目录
摘要
Abstract
文献阅读:基于Transformer的时间序列生成对抗网络
现有问题
提出方法
相关前提
GAN(生成对抗网络)
Transformer
方法论
时间序列处理
TTS-GAN (基于Transformer的时间序列生成对抗网络)
研究实验
实验目的
数据集
评估标准
实验结果分析
文献贡献
模型代码
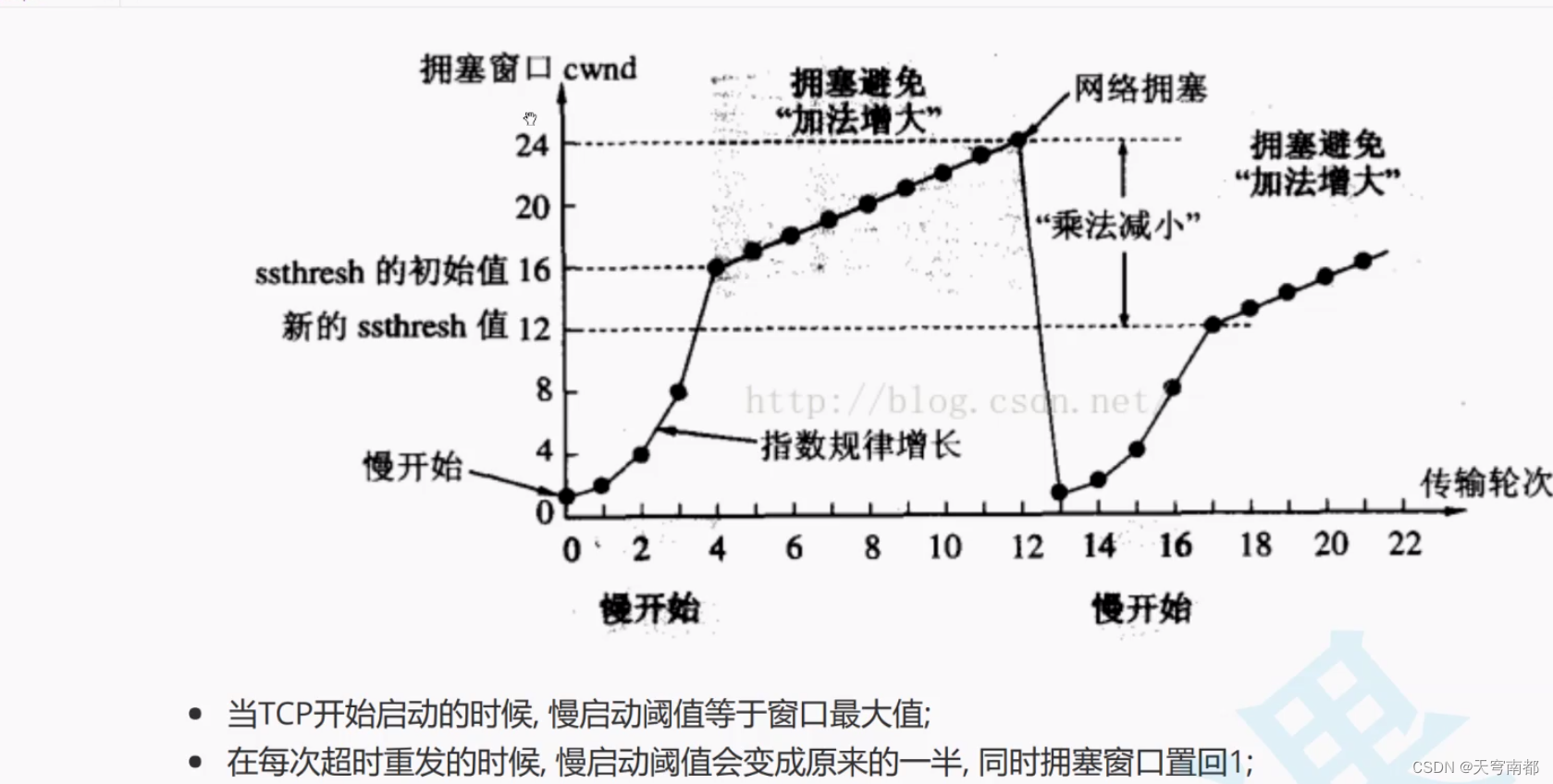
JS divergence不适合GAN优化
原始GAN中存在的两个问题
GAN的改进
Wasserstein distance
WGAN
总结
摘要
在本周阅读的文献中,提出了基于Transformer的GAN模型,GAN的生成器和鉴别器,都是基于Transformer的编码器架构构建的,通过处理图像的方式处理时间序列数据作为该模型的输入。该模型能够生成各种长度的多维时间序列数据,对原始信号模式和二维数据点分布的可视化比较显示了原始数据和合成数据的相似性。原始GAN的优化主要在于最小化真实分布和生成分布之间的js散度,而JS散度因其没有重叠则值不变的特性,导致GAN的优化存在梯度下降等问题。Wasserstein距离相比KL散度、JS散度,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。
Abstract
The literature read this week proposes a Transformer based GAN model. The generator and discriminator of GAN are both built on the encoder architecture of Transformer, processing time-series data as input to the model through image processing.This model can generate multidimensional time series data of various lengths, and the visual comparison of the original signal pattern and the distribution of two-dimensional data points shows the similarity between the original data and the synthesized data. The optimization of the original GAN mainly focuses on minimizing the JS divergence between the true distribution and the generated distribution, while the JS divergence, due to its non overlapping nature, remains unchanged, resulting in gradient descent and other problems in the optimization of GAN. Compared to KL divergence and JS divergence, Wasserstein distance can still reflect their distance even if the two distributions do not overlap.
文献阅读:基于Transformer的时间序列生成对抗网络
TTS-GAN: A Transformer-based Time-Series Generative Adversarial Network
https://arxiv.org/pdf/2202.02691v2.pdf
现有问题
- 时间序列形式出现的信号测量是机器学习应用中最常用的数据类型之一,然而这些数据集通常很小,使得深度神经网络架构的训练无效。深度学习模型需要大量数据才能成功训练,在小数据集上训练具有大量可训练参数的深度学习模型会导致过度拟合和低泛化能力。
- 在此之前GAN创建时间序列主要依赖于基于递归神经网络(RNN)的架构,而RNN存在梯度消失等问题,在时间序列数据上表现得不尽人意。
提出方法
- 采用图像处理的方式来处理时间序列数据,将一个时间序列数据,看作是一个高度等于1的图像。
- 引入了TTS-GAN,一种基于Transformer的GAN,GAN模型的产生器网络和鉴别器网络均采用纯Transformer编码器结构构建。Transformer最初是为了处理非常长的序列数据而发明的,并且没有梯度消失问题,可以成功地生成与真实时间序列相似的任意长度的真实合成时间序列数据序列。
相关前提
GAN(生成对抗网络)
GAN相关的知识在第四十周周报:第四十周:文献阅读+GAN-CSDN博客
对于时间序列生成任务而言,GAN由生成器和鉴别器两种模型组成。这两个模型通常由神经网络实现,但它们可以用任何形式的可微系统实现,将数据从一个空间映射到另一个空间。在TTG-GAN模型生成时间序列数据任务中,生成器试图捕获真实示例的分布,以生成新的数据示例。鉴别器通常是一个二元分类器,尽可能准确地将生成的示例与真实示例区分开来。GAN的优化是一个极大极小优化问题,其目标是使生成器和鉴别器相互对抗直到达到平衡。然后,可以认为生成器捕获了真实示例的真实分布。
Transformer
Transformer相关的知识在第三十九周周报:第三十九周:文献阅读+Transformer-CSDN博客
Transformer是最先进的神经网络架构。与循环神经网络不同的是,在Transformer网络中,整个序列被馈送到Transformer模块的各个层中。然后通过关注前一层中所有其他token的潜在表示来计算这一层token 的表示。而所处理的多维时间序列数据在文本和图像上都具有相似性,这意味着一个序列同时包含了时间和空间信息。序列中的每个时间步就像一张图像上的一个像素。整个序列包含一个事件或多个事件发生,这类似于NLP任务中的一个句子。
方法论
时间序列处理
利用处理图像的方法来处理时间序列数据,可以将一个时间序列数据,看作是一个高度等于1的图像。时间步长是图像的宽度W,一个时间序列序列可以有一个单通道或多个通道,这些通道可以被看作是一个图像的通道数(RGB) c,因此输入序列可以用大小矩阵(Batch Size,C,1,W),然后选择一个patch大小为N,将序列划分为。然后,我们在每个patch的末尾添加一个软位置编码值,该位置值在模型训练过程中学习。因此,识别器编码器块的输入将具有数据形状(Batch Size,C,(W=N) + 1)。
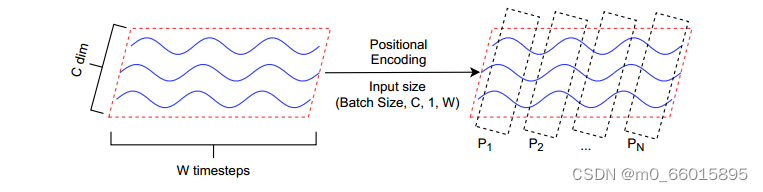
时序数据处理
TTS-GAN (基于Transformer的时间序列生成对抗网络)
TTS-GAN包含两个主要组件,一个生成器和一个鉴别器,都是基于Transformer的编码器架构构建的。其中编码器是由两个复合块组成的。第一块由多头自注意模块构成,第二块由具有GELU激活函数的前馈MLP构成。在两个块之前应用规范化层,在每个块之后添加dropout层,两个块都使用残余连接。
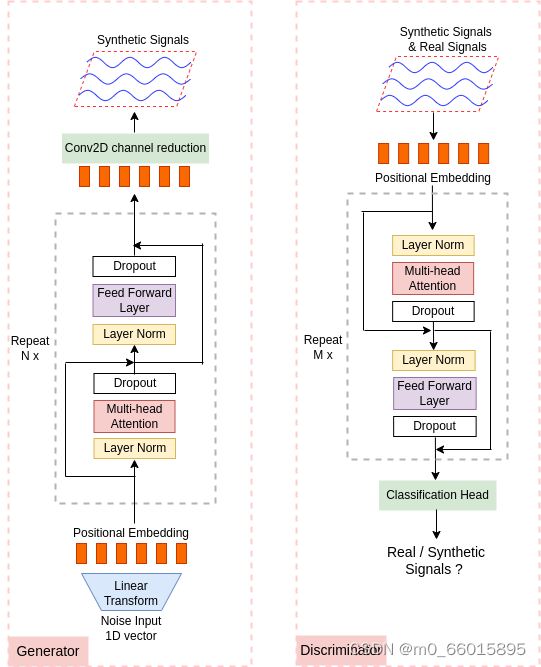
生成器模块的流程为:
- 生成器首先接收一个一维向量,其中N个均匀分布的随机数值在(0,1)范围内,即
。N表示合成信号的潜在维数,是一个可调的超参数。
- 然后将向量映射到具有相同实际信号长度和M嵌入维数的序列,其中M也是一个可以改变的超参数;
- 接下来,将序列划分为多个patch,并在每个patch中添加一个位置编码值。
- 这些补丁然后被输入到Transformer的编码器块;
- 然后将编码器块输出通过Conv2D层传递,以降低合成数据的维数(Conv2D层设置为内核大小(1;1),不会改变合成数据的宽度和高度。)
鉴别器架构类似一种二值分类器,用于区分输入序列是实信号还是合成信号。在TTS-GAN中,将任何输入序列视为高度为1的图像,输入的时间步长是图像宽度。因此,要在时间序列输入上添加位置编码,我们只需要将宽度均匀地分成多个片段,保持每个片段的高度不变。
研究实验
实验目的
使用PCA和t-SNE定性可视化和相似性得分定量指标来评估TTS-GAN,并将其与Time-GAN进行比较,研究TTS-GAN是否性能优于Time-GAN,以及合成时间序列数据的可行性。
数据集
采用了三个数据集,分别是模拟正弦波、UniMiB人类活动识别(HAR)数据集和PTB诊断心电图数据库。共使用10000个模拟正弦波来训练GAN模型。对于UniMiB数据库,从24个受试者的记录中选择2类(跳跃和跑步)样本来训练GAN模型,这两个类分别有600和1572个样本。PTB Diagnostic ECG数据集包含正常和异常两类人类心跳信号,分别有4046和10506个样本。
评估标准
使用定性可视化和定量指标来评估TTS-GAN
- 原始数据可视化:对比TTS-GAN生成的合成数据样本与真实数据;
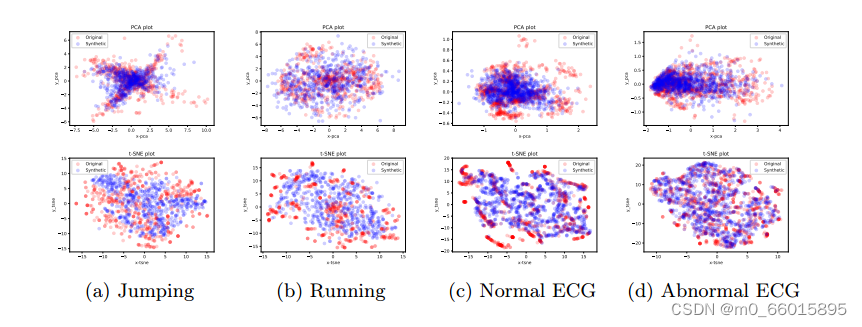
- 使用PCA和t-SNE进行可视化:进一步说明真实数据和合成数据之间的相似性;
- 相似性得分:定量比较真实序列和生成序列的相似度,定义了两个相似度分数,平均余弦相似度(avg_cos_sim)和平均Jensen-Shannon距离。。
实验结果分析
由于时间序列数据不容易被人类解释,使用PCA(主成分分析法)和t-SNE(用于高维数据降维到2维或者3维,并进行可视化)
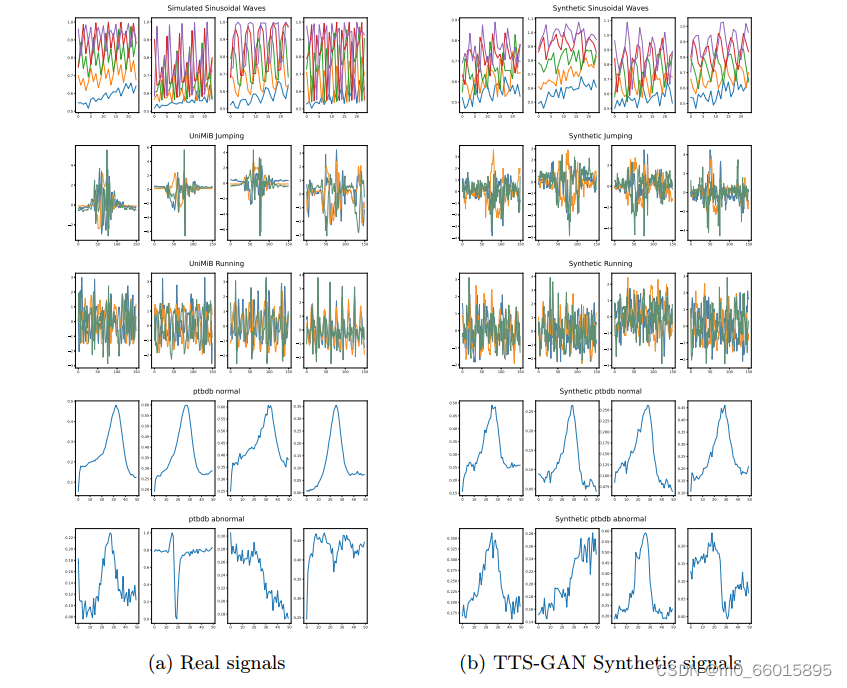
将多维输出序列向量映射到两个维度,直观地观察合成数据与真实数据实例分布的相似性。
为了进行更定量的比较,我们还测量了几个众所周知的信号特性,并将变压器生成的序列和rnn生成的序列与同类真实序列的相似性进行了比较。
- avg_cos_sim测量所有真实信号和同类合成信号之间的平均余弦相似度,接近1的值表示两个特征向量之间的相似性较高。
- avg_jen_dis是所有特征向量距离的平均值,值接近于零意味着一对信号彼此之间的距离较小,因此具有相似的分布。
两个相似度分数被用来定量地进一步验证合成数据的保真度。从实验结果可以看出,对于不同的信号类别,合成样本的平均余弦相似度较高,Jensen-Shannon距离较低。此外,TTS-GAN在10个案例中有7个战胜了Time-GAN。总的来说,当对真实样本进行训练时,TTS-GAN作为真实时间序列生成器可行性很高。

文献贡献
- 创建了一个纯粹的基于Transformer的GAN模型来生成合成时间序列数据。
- 提出了几种启发式方法来更有效地训练基于时间序列数据的Transformer的GAN模型。
- 将生成序列的质量与真实序列和其他最先进的时间序列GAN算法生成的序列进行定性和定量比较。
模型代码
生成器模块
生成器接收一维的输入向量,然后将向量映射到实际信号长度和M嵌入维数的序列,将序列划分为多个patch,并在每个patch中添加一个位置编码值。将添加了位置编码的向量输入到Transformer的编码器块;再将编码器块输出通过Conv2D层传递,以降低合成数据的维数
合成数据序列经过生成器的Transformer编码器层具有数据形状(隐藏维度,1,时间步长)将映射到(真实数据维度,1,步长)。通过这种方法,将随机噪声向量变换成与实际信号形状相同的序列。
class Generator(nn.Module):
def __init__(self, seq_len=150, patch_size=15, channels=3, num_classes=9, latent_dim=100, embed_dim=10, depth=3,
num_heads=5, forward_drop_rate=0.5, attn_drop_rate=0.5):
#定义了序列长度为150、批次大小为15、通道数为3、潜空间的维度为100,编码输出维度为10,深度为3、正则化参数为0.5
super(Generator, self).__init__()
self.channels = channels
self.latent_dim = latent_dim
self.seq_len = seq_len
self.embed_dim = embed_dim
self.patch_size = patch_size
self.depth = depth
self.attn_drop_rate = attn_drop_rate
self.forward_drop_rate = forward_drop_rate
self.l1 = nn.Linear(self.latent_dim, self.seq_len * self.embed_dim)
self.pos_embed = nn.Parameter(torch.zeros(1, self.seq_len, self.embed_dim))
#将Transformer的Encoder模块作为生成器的块,设置了深度、维度、正则化参大小等参数
self.blocks = Gen_TransformerEncoder(
depth=self.depth,
emb_size = self.embed_dim,
drop_p = self.attn_drop_rate,
forward_drop_p=self.forward_drop_rate
)
#定一个卷积层的容器
self.deconv = nn.Sequential(
#定义2维卷积层,卷积核的大小为1,卷积的步幅为1,padding为0
nn.Conv2d(self.embed_dim, self.channels, 1, 1, 0)
)
#前向传播层,输入一个张量z
def forward(self, z):
#经过一层全连接层self.11后,将输出的张量x通过view函数变为三维张量
x = self.l1(z).view(-1, self.seq_len, self.embed_dim)
x = x + self.pos_embed #添加位置编码
H, W = 1, self.seq_len
x = self.blocks(x)
#将x的维度变为x.shape[0]*1*x*shape[1]*x.shape[2]
x = x.reshape(x.shape[0], 1, x.shape[1], x.shape[2])
#permute函数:将指定的矩阵维度进行重新排序,将x的维度排序为[x.shape[0],x.shape[2],1,x.shape[1]]
#deconv:反卷积函数
output = self.deconv(x.permute(0, 3, 1, 2))
#再将output通过view函数变为四维张量
output = output.view(-1, self.channels, H, W)
return output生成器中的transformer的Encode模块
其中Encode模块由两个复合块组成,第一个由多头注意力和add&Norm层组成,一个是add代表的残差结构,一个是Norm代表的归一化。第二个由全连接层和add&Norm层组成。
在两个块之前应用规范化层,在每个块之后添加dropout层。两个块都使用残余连接。
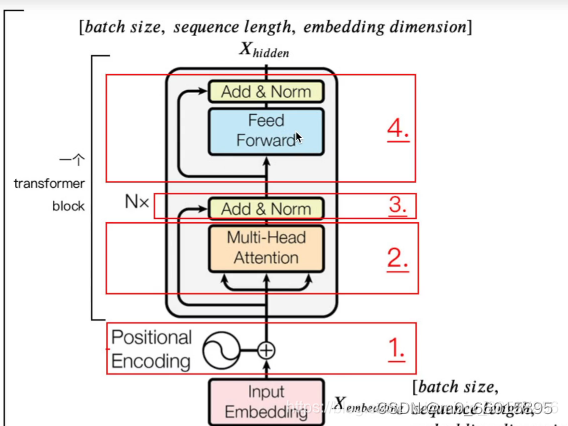
#encode模块
class Gen_TransformerEncoderBlock(nn.Sequential):
def __init__(self,
emb_size,
num_heads=5,
drop_p=0.5,
forward_expansion=4,
forward_drop_p=0.5):
super().__init__(
#两个复合模块
ResidualAdd(nn.Sequential(
#规范层
nn.LayerNorm(emb_size),
#多头注意力
MultiHeadAttention(emb_size, num_heads, drop_p),
#残余连接
nn.Dropout(drop_p)
)),
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
FeedForwardBlock(
emb_size, expansion=forward_expansion, drop_p=forward_drop_p),
nn.Dropout(drop_p)
)
))
#Encoder层由depth个Encode模块组成
class Gen_TransformerEncoder(nn.Sequential):
def __init__(self, depth=8, **kwargs):
super().__init__(*[Gen_TransformerEncoderBlock(**kwargs) for _ in range(depth)]) 辨器中的Transformer的Encoder模块(与生成器中的一样)
class Dis_TransformerEncoderBlock(nn.Sequential):
def __init__(self,
emb_size=100,
num_heads=5,
drop_p=0.,
forward_expansion=4,
forward_drop_p=0.):
super().__init__(
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
MultiHeadAttention(emb_size, num_heads, drop_p),
nn.Dropout(drop_p)
)),
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
FeedForwardBlock(
emb_size, expansion=forward_expansion, drop_p=forward_drop_p),
nn.Dropout(drop_p)
)
))
class Dis_TransformerEncoder(nn.Sequential):
def __init__(self, depth=8, **kwargs):
super().__init__(*[Dis_TransformerEncoderBlock(**kwargs) for _ in range(depth)])
多头注意力模块
多头注意力就是在多个不同的投影空间中建立不同的投影信息,将输入矩阵,进行不同的投影,得到许多输出矩阵后,将其拼接在一起。
可以看出V K Q 是固定的单个值,而Linear层有3个,Scaled Dot-Product Attention 有3个,即3个多头;最后cancat在一起,然后Linear层转换变成一个和单头一样的输出值。
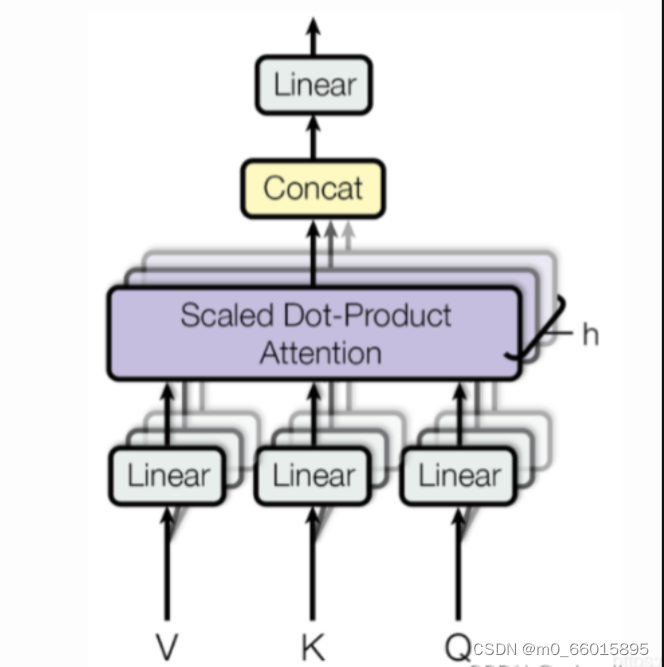
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size, num_heads, dropout):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
self.keys = nn.Linear(emb_size, emb_size)
self.queries = nn.Linear(emb_size, emb_size)
self.values = nn.Linear(emb_size, emb_size)
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x: Tensor, mask: Tensor = None) -> Tensor:
queries = rearrange(self.queries(x), "b n (h d) -> b h n d", h=self.num_heads)
keys = rearrange(self.keys(x), "b n (h d) -> b h n d", h=self.num_heads)
values = rearrange(self.values(x), "b n (h d) -> b h n d", h=self.num_heads)
# batch, num_heads, query_len, key_len
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys)
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
#缩放1/2
scaling = self.emb_size ** (1 / 2)
#softmax
att = F.softmax(energy / scaling, dim=-1)
att = self.att_drop(att)
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
return out
分类模块
class ClassificationHead(nn.Sequential):
#类别数为2,编码大小为100
def __init__(self, emb_size=100, n_classes=2):
super().__init__()
self.clshead = nn.Sequential(
Reduce('b n e -> b e', reduction='mean'),
#规范层
nn.LayerNorm(emb_size),
#线性层
nn.Linear(emb_size, n_classes)
)
def forward(self, x):
#多层感知机聚类头(CLSHead),预测样本属于某一类的概率
out = self.clshead(x)
return out
编码器
class PatchEmbedding_Linear(nn.Module):
#设置参数
def __init__(self, in_channels = 21, patch_size = 16, emb_size = 100, seq_length = 1024):
# self.patch_size = patch_size
super().__init__()
#在此处更改conv2d参数
self.projection = nn.Sequential(
Rearrange('b c (h s1) (w s2) -> b (h w) (s1 s2 c)',s1 = 1, s2 = patch_size),
nn.Linear(patch_size*in_channels, emb_size)
)
self.cls_token = nn.Parameter(torch.randn(1, 1, emb_size))
self.positions = nn.Parameter(torch.randn((seq_length // patch_size) + 1, emb_size))
def forward(self, x: Tensor) -> Tensor:
b, _, _, _ = x.shape
x = self.projection(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
#将cls标记前置到输入
x = torch.cat([cls_tokens, x], dim=1)
#加上位置编码
x += self.positions
return x
辨别器
包括三个模块:编码模块、transformer的encode模块、分类器模块
class Discriminator(nn.Sequential):
def __init__(self,
in_channels=3,
patch_size=15,
emb_size=50,
seq_length = 150,
depth=3,
n_classes=1,
**kwargs):
super().__init__(
PatchEmbedding_Linear(in_channels, patch_size, emb_size, seq_length),
Dis_TransformerEncoder(depth, emb_size=emb_size, drop_p=0.5, forward_drop_p=0.5, **kwargs),
ClassificationHead(emb_size, n_classes)
)
原始GAN的缺陷
JS divergence不适合GAN优化
在原始GAN优化过程中,鉴别器D的优化就是在求 与
的JS散度,而生成器G的优化就是在缩小
与
的JS散度。而使用JS散度优化存在两个问题:
- JS散度只有在随机生成分布与真实分布有不可忽略重叠的时候才不为0,生成器面临梯度消失问题。
- 最优判别器下等价于既要最小化生成分布与真实分布直接的KL散度,又要最大化其JS散度,相互矛盾,导致梯度不稳定;而且KL散度的不对称性使得生成器宁可丧失多样性也不愿丧失准确性,导致collapse mode现象。
JS散度只有在随机生成分布与真实分布有不可忽略重叠的时候才不为0,而和
有一个关键特性就是重叠部分非常少,有两个方面的原因(以生成图片为例):
- 从数据本身特性来说,
和
都是要产生图片,而图片就是在高维空间中一条低维的流行,以二维空间为例,那么图片的分布就是一条直线,因此重叠几乎可以忽略。
- 在计算Divergence的时候是不看

原始GAN中存在的两个问题
第一个问题:判别器越好,生成器梯度消失越严重

在最优辨别器的条件下(即固定辨别器),原始GAN生成器的优化(loss)等价变换为最小化真实分布与生成分布
之间的JS散度。因此我们会希望如果两个分布之间越接近它们的JS散度越小,我们通过优化JS散度就能将
“拉向”
。但只有在两个分布有所重叠的时候是成立的,如果两个分布完全没有重叠的部分,或者它们重叠的部分可忽略(下面解释什么叫可忽略),JS divergence特性就是两个分布没有重叠,那么算出来的divergence永远都是log2,这导致 Generator 无法知道训练是否带来结果的提升,训练学不到东西,因此导致梯度消失。
第二个问题:优化的另一种形式的生成器loss函数,等价于最小化一个不合理的距离衡量,既要最小化生成分布与真实分布直接的KL散度,又要最大化其JS散度,相互矛盾,导致两个问题,一是梯度不稳定,二是collapse mode即多样性不足。
一个要拉近,一个却要推远!在数值上则会导致梯度不稳定,这是JS散度项的问题。。

上面式子中的KL散度也有问题,KL散度不是一个对称的衡量
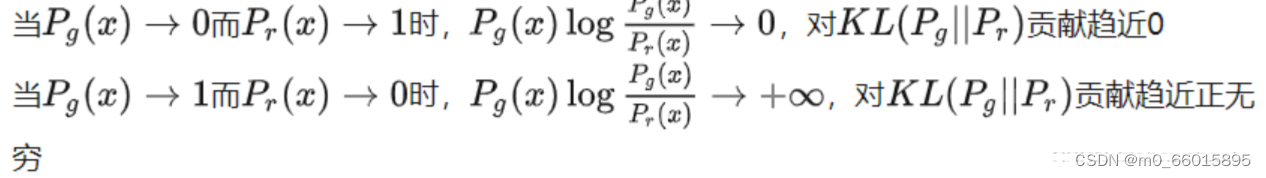
第一种错误对应的是“生成器没能生成真实的样本”,惩罚微小;第二种错误对应的是“生成器生成了不真实的样本” ,惩罚巨大。第一种错误对应的是缺乏多样性,第二种错误对应的是缺乏准确性。这一放一打之下,生成器宁可多生成一些重复但是很“安全”的样本,也不愿意去生成多样性的样本。这种现象就是大家常说的
GAN的改进
除了 JS divergence,还可以使用其它的 divergence,即设置discriminator不一样的目标函数。Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。
Wasserstein distance
Wasserstein distance就是将P推着移动到Q的平均距离,如何推动使得平均距离最小,这个最小的距离值就是Wasserstein distance。
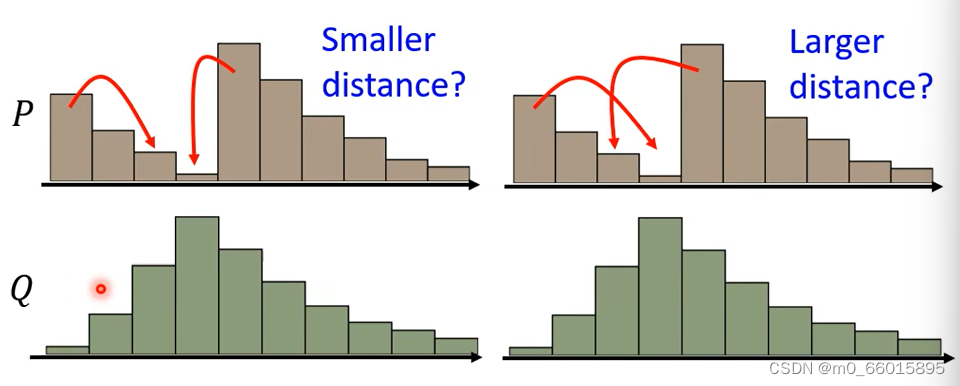
从JS divergence换到Wasserstein distance的好处:
假设可以计算Wasserstein distance的值,当使用Wasserstein distance来衡量divergence的时候,从
WGAN
用Wasserstein distance代替JS divergence的GAN 就叫做WGAN
Wasserstein distance的计算公式如下:
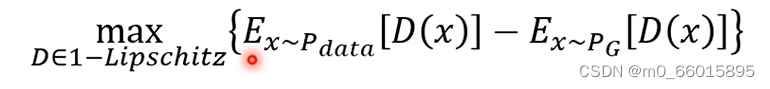
在WGAN中,对判别器D做出了限制,D必须满足1-lipschitz的条件,也可以理解为D必须是一个足够平滑的Function。
当和
没有重叠的时候,但两者相距很近的时候,要在
上得分很高,就会取到正无穷,在
取得分低就会到负无穷,那这个function的变化就会很大,D的训练就没办法收敛,因此在两组数据没有重叠的情况下,算出来的max值就会无限大。
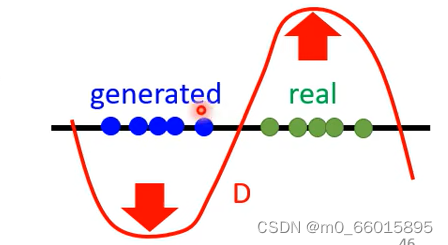
Q:为什么加上这个限制就可以解决无限大的问题?
A:这个限制是要求Discriminator不可以变化剧烈要平滑, 因此在两组数据挨得很近的时候,在平滑的限制下,real上的值不会非常大,generated上的值也不会特别小,因此计算得到的值就会比较小,这样的值才是Wasserstein distance。
WGAN中让判别器满足1-lipschitz的条件的方法其实相对较为简单,训练network的时候,更新参数后将权重w限制在c到-c之间,如下图所示:

WGAN与原始GAN第一种形式相比,只改了四点:
- 判别器最后一层去掉sigmoid(原始GAN是二分类任务,WGAN中判别器fw做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。)
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的参数w绝对值截断到不超过一个固定常数c
总结
| CNN(卷积神经网络) | |
|---|---|
| 原理 | CNN主要用于处理图像数据,通过卷积操作和池化操作来提取图像中的特征。 |
| 特点 | CNN的核心思想是局部感知,通过卷积核在输入数据上滑动来检测特征。 |
| 优点 | 1、适用于图像处理任务,如图像分类、目标检测等。 2、具有参数共享和稀疏连接,减少了参数数量。 |
| 缺点 | 1、对于不同尺寸的输入可能需要不同的架构。 2、不适用于序列数据,无法处理时序信息。 |
| RNN(循环神经网络) | |
|---|---|
| 原理 | 循环神经网络具有循环连接,可以处理序列数据,每个时间步的输出与上一个时间步的输出和当前时间步的输入相关。 |
| 特点 | RNN在处理时序数据时表现出色,适用于语言模型、文本生成等任务。 |
| 优点 | 1、能够捕捉时间依赖性,适用于序列数据。 2、具有参数共享,适用于变长输入数据。 |
| 缺点 | 1、长期依赖问题:难以捕捉长距离的时间依赖关系,容易出现梯度消失或梯度爆炸问题。 2、不适合并行化,训练速度较慢。 |
| Transformer | |
|---|---|
| 原理 | 依赖自注意力机制来捕获输入序列的全局依赖关系,其基本组成部分是编码器和解码器,其中编码器由多个相同的层堆叠而成,每一层都有两个子层构成:自注意力层和全连接层。解码器也有类似的结构,只是在自注意力层和全连接层之间添加了一个编码器-解码器注意力层。 |
| 特点 | 是一种避免循环的模型结构,完全基于注意力机制对输入输出的全局依赖关系进行建模。 |
| 优点 | 1、效果好 2、可以并行训练,速度快 3、很好地解决了长距离依赖的问题 |
| 缺点 | 完全基于self-attention,对于词语位置之间的信息有一定的丢失,虽然加入了positional encoding来解决这个问题,但也还存在着可以优化的地方。 |