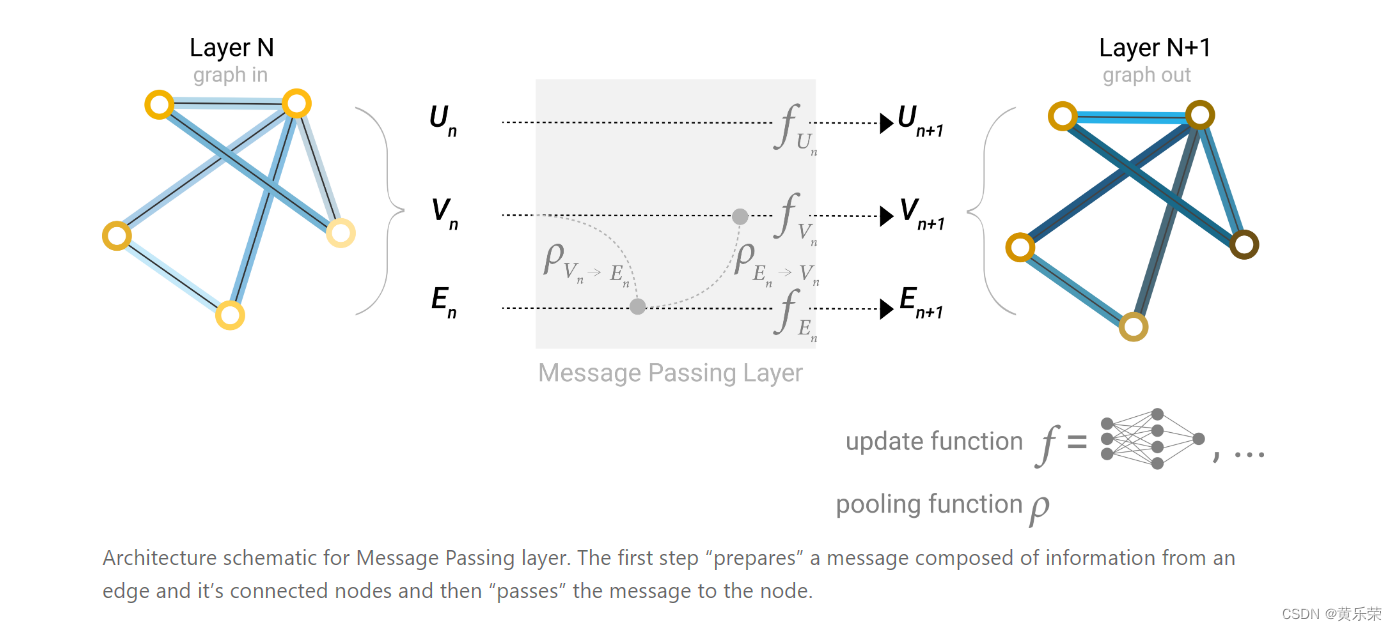

我们为何要有一个全局的信息?
之前我们每一次只看我们的邻居,假设我们的图真的比较大而且连接没有那么紧密的时候,会导致,一个消息从一个点传递到一个很远的点,需要走很多步才行。
一个解决方法是我们加入一个master node或者context vector的东西,这个点是一个虚拟的点,其可以跟所有的顶点相连,跟所有的边相连。