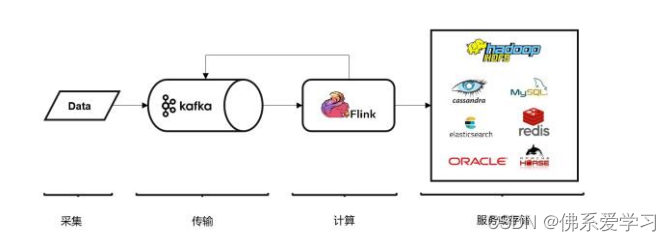
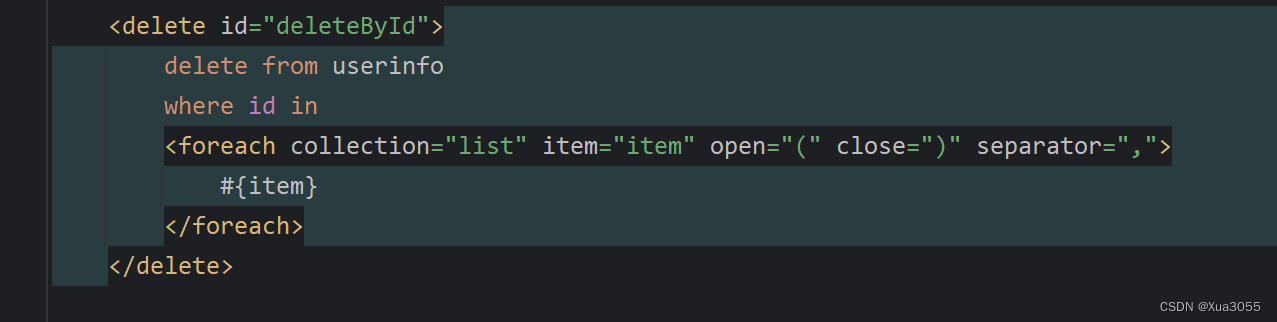
第 1 章:Spark概述
1.1 什么是spark
回顾:hadoop主要解决,海量数据的存储和海量数据的分析计算。
spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
1.2 hadoop与spark历史
hadoop的yarn框架比spark框架诞生的晚,所以spark自己也涉及了一套资源调度框架。
区别:
1、mr是基于磁盘的,spark是基于内存
2、mr的task是进程
3、spark的task是线程,在executor进程里执行的是线程
4、mr在container里执行(留有接口方便插入),spark在worker里执行(自己用,没有接口)
5、mr适合做一次计算,spark适合做迭代计算
1.3 hadoop与spark框架对比
1、hadoop mr框架
从数据源获取数据,经过分析计算,将结果输出到指定位置,核心是一次计算,不适合迭代计算。
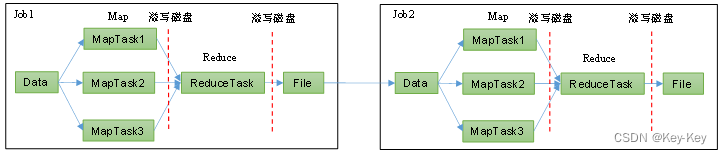
2、spark框架
spark框架计算比mr快的原因是:中间结果不落盘。注意spark的shuffle也是落盘的。

1.4 spark内置模块
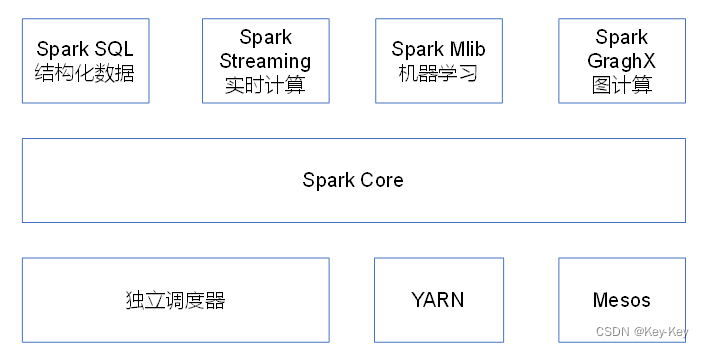
spark core:实现了spark的基本功能,包括任务调度、内存管理、错误恢复、与存储系统交互等模块。spark core中还包含了对弹性分布式数据集(resilient distributed dataset,简称rdd)的api定义。
spark sql:是spark用来操作结构化数据的程序包。通过spark sql,我们可以使用sql或者apache hive版本的hql来查询数据。spark sql支持多种数据源,比如hive表、parquet以及json等。
spark mllib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
spark graphx:主要用于图形并行计算和图挖掘系统的组件。
集群管理器:spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,spark支持在各种集群管理器(cluster manager)上运行,包括hadoop yarn、apache mesos,以及spark自带的一个简易调度器,叫做独立调度器。
1.5 spark特点
1、快:与hadoop的mapreduce相比,spark基于内存的运算要快上100倍以上,基于硬盘的运算也要快10倍以上。spark实现了高效的dag执行引擎,口头语通过基于内存来高效处理数据流。计算的中间结果是存在于内存中的。
2、易用:spark支持java、python和scala的api,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且spark支持交互式的python和scala的shell,可以非常方便地在这些shell种使用spark集群来验证解决问题的方法。
3、通用:spark提供了统一的解决方案。spark可以用于,交互式查询(spark sql)、实时流处理(spark streaming)、机器学习(spark mllib)和图计算(graphx)。这些不同类型的处理1都可以在同一个应用种无缝使用。减少了开发和维护的人力成本和部署平台的物力成本。
4、兼容性:spark可以非常方便地与其它地开源产品进行融合。比如:spark可以使用hadoop的yarn和apache mesos作为它的资源管理和调度器,并且可以处理所有hadoop支持的数据,包括hdfs、hbase等。这对于已经部署hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用spark的强大处理能力。
第 2 章:spark运行模式
部署spark集群大体上分为两种模式:单机模式与集群模式
大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。但是在生产环境种,并不会使用单机模式。因此,后续直接按照集群模式部署spark集群。
下面详细列举了spark目前支持的部署模式。
1、local模式:在本地部署spark服务
2、standalone模式:spark自带的任务调度模式。(国内常用)
3、yarn模式:spark使用hadoop的yarn组件进行资源和任务调度。(国内最常用)
4、mesos模式:spark使用mesos平台进行资源与任务的调度。(国内很少用)
2.2 local模式
local模式就是运行在一台计算机上的模式,通常就是用于在本机上练手和测试
2.2.1 安装使用
1)上传并解压spark安装包
[atguigu@hadoop102 sorfware]$ tar -zxvf spark-3.1.3-bin-hadoop3.2.tgz -C /opt/module/
[atguigu@hadoop102 module]$ mv spark-3.1.3-bin-hadoop3.2 spark-local
2)官方求pi案例
[atguigu@hadoop102 spark-local]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
可以查看spark-submit所用参数
[atguigu@hadoop102 spark-local]$ bin/spark-submit
–class:表示要执行程序的主类
–master local[2]“
(1)local:没有指定线程数,则所有计算都运行在一个线程当中,没有任何并行计算。
(2)local[k]:指定使用k个core来运行计算,比如local[2]就是运行2个core来执行
20/09/20 09:30:53 INFO TaskSetManager:
20/09/15 10:15:00 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
20/09/15 10:15:00 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
(3)local[*]:默认模式。自动帮你按照cpu最多核来设置线程数。比如cpu有8核,spark帮你自动设置8个线程。
20/09/20 09:30:53 INFO TaskSetManager:
20/09/15 10:15:58 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
20/09/15 10:15:58 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
20/09/15 10:15:58 INFO Executor: Running task 2.0 in stage 0.0 (TID 2)
20/09/15 10:15:58 INFO Executor: Running task 4.0 in stage 0.0 (TID 4)
20/09/15 10:15:58 INFO Executor: Running task 3.0 in stage 0.0 (TID 3)
20/09/15 10:15:58 INFO Executor: Running task 5.0 in stage 0.0 (TID 5)
20/09/15 10:15:59 INFO Executor: Running task 7.0 in stage 0.0 (TID 7)
20/09/15 10:15:59 INFO Executor: Running task 6.0 in stage 0.0 (TID 6)
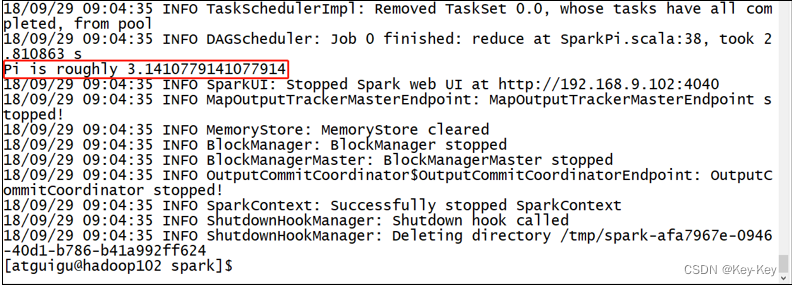
3)结果展示
该算法是利用蒙特-卡罗算法求pi
2.2.2 官方wordcount案例
1、需求:读取多个输入文件,统计每个单词出现的总次数。
2、需求分析
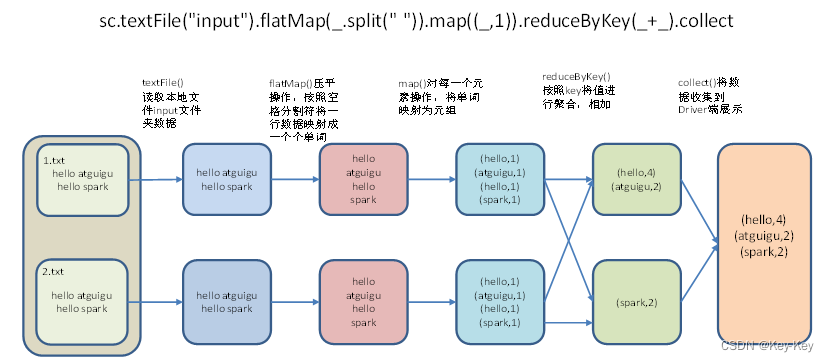
3、代码实现
1)准备文件
[atguigu@hadoop102 spark-local]$ mkdir input
在Input下创建2个文件1.txt和2.txt,并输入一下内容
hello atguigu
hello spark
2)启动spark-shell
[atguigu@hadoop102 spark-local]$ bin/spark-shell
20/07/02 10:17:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop102:4040
Spark context available as 'sc' (master = local[*], app id = local-1593656236294).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.3
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
注意:sc是sparkcore程序的入口;spark是sparksql程序入口;master=local[*]表示本地模式运行。
3)再开启一个hadoop102远程连接窗口,发现了一个sparksubmit进程
[atguigu@hadoop102 spark-local]$ jps
3627 SparkSubmit
4047 Jps
运行任务方式说明:spark-submit,是将jar上传到集群,执行spark任务;spark-shell,相当于命令行工具,本身也是一个application。
4)登录hadoop102:4040,查看程序运行情况
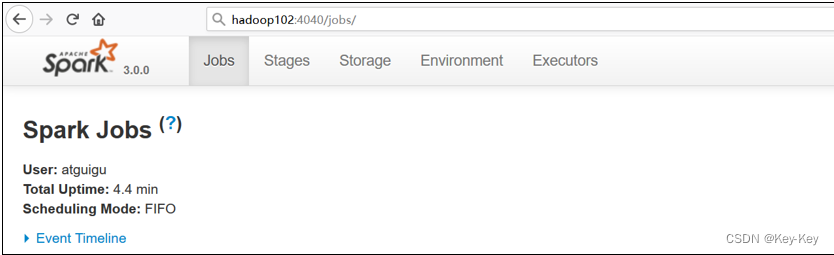
说明:本地模式下,默认的调度器为fifo。
5)运行workcount程序
scala>sc.textFile("/opt/module/spark-local/input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((hello,4), (atguigu,2), (spark,2))
注意:只有collect开始执行时,才会加载数据
可登录hadoop102:4040查看程序运行结果
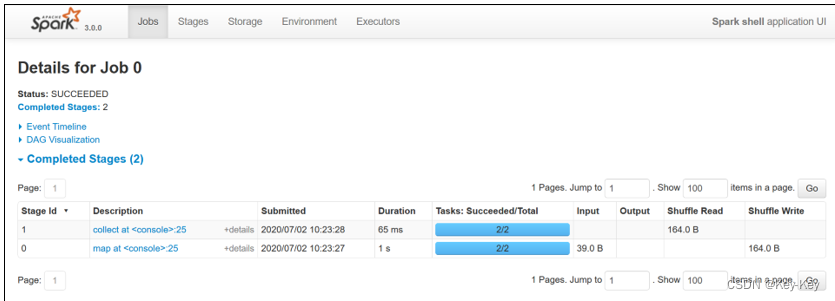
2.3 standalone模式
standalone模式是spark自带的资源调度引擎,构建一个由master+worker构成的spark集群,spark运行在集群种。
这个要和hadoop中的standalone区别开来。这里的standalone是指只用spark来搭建一个集群,不需要借助hadoop的yarn和mesos等其它框架。
2.3.1 master和worker集群资源管理
master:spark特有资源调度系统的leader。掌管着整个集群的资源信息,类似于yarn框架中的resourcemanager。
worker:spark特有资源调度系统的slave,有多个。每个slave掌管着所在节点的资源信息,类似于yarn框架中的nodemanager。
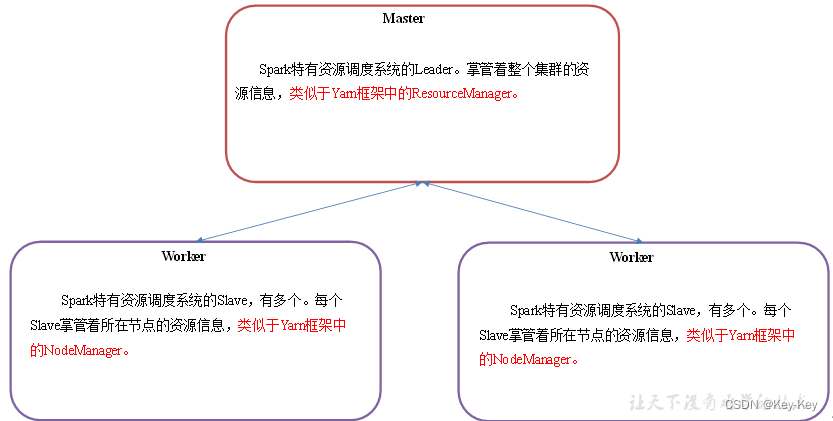
master和worker是spark的守护进程、集群资源管理者,即spark在特定模式(standalone)下正常运行必须要有的后台常驻进程。
2.3.2 driber和executor任务的管理者
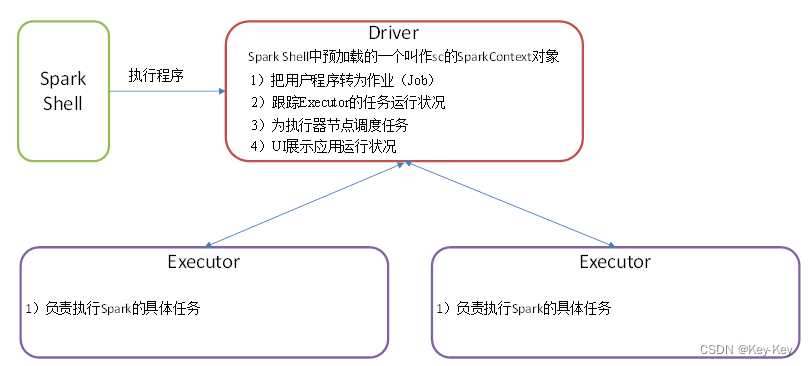
driver和executor是临时程序,当有具体任务提交到spark集群才会开启的程序。standalone模式是spark自带的资源调度引擎,构建一个由master+worker构成spark集群,spark运行在集群中。
这个要和hadoop中的standalone区别开来。这里的standalone是指只用spark来搭建一个集群,不需要借助hadoop的yarn和mesos等其它框架。
2.3.2 安装使用
1、集群规划

2、再解压一份spark安装包,并修改解压后的文件夹名称为spark-standalone
[atguigu@hadoop102 sorfware]$ tar -zxvf spark-3.1.3-bin-hadoop3.2.tgz -C /opt/module/
[atguigu@hadoop102 module]$ mv spark-3.1.3-bin-hadoop3.2 spark-standalone
3、进入spark的配置文件/opt/module/spark-standalone/conf
[atguigu@hadoop102 spark-standalone]$ cd conf
4、修改slave文件,添加work节点
atguigu@hadoop102 conf]$ mv slaves.template slaves
[atguigu@hadoop102 conf]$ vim slaves
hadoop102
hadoop103
hadoop104
5、修改spark-env.sh文件,添加master节点
[atguigu@hadoop102 conf]$ mv spark-env.sh.template spark-env.sh
[atguigu@hadoop102 conf]$ vim spark-env.sh
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=7077
6、分发spark-standalone包
[atguigu@hadoop102 module]$ xsync spark-standalone/
7、启动spark集群
[atguigu@hadoop102 module]$ xsync spark-standalone/
查看三台服务器运行进程(xcall.sh是以前数仓项目里面讲的脚本)
[atguigu@hadoop102 spark-standalone]$ xcall.sh jps
================atguigu@hadoop102================
3238 Worker
3163 Master
================atguigu@hadoop103================
2908 Worker
================atguigu@hadoop104================
2978 Worker
注意:如果遇见”Java_home not set“异常,可以在sbin目录下的spark-config.sh文件中加入如下配置
export JAVA_HOME=XXXX
8、网页查看:hadoop102:8080
9、官方求pi案例
[atguigu@hadoop102 spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
参数:–master spark://hadoop102:7077指定要连接的集群的master。
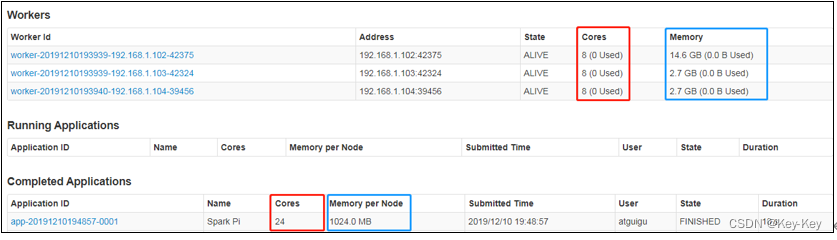
10、页面查看http://hadoop102:8080/,发现执行本次任务,默认采用三台服务器节点的总核数24核,每个节点内存1024M.
8080:master的webui
4040:application的webui的端口号
2.3.3 参数说明
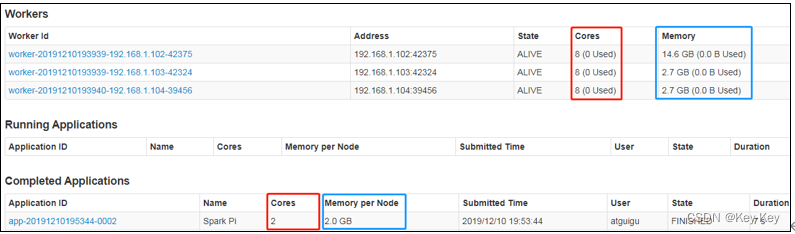
1、配置executor可用内存为2G,使用cpu核数为2个
[atguigu@hadoop102 spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 2G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
2、页面查看http://hadoop102:8080/
3、基本语法
bin/spark-submit \
--class <main-class>
--master <master-url> \
... # other options
<application-jar> \
[application-arguments]
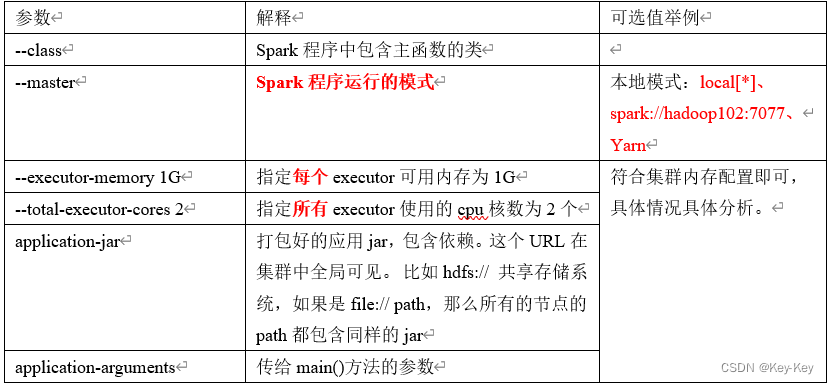
4、参数说明
2.3.4 配置历史服务
由于spark-shell停止掉后,hadoop102:4040页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况
1、修改spark-default.conf.template名称
[atguigu@hadoop102 conf]$ mv spark-defaults.conf.template spark-defaults.conf
2、修改spark-default.conf文件,配置日志存储路径
[atguigu@hadoop102 conf]$ vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/directory
注意:需要启动hdaoop集群,hdfs上的目录需要提前存在
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /directory
3、修改spark-env.sh文件,添加如下配置
[atguigu@hadoop102 conf]$ vim spark-env.sh
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory
-Dspark.history.retainedApplications=30"
1)参数1含义:webui访问的端口号为18080
2)参数2含义:指定历史服务器日志存储路径(读)
3)参数3含义:指定保存application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上的显示的应用数
4、分发配置文件
[atguigu@hadoop102 conf]$ xsync spark-defaults.conf spark-env.sh
5、启动历史服务
[atguigu@hadoop102 spark-standalone]$
sbin/start-history-server.sh
6、再次执行任务
[atguigu@hadoop102 spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
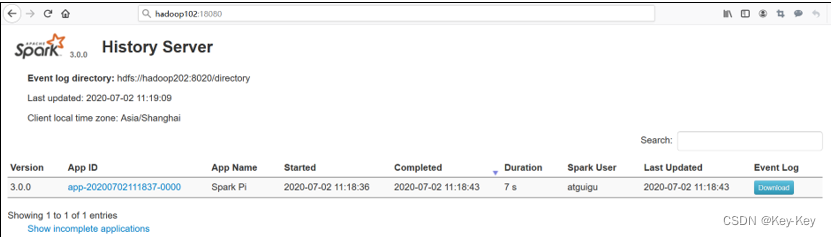
7、查看spark历史服务地址:hadoop102:18080
2.3.5 配置高可用(HA)
1、高可用原理
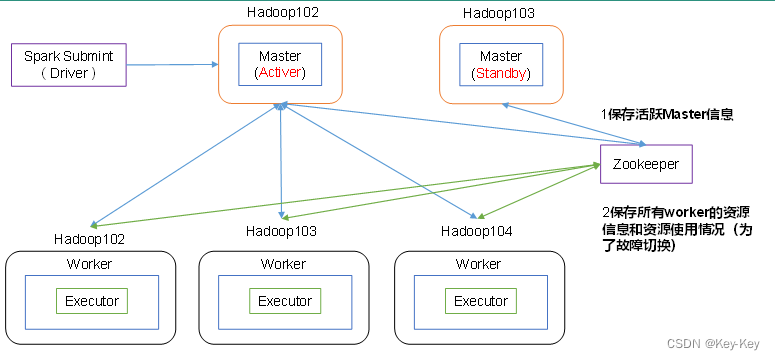
2、配置高可用
1)停止集群
[atguigu@hadoop102 spark-standalone]$ sbin/stop-all.sh
2)zookeeper正常安装并启动(基于以前讲的数仓项目脚本)
[atguigu@hadoop102 zookeeper-3.4.10]$ zk.sh start
3)修改spark-env.sh文件添加如下配置
[atguigu@hadoop102 conf]$ vim spark-env.sh
#注释掉如下内容:
#SPARK_MASTER_HOST=hadoop102
#SPARK_MASTER_PORT=7077
#添加上如下内容。配置由Zookeeper管理Master,在Zookeeper节点中自动创建/spark目录,用于管理:
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104
-Dspark.deploy.zookeeper.dir=/spark"
#添加如下代码
#Zookeeper3.5的AdminServer默认端口是8080,和Spark的WebUI冲突
export SPARK_MASTER_WEBUI_PORT=8989
4)分发配置文件
[atguigu@hadoop102 conf]$ xsync spark-env.sh
5)在hadoop102上启动全部节点
[atguigu@hadoop102 spark-standalone]$ sbin/start-all.sh
6)在hadoop103上单独启动master节点
[atguigu@hadoop103 spark-standalone]$ sbin/start-master.sh
7)在启动一个hadoop102窗口,将/opt/module/spark-local/input数据上传到hadoop集群的/input目录
[atguigu@hadoop102 spark-standalone]$ hadoop fs -put /opt/module/spark-local/input/ /input
8)spark ha集群访问
[atguigu@hadoop102 spark-standalone]$
bin/spark-shell \
--master spark://hadoop102:7077,hadoop103:7077 \
--executor-memory 2g \
--total-executor-cores 2
参数:–master spark://hadoop102:7077指定要连接的集群的master
注:一旦配置了高可用以后,master后面要连接多个master
9)执行wordcount程序
scala>sc.textFile("hdfs://hadoop102:8020/input").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((hello,4), (atguigu,2), (spark,2))
3、高可用性测试
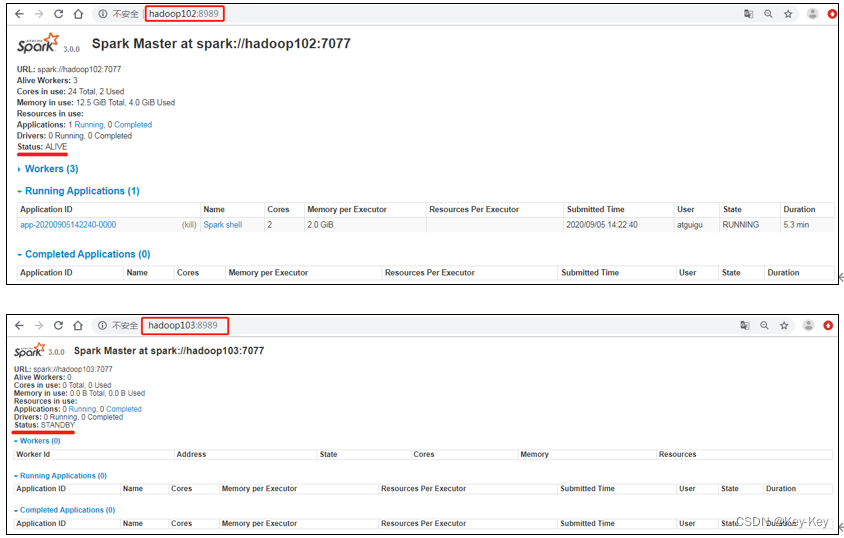
1)查看hadoop102的master进程
[atguigu@hadoop102 ~]$ jps
5506 Worker
5394 Master
5731 SparkSubmit
4869 QuorumPeerMain
5991 Jps
5831 CoarseGrainedExecutorBackend
2)kill掉hadoop102的master进程,页面中观察http://hadoop103:8080/的状态是否切换为active
[atguigu@hadoop102 ~]$ kill -9 5394
3)再启动hadoop102的master进程
[atguigu@hadoop102 spark-standalone]$ sbin/start-master.sh
2.3.5 运行流程
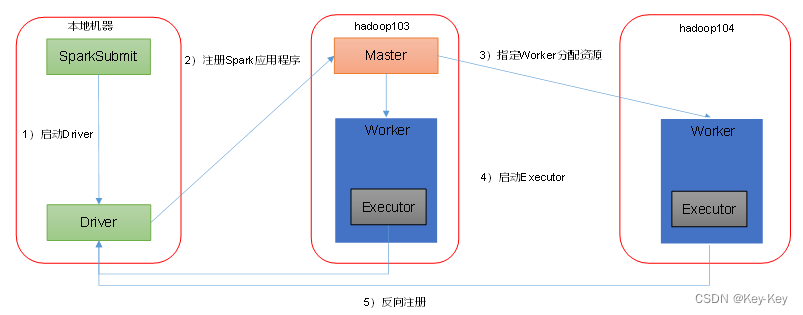
spark由standalone-client核standalone-cluster两种模式,主要区别在于:driver程序的运行节点。
1、客户端模式
[atguigu@hadoop102 spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077,hadoop103:7077 \
--executor-memory 2G \
--total-executor-cores 2 \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
–deploy-mode client,表示driver程序运行再本地客户端,默认模式。
standalone client运行流程
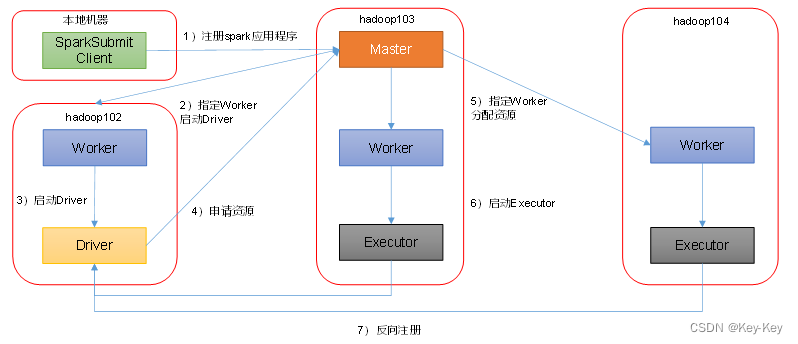
2、集群模式
[atguigu@hadoop102 spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077,hadoop103:7077 \
--executor-memory 2G \
--total-executor-cores 2 \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
–deploy-mode cluster,表示driver程序运行在集群
standalone cluster运行流程
1)查看http://hadoop102:8989/页面,点击completed drivers里面的worker

2)跳转到spark worker页面,点击finished drivers中logs下面的stdout

3)最终打印结果如下
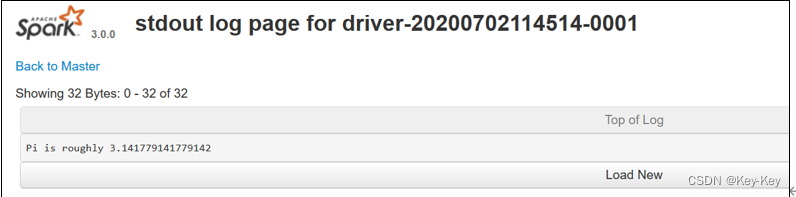
注意:在测试standalone模式,cluster运行流程的时候,阿里云用户访问不到worker,因为worker是从master内部跳转的,这是正常的,实际工作中我们不可能通过客户端访问的,这些恶端口都对外都会禁用,需要的时候会通过授权到master访问worker
2.4 yarn模式(重点)
spark客户端直接连接yarn,不需要额外构建spark集群
2.4.1 安装使用
1、停止standalone模式下的spark集群
[atguigu@hadoop102 spark-standalone]$ sbin/stop-all.sh
[atguigu@hadoop102 spark-standalone]$ zk.sh stop
[atguigu@hadoop103 spark-standalone]$ sbin/stop-master.sh
2、为了防止和standalone模式冲突,再单独解压一份spark
[atguigu@hadoop102 software]$ tar -zxvf spark-3.1.3-bin-hadoop3.2.tgz -C /opt/module/
3、进入到/opt/module目录,修改spark-~名称为spark-yarn
[atguigu@hadoop102 module]$ mv spark-3.1.3-bin-hadoop3.2/ spark-yarn
4、修改hadoop配置文件/opt/module/~/yarn-site.xml,添加如下内容
因为测试环境虚拟机内存较少,防止执行过程进行倍意外杀死,做如下处理
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
5、分发配置文件
[atguigu@hadoop102 conf]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
6、修改/opt/~/spark-env.sh,添加yarn_conf_dir配置,保证后续运行任务的路径都编程集群路径
[atguigu@hadoop102 conf]$ mv spark-env.sh.template spark-env.sh
[atguigu@hadoop102 conf]$ vim spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
7、启动hdfs以及yarn集群
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
8、执行一个程序
[atguigu@hadoop102 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
参数:–master yarn,表示yarn方式运行;–deploy-mode,表示客户端方式运行程序
9、查看hadoop103:8088页面,点击history,查看历史页面

2.4.2 配置历史服务
由于是重新解压的spark压缩文件,所以需要针对yarn模式,再次配置一下历史服务器。
1、修改spark-default.conf.template名称
2、修改spark-default.conf文件,配置日志存储路径(写)
3、修改spark-env.sh文件,添加如下配置
参数1含义:webui访问的端口号为18080
参数2含义:指定历史服务器日志存储路径(读)
参数3含义:指定保存application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数
2.4.3 配置查看历史日志
为了能从yarn上关联到spark历史服务器,需要配置spark历史服务器关联路径
目的:点击yarn(8088)上spark任务的history按钮,进入的是spark历史服务器(18080),而不再是yarn历史服务器(19888)
1、修改配置文件/opt/module/~/spark-defaults.conf
添加如下内容:
spark.yarn.historyserver.address=hadoop102:18080
spark.history.ui.port=18080
2、重启spark历史服务
[atguigu@hadoop102 spark-yarn]$ sbin/stop-history-server.sh
[atguigu@hadoop102 spark-yarn]$ sbin/start-history-server.sh
3、提交任务到yarn执行
[atguigu@hadoop102 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
4、web页面查看日志:http://hadoop103:8088/cluster
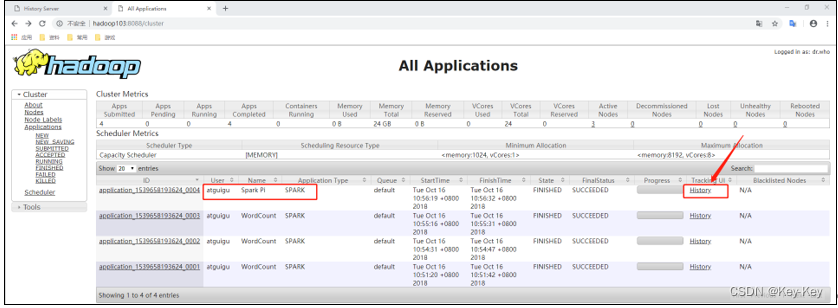
点击”history“跳转到http://hadoop102:18080/
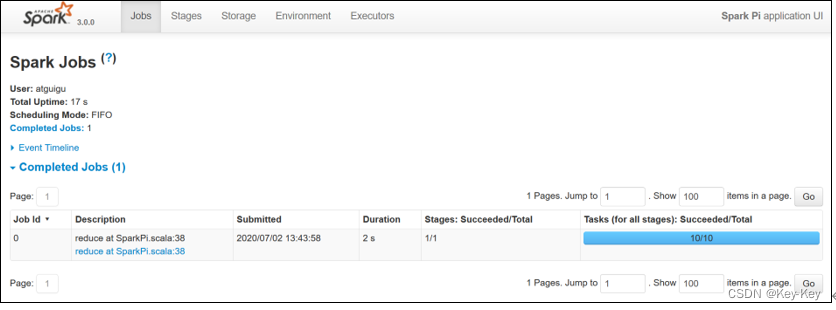
2.4.4 运行流程
spark由yarn-client和yarn-cluster两种模式,主要区别在于:driver程序的运行节点
yarn-client:driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
yarn-cluster:driver程序运行在由resourcemanager启动的appmaster,适用于生产环境
1、客户端模式(默认)
[atguigu@hadoop102 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
yarnclient运行模式介绍
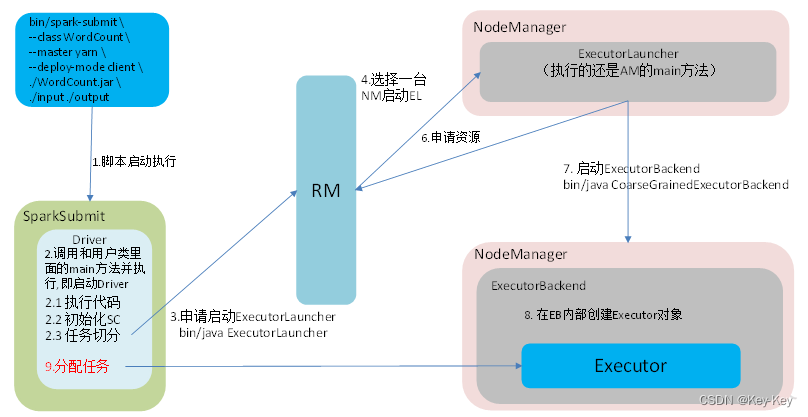
2、集群模式
[atguigu@hadoop102 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
(1)查看http://hadoop103:8088/cluster页面,点击history按钮,跳转到历史详情页面

(2)http://hadoop102:18080点击executors->点击driver的stdout
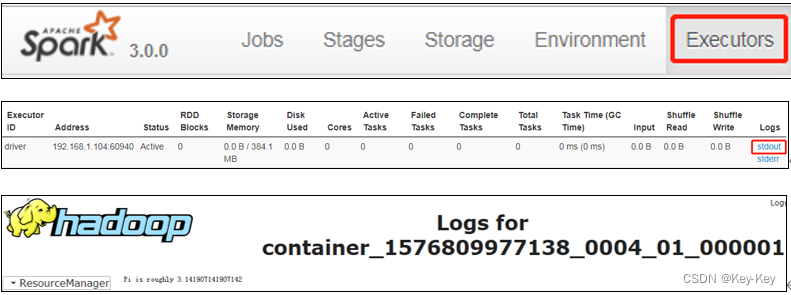
注意:如果在yarn日志端无法查看到具体的日志,则在yarn-site.xml中添加如下配置并启动yarn历史服务器
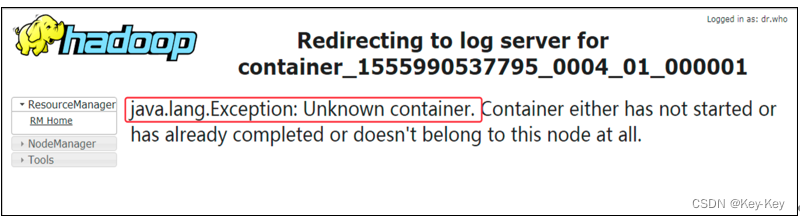
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
注意:hadoop历史服务器也要启动 mr-jobhistory-daemon.sh start historyserver
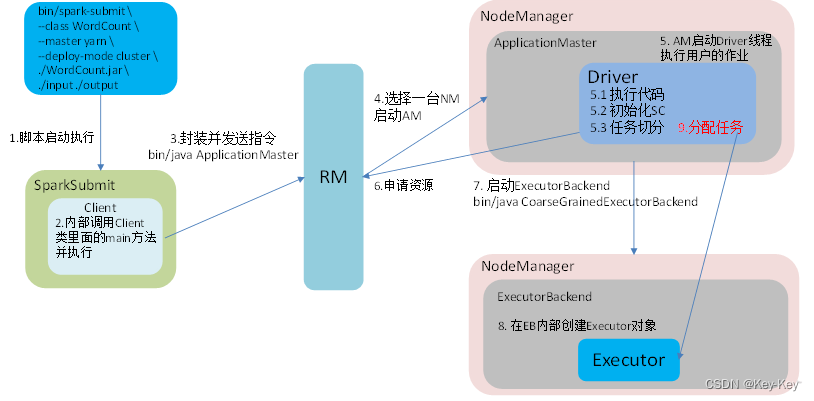
yarncluster模式
2.6 几种模式对比

2.7 端口号总结
1、spark查看当前spark-shell运行任务情况端口号:4040
2、spark master内部通信服务端口号:7077(类似于yarn的8032(rm和nm的内部通信)端口)
3、spark standalone模式master web端口号:8080(类似于hadoop yarn任务运行情况查看端口号:8088)(yarn模式)8989
4、spark历史服务器端口号:18080(类似于hadoop历史服务器端口号:19888)
第 3 章:workcount案例实操
spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在idea中编制程序,然后打包jar包,然后提交到集群,最常用的是创建一个maven项目,利用maven来管理jar包的依赖。
3.1 部署环境
1、创建一个maven项目wordcount
2、在项目wordcount上点击右键,add framework support -> 勾选scala
3、在main下创建scala文件夹,并右键mark directory as sources root -> 在scala下创建包com.atguigu.spark
4、输入文件夹准备
5、导入项目依赖
下方的的是scala语言打包插件,只要使用scala语法打包运行到linux上面,必须要有
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
<build>
<finalName>WordCount</finalName>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
3.2 本地调试
本地spark程序调试需要使用local提交模式,即将本机当作运行环境,master和worker都为本机。运行时直接加断点调试即可。如下:
1、代码实现
package com.atguigu.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("WC").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//3.读取指定位置文件:hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input")
//4.读取的一行一行的数据分解成一个一个的单词(扁平化)(hello)(atguigu)(atguigu)
val wordRdd: RDD[String] = lineRdd.flatMap(_.split(" "))
//5. 将数据转换结构:(hello,1)(atguigu,1)(atguigu,1)
val wordToOneRdd: RDD[(String, Int)] = wordRdd.map((_, 1))
//6.将转换结构后的数据进行聚合处理 atguigu:1、1 =》1+1 (atguigu,2)
val wordToSumRdd: RDD[(String, Int)] = wordToOneRdd.reduceByKey(_+_)
//7.将统计结果采集到控制台打印
wordToSumRdd.collect().foreach(println)
//8.关闭连接
sc.stop()
}
}
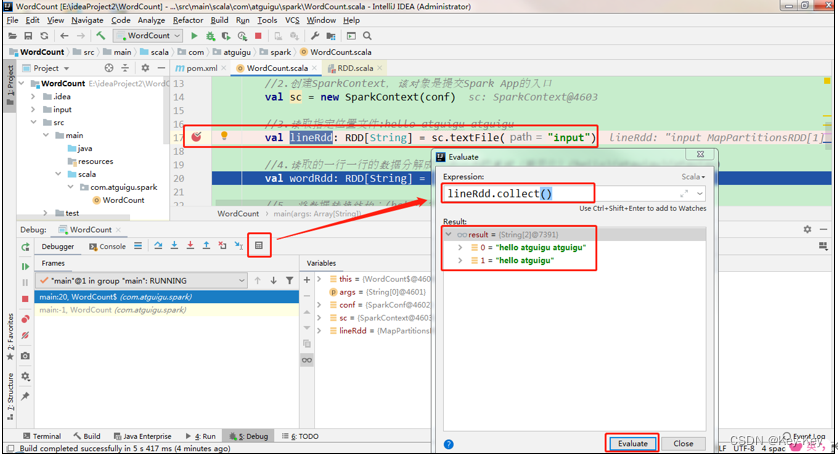
2、调试流程
spark程序运行过程中会打印大量的执行日志,为了能够更好的查看程序的执行结果,可以在项目的resources目录中创建log4j.properties文件,并添加日志配置文件:
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
3、集群运行
3.3 集群运行
1、修改代码,修改运行模式,将输出的方法修改为落盘,同时设置可以自定义的传入传出路径
package com.atguigu.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// 创建配置对象 添加配置参数
val conf: SparkConf = new SparkConf()
.setAppName("wc")
// 如果是yarn模式 写yarn
// 如果是本地模式一定要写local
.setMaster("yarn")
// 初始化sc
val sc = new SparkContext(conf)
// 编写wordCount计算流程
// 把读入和写出的路径 做成动态的参数 可以由用户手动填写
// 写成main方法参数
val lineRDD: RDD[String] = sc.textFile(args(0))
// 切分
val wordRDD: RDD[String] = lineRDD.flatMap(_.split(" "))
// 转换
val tupleOneRDD: RDD[(String, Int)] = wordRDD.map((_, 1))
// 聚合
val wordCountRDD: RDD[(String, Int)] = tupleOneRDD.reduceByKey(_ + _)
// 触发计算 一定要使用行动算子
// 将结果保存到文件中
// 不能重复写入同一个路径
wordCountRDD.saveAsTextFile(args(1))
}
}
2、打包到集群测试
1)点击package打包,然后,查看打包完后的jar包
2)将wordcount.jar上传到/opt/module/spark-yarn目录
3)在hdfs上创建,存储输入文件的路径/input
[atguigu@hadoop102 spark-yarn]$ hadoop fs -mkdir /input
4)上传输入文件到/input路径
[atguigu@hadoop102 spark-yarn]$ hadoop fs -put /opt/module/spark-local/input/1.txt /input
5)执行任务
[atguigu@hadoop102 spark-yarn]$ bin/spark-submit \
--class com.atguigu.spark.WordCount \
--master yarn \
./WordCount.jar \
hdfs://hadoop102:8020/input \
hdfs://hadoop102:8020/output
注意:input和output都是hdfs上的集群路径
6)查看运行结果
[atguigu@hadoop102 spark-yarn]$ hadoop fs -cat /output/*
3.4 关联源码
1、按住ctrl键,点击rdd

2、提示下载或者绑定源码

3、解压资料包中spark-3.1.3.tgz到非中文路径。例如解压到:e:\02_software
4、点击attach source…按钮,选择源码路径e:\02_software\spark-3.1.3
3.5 异常处理
如果本机操作系统是windows,如果在程序中使用了hadoop相关的东西,比如写入文件到hdfs,则会遇到如下异常:

出现这个问题的原因,并不是程序的错误,而是用到了hadoop相关的服务,解决办法
1、配置hadoop_home环境变量
2、在idea中配置 run configuration,添加hadoop_home变量
第 1 章:rdd概述
1.1 什么是rdd
rdd(resilient distributed dataset)叫做弹性分布式数据集,是spark中最基本的数据抽象。
代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
1.1.1 rdd类比工厂生产
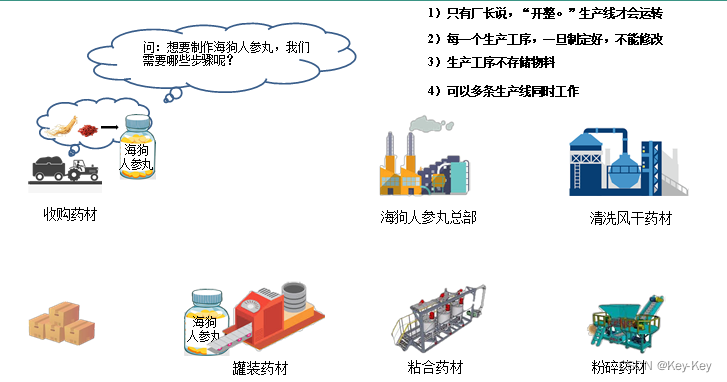
1.1.2 wordcount工作流程

1.2 rdd五大特性
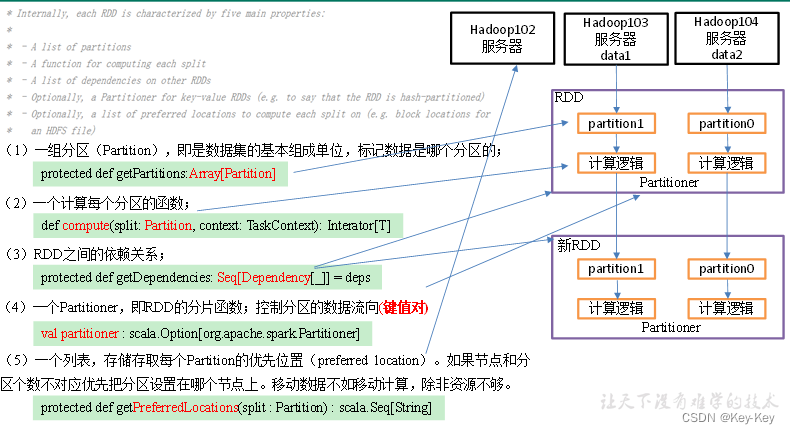
1、一组分区(partition),即是数据集的基本组成单位,标记数据是哪个分区的;
protected def getpartitions:array[partition]
2、一个计算每个分区的函数;
def compute(split:partition,context:taskcontext):inteator[t]
3、rdd之间的依赖关系;
protected def getdependencies:seq[dependency[ ]]=deps
4、一个partitioner,即rdd的分片函数;控制分区的数据流向(键值对)
val partitioner:scala.option[org.apache.sparkpartitioner]
5、一个列表,存储存取每个partition的优先位置(preferred location)。如果节点和分区个数不对应优先把分区设置在哪个节点上。移动数据不如移动计算,除非资源不够。
protect def getpreferredlocations(split:partition):scala.sea[string]
第 2 章:rdd编程
2.1 rdd的创建
在spark中创建rdd的创建方式可以分为三种:从集合中创建rdd、从外部存储创建rdd、从其它rdd创建。
2.1.1 idea环境准备
1、创建一个maven工程,工程名称叫sparkcoretest

2、添加scala框架支持
3、创建一个scala文件夹,并把它修改为sourceroot
4、创建包名:com.atguigu.createrdd
5、在pom文件中添加spark-core的依赖和scala的编译插件
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
<build>
<finalName>SparkCoreTest</finalName>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.1.2 从集合中创建
1、从集合中创建rdd,spark主要提供了两种函数:parallelize和makerdd
package com.atguigu.create
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test01_FromList {
def main(args: Array[String]): Unit = {
// 1.创建sc的配置对象
val conf: SparkConf = new SparkConf()
.setAppName("sparkCore").setMaster("local[*]")
// 2. 创建sc对象
val sc = new SparkContext(conf)
// 3. 编写任务代码
val list = List(1, 2, 3, 4)
// 从集合创建rdd
val intRDD: RDD[Int] = sc.parallelize(list)
intRDD.collect().foreach(println)
// 底层调用parallelize 推荐使用 比较好记
val intRDD1: RDD[Int] = sc.makeRDD(list)
intRDD1.collect().foreach(println)
// 4.关闭sc
sc.stop()
}
}
注意:makerdd有两种重构方法,重构方法一如下,makerdd和parallelize功能一样
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
2、makerdd的重构方法二,增加了位置信息
注意:只需要知道makerdd不完全等于parallelize即可
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope {
assertNotStopped()
val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMap
new ParallelCollectionRDD[T](this, seq.map(_._1), math.max(seq.size, 1), indexToPrefs)
}
2.1.3 从外部存储系统的数据集创建
由外部存储系统的数据集创建rdd包括:本地的文件系统,还有所有hadoop支持的数据集,比如hdfs、hbase等
1、数据准备
在新建的sparkcoretest项目名称上右键->新建input文件夹->在input文件夹上右键->分别新建1.txt和2.txt。每个文件里面准备一些word单词。
2、创建rdd
package com.atguigu.create
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test02_FromFile {
def main(args: Array[String]): Unit = {
// 1.创建sc的配置对象
val conf: SparkConf = new SparkConf()
.setAppName("sparkCore").setMaster("local[*]")
// 2. 创建sc对象
val sc = new SparkContext(conf)
// 3. 编写任务代码
// 不管文件中存的是什么数据 读取过来全部当做字符串处理
val lineRDD: RDD[String] = sc.textFile("input/1.txt")
lineRDD.collect().foreach(println)
// 4.关闭sc
sc.stop()
}
}
2.1.4 从其它rdd创建
主要是通过一个rdd运算完后,再产生新的rdd
2.1.5 创建idea快捷键
1、点击file->settings…->editor->live templates-output->live template
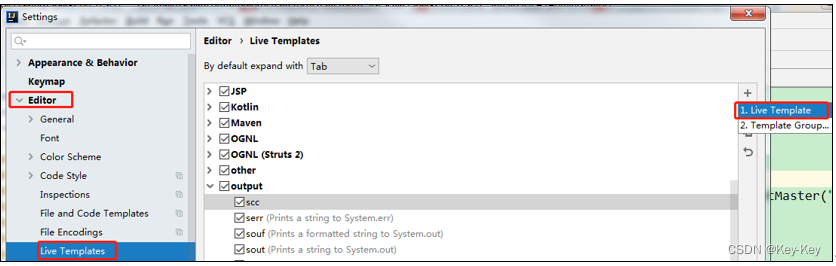
2、点击左下角的define->选择scala
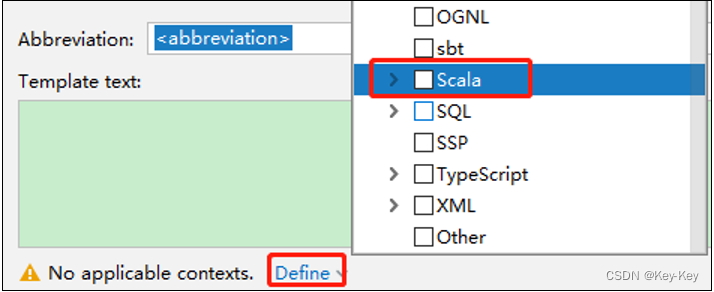
3、在abbreviation中输入快捷键名称scc,在template text中填写,输入快捷键后生成的内容

//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//4.关闭连接
sc.stop()
2.2 分区规则
2.2.1 从集合创建rdd
1、创建一个包名:com.atguigu.partition
2、代码验证
package com.atguigu.create
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test03_ListPartition {
def main(args: Array[String]): Unit = {
// 1.创建sc的配置对象
val conf: SparkConf = new SparkConf()
.setAppName("sparkCore").setMaster("local[*]")
// 2. 创建sc对象
val sc = new SparkContext(conf)
// 3. 编写任务代码
// 默认环境的核数
// 可以手动填写参数控制分区的个数
val intRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5),2)
// 数据分区的情况
// 0 => 1,2 1 => 3,4,5
// RDD的五大特性 getPartitions
// 利用整数除机制 左闭右开
// 0 => start 0*5/2 end 1*5/2
// 1 => start 1*5/2 end 2*5/2
// 将rdd保存到文件 有几个文件生成 就有几个分区
intRDD.saveAsTextFile("output")
// 4.关闭sc
sc.stop()
}
}
2.2.2 从文件创建rdd
1、分区测试
package com.atguigu.create
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test04_FilePartition {
def main(args: Array[String]): Unit = {
// 1.创建sc的配置对象
val conf: SparkConf = new SparkConf()
.setAppName("sparkCore").setMaster("local[*]")
// 2. 创建sc对象
val sc = new SparkContext(conf)
// 3. 编写任务代码
// 默认填写的最小分区数 2和环境的核数取小的值 一般为2
// math.min(defaultParallelism, 2)
val lineRDD: RDD[String] = sc.textFile("input/1.txt",3)
// 具体的分区个数需要经过公式计算
// 首先获取文件的总长度 totalSize
// 计算平均长度 goalSize = totalSize / numSplits
// 获取块大小 128M
// 计算切分大小 splitSize = Math.max(minSize, Math.min(goalSize, blockSize));
// 最后使用splitSize 按照1.1倍原则切分整个文件 得到几个分区就是几个分区
// 实际开发中 只需要看文件总大小 / 填写的分区数 和块大小比较 谁小拿谁进行切分
lineRDD.saveAsTextFile("output")
// 数据会分配到哪个分区
// 如果切分的位置位于一行的中间 会在当前分区读完一整行数据
// 0 -> 1,2 1 -> 3 2 -> 4 3 -> 空
// 4.关闭sc
sc.stop()
}
}
2、分区源码
注意:getsplits文件返回的是切片规划,真正读取是在compute方法中创建linerecordreader读取的,有两个关键变量:start=split.getstart() end=start+split.getlength
1)分区数量的计算方式
totalsize=10
goalsize=10/3=3(byte)表示每个分区存储3字节的数据
分区数=totalsize/goalsize=10/3=3
4字节大于3字节的1.1倍,符合hadoop切片1.1倍的策略,因此会多创建一个分区,即一共4个分区 3,3,3,1
2)spark读取文件,采用的是hadoop的方式读取,所以一行一行读取,跟字节数没有关系
3)数据读取位置计算的以偏移量为单位来进行计算的
4)数据分区的偏移量范围的计算

2.3 transformation转换算子
rdd整体上分为value类型、双value类型和key-value类型。
2.3.1 value类型
1、创建包名:com.atguigu.value
2.3.1.1 map()映射
1、函数签名:def.map(u:classtag)(f:t=>u):rdd[u]
2、功能说明:参数f是一个函数,它可以接收一个参数。当某个rdd执行map方法时,会遍历该rdd中的每一个数据项,并依次应用f函数,从而产生一个新的rdd。即,这个新rdd中的每一个元素都是原来rdd中每一个元素依次应用f函数而得到的。
3、需求说明:创建一个1-4数组的rdd,两个分区,将所有元素*2形成新的rdd
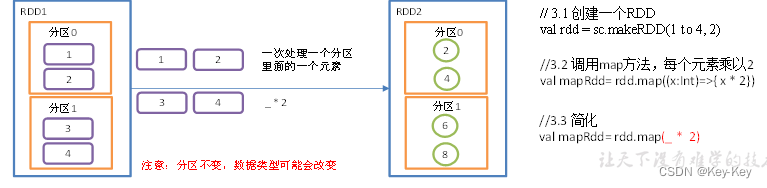
4、具体实现
object value01_map {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4, 2)
// 3.2 调用map方法,每个元素乘以2
val mapRdd: RDD[Int] = rdd.map(_ * 2)
// 3.3 打印修改后的RDD中数据
mapRdd.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3.1.2 mappartitions()以分区为单位执行map
mappartitions算子
1、函数签名:
def mappartitions[u:classtag](
f:iterator[t]=>iterator[u]
preservespartitioning:boolean=false):rdd[u]
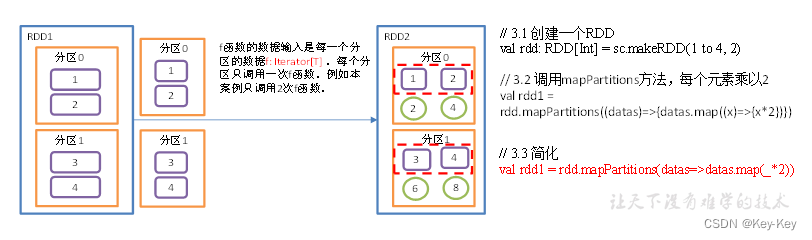
2、功能说明:map是一次处理一个元素,而mappartitions一次处理一个分区数据
3、需求说明:创建一个rdd,4个元素,2个分区,使每个元素*2组成新的rdd
4、具体实现
object value02_mapPartitions {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4, 2)
// 3.2 调用mapPartitions方法,每个元素乘以2
val rdd1 = rdd.mapPartitions(x=>x.map(_*2))
// 3.3 打印修改后的RDD中数据
rdd1.collect().foreach(println)
// 将RDD中的一个分区作为几个集合 进行转换结构
// 只是将一个分区一次性进行计算 最终还是修改单个元素的值
// 可以将RDD中的元素个数减少 只需要保证一个集合对应一个输出集合即可
val value: RDD[Int] = intRDD.mapPartitions(list => {
println("mapPartition调用")
// 对已经是集合的数据调用集合常用函数进行修改即可
// 此处的map是集合常用函数
list.filter(i => i % 2 == 0)
})
value.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3.1.3 map()和mappartitions()区别
1、map():每次处理一条数据
2、mappartition():每次处理一个分区的数据,这个分区的数据处理完成后,原rdd中分区的数据才能释放,可能导致oom
3、开发经验:当内存空间较大的时候建议使用mappartition(),以提高效率
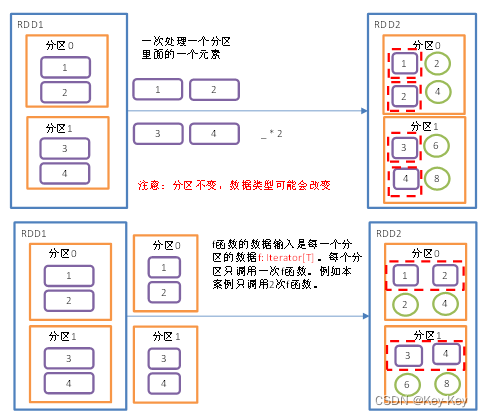
2.3.1.4 mappartitionswithindex()带分区号
1、函数签名

2、功能说明:类似mappartitions,比mappartitions多一个整数参数表示分区号
3、需求说明:创建一个rdd,使每个元素跟所在分区号形成一个元组,组成一个新的rdd
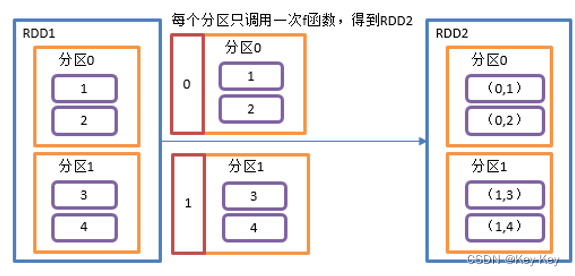
4、具体实现
object value03_mapPartitionsWithIndex {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4, 2)
// 3.2 创建一个RDD,使每个元素跟所在分区号形成一个元组,组成一个新的RDD
val indexRdd = rdd.mapPartitionsWithIndex( (index,items)=>{items.map( (index,_) )} )
// 3.3 打印修改后的RDD中数据
indexRdd.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3.1.5 flatmap()扁平化
1、函数签名
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
2、功能说明
与map操作类似,将rdd中的每一个元素通过应用f函数依次转换为新的元素,并封装到rdd中。
区别:在flatmap操作中,f函数的返回值是一个集合,并且会将每一个该集合中的元素拆分出来放到新的rdd中。
3、需求说明:创建一个集合,集合里面存储的还是子集合,把所有子集合中数据取出放入到一个大的集合中。
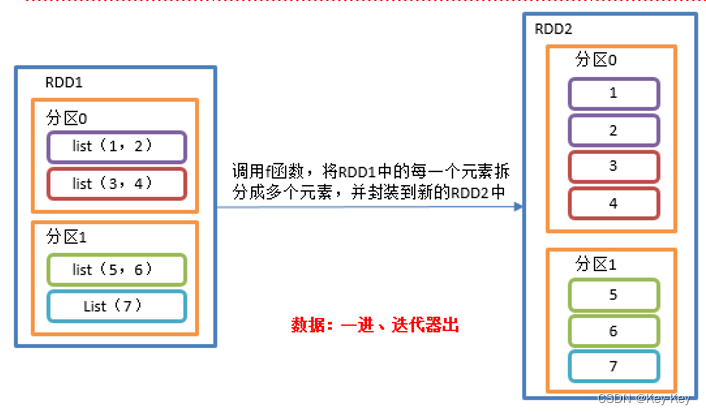
4、具体实现
object value04_flatMap {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val listRDD=sc.makeRDD(List(List(1,2),List(3,4),List(5,6),List(7)), 2)
// 3.2 把所有子集合中数据取出放入到一个大的集合中
listRDD.flatMap(list=>list).collect.foreach(println)
//4.关闭连接
sc.stop()
}
}
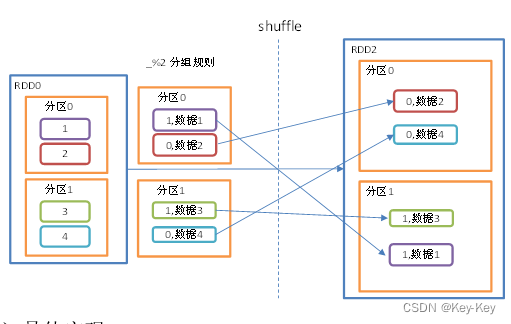
2.3.1.6 groupby()分组
groupby算子
1、函数签名
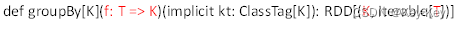
2、功能说明
分组,按照传入函数的返回值进行分组。将相同的key对应的值放入到一个迭代器。
3、需求说明
创建一个rdd,按照元素模以2的值进行分组
4、具体实现
object value05_groupby {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val rdd = sc.makeRDD(1 to 4, 2)
// 3.2 将每个分区的数据放到一个数组并收集到Driver端打印
rdd.groupBy(_ % 2).collect().foreach(println)
// 3.3 创建一个RDD
val rdd1: RDD[String] = sc.makeRDD(List("hello","hive","hadoop","spark","scala"))
// 3.4 按照首字母第一个单词相同分组
rdd1.groupBy(str=>str.substring(0,1)).collect().foreach(println)
sc.stop()
}
}
groupby会存在shuffle过程
shuffle:将同步的分区数据进行打乱重组的过程
shuffle一定会落盘。可以在local模式下执行程序,通过4040看效果
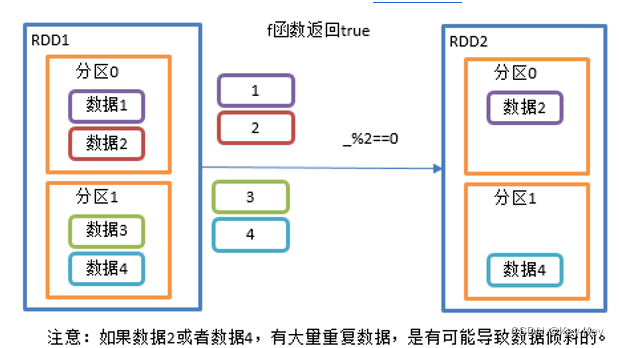
2.3.1.7 filter()过滤
1、函数签名
def filter(f: T => Boolean): RDD[T]
2、功能说明
接收一个返回值为布尔类型的函数作为参数。当某个rdd调用filter方法时,会对该rdd中每一个元素应用f函数,如果返回值类型为true,则该元素会被添加到新的rdd中。
3、需求说明
创建一个rdd,过滤出对2取余等于0的数据
4、代码实现
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3.创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4), 2)
//3.1 过滤出符合条件的数据
val filterRdd: RDD[Int] = rdd.filter(_ % 2 == 0)
//3.2 收集并打印数据
filterRdd.collect().foreach(println)
//4 关闭连接
sc.stop()
}
}
2.3.1.8 distinct()去重
distinct算子
1、函数签名
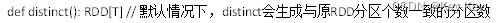
2、功能说明
对内部的元素去重,并将去重后的元素放到新的rdd中
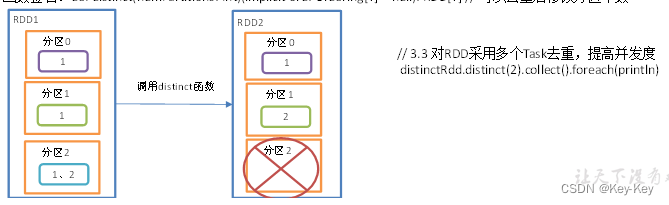
3、源码解析
用分布式的方法去重比hashset集合方式不容易oom

4、函数签名
5、代码实现
object value07_distinct {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val distinctRdd: RDD[Int] = sc.makeRDD(List(1,2,1,5,2,9,6,1))
// 3.2 打印去重后生成的新RDD
distinctRdd.distinct().collect().foreach(println)
// 3.3 对RDD采用多个Task去重,提高并发度
distinctRdd.distinct(2).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
注意:distinct会存在shuffle过程
2.3.1.9 coalesce()合并分区
coalesce算子包括:配置执行shuffle和配置不执行shuffle两种方式
1、不执行shuffle方式
1)函数签名
def coalesce(numPartitions: Int, shuffle: Boolean = false, //默认false不执行shuffle
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null) : RDD[T]
2)功能说明
缩减分区数,用于大数据集过滤后,提高小数据集的执行效率
3)需求
4个分区合并为两个分区

4)代码实现
object value08_coalesce {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3.创建一个RDD
//val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4), 4)
//3.1 缩减分区
//val coalesceRdd: RDD[Int] = rdd.coalesce(2)
//4. 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), 3)
//4.1 缩减分区
val coalesceRDD: RDD[Int] = rdd.coalesce(2)
//5 查看对应分区数据
val indexRDD: RDD[(Int, Int)] = coalesceRDD.mapPartitionsWithIndex(
(index, datas) => {
datas.map((index, _))
}
)
//6 打印数据
indexRDD.collect().foreach(println)
//8 延迟一段时间,观察http://localhost:4040页面,查看Shuffle读写数据
Thread.sleep(100000)
//7.关闭连接
sc.stop()
}
}
2、执行shuffle方式
//3. 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), 3)
//3.1 执行shuffle
val coalesceRdd: RDD[Int] = rdd.coalesce(2, true)
输出结果
(0,1)
(0,4)
(0,5)
(1,2)
(1,3)
(1,6)
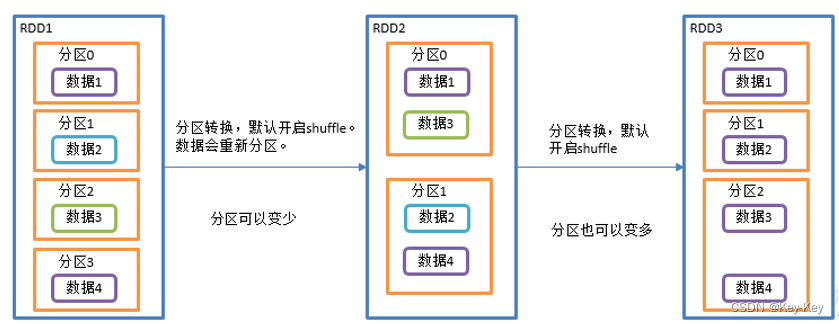
2.3.1.10 repartition()重新分区(执行shuffle)
1、函数签名
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
2、功能说明
该操作内部其实执行的是coalesce操作,参数shuffle的默认值是true。无论是将分区数多的rdd转换为分区数少的rdd,还是将分区数少的erdd转换为分区数多的rdd,repartition操作都可以完成,因为无论如何都会经shuffle过程。分区规则不是hash,因为平时使用的分区都是按照hash来实现的,repartition一般是对hash的结果不满意,想要打散重新分区。
3、需求
创建一个4个分区的rdd,对其重新分区
4、代码实现
object value09_repartition {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3. 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), 3)
//3.1 缩减分区
//val coalesceRdd: RDD[Int] = rdd.coalesce(2, true)
//3.2 重新分区
val repartitionRdd: RDD[Int] = rdd.repartition(2)
//4 打印查看对应分区数据
val indexRdd: RDD[(Int, Int)] = repartitionRdd.mapPartitionsWithIndex(
(index, datas) => {
datas.map((index, _))
}
)
//5 打印
indexRdd.collect().foreach(println)
//6. 关闭连接
sc.stop()
}
}
2.3.1.11 coalesce和repartition区别
1、coalesce重新分区,可以选择是否进行shuffle过程。由参数shuffle:boolean=false/true决定。
2、repartition实际上是调用的coalesce,进行shuffle。源码如下
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
3、coalesce一般为缩减分区,如果扩大分区,不使用shuffle是没有意义的,repartition扩大分区执行shuffle
2.3.1.12 sortby()排序
1、函数签名
def sortBy[K]( f: (T) => K,
ascending: Boolean = true, // 默认为正序排列
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
2、功能说明
该操作用于排序数据。在排序之前,可以将数据通过f函数进行处理,之后按照f函数处理的结果进行排序,默认为正序排序。排序后新产生的rdd的分区数与原rdd的分区数一致。
3、需求
创建一个rdd,按照数字大小分别实现正序和倒叙排序

4、代码实现
object value10_sortBy {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
// 3.1 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(2, 1, 3, 4, 6, 5))
// 3.2 默认是升序排
val sortRdd: RDD[Int] = rdd.sortBy(num => num)
sortRdd.collect().foreach(println)
// 3.3 配置为倒序排
val sortRdd2: RDD[Int] = rdd.sortBy(num => num, false)
sortRdd2.collect().foreach(println)
// 3.4 创建一个RDD
val strRdd: RDD[String] = sc.makeRDD(List("1", "22", "12", "2", "3"))
// 3.5 按照字符的int值排序
strRdd.sortBy(num => num.toInt).collect().foreach(println)
// 3.5 创建一个RDD
val rdd3: RDD[(Int, Int)] = sc.makeRDD(List((2, 1), (1, 2), (1, 1), (2, 2)))
// 3.6 先按照tuple的第一个值排序,相等再按照第2个值排
rdd3.sortBy(t=>t).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3.2 双value类型交互
1、创建包名:com.atguigu.doublevalue
2.3.2.1 intersection()交集
1、函数签名
def intersection(other: RDD[T]): RDD[T]
2、功能说明
对源rdd和参数rdd求交集后返回一个新的rdd
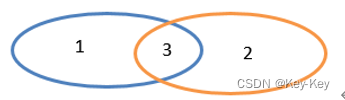
交集:只有3
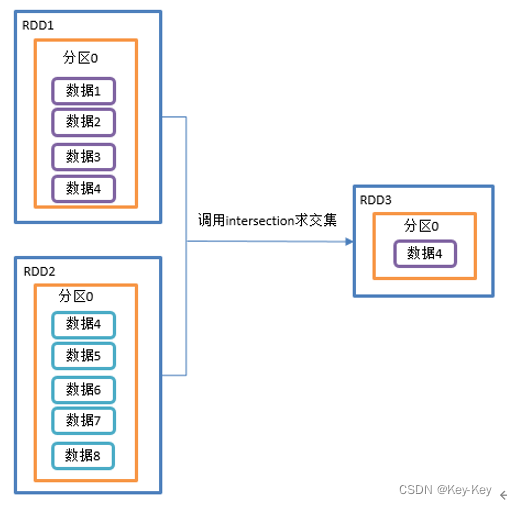
3、需求
创建两个rdd,求两个rdd的交集
4、代码实现
object DoubleValue01_intersection {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 4)
//3.2 创建第二个RDD
val rdd2: RDD[Int] = sc.makeRDD(4 to 8)
//3.3 计算第一个RDD与第二个RDD的交集并打印
// 利用shuffle的原理进行求交集 需要将所有的数据落盘shuffle 效率很低 不推荐使用
rdd1.intersection(rdd2).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3.2.2 union()并集不去重
1、函数签名
def union(other: RDD[T]): RDD[T]
2、功能说明
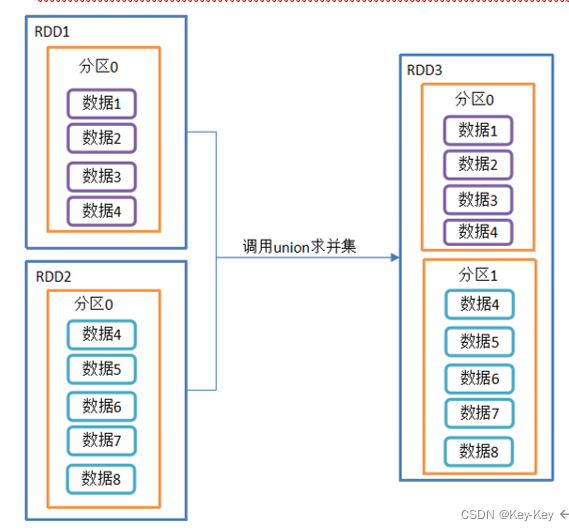
对源rdd和参数rdd求并集后返回一个新的rdd

并集:1、2、3全包括
3、需求
创建两个rdd,求并集
4、代码实现
object DoubleValue02_union {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 4)
//3.2 创建第二个RDD
val rdd2: RDD[Int] = sc.makeRDD(4 to 8)
//3.3 计算两个RDD的并集
// 将原先的RDD的分区和数据都保持不变 简单的将多个分区合并在一起 放到一个RDD中
// 由于不走shuffle 效率高 所有会使用到
rdd1.union(rdd2).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3.2.3 subtract()差集
1、函数签名
def subtract(other: RDD[T]): RDD[T]
2、功能说明
计算差的一种函数,去除两个rdd中相同元素,不同的rdd将保留下来
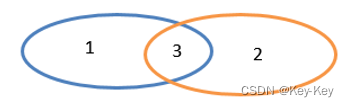
差集:只有1
3、需求说明:创建两个rdd,求第一个rdd与第二个rdd的差集

4、代码实现
object DoubleValue03_subtract {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4)
//3.2 创建第二个RDD
val rdd1: RDD[Int] = sc.makeRDD(4 to 8)
//3.3 计算第一个RDD与第二个RDD的差集并打印
// 同样使用shuffle的原理 将两个RDD的数据写入到相同的位置 进行求差集
// 需要走shuffle 效率低 不推荐使用
rdd.subtract(rdd1).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3.2.4 zip()拉链
1、函数签名
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
2、功能说明
该操作可以将两个rdd中的元素,以键值对的形式进行合并。其中,键值对中的key为第1个rdd中的元素,value为第2个rdd中的元素。
将两个rdd组合成key/value形式的rdd,这里默认两个rdd的partition数量以及元素数量都相同,否则会抛出异常。
3、需求说明
创建两个rdd,并将两个rdd组合到一起形成一个(k,v)rdd
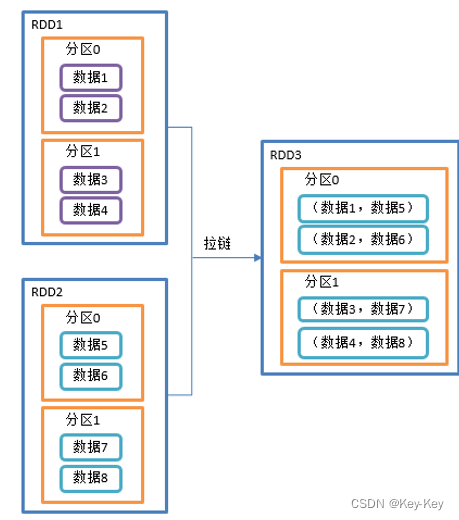
4、代码实现
object DoubleValue04_zip {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd1: RDD[Int] = sc.makeRDD(Array(1,2,3),3)
//3.2 创建第二个RDD
val rdd2: RDD[String] = sc.makeRDD(Array("a","b","c"),3)
//3.3 第一个RDD组合第二个RDD并打印
rdd1.zip(rdd2).collect().foreach(println)
//3.4 第二个RDD组合第一个RDD并打印
rdd2.zip(rdd1).collect().foreach(println)
//3.5 创建第三个RDD(与1,2分区数不同)
val rdd3: RDD[String] = sc.makeRDD(Array("a","b"), 3)
//3.6 元素个数不同,不能拉链
// Can only zip RDDs with same number of elements in each partition
rdd1.zip(rdd3).collect().foreach(println)
//3.7 创建第四个RDD(与1,2分区数不同)
val rdd4: RDD[String] = sc.makeRDD(Array("a","b","c"), 2)
//3.8 分区数不同,不能拉链
// Can't zip RDDs with unequal numbers of partitions: List(3, 2)
rdd1.zip(rdd4).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3.3 key-value类型
1、创建包名:com.atguigu.keyvalue
2.3.3.1 partitionby()按照k重新分区
1、函数签名
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
2、功能说明
将rdd[k,v]中的k按照指定partitioner重新进行分区;
如果原有的rdd和新的rdd是一致的话就不进行分区,否则会产生shuffle过程。
3、需求说明
创建一个3个分区的rdd,对其重新分区
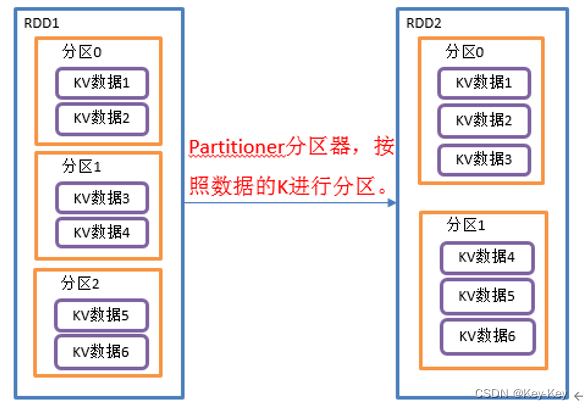
4、代码实现:
object KeyValue01_partitionBy {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1,"aaa"),(2,"bbb"),(3,"ccc")),3)
//3.2 对RDD重新分区
val rdd2: RDD[(Int, String)] = rdd.partitionBy(new org.apache.spark.HashPartitioner(2))
//3.3 打印查看对应分区数据 (0,(2,bbb)) (1,(1,aaa)) (1,(3,ccc))
val indexRdd = rdd2.mapPartitionsWithIndex(
(index, datas) => datas.map((index,_))
)
indexRdd.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3.3.2 自定义分区
1、hashpartitioner源码解读
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")
def numPartitions: Int = partitions
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
override def equals(other: Any): Boolean = other match {
case h: HashPartitioner =>
h.numPartitions == numPartitions
case _ =>
false
}
override def hashCode: Int = numPartitions
}
2、自定义分区器
要实现自定义分区器,需要继承org.apache.spark.partitioner类,并实现下面三个方法。
1)numpartitions:int:返回创建出来的分区数
2)getpartition(key:any):int:返回给定键的分区编号(0到numpartitions-1)
3)equals():java判断相等性的标准方法。这个方法的实现非常重要,spark需要用这个方法来检查你的分区器对象是否和其它分区器实例相同,这样spark才可以判断两个rdd的分区方式是否相同
object KeyValue01_partitionBy {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "aaa"), (2, "bbb"), (3, "ccc")), 3)
//3.2 自定义分区
val rdd3: RDD[(Int, String)] = rdd.partitionBy(new MyPartitioner(2))
//4 打印查看对应分区数据
rdd3.mapPartitionsWithIndex((index,list) => list.map((index,_)))
.collect().foreach(println)
//5.关闭连接
sc.stop()
}
}
// 自定义分区
class MyPartitioner(num: Int) extends Partitioner {
// 设置的分区数
override def numPartitions: Int = num
// 具体分区逻辑
// 根据传入数据的key 输出目标的分区号
// spark中能否根据value进行分区 => 不能 只能根据key进行分区
override def getPartition(key: Any): Int = {
// 使用模式匹配 对类型进行推断
// 如果是字符串 放入到0号分区 如果是整数 取模分区个数
key match {
case s:String => 0
case i:Int => i % numPartitions
case _ => 0
}
}
}
2.3.3.3 groupbykey()按照k重新分组
1、函数签名
def groupByKey(): RDD[(K, Iterable[V])]
2、功能说明
groupbykey对每个key进行操作,但只生成一个seq,并不进行聚合。
该操作可以指定分区器或者分区数(默认使用hashpartitioner)
3、需求说明
统计单词出现次数

4、代码实现
object KeyValue03_groupByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd = sc.makeRDD(List(("a",1),("b",5),("a",5),("b",2)))
//3.2 将相同key对应值聚合到一个Seq中
val group: RDD[(String, Iterable[Int])] = rdd.groupByKey()
//3.3 打印结果
group.collect().foreach(println)
//3.4 计算相同key对应值的相加结果
group.map(t=>(t._1,t._2.sum)).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3.3.4 reducebykey()按照k聚合v
1、函数签名
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
2、功能说明:该操作可以将rdd[k,v]中的元素按照相同的k对v进行聚合。其存在多种重载形式,还可以设置新的rdd的分区数。
3、需求说明:统计单词出现次数
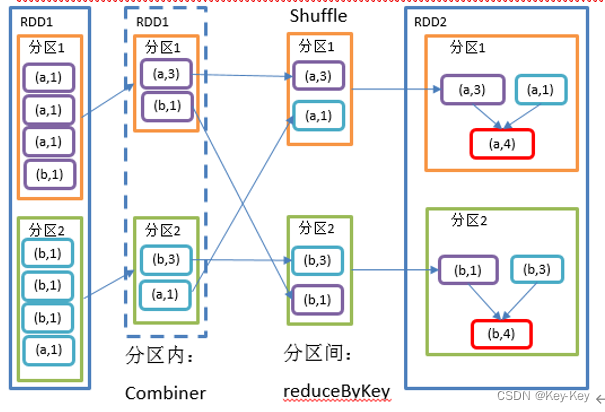
4、代码实现
object KeyValue02_reduceByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd = sc.makeRDD(List(("a",1),("b",5),("a",5),("b",2)))
//3.2 计算相同key对应值的相加结果
val reduce: RDD[(String, Int)] = rdd.reduceByKey((v1,v2) => v1+v2)
//3.3 打印结果
reduce.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3.3.5 reducebykey和groupbykey区别
1、reducebykey
按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是rdd[k,v]。
2、groupbykey
按照key进行分组,直接进行shuffle。
3、开发指导
在不影响业务逻辑的前提下,优先选择reducebykey。求和操作不影响业务逻辑,求平均值影响业务逻辑,后续会学习功能更加强大的规约算子,能够在预聚合的情况下实现求平均值。
2.3.3.6 aggregatebykey()分区内和分区间逻辑不同的规约
aggregatebykey算子
1、函数签名
1)zerovalue(初始值):给每一个分区中的每一种key一个初始值
2)seqop(分区内):函数用于在每一个分区中用初始值逐步迭代value
3)combop(分区间):函数用于合并每个分区中的结果

2、代码实现
object KeyValue04_aggregateByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a",1),("a",3),("a",5),("b",7),("b",2),("b",4),("b",6),("a",7)), 2)
//3.2 取出每个分区相同key对应值的最大值,然后相加
rdd.aggregateByKey(0)(math.max(_, _), _ + _).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
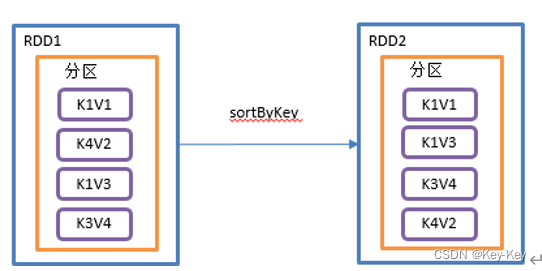
2.3.3.7 sortbykey()按照k进行排序
1、函数签名
def sortByKey(
ascending: Boolean = true, // 默认,升序
numPartitions: Int = self.partitions.length) : RDD[(K, V)]
2、功能说明
在一个(k,v)的rdd上调用,k必须实现ordered接口,返回一个按照key进行排序的(k,v)的rdd。
3、需求说明
创建一个pairrdd,按照key的正序和倒叙进行排序
4、代码实现:
object KeyValue07_sortByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
//3.2 按照key的正序(默认顺序)
rdd.sortByKey(true).collect().foreach(println)
//3.3 按照key的倒序
rdd.sortByKey(false).collect().foreach(println)
// 只会按照key来排序 最终的结果是key有序 value不会排序
// spark的排序是全局有序 不会进行hash shuffle处理
// 使用range分区器
// new RangePartitioner(numPartitions, self, ascending)
//4.关闭连接
sc.stop()
}
}
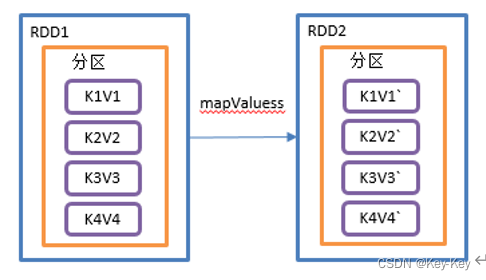
2.3.3.8 mapvalues()只对v进行操作
1、函数签名
def mapValues[U](f: V => U): RDD[(K, U)]
2、功能说明
针对(k,v)形式的类型只对v进行操作
3、需求说明
创建一个pairrdd,并将value添加字符串"|||"
4、代码实现
object KeyValue08_mapValues {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (1, "d"), (2, "b"), (3, "c")))
//3.2 对value添加字符串"|||"
rdd.mapValues(_ + "|||").collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3.3.9 join()等同于sql里的内连接,关联上的要,关联补上的舍弃
1、函数签名
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))]
2、功能说明
在类型为(k,v)和(k,w)的rdd上调用,返回一个相同key对应的所有元素对在一起的(k,(v,w))的rdd
3、需求说明
创建两个pairrdd,并将key相同的数据聚合到一个元组
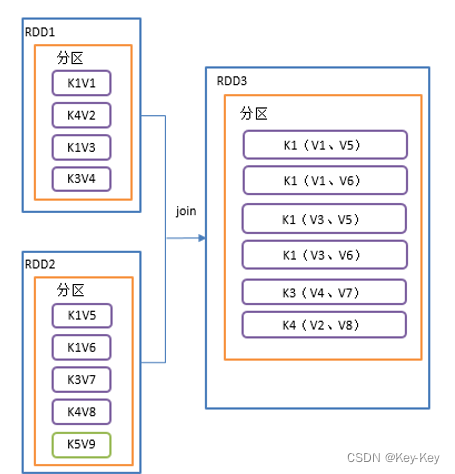
注意:如果key只是某一个rdd有,这个key不会关联
4、代码实现
object KeyValue09_join {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
//3.2 创建第二个pairRDD
val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (4, 6)))
//3.3 join操作并打印结果
rdd.join(rdd1).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
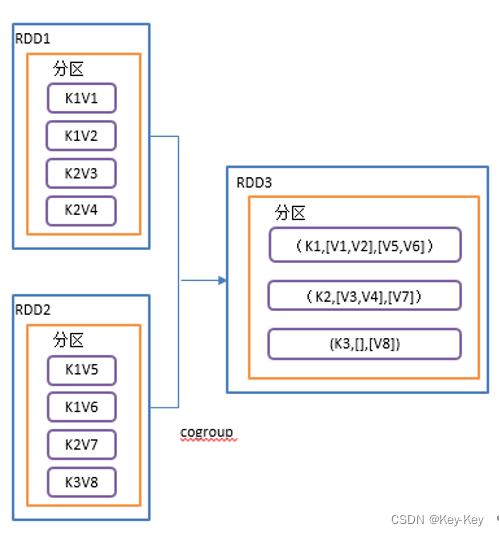
2.3.3.10 cogroup()类似于sql的全连接,但是在同一个rdd中对key聚合
1、函数签名
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
2、功能说明
在类型为(k,v)和(k,w)的rdd上调用,返回(k,(iterable,iterable))类型的rdd。
操作两个rdd中的kv元素,每个rdd中相同的key中的元素分别聚合成一个集合。
3、需求说明
创建两个pairrdd,并将key相同的数据聚合到一个迭代器
4、代码实现
object KeyValue10_cogroup {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1,"a"),(2,"b"),(3,"c")))
//3.2 创建第二个RDD
val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1,4),(2,5),(4,6)))
//3.3 cogroup两个RDD并打印结果
// (1,(CompactBuffer(a),CompactBuffer(4)))
// (2,(CompactBuffer(b),CompactBuffer(5)))
// (3,(CompactBuffer(c),CompactBuffer()))
// (4,(CompactBuffer(),CompactBuffer(6)))
rdd.cogroup(rdd1).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.3.4 案例实操(省份广告被点击top3)
1、数据准备:时间戳,省份,城市,用户,广告,中间字段使用空格分割。

2、需求:统计出每一个省份广告被点击次数的top3
3、需求分析:
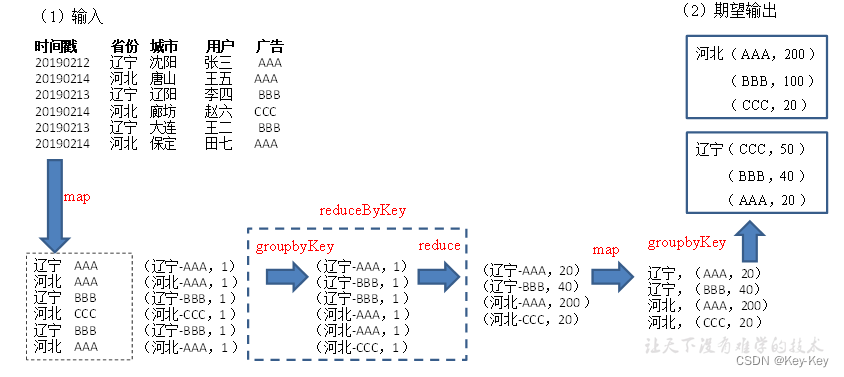
4、实现过程
object Test01_DemoTop3 {
def main(args: Array[String]): Unit = {
// 1. 创建配置对象
val conf: SparkConf = new SparkConf().setAppName("coreTest").setMaster("local[*]")
// 2. 创建sc
val sc = new SparkContext(conf)
// 3. 编写代码 执行操作
val lineRDD: RDD[String] = sc.textFile("input/agent.log")
// 步骤一: 过滤出需要的数据
val tupleRDD: RDD[(String, String)] = lineRDD.map(line => {
val data: Array[String] = line.split(" ")
(data(1), data(4))
})
// 将一行的数据转换为(省份,广告)
// tupleRDD.collect().foreach(println)
// 步骤二: 对省份加广告进行wordCount 统计
val provinceCountRDD: RDD[((String, String), Int)] = tupleRDD.map((_, 1))
.reduceByKey(_ + _)
// 一步进行过滤数据加wordCount
val tupleRDD1: RDD[((String, String), Int)] = lineRDD.map(line => {
val data: Array[String] = line.split(" ")
((data(1), data(4)), 1)
})
val provinceCountRDD1: RDD[((String, String), Int)] = tupleRDD1.reduceByKey(_ + _)
// 统计单个省份单条广告点击的次数 ((省份,广告id),count次数)
// provinceCountRDD.collect().foreach(println)
// 步骤三:分省份进行聚合
// ((省份,广告id),count次数)
// 使用groupBY的方法 数据在后面会有省份的冗余
// val provinceRDD: RDD[(String, Iterable[((String, String), Int)])] = provinceCountRDD1.groupBy(tuple => tuple._1._1)
// provinceRDD.collect().foreach(println)
// 推荐使用groupByKey => 前面已经聚合过了
// ((省份,广告id),count次数) => (省份,(广告id,count次数))
// 使用匿名函数的写法
val value: RDD[(String, (String, Int))] = provinceCountRDD1.map(tuple =>
(tuple._1._1, (tuple._1._2, tuple._2)))
// 偏函数的写法
provinceCountRDD1.map({
case ((province,id),count) => (province,(id,count))
})
val provinceRDD1: RDD[(String, Iterable[(String, Int)])] = value.groupByKey()
// (省份,(广告id,count次数)) => (省份,List((广告1,次数),(广告2,次数),(广告3,次数)))
// provinceRDD1.collect().foreach(println)
//步骤四: 对单个二元组中的value值排序取top3
// 相当于只需要对value进行处理
val result: RDD[(String, List[(String, Int)])] = provinceRDD1.mapValues(it => {
// 将list中的广告加次数排序取top3即可
val list1: List[(String, Int)] = it.toList
// 此处调用的sort是集合常用函数
// 对rdd调用的是算子 对list调用的是集合常用函数
list1.sortWith(_._2 > _._2).take(3)
})
result.collect().foreach(println)
Thread.sleep(60000)
// 4. 关闭sc
sc.stop()
}
}
2.4 action行动算子
行动算子是触发了整个作业的执行。因为转换算子都是懒加载,并不会立即执行。
1、创建包名:com.atguigu.action
2.4.1 collect()以数组的形式返回数据集
1、函数签名
def collect(): Array[T]
2、功能说明
在驱动程序中,以数组array的形式返回数据集的所有元素
注意:所有的数据都会被拉取到driver端,慎用。
3、需求说明
创建一个rdd,并将rdd内存收集到driver端打印
object action01_collect {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 收集数据到Driver
rdd.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.4.2 count()返回rdd中元素个数
1、函数签名
def count(): Long
2、功能说明:返回rdd中元素的个数
3、需求说明:创建一个rdd,统计该rdd的条数
object action02_count {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 返回RDD中元素的个数
val countResult: Long = rdd.count()
println(countResult)
//4.关闭连接
sc.stop()
}
}
2.4.3 first()返回rdd中的第一个元素
1、函数签名
def first(): T
2、功能说明
返回rdd中的第一个元素
3、需求说明
创建一个rdd,返回该rdd中的第一个元素
object action03_first {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 返回RDD中元素的个数
val firstResult: Int = rdd.first()
println(firstResult)
//4.关闭连接
sc.stop()
}
}
2.4.4 take()返回由rdd前n个元素组成的数组
1、函数签名
def take(num: Int): Array[T]
2、功能说明
返回一个由rdd的前n个元素组成的数组

3、需求说明:创建一个rdd,取出前两个元素
object action04_take {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 返回RDD中前2个元素
val takeResult: Array[Int] = rdd.take(2)
println(takeResult.mkString(","))
//4.关闭连接
sc.stop()
}
}
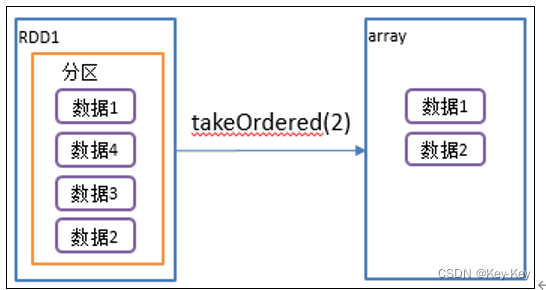
2.4.5 takeordered()返回该rdd排序后前n个元素组成的数组
1、函数签名
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]
2、功能说明
返回该rdd排序后的前n个元素组成的数组
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope {
......
if (mapRDDs.partitions.length == 0) {
Array.empty
} else {
mapRDDs.reduce { (queue1, queue2) =>
queue1 ++= queue2
queue1
}.toArray.sorted(ord)
}
}
3、需求说明
创建一个rdd,获取该rdd排序后的前两个数据
object action05_takeOrdered{
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,3,2,4))
//3.2 返回RDD中排完序后的前两个元素
val result: Array[Int] = rdd.takeOrdered(2)
println(result.mkString(","))
//4.关闭连接
sc.stop()
}
}
2.4.6 countbykey()统计每种key的个数
1、函数签名
def countByKey(): Map[K, Long]
2、功能说明
统计每种key的个数
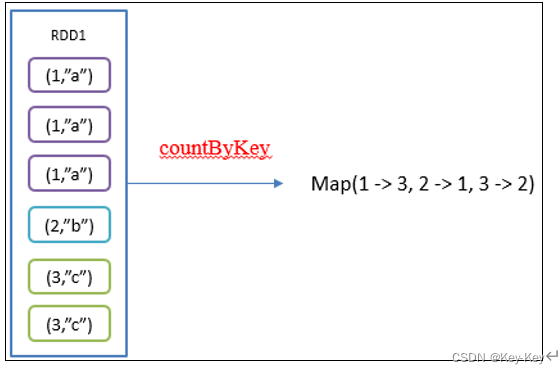
3、需求说明:创建一个pairrdd,统计每种key的个数
object action06_countByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c")))
//3.2 统计每种key的个数
val result: collection.Map[Int, Long] = rdd.countByKey()
println(result)
//4.关闭连接
sc.stop()
}
}
2.4.7 save相关算子
1、saveastextfile(path)保存成text文件
1)函数签名
2)功能说明
将数据集的元素以textfile的形式保存到hdfs文件系统或者其它支持的文件系统,对于每个元素,spark将会调用tostring方法,将它转换为文件中的文本
2、saveassequencefile(path)
1)函数签名
2)功能说明
将数据集中的元素以hadoop sequencefile的格式保存到指定的目录下,可以使hdfs或者其它hadoop支持的文件系统。
注意:只有kv类型rdd有该操作,单值的没有。
3、saveasobjectfile(path)序列化成对象保存到文件
1)函数签名
2)功能说明
用于将rdd中的元素序列化成对象,存储到文件中。
4、代码实现
object action07_save {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2)
//3.2 保存成Text文件
rdd.saveAsTextFile("output")
//3.3 序列化成对象保存到文件
rdd.saveAsObjectFile("output1")
//3.4 保存成Sequencefile文件
rdd.map((_,1)).saveAsSequenceFile("output2")
//4.关闭连接
sc.stop()
}
}
2.4.8 foreach()遍历rdd中每一个元素
1、函数签名
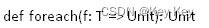
2、功能说明
遍历rdd中的每一个元素,并依次应用f函数
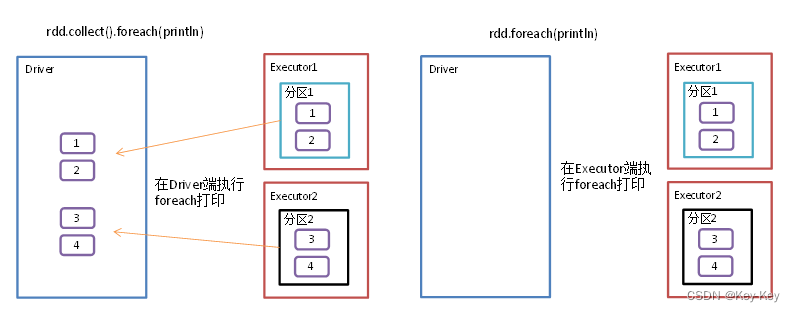
3、需求说明
创建一个rdd,对每个元素进行打印
object action08_foreach {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
// val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 收集后打印
rdd.collect().foreach(println)
println("****************")
//3.3 分布式打印
rdd.foreach(println)
//4.关闭连接
sc.stop()
}
}
2.5 rdd序列化
在实际开发中我们往往需要自己定义一些对于rdd的操作,那么此时需要注意的是,初始化工作是在driver端进行的,而实际运行程序是在executor端进行的,这就涉及到了跨进程通信,是需要序列化的。下面我们看几个例子:

2.5.1 闭包检查
1、创建闭包
com.atguigu.serializable
2、闭包引入(有闭包就需要进行序列化)
object serializable01_object {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3.创建两个对象
val user1 = new User()
user1.name = "zhangsan"
val user2 = new User()
user2.name = "lisi"
val userRDD1: RDD[User] = sc.makeRDD(List(user1, user2))
//3.1 打印,ERROR报java.io.NotSerializableException
//userRDD1.foreach(user => println(user.name))
//3.2 打印,RIGHT (因为没有传对象到Executor端)
val userRDD2: RDD[User] = sc.makeRDD(List())
//userRDD2.foreach(user => println(user.name))
//3.3 打印,ERROR Task not serializable
//注意:此段代码没执行就报错了,因为spark自带闭包检查
userRDD2.foreach(user => println(user.name+" love "+user1.name))
//4.关闭连接
sc.stop()
}
}
//case class User() {
// var name: String = _
//}
class User extends Serializable {
var name: String = _
}
2.5.2 kryo序列化框架
参考地址:https://github.com/esotericsoftware/kryo
java的序列化能够序列化任何的类。但是比较重,序列化后对象的体积也比较大。
spark出于性能的考虑,spark2.0开始支持另外一种kryo序列化机制。kryo速度是serializable的10倍。当rdd在shuffle数据的时候,简单数据类型、数组和字符串类型已经在spark内部使用kryo来序列化。
object serializable02_Kryo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("SerDemo")
.setMaster("local[*]")
// 替换默认的序列化机制
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册需要使用kryo序列化的自定义类
.registerKryoClasses(Array(classOf[Search]))
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello atguigu", "atguigu", "hahah"), 2)
val search = new Search("hello")
val result: RDD[String] = rdd.filter(search.isMatch)
result.collect.foreach(println)
}
// 关键字封装在一个类里面
// 需要自己先让类实现序列化 之后才能替换使用kryo序列化
class Search(val query: String) extends Serializable {
def isMatch(s: String): Boolean = {
s.contains(query)
}
}
}
2.6 rdd依赖关系
2.6.1 查看血缘关系
rdd只支持粗粒度转换,即在大量记录上执行的单个操作。将创建rdd的一系列lineage(血统)记录下来,以便恢复丢失的分区。rdd的lineage会记录rdd的元数据信息和转换行为,当该rdd的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。

1、创建包名:com.atguigu.dependency
2、代码实现
object Lineage01 {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.toDebugString)
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.toDebugString)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.toDebugString)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.toDebugString)
resultRDD.collect()
//4.关闭连接
sc.stop()
}
}
3、打印结果
(2) input/1.txt MapPartitionsRDD[1] at textFile at Lineage01.scala:15 []
| input/1.txt HadoopRDD[0] at textFile at Lineage01.scala:15 []
----------------------
(2) MapPartitionsRDD[2] at flatMap at Lineage01.scala:19 []
| input/1.txt MapPartitionsRDD[1] at textFile at Lineage01.scala:15 []
| input/1.txt HadoopRDD[0] at textFile at Lineage01.scala:15 []
----------------------
(2) MapPartitionsRDD[3] at map at Lineage01.scala:23 []
| MapPartitionsRDD[2] at flatMap at Lineage01.scala:19 []
| input/1.txt MapPartitionsRDD[1] at textFile at Lineage01.scala:15 []
| input/1.txt HadoopRDD[0] at textFile at Lineage01.scala:15 []
----------------------
(2) ShuffledRDD[4] at reduceByKey at Lineage01.scala:27 []
+-(2) MapPartitionsRDD[3] at map at Lineage01.scala:23 []
| MapPartitionsRDD[2] at flatMap at Lineage01.scala:19 []
| input/1.txt MapPartitionsRDD[1] at textFile at Lineage01.scala:15 []
| input/1.txt HadoopRDD[0] at textFile at Lineage01.scala:15 []
注意:圆括号中的数字表示rdd的并行度,也就是有几个分区
2.6.2 查看依赖关系
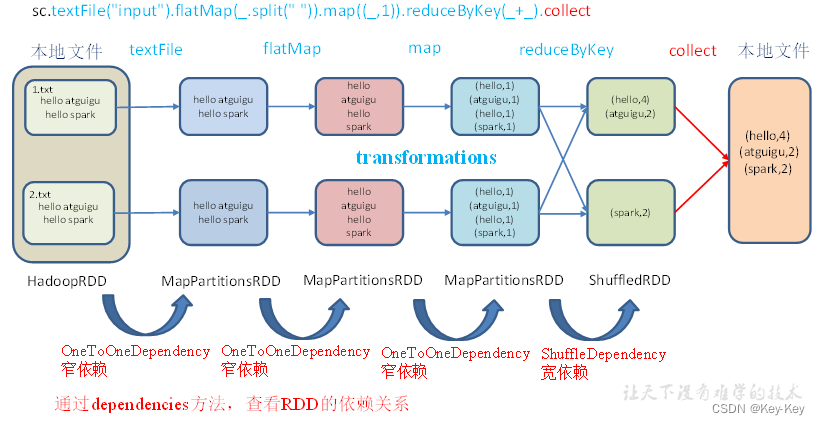
1、代码实现
object Lineage02 {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.dependencies)
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.dependencies)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.dependencies)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.dependencies)
resultRDD.collect()
// 查看localhost:4040页面,观察DAG图
Thread.sleep(10000000)
//4.关闭连接
sc.stop()
}
}
2、打印结果
List(org.apache.spark.OneToOneDependency@f2ce6b)
----------------------
List(org.apache.spark.OneToOneDependency@692fd26)
----------------------
List(org.apache.spark.OneToOneDependency@627d8516)
----------------------
List(org.apache.spark.ShuffleDependency@a518813)
3、全局搜索(ctrl+n)org.apache.spark.onetoonedependency
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}
注意:要想理解rdds是如何工作的,最重要的就是理解transformations
rdd之间的关系可以从两个维度来理解:一个是rdd是从哪些rdd转换而来,也就是rdd的parentrdd(s)是什么(血缘);另一个就是rdd依赖parentrdd(s)的哪些partition(s),这种关系就是rdd之间的依赖(依赖)。
rdd和它依赖的父rdd(s)的依赖关系有两种不同的类型,即窄依赖(narrowdepency)和宽依赖(shuffledependency)
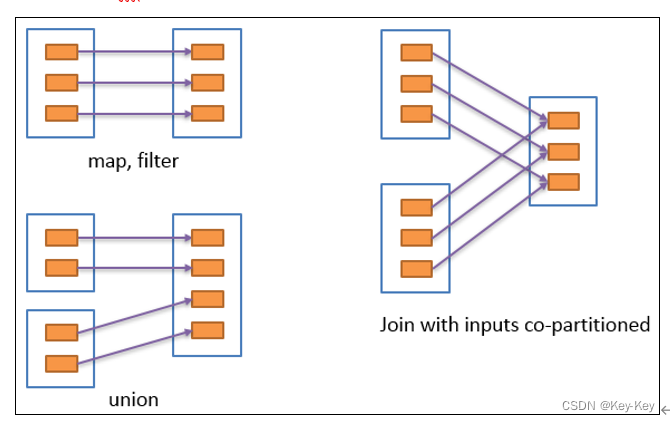
2.6.3 窄依赖
窄依赖表示每一个父rdd的partition最多被子rdd的一个partition使用(一对一 or 多对一),窄依赖我们形象的比喻为独生子女。
2.6.4 宽依赖
宽依赖表示同一个父rdd的partition被多个子rdd的partition依赖(只能是一对多),会引起shuffle,总结:宽依赖我们形象的比喻为超生。
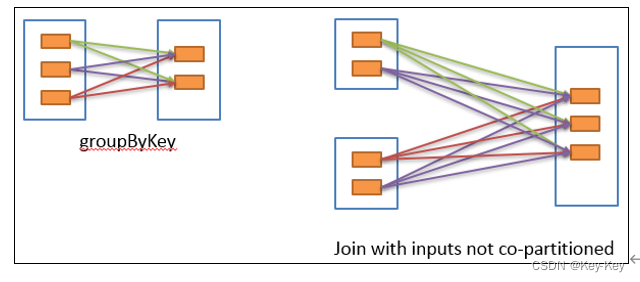
具有宽依赖的transformations包括:sort、reducebykey、groupbykey、join和调用repartition函数的任何操作。
宽依赖对spark去评估一个transformations有更加重要的影响,比如对性能的影响。在不影响业务要求的情况下,要尽量避免使用有宽依赖的转换算子,因为有宽依赖,就一定会走shuffle,影响性能。
2.6.5 stage任务划分
1、dag有向无环图
dag(directed acyclic graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。例如,dag记录了rdd的转换过程和任务的阶段。

2、任务运行的整体流程
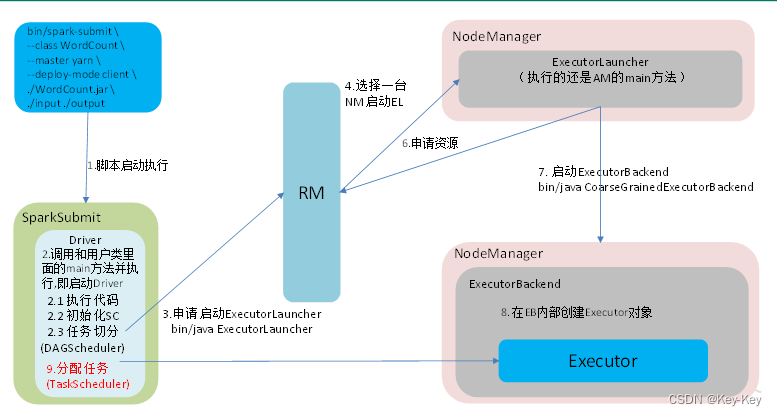
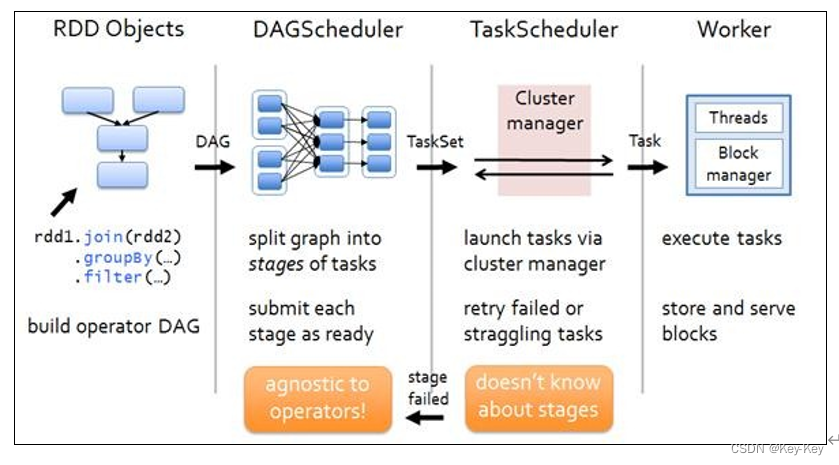
3、rdd任务切分中间分为:application、job、stage和task
1)application:初始化一个sparkcontext即生成一个application
2)job:一个action算子就会生成一个job
3)stage:stage等于宽依赖的个数加1
4)task:一个stage阶段中,最后一个rdd的分区个数就是task的个数
注意:application->job->stage-task每一层都是1对n的关系
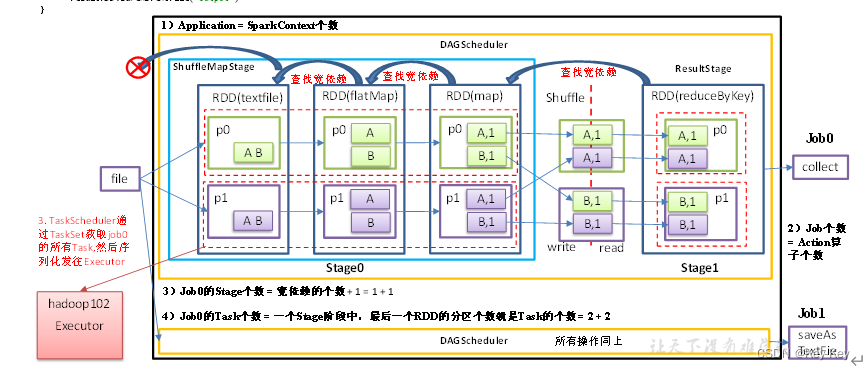
4、代码实现
object Lineage03 {
def main(args: Array[String]): Unit = {
//TODO 1 创建SparkConf配置文件,并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//TODO 2 利用SparkConf创建sc对象
//Application:初始化一个SparkContext即生成一个Application
val sc = new SparkContext(conf)
//textFile,flatMap,map算子全部是窄依赖,不会增加stage阶段
val lineRDD: RDD[String] = sc.textFile("D:\\IdeaProjects\\SparkCoreTest\\input\\1.txt")
val flatMapRDD: RDD[String] = lineRDD.flatMap(_.split(" "))
val mapRDD: RDD[(String, Int)] = flatMapRDD.map((_, 1))
//reduceByKey算子会有宽依赖,stage阶段加1,2个stage
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)
//Job:一个Action算子就会生成一个Job,2个Job
//job0打印到控制台
resultRDD.collect().foreach(println)
//job1输出到磁盘
resultRDD.saveAsTextFile("D:\\IdeaProjects\\SparkCoreTest\\out")
//阻塞线程,方便进入localhost:4040查看
Thread.sleep(Long.MaxValue)
//TODO 3 关闭资源
sc.stop()
}
}
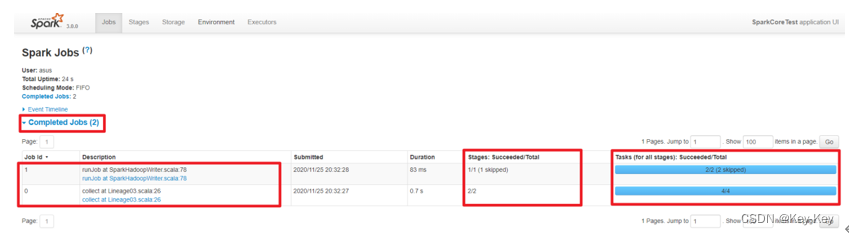
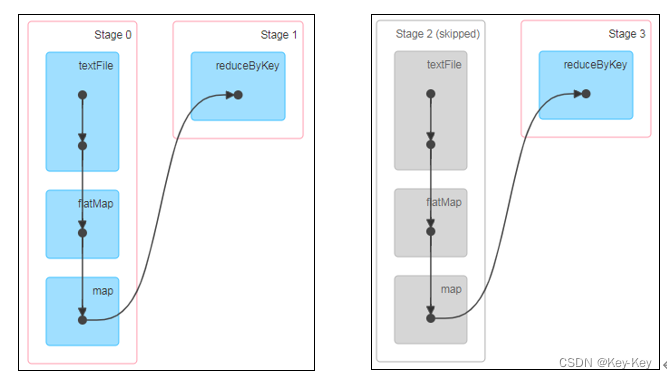
5、查看Job个数
查看http://localhost:4040/jobs/,发现job有两个
6、查看stage个数
查看job0的stage。由于只有1个shuffle阶段,所以stage个数为2
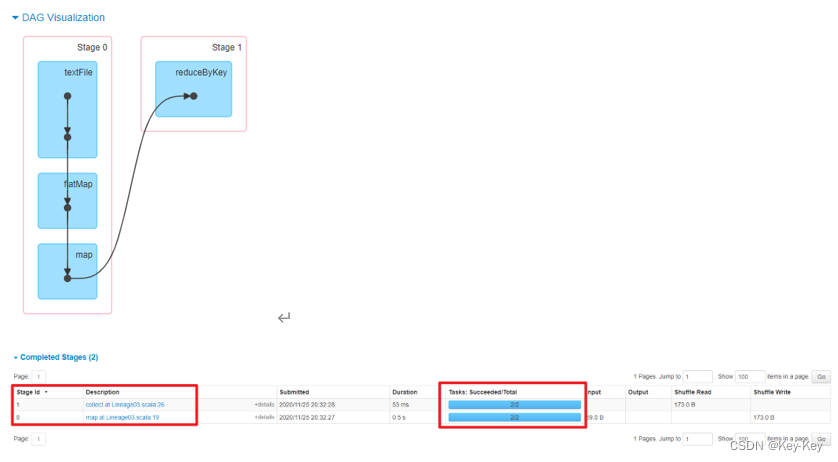
查看job1的stage。由于只有1个shuffle阶段,所以stage个数为2

7、task个数
查看job0的stage0的task个数,2个

查看job0的stage1的task个数,2个

查看job1的stage2的task个数,0个(2个跳过skipped)

查看job1的stage3的task个数,2个

注意:如果存在shuffle过程,系统会自动进行缓存,ui界面显示skipped的部分
2.7 rdd持久化
2.7.1 rdd cache缓存
rdd通过cache或者persist方法将前面的计算结果缓存,默认情况下会把数据以序列化的形式缓存在jvm的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的eaction算子时,该rdd将被缓存在计算节点的内存中,并供后面重用。

1、创建包名:com.atguigu.cache
2、代码实现
object cache01 {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3. 创建一个RDD,读取指定位置文件:hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input1")
//3.1.业务逻辑
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Int)] = wordRdd.map {
word => {
println("************")
(word, 1)
}
}
//3.5 cache缓存前打印血缘关系
println(wordToOneRdd.toDebugString)
//3.4 数据缓存。
//cache底层调用的就是persist方法,缓存级别默认用的是MEMORY_ONLY
wordToOneRdd.cache()
//3.6 persist方法可以更改存储级别
// wordToOneRdd.persist(StorageLevel.MEMORY_AND_DISK_2)
//3.2 触发执行逻辑
wordToOneRdd.collect().foreach(println)
//3.5 cache缓存后打印血缘关系
//cache操作会增加血缘关系,不改变原有的血缘关系
println(wordToOneRdd.toDebugString)
println("==================================")
//3.3 再次触发执行逻辑
wordToOneRdd.collect().foreach(println)
Thread.sleep(1000000)
//4.关闭连接
sc.stop()
}
}
3、源码解析
mapRdd.cache()
def cache(): this.type = persist()
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
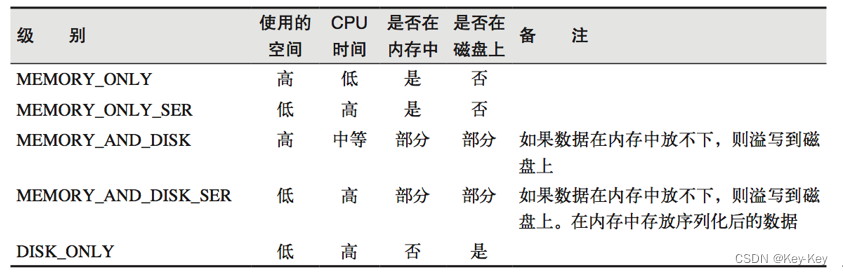
注意:默认的存储级别都是仅在内存存储一份。在存储级别的末尾加上"_2"表示持久化的数据存为两份。ser:表示序列化。
缓存有可能丢失,或者存储在内存的数据由于内存不足而被删除,rdd的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于rdd的一系列转换,丢失的数据会被重算,由于rdd的各个partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部partition。
4、自带缓存算子
spark会自动对一些shuffle操作的中间数据做持久化操作(比如:reducebykey)。这样做的目的是为了当一个节点shuffle失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用persist或cache。
object cache02 {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3. 创建一个RDD,读取指定位置文件:hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input1")
//3.1.业务逻辑
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Int)] = wordRdd.map {
word => {
println("************")
(word, 1)
}
}
// 采用reduceByKey,自带缓存
val wordByKeyRDD: RDD[(String, Int)] = wordToOneRdd.reduceByKey(_+_)
//3.5 cache操作会增加血缘关系,不改变原有的血缘关系
println(wordByKeyRDD.toDebugString)
//3.4 数据缓存。
//wordByKeyRDD.cache()
//3.2 触发执行逻辑
wordByKeyRDD.collect()
println("-----------------")
println(wordByKeyRDD.toDebugString)
//3.3 再次触发执行逻辑
wordByKeyRDD.collect()
Thread.sleep(1000000)
//4.关闭连接
sc.stop()
}
}
访问http://localhost:4040/jobs/页面,查看第一个和第二个job的dag图。说明:增加缓存后血缘依赖关系仍然有,但是,第二个job取的数据是从缓存中取得。
2.7.2 rdd checkpoint检查点
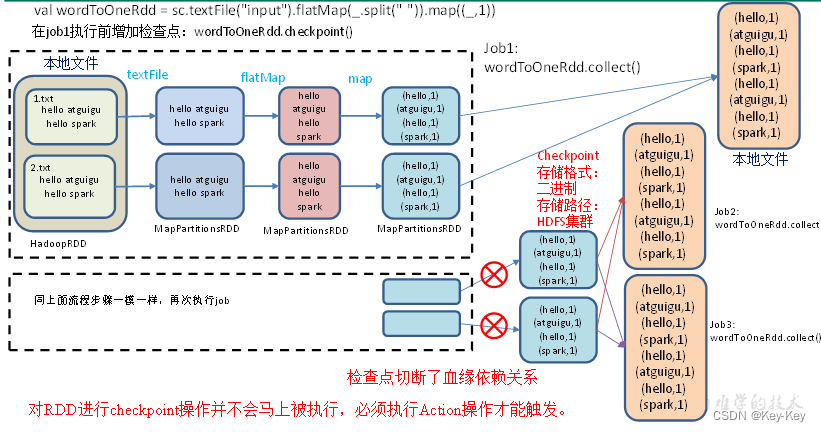
1、检查点:是通过将rdd中间结果写入磁盘。
2、为什么要做检查点?
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
3、检查点存储路径:checkpoint的数据通常是存储在hdfs等容错、高可用的文件系统
4、检查点数据存储格式为:二进制的文件
5、检查点切断血缘:在checkpoint的过程中,该rdd的所有依赖与父rdd中的信息将全部被溢出。
6、检查点触发事件:对rdd进行checkpoint操作并不会马上被执行,必须执行action操作才能触发。但是检查点为了数据安全,会从血缘关系的最开始执行一遍。
checkpoint检查点
7、设置检查点步骤
1)设置检查点数据存储路径:sc.setcheckpointdir(“./checkpoint1”)
2)调用检查点方法:wordtoonerdd.checkpoint()
8、代码实现
object checkpoint01 {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
// 需要设置路径,否则抛异常:Checkpoint directory has not been set in the SparkContext
sc.setCheckpointDir("./checkpoint1")
//3. 创建一个RDD,读取指定位置文件:hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input1")
//3.1.业务逻辑
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {
word => {
(word, System.currentTimeMillis())
}
}
//3.5 增加缓存,避免再重新跑一个job做checkpoint
// wordToOneRdd.cache()
//3.4 数据检查点:针对wordToOneRdd做检查点计算
wordToOneRdd.checkpoint()
//3.2 触发执行逻辑
wordToOneRdd.collect().foreach(println)
// 会立即启动一个新的job来专门的做checkpoint运算
//3.3 再次触发执行逻辑
wordToOneRdd.collect().foreach(println)
wordToOneRdd.collect().foreach(println)
Thread.sleep(10000000)
//4.关闭连接
sc.stop()
}
}
9、执行结果
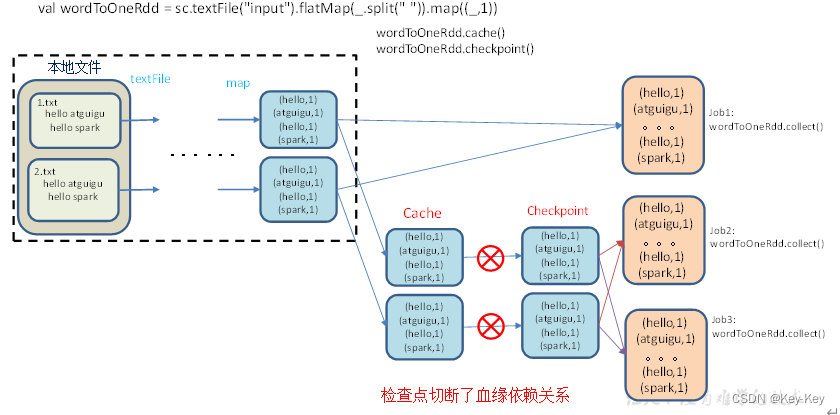
访问http://localhost:4040/jobs/页面,查看4个job的dag图。其中第2个图是checkpoint的job运行dag图。第3、4张图说明,检查点切断了血缘依赖关系。
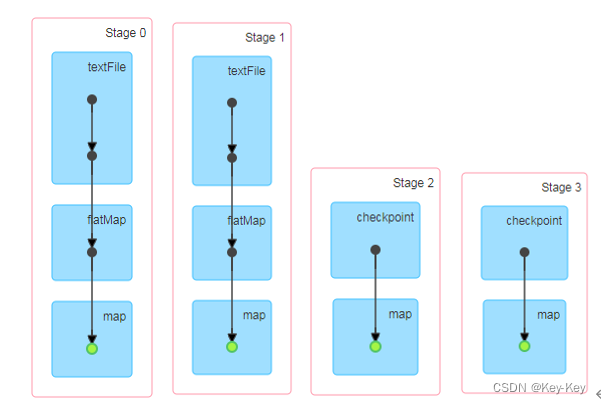
1)只增加checkpoint,没有增加cache缓存打印
第一个job执行完,触发了checkpoint,第2个job运行checkpoint,并把数据存储在检查点上。第3、4个job,数据从检查点上直接读取。

2)增加checkpoint,也增加cache缓存打印
第1个job执行完,数据就保存到Cache里面了,第2个job运行checkpoint,直接读cache里面的数据,并把数据存储在检查点上。第3、4个job,数据从检查点上直接读取。

checkpoint检查点+缓存
2.7.3 缓存和检查点区别
1、cache缓存只是将数据保存起来,不切断血缘依赖。checkpoint检查点切断血缘依赖。
2、cache缓存的数据通常存储在磁盘、内存等地方,可靠性低。checkpoint的数据通常存储在hdfs等容错、高可用的文件系统,可靠性高。
3、建议对checkpoint()的rdd使用cache缓存,这样checkpoint的job只需从cache缓存中读取数据即可,否则需要再从头计算一次rdd。
4、如果使用完了缓存,可用通过unpersist()方法释放缓存。
2.7.4 检查点存储到hdfs集群
如果检查点数据存储到hdfs集群,要注意配置访问集群的用户名。否则会报访问权限异常。
object checkpoint02 {
def main(args: Array[String]): Unit = {
// 设置访问HDFS集群的用户名
System.setProperty("HADOOP_USER_NAME","atguigu")
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
// 需要设置路径.需要提前在HDFS集群上创建/checkpoint路径
sc.setCheckpointDir("hdfs://hadoop102:8020/checkpoint")
//3. 创建一个RDD,读取指定位置文件:hello atguigu atguigu
val lineRdd: RDD[String] = sc.textFile("input1")
//3.1.业务逻辑
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {
word => {
(word, System.currentTimeMillis())
}
}
//3.4 增加缓存,避免再重新跑一个job做checkpoint
wordToOneRdd.cache()
//3.3 数据检查点:针对wordToOneRdd做检查点计算
wordToOneRdd.checkpoint()
//3.2 触发执行逻辑
wordToOneRdd.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
2.8 键值对rdd数据分区
spark目前支持hash分区、range分区和用户自定义分区。hash分区为当前的默认分区。分区器直接决定了rdd中分区的个数、rdd中每条数据经过shuffle后进入哪个分区和reduce的个数。
1、注意:
1)只有Key-value类型的rdd才有分区号,非key-value类型的rdd分区的值是none
2)每个rdd的分区id范围:0~numpartitions-1,决定这个值是属于哪个分区的
2、获取rdd分区
1)创建包名:com.atguigu.partitioner
2)代码实现
object partitioner01_get {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3 创建RDD
val pairRDD: RDD[(Int, Int)] = sc.makeRDD(List((1,1),(2,2),(3,3)))
//3.1 打印分区器
println(pairRDD.partitioner)
//3.2 使用HashPartitioner对RDD进行重新分区
val partitionRDD: RDD[(Int, Int)] = pairRDD.partitionBy(new HashPartitioner(2))
//3.3 打印分区器
println(partitionRDD.partitioner)
//4.关闭连接
sc.stop()
}
}
2.8.1 hash分区
hashpartitioner分区的原理:对于给定的key,计算其hashcode,并除以分区的个数取余,如果余数小于0,则用余数+分区的个数(否则加0),最后返回的值就是这个key所属分区

hashpartitioner分区弊端:可能导致每个分区中数据量的不均匀,极端情况下会导致某个分区拥有rdd的全部数据。
2.8.2 ranger分区
rangepartitioner作用:将一定范围内的数映射到某一个分区内,尽量保证每个分区中数据量均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大,但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。
实现过程为:
1、先从整个rdd中采用水塘抽样算法,抽取出样本数据,将样本数据排序,计算出每个分区最大key值,形成一个array[key]类型的数组变量rangebounds。
2、判断key在rangebounds中所处的范围,给出该key值再下一个rdd中的分区id下表;该分区器要求rdd中的key类型必须是可以排序的。

第 3 章:累加器
累加器:分布式共享只写变量。(executor和executor之间不能读数据)
累加器用来把executor端变量信息聚合到driver端。在driver中定义的一个变量,在executor端的每个task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回driver端进行合并计算。

1、累加器使用
1)累加器定义(sparkcontext.accumulator(initialvalue)方法)
val sum: LongAccumulator = sc.longAccumulator("sum")
2)累加器添加数据(累加器.add方法)
sum.add(count)
3)累加器获取数据(累加器.value)
sum.value
2、创建包名:com.atguigu.accumulator
3、代码实现
object accumulator01_system {
package com.atguigu.cache
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
object accumulator01_system {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val dataRDD: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4)))
//需求:统计a出现的所有次数 ("a",10)
//普通算子实现 reduceByKey 代码会走shuffle 效率低
//val rdd1: RDD[(String, Int)] = dataRDD.reduceByKey(_ + _)
//普通变量无法实现
//结论:普通变量只能从driver端发给executor端,在executor计算完以后,结果不会返回给driver端
/*
var sum = 0
dataRDD.foreach{
case (a,count) => {
sum += count
println("sum = " + sum)
}
}
println(("a",sum))
*/
//累加器实现
//1 声明累加器
val accSum: LongAccumulator = sc.longAccumulator("sum")
dataRDD.foreach{
case (a,count) => {
//2 使用累加器累加 累加器.add()
accSum.add(count)
// 4 不要在executor端获取累加器的值,因为不准确
//因此我们说累加器叫分布式共享只写变量
//println("sum = " + accSum.value)
}
}
//3 获取累加器的值 累加器.value
println(("a",accSum.value))
sc.stop()
}
}
注意:executor端的任务不能读取累加器的值(例如:在executor端调用sum.value,获取的值不是累加器最终的值)。因此我们说,累加器事一个分布式共享只写变量。累加器要放在行动算子中。因为转换算子执行的次数取决于job的数量,如果一个spark应用有多个行动算子,那么转换算子中的累加器可能会不止一次更新,导致结果错误。所以,如果想要一个无论是失败还是重复计算时都绝对可靠的累加器,我们必须把它放在foreach()这样的行动算子中。
对于在行动算子中使用的累加器,spark只会把每个job对各累加器的修改应用一次。
object accumulator02_updateCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val dataRDD: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4)))
//需求:统计a出现的所有次数 ("a",10)
//累加器实现
//1 声明累加器
val accSum: LongAccumulator = sc.longAccumulator("sum")
val mapRDD: RDD[Unit] = dataRDD.map {
case (a, count) => {
//2 使用累加器累加 累加器.add()
accSum.add(count)
// 4 不要在executor端获取累加器的值,因为不准确 因此我们说累加器叫分布式共享只写变量
//println("sum = " + accSum.value)
}
}
//调用两次行动算子,map执行两次,导致最终累加器的值翻倍
mapRDD.collect()
mapRDD.collect()
/**
* 结论:使用累加器最好要在行动算子中使用,因为行动算子只会执行一次,而转换算子的执行次数不确定!
*/
//2 获取累加器的值 累加器.value
println(("a",accSum.value))
sc.stop()
}
}
一般在开发中使用的累加器为集合累加器,在某些场景可以减少shuffle
现在我们用集合累加器实现wordcount:
object Test02_Acc {
def main(args: Array[String]): Unit = {
//1、创建sparkcontext配置
val conf = new SparkConf().setMaster("local[4]").setAppName("test")
//2、创建sparkcontext
val sc = new SparkContext(conf)
//3、创建集合累加器,累加元素为Map
val acc = sc.collectionAccumulator[mutable.Map[String,Int]]
//4、读取文件
val rdd1 = sc.textFile("datas/wc.txt")
//5、切割+转换
val rdd2 = rdd1.flatMap(x=>x.split(" "))
//6、转换为KV键值对
val rdd3 = rdd2.map(x=>(x,1))
//7、使用foreachPartitions在每个分区中对所有单词累加,将累加结果放入累加器中
rdd3.foreachPartition(it=> {
//创建一个累加Map容器
val map = mutable.Map[String,Int]()
//遍历分区数据
it.foreach(x=>{
val num = map.getOrElse(x._1,0)
//将单词累加到map容器中
map.put(x._1,num+x._2)
})
//将装载分区累加结果的map容器放入累加器中
acc.add(map)
})
//为了方便操作,将java集合转成scala集合
import scala.collection.JavaConverters._
//获取累加器结果,此时List中的每个Map是之前放入累加器的分区累加结果Map
val r = acc.value.asScala
//压平,将所有分区计算结果放入List中
val pList = r.flatten
//按照单词分组
val rMap = pList.groupBy(x=>x._1)
//,统计每个单词总个数
val result = rMap.map(x => (x._1, x._2.map(_._2).sum))
println(result)
// 4.关闭sc
sc.stop()
}
}
第 4 章:广播变量
广播变量:分布式共享只读变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个spark task操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量会用起来会很顺手。在多个task并行操作中使用同一个变量,但是spark会为每个task任务分别发送。
1、使用广播变量步骤:
1)调用sparkcontext.broadcast(广播变量)创建出一个广播对象,任何可序列化的类型都可以这么实现。
2)通过广播变量.value,访问该对象的值。
3)广播变量只会被发到各个节点一次,作为只读值处理(修改这个值不会影响到别的节点)。
2、原理说明
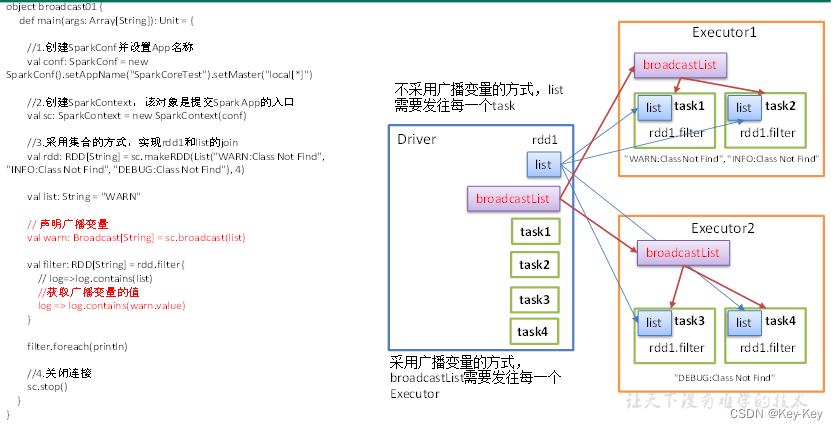
3、创建包名:com.atguigu.broadcast
4、代码实现
object broadcast01 {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3.创建一个字符串RDD,过滤出包含WARN的数据
val rdd: RDD[String] = sc.makeRDD(List("WARN:Class Not Find", "INFO:Class Not Find", "DEBUG:Class Not Find"), 4)
val str: String = "WARN"
// 声明广播变量
val bdStr: Broadcast[String] = sc.broadcast(str)
val filterRDD: RDD[String] = rdd.filter {
// log=>log.contains(str)
log => log.contains(bdStr.value)
}
filterRDD.foreach(println)
//4.关闭连接
sc.stop()
}
}
第 5 章:sparkcore实战
5.1 数据准备
1、数据格式

1)数据采用_分割字段
2)每一行表示用户的一个行为,所以每一行只能是四种行为中的一种
3)如果点击的品类id和产品id是-1表示这次不是点击
4)针对下单行为,一次可以下单多个产品,所以品类id和产品id都是多个,id之间使用逗号分割。如果本次不是下单行为,则他们相关数据用null来表示。
5)支付行为和下单行为格式类似。
2、数据详情字段说明
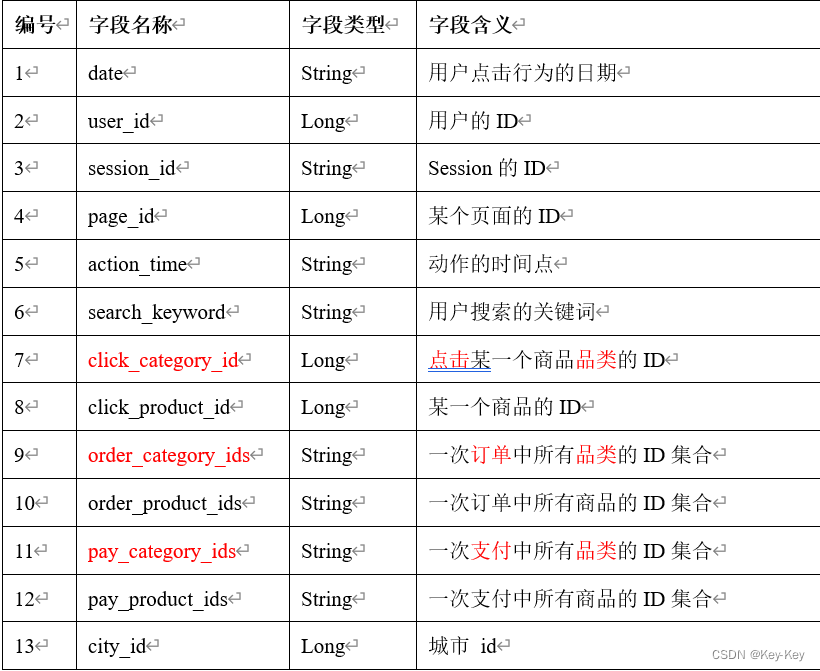
5.2 需求:top10热门品类

需求说明:品类是指产品的分类,大型电商网站品类分多级,咱们的项目中品类只有一级,不同的公司可能对热门的定义不一样。我们按照每个品类的点击、下单、支付的量(次数)来统计热门品类。

例如:综合排名=点击数20%+下单数30%+支付书数*50%
本项目需求优化为:先按照点击数排名,考前的就排名高;如果点击数相同,再比较下单数;下单数相同,就比较支付数。
5.2.1 需求分析(方案一)常规算子
思路:分别统计每个品类点击的次数,下单的次数和支付的次数。然后想办法将三个rdd联合在一块。
(品类,点击总数)(品类,下单总数)(品类,支付总数)
(品类,(点击总数,下单总数,支付总数))
然后就可以按照各品类的元组(点击总数,下单总数,支付总数)进行倒叙排序了,因为元组排序刚好是先排第一个元素,然后排第二个元素,最后第三个元素。最后取top10即可。
5.2.2 需求实现(方案一)
1)创建包名:com.atguigu.project01
2)方案一:代码实现(cogroup算子实现满外连接)
package com.atguigu.spark.demo
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test01_Top10 {
def main(args: Array[String]): Unit = {
// 1. 创建配置对象
val conf: SparkConf = new SparkConf().setAppName("sparkCore").setMaster("local[*]")
// 2. 初始化sc
val sc = new SparkContext(conf)
// 3. 编写代码
// 需求: top10的热门品类 通过(id,(点击,下单,支付))
val lineRDD: RDD[String] = sc.textFile("input/user_visit_action.txt")
// 1. 过滤点击数据 进行统计
val clickRDD: RDD[String] = lineRDD.filter(line => {
val data: Array[String] = line.split("_")
// 读进来的数据全部都是字符串
data(6) != "-1"
})
// 统计品类点击次数即可
val clickCountRDD: RDD[(String, Int)] = clickRDD.map(line => {
val data: Array[String] = line.split("_")
(data(6), 1)
})
.reduceByKey(_ + _)
// 2. 过滤统计下单品类
val orderRDD: RDD[String] = lineRDD.filter(line => {
val data: Array[String] = line.split("_")
data(8) != "null"
})
val orderCountRDD: RDD[(String, Int)] = orderRDD.flatMap(line => {
// 切分整行数据
val data: Array[String] = line.split("_")
// 切分下单品类
val orders: Array[String] = data(8).split(",")
// 改变数据结构 (下单品类,1)
orders.map((_, 1))
}).reduceByKey(_ + _)
// 3. 过滤统计支付品类数据
val payRDD: RDD[String] = lineRDD.filter(line => {
val data: Array[String] = line.split("_")
data(10) != "null"
})
val payCountRDD: RDD[(String, Int)] = payRDD.flatMap(line => {
val data: Array[String] = line.split("_")
val pays: Array[String] = data(10).split(",")
pays.map((_, 1))
}).reduceByKey(_ + _)
// 使用cogroup满外连接 避免使用join出现有的品类只有点击没有下单支付 造成数据丢失
val cogroupRDD: RDD[(String, (Iterable[Int], Iterable[Int], Iterable[Int]))] = clickCountRDD.cogroup(orderCountRDD, payCountRDD)
// 改变数据结构 (id,(list(所有当前id的点击数据),list(所有当前id的下单数据),list(所有当前id的支付数据)))
val cogroupRDD2: RDD[(String, (Int, Int, Int))] = cogroupRDD.mapValues({
case (clickList, orderList, payList) => (clickList.sum, orderList.sum, payList.sum)
})
// 排序取top10
val result: Array[(String, (Int, Int, Int))] = cogroupRDD2.sortBy(_._2, false).take(10)
result.foreach(println)
Thread.sleep(600000)
// 4.关闭sc
sc.stop()
}
}
3)一次计算,转换数据结构,通过位置标记数据的类型,不再使用三次过滤,减少reducebykey的次数
package com.atguigu.spark.demo
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test02_Top10 {
def main(args: Array[String]): Unit = {
// 1. 创建配置对象
val conf: SparkConf = new SparkConf().setAppName("sparkCore").setMaster("local[*]")
// 2. 初始化sc
val sc = new SparkContext(conf)
// 3. 编写代码
// 需求: top10的热门品类 通过(id,(点击,下单,支付))
val lineRDD: RDD[String] = sc.textFile("input/user_visit_action.txt")
// 通过位置来标记属于什么类型的数据
// val filterRDD: RDD[String] = lineRDD.filter(line => {
// val data: Array[String] = line.split("_")
// // 过滤出所有的点击 下单 支付数据
// data(6) != "-1" || data(8) != "null" || data(10) != "null"
// })
// 转换数据结构
// 1. 点击数据 -> (id,(1,0,0))
// 2. 下单数据 -> (id,(0,1,0))
// 3. 支付数据 -> (id,(0,0,1))
val flatMapRDD: RDD[(String, (Int, Int, Int))] = lineRDD.flatMap(line => {
val data: Array[String] = line.split("_")
// 判断属于三种的哪一种
if (data(6) != "-1") {
// 点击数据
List((data(6), (1, 0, 0)))
} else if (data(8) != "null") {
// 下单数据
// 此处为数组 需要拆分为多个
val orders: Array[String] = data(8).split(",")
// 多个订单(15,13,5) => (15,(0,1,0)),(13,(0,1,0))...
orders.map(order => (order, (0, 1, 0)))
} else if (data(10) != "null") {
// 支付数据
val pays: Array[String] = data(10).split(",")
pays.map(pay => (pay, (0, 0, 1)))
} else {
List()
}
})
val reduceRDD: RDD[(String, (Int, Int, Int))] = flatMapRDD.reduceByKey((res, elem) => (res._1 + elem._1, res._2 + elem._2, res._3 + elem._3))
val result: Array[(String, (Int, Int, Int))] = reduceRDD.sortBy(_._2, false).take(10)
result.foreach(println)
Thread.sleep(600000)
// 4.关闭sc
sc.stop()
}
}
5.2.3 需求分析(方案二)样例类
使用样例类的方式实现。

5.2.4 需求实现(方案二)
1、用来封装用户行为的样例类
//用户访问动作表
case class UserVisitAction(date: String,//用户点击行为的日期
user_id: String,//用户的ID
session_id: String,//Session的ID
page_id: String,//某个页面的ID
action_time: String,//动作的时间点
search_keyword: String,//用户搜索的关键词
click_category_id: String,//某一个商品品类的ID
click_product_id: String,//某一个商品的ID
order_category_ids: String,//一次订单中所有品类的ID集合
order_product_ids: String,//一次订单中所有商品的ID集合
pay_category_ids: String,//一次支付中所有品类的ID集合
pay_product_ids: String,//一次支付中所有商品的ID集合
city_id: String)//城市 id
// 输出结果表
case class CategoryCountInfo(categoryId: String,//品类id
clickCount: Long,//点击次数
orderCount: Long,//订单次数
payCount: Long)//支付次数
注意:样例类的属性默认是val修饰,不能修改;需要修改属性,需要采用var修饰。
// 输出结果表
case class CategoryCountInfo(var categoryId: String,//品类id
var clickCount: Long,//点击次数
var orderCount: Long,//订单次数
var payCount: Long)//支付次数
注意:样例类的属性默认是val修饰,不能修改;需要修改属性,需要采用var修饰。
2、核心业务代码实现
package com.atguigu.spark.demo
import com.atguigu.spark.demo.bean.{CategoryCountInfo, UserVisitAction}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test04_Top10 {
def main(args: Array[String]): Unit = {
// 1. 创建配置对象
val conf: SparkConf = new SparkConf().setAppName("sparkCore").setMaster("local[*]")
// 2. 初始化sc
val sc = new SparkContext(conf)
// 3. 编写代码
// 读取数据
val lineRDD: RDD[String] = sc.textFile("input/user_visit_action.txt")
// 转换为样例类
val userRDD: RDD[UserVisitAction] = lineRDD.map(line => {
val data: Array[String] = line.split("_")
UserVisitAction(
data(0),
data(1),
data(2),
data(3),
data(4),
data(5),
data(6),
data(7),
data(8),
data(9),
data(10),
data(11),
data(12)
)
})
//切分数据为单个品类
val categoryRDD: RDD[CategoryCountInfo] = userRDD.flatMap(user => {
if (user.click_category_id != "-1") {
// 点击数据
List(CategoryCountInfo(user.click_category_id, 1, 0, 0))
} else if (user.order_category_ids != "null") {
// 下单数据
val orders: Array[String] = user.order_category_ids.split(",")
orders.map(order => CategoryCountInfo(order, 0, 1, 0))
} else if (user.pay_category_ids != "null") {
// 支付数据
val pays: Array[String] = user.pay_category_ids.split(",")
pays.map(pay => CategoryCountInfo(pay, 0, 0, 1))
} else {
List()
}
})
// 聚合同一品类的数据
val groupRDD: RDD[(String, Iterable[CategoryCountInfo])] = categoryRDD.groupBy(_.categoryId)
val value: RDD[(String, CategoryCountInfo)] = groupRDD.mapValues(list => {
// 集合常用函数
list.reduce((res, elem) => {
res.clickCount += elem.clickCount
res.orderCount += elem.orderCount
res.payCount += elem.payCount
res
})
})
val categoryReduceRDD: RDD[CategoryCountInfo] = value.map(_._2)
// 排序取top10
val result: Array[CategoryCountInfo] = categoryReduceRDD.sortBy(info =>
(info.clickCount, info.orderCount, info.payCount),false)
.take(10)
result.foreach(println)
Thread.sleep(600000)
// 4.关闭sc
sc.stop()
}
}
5.2.5 需求分析(方案三)样例类+算子优化
针对方案二中的groupby算子,没有提前聚合的功能,替换成reducebykey

5.2.6 需求实现(方案三)
1、样例类代码和方案二一样。
2、核心代码实现
package com.atguigu.spark.demo
import com.atguigu.spark.demo.bean.{CategoryCountInfo, UserVisitAction}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test05_Top10 {
def main(args: Array[String]): Unit = {
// 1. 创建配置对象
val conf: SparkConf = new SparkConf().setAppName("sparkCore").setMaster("local[*]")
// 2. 初始化sc
val sc = new SparkContext(conf)
// 3. 编写代码
// 读取数据
val lineRDD: RDD[String] = sc.textFile("input/user_visit_action.txt")
// 转换为样例类
val userRDD: RDD[UserVisitAction] = lineRDD.map(line => {
val data: Array[String] = line.split("_")
UserVisitAction(
data(0),
data(1),
data(2),
data(3),
data(4),
data(5),
data(6),
data(7),
data(8),
data(9),
data(10),
data(11),
data(12)
)
})
//切分数据为单个品类
val categoryRDD: RDD[CategoryCountInfo] = userRDD.flatMap(user => {
if (user.click_category_id != "-1") {
// 点击数据
List(CategoryCountInfo(user.click_category_id, 1, 0, 0))
} else if (user.order_category_ids != "null") {
// 下单数据
val orders: Array[String] = user.order_category_ids.split(",")
orders.map(order => CategoryCountInfo(order, 0, 1, 0))
} else if (user.pay_category_ids != "null") {
// 支付数据
val pays: Array[String] = user.pay_category_ids.split(",")
pays.map(pay => CategoryCountInfo(pay, 0, 0, 1))
} else {
List()
}
})
// 聚合同一品类的数据
// 使用reduceByKey调换groupBy (重要)
val reduceRDD: RDD[(String, CategoryCountInfo)] = categoryRDD.map(info => (info.categoryId, info))
.reduceByKey((res, elem) => {
res.clickCount += elem.clickCount
res.orderCount += elem.orderCount
res.payCount += elem.payCount
res
})
val categoryReduceRDD: RDD[CategoryCountInfo] = reduceRDD.map(_._2)
// 排序取top10
val result: Array[CategoryCountInfo] = categoryReduceRDD.sortBy(info =>
(info.clickCount, info.orderCount, info.payCount),false)
.take(10)
result.foreach(println)
Thread.sleep(600000)
// 4.关闭sc
sc.stop()
}
}
第 1 章:spark sql概述
1.1 什么是spark sql
1、spark sql是spark用于结构化数据处理的spark模块
1)半结构化数据(日志数据)

2)结构化数据(数据库数据)

1.2 为什么要有sparksql

hive on spark:hive既作为存储元数据又负责sql的解析优化,语法是hql语法,执行引擎编程了spark,spark负责采用rdd执行。
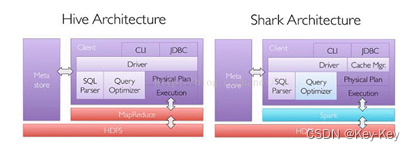
spark on hive:hive只作为存储元数据,spark负责sql解析优化,语法是spark sql语法,spark底层采用优化后的df或者ds执行。
1.3 spark sql原理
spark sql它提供了2个编程抽象,dataframe、dataset(类似spark core中的rdd)

1.3.1 什么是dataframe
1、dataframe是一种类似rdd的分布式数据集,类似于传统数据库中的二维表格。
2、dataframe与rdd的主要区别在于,dataframe带有schema元信息,即dataframe所表示的二维表数据集的每一列都带有名称和类型。
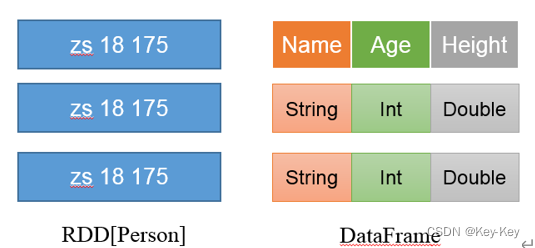
左侧的rdd[person]虽然person为类型参数,但spark框架本身不了解person类的内部结构。而右侧的dataframe却提供了详细的结构信息,使得spark sql可以清楚的指导这些数据集中包含哪些列,每列的名称和类型各是什么。
3、spark sql性能上比rdd要高。因为spark sql了解数据内部结构,从而对藏于dataframe背后的数据源以及作用域dataframe之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观rdd,由于无从得知所存数据元素的具体内部结构,spark core只能在stage层面进行简单、通用的流水线优化。
1.3.2 什么是dataset
dataset是分布式数据集。
dataset是强类型的。比如可以有dataset[car],dataset[user]。具有类型安全检查。
dataframe是dataset的特例,type dataframe=dataset[row],row是一个类型,跟car、user这些的类型一样,所有的表结构信息都用row来表示。
1.3.3 rdd、dataframe和dataset之间关系
1、发展历史
如果同样的数据都给到这三种数据结构,他们分别计算之后,都会给出相同的结果。不同的是他们的执行效率和执行方式。在后期的spark版本中,dataset有可能会逐步取代rdd和dataframe成为唯一的api接口。
2、三者的共性
1)rdd、dataframe、dataset全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利。
2)三者都是惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到action行动算子如foreach时,三者才会开始遍历运算
3)三者有许多共同的函数,如filter,排序等
4)三者都会根据spark的内存情况自动缓存运算
5)三者都有分区概念
1.4 spark sql的特点
1、易整合
无缝的整合了sql查询和spark编程。

2、统一的数据访问方式
使用相同的方式连接不同的数据源

3、兼容hive
在已有的仓库上直接运行sql或者hql
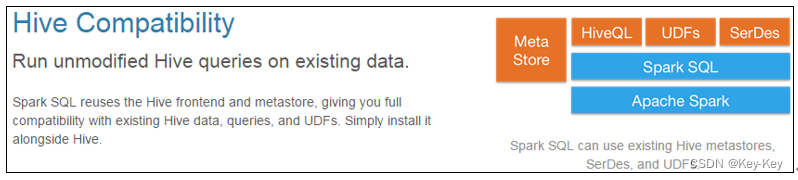
4、标准的数据连接
通过jdbc或者odbc来连接

第2 章:spark sql编程
本章重点学习如何使用dataframe和dataset进行编程,以及他们之间的关系和转换,关于具体的sql书写不是本章的重点。
2.1 sparksession新的起始点
在老的版本中,sparksql提供两种sql查询起始点:
1、一个是sqlcontext,用于spark自己提供的sql查询
2、一个叫hivecontext,用于连接hive的查询
sparksession是spark最新的sql查询起始点,实质上是sqlcontext和hivecontext的组合,所以在sqlcontext和hivecontext上可用的api在sparksession上同样是可用使用的。
sparksession内部封装了sparkcontext,所以计算实际上是由sparkcontext完成的。当我们使用spark-shell的时候,spark框架会自动地创建一个名称叫做spark的sparksession,就像我们以前可以自动获取到一个sc来表示sparkcontext。
[atguigu@hadoop102 spark-local]$ bin/spark-shell
20/09/12 11:16:35 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop102:4040
Spark context available as 'sc' (master = local[*], app id = local-1599880621394).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
2.2 dataframe
dataframe是一种类似于rdd的分布式数据集,类似于传统数据库中的二维表格
2.2.1 创建dataframe
在spark sql中sparksession是创建dataframe和执行sql的入口,创建dataframe有三种方式:
通过spark的数据源进行创建;
从一个存在的rdd进行转换;
还可以从hive table进行查询返回;
1、从spark数据源进行创建
1)数据准备,在/opt/module/spark-local目录下创建一个user.json文件
{"age":20,"name":"qiaofeng"}
{"age":19,"name":"xuzhu"}
{"age":18,"name":"duanyu"}
2)查看spark支持创建文件的数据源格式,使用tab键查看
scala> spark.read.
csv format jdbc json load option options orc parquet schema table text textFile
3)读取json文件创建dataframe
scala> val df = spark.read.json("/opt/module/spark-local/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
注意:如果从内存种获取数据,spark可以指导数据类型具体是什么,如果是数字,默认作为int处理;但是从文件种读取的数字,不能确定是什么类型,所以用bigint接收,可以和long类型转换,但是和int不能进行转换。
4)查看dataframe算子
scala> df.
5)展示结果
scala> df.show
+---+--------+
|age| name|
+---+--------+
| 20|qiaofeng|
| 19| xuzhu|
| 18| duanyu|
+---+--------+
2、从rdd进行转换
3、hive table进行查询返回
2.2.2 sql风格语法
sql语法风格是指我们查询数据的时候使用sql语句来查询,这种风格的查询必须要有临时视图或者全局视图来辅助。
视图:对特定表的数据的查询结果重复使用。view只能查询,不能修改和插入。
1、临时视图
1)创建一个dataframe
scala> val df = spark.read.json("/opt/module/spark-local/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2)对dataframe创建一个临时视图
scala> df.createOrReplaceTempView("user")
3)通过sql语句实现查询全表
scala> val sqlDF = spark.sql("SELECT * FROM user")
sqlDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
(4)结果展示
4)结果展示
scala> sqlDF.show
+---+--------+
|age| name|
+---+--------+
| 20|qiaofeng|
| 19| xuzhu|
| 18| duanyu|
+---+--------+
5)求年龄的平均值
scala> val sqlDF = spark.sql("SELECT avg(age) from user")
sqlDF: org.apache.spark.sql.DataFrame = [avg(age): double]
6)结果展示
scala> sqlDF.show
+--------+
|avg(age)|
+--------+
| 19.0|
+--------+
7)创建一个新会话再执行,发现视图找不到
scala> spark.newSession().sql("SELECT avg(age) from user ").show()
org.apache.spark.sql.AnalysisException: Table or view not found: user; line 1 pos 14;
注意:普通临时视图是session范围内的,如果向全局有效,可以创建全局临时视图。
2、全局视图
1)对于dataframe创建一个全局视图
scala> df.createOrReplaceGlobalTempView ("user2")
2)通过sql语句查询全表
scala> spark.sql("SELECT * FROM global_temp.user2").show()
+---+--------+
|age| name|
+---+--------+
| 20|qiaofeng|
| 19| xuzhu|
| 18| duanyu|
+---+--------+
3)新建session,通过sql语句实现查询全表
scala> spark.newSession().sql("SELECT * FROM global_temp.user2").show()
+---+--------+
|age| name|
+---+--------+
| 20|qiaofeng|
| 19| xuzhu|
| 18| duanyu|
+---+--------+
2.2.3 dsl风格语法
dataframe提供一个特定领域语言去管理格式化的数据,可以在scala,java,python和r种使用dsl,使用dsl语法风格不必去创建临时视图了。
1、创建一个dataframe
scala> val df = spark.read.json("/opt/module/spark-local/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2、查看dataframe的schema信息
scala> df.printSchema
root
|-- age: Long (nullable = true)
|-- name: string (nullable = true)
3、只查看“name”列数据
注意:列名要用双括号引起来,如果是单引号的话,只能在前面加一个单引号
scala> df.select("name").show()
+--------+
| name|
+--------+
|qiaofeng|
| xuzhu|
| duanyu|
+--------+
scala> df.select('name).show
+--------+
| name|
+--------+
|qiaofeng|
| xuzhu|
| duanyu|
+--------+
4、查看年龄和姓名,且年龄大于18
scala> df.select("age","name").where("age>18").show
+---+--------+
|age| name|
+---+--------+
| 20|qiaofeng|
| 19| xuzhu|
+---+--------+
5、查看所有列
scala> df.select("*").show
+---+--------+
|age| name|
+---+--------+
| 20| qiaofeng|
| 19| xuzhu|
| 18| duanyu|
+---+--------+
6、查看"name"列数据以及“age+1”数据
注意:涉及到运算的时候,每列都必须使用$,或者采用单引号表达式:单引号+字段名
scala> df.select($"name",$"age" + 1).show
scala> df.select('name, 'age + 1).show()
scala> df.select('name, 'age + 1 as "newage").show()
+--------+---------+
| name |(age + 1)|
+--------+---------+
|qiaofeng| 21|
| xuzhu| 20|
| duanyu| 19|
+--------+---------+
7、查看”age“大于”19“的数据
scala> df.filter("age>19").show
+---+--------+
|age | name|
+---+--------+
| 20|qiaofeng|
+---+--------+
8、按照”age“分组,查看数据条数
scala> df.groupBy("age").count.show
+---+-----+
|age|count|
+---+-----+
| 19| 1|
| 18| 1|
| 20| 1|
+---+-----+
9、求平均年龄avg(age)
scala> df.agg(avg("age")).show
+--------+
|avg(age)|
+--------+
| 19.0|
+--------+
10、求年龄总和sum(age)
scala> df.agg(max("age")).show
+--------+
|max(age)|
+--------+
| 20|
+--------+
2.3 dataset
dataset是具有强类型的数据集合,需要提供对应的类型信息。
2.3.1 创建dataset(基本数据类型)
使用基本类型的序列创建dataset。
1、将集合转换为dataset
scala> val ds = Seq(1,2,3,4,5,6).toDS
ds: org.apache.spark.sql.Dataset[Int] = [value: int]
2、查看dataset的值
scala> ds.show
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
| 4|
| 5|
| 6|
+-----+
2.3.2 创建dataset(样例类序列)
使用样例类序列创建dataset。
1、创建一个user的样例类
scala> case class User(name: String, age: Long)
defined class User
2、将集合转换为dataset
scala> val caseClassDS = Seq(User("wangyuyan",18)).toDS()
caseClassDS: org.apache.spark.sql.Dataset[User] = [name: string, age: bigint]
3、查看dataset的值
scala> caseClassDS.show
+---------+---+
| name|age|
+---------+---+
|wangyuyan| 18|
+---------+---+
注意:在实际开发的时候,很少会把序列转换成dataset,更多是通过rdd和dataframe转换来得到dataset
2.4 rdd、dataframe、dataset相互转换
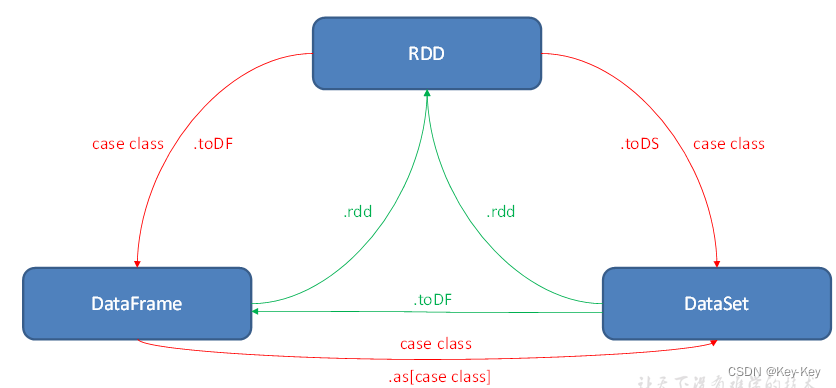
2.4.1 idea创建sparksql工程
1、创建一个maven工程sparksqltest
2、在项目sparksqltest上点击右键,add framework support->勾选scala
3、在main下创建scala文件夹,并右键mark directory as sources root->在Scala下创建包名com.atguigu.sparksql
4、输入文件夹准备:在新建的sparksqltest项目上右键->新建input文件夹->在input文件夹上右键->新建user.json。并输入如下内容:
{"age":20,"name":"qiaofeng"}
{"age":19,"name":"xuzhu"}
{"age":18,"name":"duanyu"}
5、在pom.xml文件中添加spark-sql的依赖和scala的编译插件
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
<build>
<finalName>SparkSQLTest</finalName>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
6、代码实现
package com.atguigu.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
object SparkSQL01_input {
def main(args: Array[String]): Unit = {
// 1 创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setAppName("SparkSQLTest").setMaster("local[*]")
// 2 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 3 读取数据
val df: DataFrame = spark.read.json("input/user.json")
// 4 可视化
df.show()
// 5 释放资源
spark.stop()
}
}
2.4.2 rdd与dataframe相互转换
1、rdd转换为dataframe
手动转换:rdd.todf(“列名1”,“列名2”)
通过样例类反射转换:userrdd.map{x->user(x._1,x._2)}.todf()
2、dataframe转换为rdd
dataframe.rdd
3、在Input/目录下准备user.txt
qiaofeng,20
xuzhu,19
duanyu,18
4、代码实现
package com.atguigu.sparksql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
object SparkSQL02_RDDAndDataFrame {
def main(args: Array[String]): Unit = {
//TODO 1 创建SparkConf配置文件,并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//TODO 2 利用SparkConf创建sc对象
val sc = new SparkContext(conf)
val lineRDD: RDD[String] = sc.textFile("input\\user.txt")
//普通rdd,数据只有类型,没有列名(缺少元数据)
val rdd: RDD[(String, Long)] = lineRDD.map {
line => {
val fileds: Array[String] = line.split(",")
(fileds(0), fileds(1).toLong)
}
}
//TODO 3 利用SparkConf创建sparksession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
//RDD和DF、DS转换必须要导的包(隐式转换),spark指的是上面的sparkSession
import spark.implicits._
//TODO RDD=>DF
//普通rdd转换成DF,需要手动为每一列补上列名(补充元数据)
val df: DataFrame = rdd.toDF("name", "age")
df.show()
//样例类RDD,数据是一个个的样例类,有类型,有属性名(列名),不缺元数据
val userRDD: RDD[User] = rdd.map {
t => {
User(t._1, t._2)
}
}
//样例类RDD转换DF,直接toDF转换即可,不需要补充元数据
val userDF: DataFrame = userRDD.toDF()
userDF.show()
//TODO DF=>RDD
//DF转换成RDD,直接.rdd即可,但是要注意转换出来的rdd数据类型会变成Row
val rdd1: RDD[Row] = df.rdd
val userRDD2: RDD[Row] = userDF.rdd
rdd1.collect().foreach(println)
userRDD2.collect().foreach(println)
//如果想获取到row里面的数据,直接row.get(索引)即可
val rdd2: RDD[(String, Long)] = rdd1.map {
row => {
(row.getString(0), row.getLong(1))
}
}
rdd2.collect().foreach(println)
//TODO 4 关闭资源
sc.stop()
}
}
case class User(name:String,age:Long)
2.4.3 rdd与dataset相互转换
1、rdd转换为dataset
rdd.map{x->user(x._1,x._2)},tods()
sparksql能够自动将包含有样例类的rdd转换成dataset,样例类定义了table的结构,样例类属性通过反射编程了表的列名。样例类可以包含诸如seq或者array等复杂的结构。
2、dataset转换为rdd
ds.rdd
3、代码实现
package com.atguigu.sparksql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Dataset, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
object SparkSQL03_RDDAndDataSet {
def main(args: Array[String]): Unit = {
//TODO 1 创建SparkConf配置文件,并设置App名称
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//TODO 2 利用SparkConf创建sc对象
val sc = new SparkContext(conf)
val lineRDD: RDD[String] = sc.textFile("input\\user.txt")
//普通rdd,数据只有类型,没有列名(缺少元数据)
val rdd: RDD[(String, Long)] = lineRDD.map {
line => {
val fileds: Array[String] = line.split(",")
(fileds(0), fileds(1).toLong)
}
}
//TODO 3 利用SparkConf创建sparksession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
//RDD和DF、DS转换必须要导的包(隐式转换),spark指的是上面的sparkSession
import spark.implicits._
//TODO RDD=>DS
//普通rdd转DS,没办法补充元数据,因此一般不用
val ds: Dataset[(String, Long)] = rdd.toDS()
ds.show()
//样例类RDD,数据是一个个的样例类,有类型,有属性名(列名),不缺元数据
val userRDD: RDD[User] = rdd.map {
t => {
User(t._1, t._2)
}
}
//样例类RDD转换DS,直接toDS转换即可,不需要补充元数据,因此转DS一定要用样例类RDD
val userDs: Dataset[User] = userRDD.toDS()
userDs.show()
//TODO DS=>RDD
//ds转成rdd,直接.rdd即可,并且ds不会改变rdd里面的数据类型
val rdd1: RDD[(String, Long)] = ds.rdd
val userRDD2: RDD[User] = userDs.rdd
//TODO 4 关闭资源
sc.stop()
}
}
2.4.4 dataframe与dataset相互转换
1、dataframe转为dataset
df.as[user]
2、dataset转换为dataframe
ds.todf
3、代码实现
package com.atguigu.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object SparkSQL04_DataFrameAndDataSet {
def main(args: Array[String]): Unit = {
// 1 创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLTest")
// 2 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 3 读取数据
val df: DataFrame = spark.read.json("input/user.json")
//4.1 RDD和DataFrame、DataSet转换必须要导的包
import spark.implicits._
// 4.2 DataFrame 转换为DataSet
val userDataSet: Dataset[User] = df.as[User]
userDataSet.show()
// 4.3 DataSet转换为DataFrame
val userDataFrame: DataFrame = userDataSet.toDF()
userDataFrame.show()
// 5 释放资源
spark.stop()
}
}
case class User(name: String,age: Long)
2.5 用户自定义函数
2.5.1 udf
1、udf:一行进入,一行出
2、代码实现
package com.atguigu.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
object SparkSQL05_UDF{
def main(args: Array[String]): Unit = {
// 1 创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLTest")
// 2 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 3 读取数据
val df: DataFrame = spark.read.json("input/user.json")
// 4 创建DataFrame临时视图
df.createOrReplaceTempView("user")
// 5 注册UDF函数。功能:在数据前添加字符串“Name:”
spark.udf.register("addName", (x:String) => "Name:"+ x)
// 6 调用自定义UDF函数
spark.sql("select addName(name), age from user").show()
// 7 释放资源
spark.stop()
}
}
2.5.2 udaf
1、udaf:输入多行,返回一行
2、spark3.x推荐使用extends aggregator自定义udaf,属于强类型的dataset方式
3、spark2.x使用extends userdefinedaggregatefunction,数以弱类型的dataframe
4、案例:
需求:实现求平均年龄,自定义udaf,myavg(age)
1)自定义聚合函数实现-强类型
package com.atguigu.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{DataFrame, Encoder, Encoders, SparkSession, functions}
object SparkSQL06_UDAF {
def main(args: Array[String]): Unit = {
// 1 创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLTest")
// 2 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 3 读取数据
val df: DataFrame = spark.read.json("input/user.json")
// 4 创建DataFrame临时视图
df.createOrReplaceTempView("user")
// 5 注册UDAF
spark.udf.register("myAvg", functions.udaf(new MyAvgUDAF()))
// 6 调用自定义UDAF函数
spark.sql("select myAvg(age) from user").show()
// 7 释放资源
spark.stop()
}
}
//输入数据类型
case class Buff(var sum: Long, var count: Long)
/**
* 1,20岁; 2,19岁; 3,18岁
* IN:聚合函数的输入类型:Long
* Buff : sum = (18+19+20) count = 1+1+1
* OUT:聚合函数的输出类型:Double (18+19+20) / 3
*/
class MyAvgUDAF extends Aggregator[Long, Buff, Double] {
// 初始化缓冲区
override def zero: Buff = Buff(0L, 0L)
// 将输入的年龄和缓冲区的数据进行聚合
override def reduce(buff: Buff, age: Long): Buff = {
buff.sum = buff.sum + age
buff.count = buff.count + 1
buff
}
// 多个缓冲区数据合并
override def merge(buff1: Buff, buff2: Buff): Buff = {
buff1.sum = buff1.sum + buff2.sum
buff1.count = buff1.count + buff2.count
buff1
}
// 完成聚合操作,获取最终结果
override def finish(buff: Buff): Double = {
buff.sum.toDouble / buff.count
}
// SparkSQL对传递的对象的序列化操作(编码)
// 自定义类型就是product 自带类型根据类型选择
override def bufferEncoder: Encoder[Buff] = Encoders.product
override def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
第 3 章:sparksql数据的加载和保存
3.1 加载数据
1、加载数据通用方法
spark.read.load是加载数据的通用方式
2、代码实现
package com.atguigu.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
object SparkSQL08_Load{
def main(args: Array[String]): Unit = {
// 1 创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLTest")
// 2 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 3.1 spark.read直接读取数据:csv format jdbc json load option
// options orc parquet schema table text textFile
// 注意:加载数据的相关参数需写到上述方法中,
// 如:textFile需传入加载数据的路径,jdbc需传入JDBC相关参数。
spark.read.json("input/user.json").show()
// 3.2 format指定加载数据类型
// spark.read.format("…")[.option("…")].load("…")
// format("…"):指定加载的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和"text"
// load("…"):在"csv"、"jdbc"、"json"、"orc"、"parquet"和"text"格式下需要传入加载数据路径
// option("…"):在"jdbc"格式下需要传入JDBC相应参数,url、user、password和dbtable
spark.read.format("json").load ("input/user.json").show
// 4 释放资源
spark.stop()
}
}
3.2 保存数据
1、保存数据通用方法
df.write.save是保存数据的通用方法
2、代码实现
package com.atguigu.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.sql._
object SparkSQL09_Save{
def main(args: Array[String]): Unit = {
// 1 创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLTest")
// 2 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 3 获取数据
val df: DataFrame = spark.read.json("input/user.json")
// 4.1 df.write.保存数据:csv jdbc json orc parquet text
// 注意:保存数据的相关参数需写到上述方法中。如:text需传入加载数据的路径,JDBC需传入JDBC相关参数。
// 默认保存为parquet文件(可以修改conf.set("spark.sql.sources.default","json"))
df.write.save("output")
// 默认读取文件parquet
spark.read.load("output").show()
// 4.2 format指定保存数据类型
// df.write.format("…")[.option("…")].save("…")
// format("…"):指定保存的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和"text"。
// save ("…"):在"csv"、"orc"、"parquet"和"text"(单列DF)格式下需要传入保存数据的路径。
// option("…"):在"jdbc"格式下需要传入JDBC相应参数,url、user、password和dbtable
df.write.format("json").save("output2")
// 4.3 可以指定为保存格式,直接保存,不需要再调用save了
df.write.json("output1")
// 4.4 如果文件已经存在则追加
df.write.mode("append").json("output2")
// 如果文件已经存在则忽略(文件存在不报错,也不执行;文件不存在,创建文件)
df.write.mode("ignore").json("output2")
// 如果文件已经存在则覆盖
df.write.mode("overwrite").json("output2")
// 默认default:如果文件已经存在则抛出异常
// path file:/E:/ideaProject2/SparkSQLTest/output2 already exists.;
df.write.mode("error").json("output2")
// 5 释放资源
spark.stop()
}
}
3.3 与mysql交互
1、导入依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
2、从mysql读数据
package com.atguigu.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.sql._
object SparkSQL10_MySQL_Read{
def main(args: Array[String]): Unit = {
// 1 创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLTest")
// 2 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 3.1 通用的load方法读取mysql的表数据
val df: DataFrame = spark.read.format("jdbc")
.option("url", "jdbc:mysql://hadoop102:3306/gmall")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "000000")
.option("dbtable", "user_info")
.load()
// 3.2 创建视图
df.createOrReplaceTempView("user")
// 3.3 查询想要的数据
spark.sql("select id, name from user").show()
// 4 释放资源
spark.stop()
}
}
3、向mysql写数据
package com.atguigu.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql._
object SparkSQL11_MySQL_Write {
def main(args: Array[String]): Unit = {
// 1 创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLTest")
// 2 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 3 准备数据
// 注意:id是主键,不能和MySQL数据库中的id重复
val rdd: RDD[User] = spark.sparkContext.makeRDD(List(User(3000, "zhangsan"), User(3001, "lisi")))
val ds: Dataset[User] = rdd.toDS
// 4 向MySQL中写入数据
ds.write
.format("jdbc")
.option("url", "jdbc:mysql://hadoop102:3306/gmall")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "000000")
.option("dbtable", "user_info")
.mode(SaveMode.Append)
.save()
// 5 释放资源
spark.stop()
}
case class User(id: Int, name: String)
}
3.4 与hive交互
sparksql可以采用内嵌hive,也可以采用外部hive。企业开发中,通常采用外部hive。
3.4.1 内嵌hive应用
内嵌hive,元数据存储在derby数据库
1、如果使用spark内嵌的hive,则什么都不用做,直接使用即可。
[atguigu@hadoop102 spark-local]$ bin/spark-shell
scala> spark.sql("show tables").show
注意:执行完后,发现多了$spark_home/metastore_db和derby.log,用于存储元数据。
2、创建一个表
scala> spark.sql("create table user(id int, name string)")
注意:执行完后,发现多了$spark_home/spark-warehouse/user,用于存储数据库数据。
3、查看数据库
scala> spark.sql("show tables").show
4、向表中插入数据
scala> spark.sql("insert into user values(1,'zs')")
5、查询数据
scala> spark.sql("select * from user").show
注意:然而在实际使用中,几乎没有任何人会使用内置的hive,因为元数据存储在derby数据库,不支持多客户端访问。
3.4.2 外部hive应用
如果spark要接管hive外部已经部署好的hive,需要通过一下几个步骤。
1、为了说明内嵌hive和外部hive区别:删除内嵌hive的metastore_db和spark-warehouse
[atguigu@hadoop102 spark-local]$ rm -rf metastore_db/ spark-warehouse/
2、确定原有hive是正常工作的
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
[atguigu@hadoop102 hive]$ bin/hive
3、需要把hive-site.xml拷贝到spark的conf/目录下
[atguigu@hadoop102 conf]$ cp hive-site.xml /opt/module/spark-local/conf/
4、如果以前hive-site.xml文件中,配置过tez相关信息,注释掉(不是必须)
5、把mysql的驱动copy到spark的jars/目录下
[atguigu@hadoop102 software]$ cp mysql-connector-java-5.1.48.jar /opt/module/spark-local/jars/
6、需要提前启动hive服务,/opt/module/hive/bin/hiveservices.sh start(不是必须)
7、如果访问不到hdfs,则需把core-site.xml和hdfs-site.xml拷贝到conf/目录(不是必须)
8、启动spark-shell
[atguigu@hadoop102 spark-local]$ bin/spark-shell
9、查询表
scala> spark.sql("show tables").show
10、创建一个表
scala> spark.sql("create table student(id int, name string)")
11、向表中插入数据
scala> spark.sql("insert into student values(1,'zs')")
12、查询数据
scala> spark.sql("select * from student").show
3.4.3 运行spark sql cli
spark sql cli可以方便的在本地下运行hive元数据服务以及从命令行执行查询任务。在spark目录下执行如下命令启动spark sql cli,直接执行sql语句,类型hive窗口。
[atguigu@hadoop102 spark-local]$ bin/spark-sql
spark-sql (default)> show tables;
3.4.4 idea操作外部hive
1、添加依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
2、拷贝hive-site.xml到resources目录(如果需要操作hadoop,需要拷贝hdfs-site.xml、core-site.xml、yarn-site.xml)
3、代码实现
package com.atguigu.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.sql._
object SparkSQL12_Hive {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME","atguigu")
// 1 创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLTest")
// 2 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().enableHiveSupport().config(conf).getOrCreate()
// 3 连接外部Hive,并进行操作
spark.sql("show tables").show()
spark.sql("create table user3(id int, name string)")
spark.sql("insert into user3 values(1,'zs')")
spark.sql("select * from user3").show
// 4 释放资源
spark.stop()
}
}
第 1 章:SparkStreaming概述
1.1 spark streaming是什么
spark streaming用于流式数据的处理。
spark streaming支持的数据源很多,例如:kafka、flume、hdfs等。
数据输入后可以用spark的高度抽象原语如:map、reduce、join、window等进行计算。
而结果也能保存在很多地方,如hdfs、数据库等。
1.2 spark streaming框架原理
dstream是什么?
sparkcore->rdd
sparksql->dataframe、dataset
spark streaming使用离散化流作为抽象表示,叫做dstream。
dsteam是随时间推移而受到的数据的序列。
在dsteam内部,每个时间区间受到的数据都作为rdd存在,而dstream是由这些rdd所组合成的序列。
简单来说,dstream就是对rdd在实时数据处理场景的一种封装。

1.2.2 架构图
整体架构图
spark streaming架构图
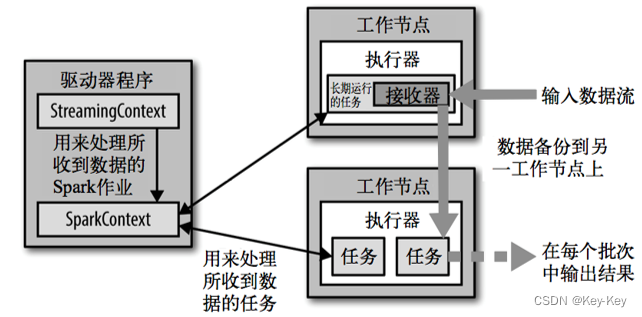
1.2.3 背压机制
spark 1.5以前版本,用户如果要限制receiver的数据接收速率,可以通过设置静态配置参数“spark.streaming.receiver.maxrate”的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,单也会引入其它问题。比如:producer数据生产高于maxrate,当前集群处理能力也高于maxrate,这就会造成资源利用率下降等问题。
为了更好的协调数据接收速率与资源处理能力,1.5版本开始spark streaming可以动态控制速率来适配集群数据处理能力。背压机制:根据jobscheduler反馈作业的执行信息来动态调整receiver数据接受率。
通过属性“spark.streaming.backpressure.enabled”来控制是否启动背压机制,默认值false,即不启用。
1.3 spark steaming 特点
易用

容错

易整合到spark体系

第 2 章:dstream入门
2.1 wordcount案例入门
需求:使用Netcat工具向9999端口不断地发送数据,通过sparkstreaming读取端口数据并统计不同单词出现的次数。
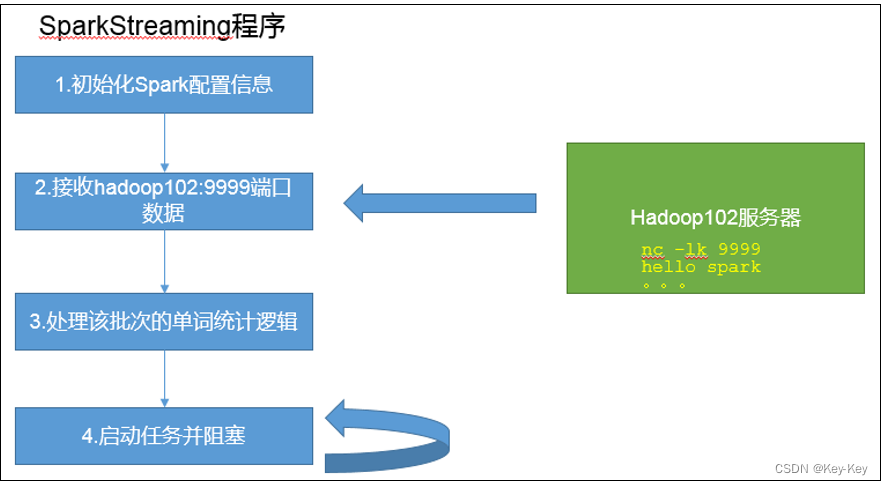
1、添加依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
2、编写代码
package com.atguigu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming01_WordCount {
def main(args: Array[String]): Unit = {
//1.初始化Spark配置信息
val sparkConf = new SparkConf().setAppName("SparkStreaming").setMaster("local[*]")
//2.初始化SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3.通过监控端口创建DStream,读进来的数据为一行行
val lineDStream = ssc.socketTextStream("hadoop102", 9999)
//3.1 将每一行数据做切分,形成一个个单词
val wordDStream = lineDStream.flatMap(_.split(" "))
//3.2 将单词映射成元组(word,1)
val wordToOneDStream = wordDStream.map((_, 1))
//3.3 将相同的单词次数做统计
val wordToSumDStream = wordToOneDStream.reduceByKey(_+_)
//3.4 打印
wordToSumDStream.print()
//4 启动SparkStreamingContext
ssc.start()
// 将主线程阻塞,主线程不退出
ssc.awaitTermination()
}
}
3、更改日志打印级别
将log4j.properties文件添加到resources里面,就能更改打印日志的级别为error
log4j.rootLogger=error, stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=../log/agent.log
log4j.appender.R.MaxFileSize=1024KB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%6L) : %m%n
4、启动程序并通过netcat发送数据
[atguigu@hadoop102 ~]$ nc -lk 9999
hello spark
5、在idea控制台输出如下内容
-------------------------------------------
Time: 1602731772000 ms
-------------------------------------------
(hello,1)
(spark,1)
2.2 wordcount解析
dstream是spark streaming的基础抽象,代表持续性的而数据流和经过各种spark算子操作后的结果数据流。
在内部实现上,每一批次的数据封装成一个rdd,一系列连续的rdd组成了dstream。对这些rdd的转换是由spark引擎来计算。
说明:dstream中批次与批次之间计算相互独立。如果批次设置时间小于计算时间会出现计算任务叠加情况,需要多分配资源。通常情况,批次设置时间要大于计算时间。

第 3 章:dstream创建
3.1 rdd队列
3.1.1 用法及说明
测试方式:
1、使用ssc.queuestream(queueofrdds)来创建dstream。
2、将每一个推送到这个队列中的rdd,都会作为dstream的一个批次处理。
3.1.2 案例实操
需求:循环创建几个rdd,将rdd放入队列。通过sparkstreaming创建dstream,计算wordcount。
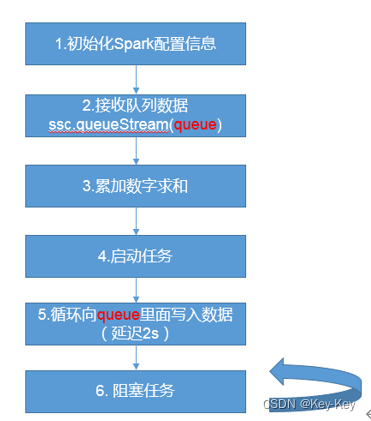
1、编写代码
package com.atguigu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object SparkStreaming02_RDDStream {
def main(args: Array[String]): Unit = {
//1.初始化Spark配置信息
val conf = new SparkConf().setAppName("SparkStreaming").setMaster("local[*]")
//2.初始化SparkStreamingContext
val ssc = new StreamingContext(conf, Seconds(4))
//3.创建RDD队列
val rddQueue = new mutable.Queue[RDD[Int]]()
//4.创建QueueInputDStream
// oneAtATime = true 默认,一次读取队列里面的一个数据
// oneAtATime = false, 按照设定的批次时间,读取队列里面数据
val inputDStream = ssc.queueStream(rddQueue, oneAtATime = false)
//5.处理队列中的RDD数据
val sumDStream = inputDStream.reduce(_+_)
//6.打印结果
sumDStream.print()
//7.启动任务
ssc.start()
//8.循环创建并向RDD队列中放入RDD
for (i <- 1 to 5) {
rddQueue += ssc.sparkContext.makeRDD(1 to 5)
Thread.sleep(2000)
}
ssc.awaitTermination()
}
}
2、结果展示(oneatatime=false)
-------------------------------------------
Time: 1603347444000 ms
-------------------------------------------
15
-------------------------------------------
Time: 1603347448000 ms
-------------------------------------------
30
-------------------------------------------
Time: 1603347452000 ms
-------------------------------------------
30
说明:如果一个批次中由多个rdd进入队列,最终计算前都会合并到一个rdd计算。
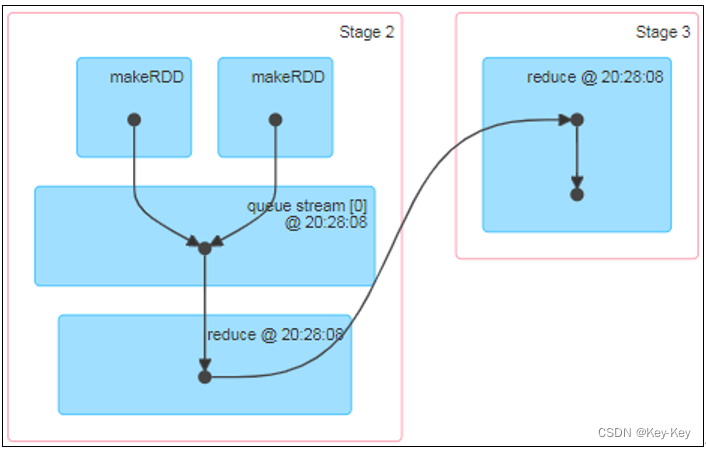
3.2 自定义数据源接收器
3.2.1 用法及说明
需要继承receiver,并实现onstart、onstop方法来自定义数据源采集。
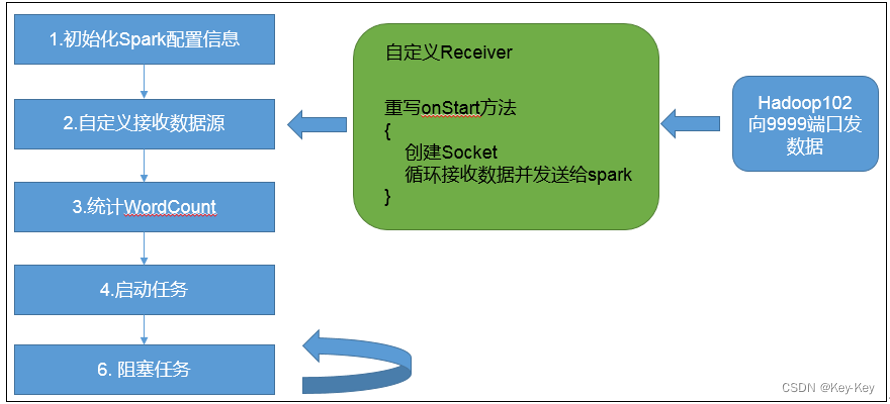
3.2.2 案例
需求:自定义数据源,实现监控某个端口号,获取该端口号内容。
1、使用自定义的数据源采集数据
package com.atguigu.sparkstreaming
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import java.nio.charset.StandardCharsets
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming03_CustomerReceiver {
def main(args: Array[String]): Unit = {
//1.初始化Spark配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
//2.初始化SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(5))
//3.创建自定义receiver的Streaming
val lineDStream = ssc.receiverStream(new CustomerReceiver("hadoop102", 9999))
//4.将每一行数据做切分,形成一个个单词
val wordDStream = lineDStream.flatMap(_.split(" "))
//5.将单词映射成元组(word,1)
val wordToOneDStream = wordDStream.map((_, 1))
//6.将相同的单词次数做统计
val wordToSumDStream = wordToOneDStream.reduceByKey(_ + _)
//7.打印
wordToSumDStream.print()
//8.启动SparkStreamingContext
ssc.start()
ssc.awaitTermination()
}
}
2、自定义数据源
/**
* @param host : 主机名称
* @param port : 端口号
* Receiver[String] :返回值类型:String
* StorageLevel.MEMORY_ONLY: 返回值存储级别
*/
class CustomerReceiver(host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) {
// receiver刚启动的时候,调用该方法,作用为:读数据并将数据发送给Spark
override def onStart(): Unit = {
//在onStart方法里面创建一个线程,专门用来接收数据
new Thread("Socket Receiver") {
override def run() {
receive()
}
}.start()
}
// 读数据并将数据发送给Spark
def receive(): Unit = {
// 创建一个Socket
var socket: Socket = new Socket(host, port)
// 字节流读取数据不方便,转换成字符流buffer,方便整行读取
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream, StandardCharsets.UTF_8))
// 读取数据
var input: String = reader.readLine()
//当receiver没有关闭并且输入数据不为空,就循环发送数据给Spark
while (!isStopped() && input != null) {
store(input)
input = reader.readLine()
}
// 如果循环结束,则关闭资源
reader.close()
socket.close()
//重启接收任务
restart("restart")
}
override def onStop(): Unit = {}
}
3、测试
[atguigu@hadoop102 ~]$ nc -lk 9999
hello spark
3.3 kafka数据源(面试、开发重点)
3.3.1 版本选型
receiverapi:需要一个专门的executor来接收数据,然后发送给其它的executor做计算。存在的问题:接收数据的executor和计算的executor速度会有所不同,特别在接收数据的executor速度大于计算的executor速度,会导致计算数据的节点内存溢出。早期版本中提供此方式,当前版本不适用。
directapi:是由计算的executor来主动消费kafka的数据,速度由自身控制。
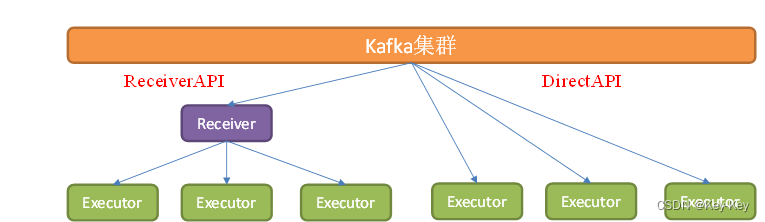
注意:目前spark3.0.0以上版本只有direct模式。
http://spark.apache.org/docs/2.4.7/streaming-kafka-integration.html
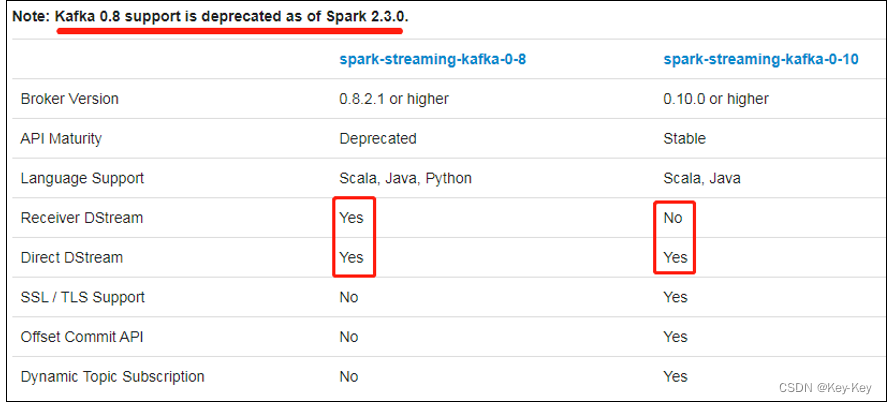
http://spark.apache.org/docs/3.0.0/streaming-kafka-0-10-integration.html
总结:不同版本的offset存储位置。
0-8 receiverapi offset默认存储在:zookeeper中。
0-8 directapi offset默认存储在:checkpoint。手动维护:mysql等有事务的存储系统。
0-10 directapi offset默认存储在:_consumer_offsets系统主题。手动维护:mysql等有事务的存储系统。
3.3.2 kafka 0-10 direct模式
1、需求:通过sparkstreaming从kafka读取数据,并将读取过来的数据做简单计算,最终打印到控制台。
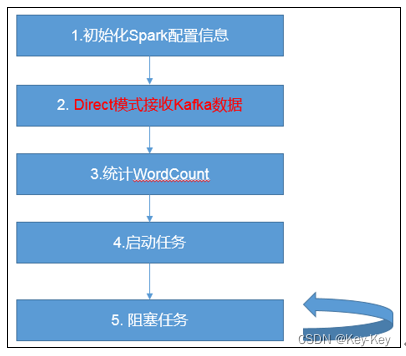
2、导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.0.0</version>
</dependency>
3、编写代码
package com.atguigu.sparkstreaming
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming04_DirectAuto {
def main(args: Array[String]): Unit = {
//1.创建SparkConf
val sparkConf: SparkConf = new SparkConf().setAppName("sparkstreaming").setMaster("local[*]")
//2.创建StreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3.定义Kafka参数:kafka集群地址、消费者组名称、key序列化、value序列化
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "hadoop102:9092,hadoop103:9092,hadoop104:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguiguGroup",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer]
)
//4.读取Kafka数据创建DStream
val kafkaDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent, //优先位置
ConsumerStrategies.Subscribe[String, String](Set("testTopic"), kafkaPara)// 消费策略:(订阅多个主题,配置参数)
)
//5.将每条消息(KV)的V取出
val valueDStream: DStream[String] = kafkaDStream.map(record => record.value())
//6.计算WordCount
valueDStream.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.print()
//7.开启任务
ssc.start()
ssc.awaitTermination()
}
}
4、测试
1)分别启动zookeeper和kafka集群
[atguigu@hadoop102 ~]$ zk.sh start
[atguigu@hadoop102 ~]$ kf.sh start
2)创建一个kafka的topic主题testtopic,两个分区
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --replication-factor 1 --partitions 2 --topic testTopic
3)查看topic列表
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka -list
4)查看topic详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka \
--describe --topic testTopic
5)创建kafka生产者
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh \
--broker-list hadoop102:9092 --topic testTopic
Hello spark
Hello spark
6)创建kafka消费组
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic testTopic
5、查看_consumer_offsets主题中存储的offset
[atguigu@hadoop102 kafka]$ bin/kafka-consumer-groups.sh --bootstrap-server hadoop102:9092 --describe --group atguiguGroup
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET
atguiguGroup testTopic 0 13 13
在生产者中生产数据,再次观察offset变换。
第 4 章:dstream转换
dstream上的操作与rdd的类似,分为转换和输出两种,此外转换操作中还有一些比较特殊的原语,如:updatastatebykey()、transform()以及各种windows相关的原语。
4.1 无状态转化操作
就是把rdd转化操作应用到dstream每个批次上,每个批次相互独立,自己算自己的。
4.1.1 常规无状态转化操做
dstream的部分无状态转化操作列在了下表中,都是dstream自己的api。
注意:针对键值对的dstream转化操作,要添加import streamingcontext._才能咋scala中使用,比如reducebykey()。

需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个dstream在内部都是由许多rdd批次组成,且无状态转化操作是分别应用到每个rdd(一个批次的数据)上的。
4.1.2 transform
需求:通过transform可以将dstream每一批次的数据直接转换为rdd的算子操作。

1、代码编写
package com.atguigu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming05_Transform {
def main(args: Array[String]): Unit = {
//1 创建SparkConf
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
//2 创建StreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3 创建DStream
val lineDStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
// 在Driver端执行,全局一次
println("111111111:" + Thread.currentThread().getName)
//4 转换为RDD操作
val wordToSumDStream: DStream[(String, Int)] = lineDStream.transform(
rdd => {
// 在Driver端执行(ctrl+n JobGenerator),一个批次一次
println("222222:" + Thread.currentThread().getName)
val words: RDD[String] = rdd.flatMap(_.split(" "))
val wordToOne: RDD[(String, Int)] = words.map(x=>{
// 在Executor端执行,和单词个数相同
println("333333:" + Thread.currentThread().getName)
(x, 1)
})
val result: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)
result
}
)
//5 打印
wordToSumDStream.print
//6 启动
ssc.start()
ssc.awaitTermination()
}
}
2、测试
[atguigu@hadoop102 ~]$ nc -lk 9999
hello spark
4.2 由状态转换操作
4.2.1 updatestatebykey
updatestatebykey()用于键值对形式的dstream,可以记录历史批次状态。例如可以实现累加wordcount。
updatestatebykey()参数中需要传递一个函数,在函数内部可以根据需求对新数据和历史状态进行整合处理,返回一个新的dstream。
注意:使用Updatestatebykey需要对检查点目录进行配置,会使用检查点来保存状态。
checkpoint小文件过多。
checkpoint记录最后一次时间戳,再次启动的时候会把间隔时间的周期再执行一次。
1、需求:更新版的wordcount
2、编写代码
package com.atguigu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object sparkStreaming06_updateStateByKey {
// 定义更新状态方法,参数seq为当前批次单词次数,state为以往批次单词次数
val updateFunc = (seq: Seq[Int], state: Option[Int]) => {
// 当前批次数据累加
val currentCount = seq.sum
// 历史批次数据累加结果
val previousCount = state.getOrElse(0)
// 总的数据累加
Some(currentCount + previousCount)
}
def createSCC(): StreamingContext = {
//1 创建SparkConf
val conf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
//2 创建StreamingContext
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("./ck")
//3 获取一行数据
val lines = ssc.socketTextStream("hadoop102", 9999)
//4 切割
val words = lines.flatMap(_.split(" "))
//5 统计单词
val wordToOne = words.map(word => (word, 1))
//6 使用updateStateByKey来更新状态,统计从运行开始以来单词总的次数
val stateDstream = wordToOne.updateStateByKey[Int](updateFunc)
stateDstream.print()
ssc
}
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = StreamingContext.getActiveOrCreate("./ck",()=>createSCC())
//7 开启任务
ssc.start()
ssc.awaitTermination()
}
}
3、启动程序并向9999端口发送数据
[atguigu@hadoop102 ~]$ nc -lk 9999
hello atguigu
hello atguigu
4、结果展示
-------------------------------------------
Time: 1603441344000 ms
-------------------------------------------
(hello,1)
(atguigu,1)
-------------------------------------------
Time: 1603441347000 ms
-------------------------------------------
(hello,2)
(atguigu,2)
5、原理说明
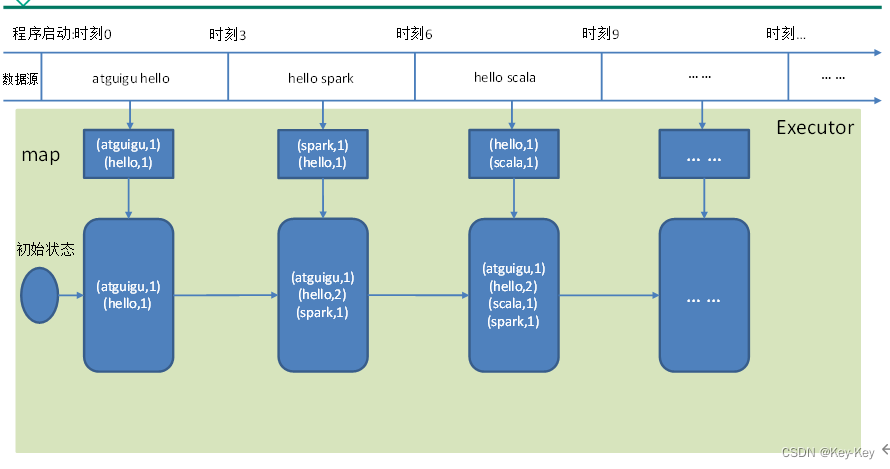
4.2.2 winodwoperations
window operations可以设置窗口的大小和滑动窗口的间隔来动态的获取当前streaming的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
窗口时长:计算内容的时间范围;
滑动步长:隔多久触发一次计算。
注意:这两者都必须为采集批次大小的整数倍。
如下图所示wordcount案例:窗口大小为批次的2倍,滑动步等于批次大小。
窗口操作数据流解析
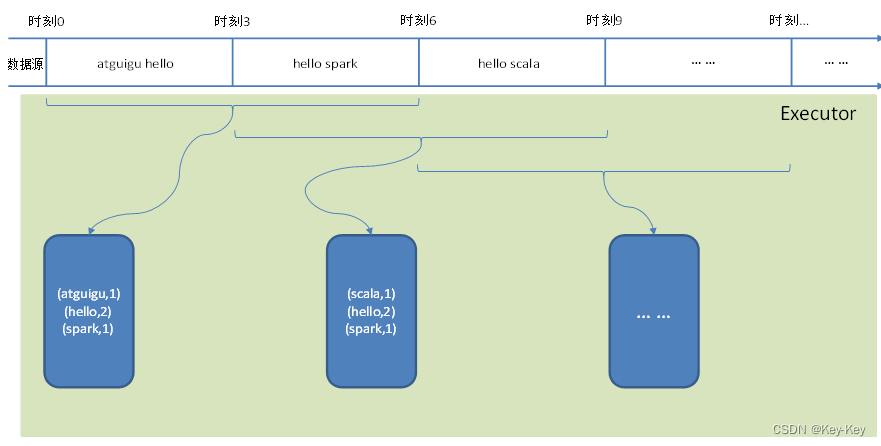
4.2.3 window
1、基本语法:window,基于对源dstream窗口的批次进行计算返回一个新的dstream。
2、需求:统计wordcount,3秒一个批次,窗口12秒,滑步6秒。
3、代码编写
package com.atguigu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming07_window {
def main(args: Array[String]): Unit = {
// 1 初始化SparkStreamingContext
val conf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
val ssc = new StreamingContext(conf, Seconds(3))
// 2 通过监控端口创建DStream,读进来的数据为一行行
val lines = ssc.socketTextStream("hadoop102", 9999)
// 3 切割=》变换
val wordToOneDStream = lines.flatMap(_.split(" "))
.map((_, 1))
// 4 获取窗口返回数据
val wordToOneByWindow: DStream[(String, Int)] = wordToOneDStream.window(Seconds(12), Seconds(6))
// 5 聚合窗口数据并打印
val wordToCountDStream: DStream[(String, Int)] = wordToOneByWindow.reduceByKey(_+_)
wordToCountDStream.print()
// 6 启动=》阻塞
ssc.start()
ssc.awaitTermination()
}
}
4、测试
[atguigu@hadoop102 ~]$ nc -lk 9999
hello
5、如果有多批数据进入窗口,最终也会通过window操作变成统一的rdd处理
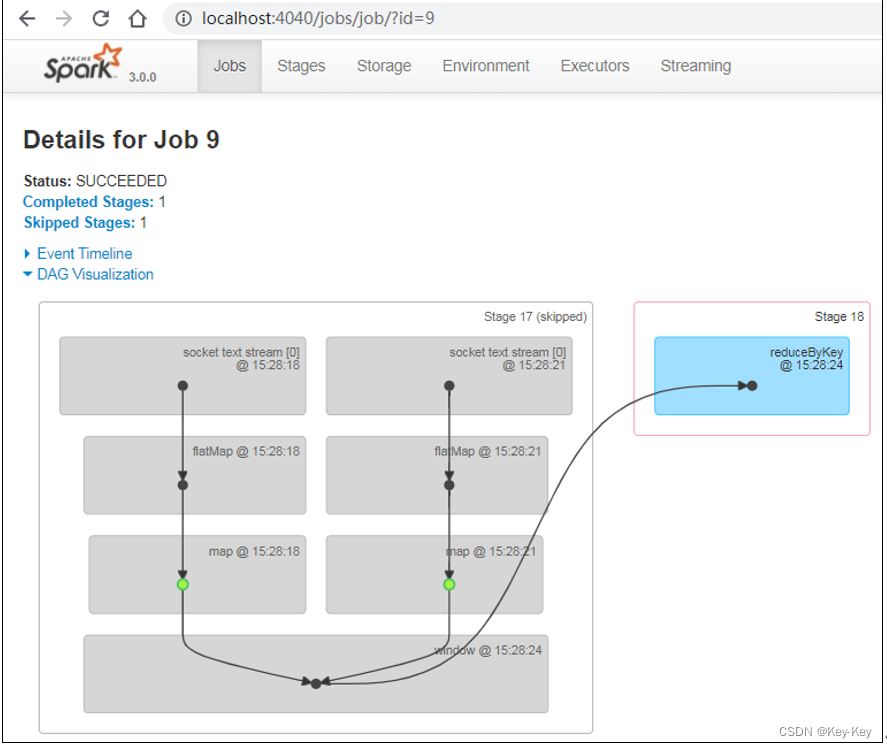
4.2.4 reducebykeyandwindow
1、基本语法
reducebykeyandwindow(func,windowlength,slideinterval,[numtasks]):当在一个(k,v)对的dstream上调用此函数,会返回一个新的(k,v)对的dstream,此处通过对滑动窗口中批次数据使用reduce函数来整合每个key的value值。
2、需求:统计wordcount,3秒一个批次,窗口12秒,滑步6秒。
3、代码编写
package com.atguigu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming08_reduceByKeyAndWindow {
def main(args: Array[String]): Unit = {
// 1 初始化SparkStreamingContext
val conf = new SparkConf().setAppName("sparkstreaming").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(3))
// 保存数据到检查点
ssc.checkpoint("./ck")
// 2 通过监控端口创建DStream,读进来的数据为一行行
val lines = ssc.socketTextStream("hadoop102", 9999)
// 3 切割=》变换
val wordToOne = lines.flatMap(_.split(" "))
.map((_, 1))
// 4 窗口参数说明: 算法逻辑,窗口12秒,滑步6秒
val wordCounts = wordToOne.reduceByKeyAndWindow((a: Int, b: Int) => (a + b), Seconds(12), Seconds(6))
// 5 打印
wordCounts.print()
// 6 启动=》阻塞
ssc.start()
ssc.awaitTermination()
}
}
4、测试
[atguigu@hadoop102 ~]$ nc -lk 9999
hello atguigu
4.2.5 reducebykeyandwindow(反向reduce)
1、基本语法
reducebykeyandwindow(func,invfunc,windowlength,slideinterval,[numtasks]):这个函数是上述函数的变化版本,每个窗口的reduce值都是通过用前一个窗的reduce值来递增计算。通过reduce进入到滑动窗口数据并“反向reduce“离开窗口的旧数据来实现这个操作。一个例子是随着滑动窗口对keys的”加“”减“计数。通过前边介绍可以想到,这个函数只使用于”可逆的reduce函数“,也就是这些reduce函数有相应的”反reduce“函数(以参数invfunc形式传入)。如前述函数,reduce任务的数量通过可选参数来配置。
2、需求:统计wordcount,3秒一个批次,窗口12秒,滑步6秒。
3、代码编写
package com.atguigu.sparkstreaming
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming09_reduceByKeyAndWindow_reduce {
def main(args: Array[String]): Unit = {
// 1 初始化SparkStreamingContext
val conf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
val ssc = new StreamingContext(conf, Seconds(3))
// 保存数据到检查点
ssc.checkpoint("./ck")
// 2 通过监控端口创建DStream,读进来的数据为一行行
val lines = ssc.socketTextStream("hadoop102", 9999)
// 3 切割 =》变换
val wordToOne = lines.flatMap(_.split(" "))
.map((_, 1))
// 4 窗口参数说明: 算法逻辑,窗口12秒,滑步6秒
/*
val wordToSumDStream: DStream[(String, Int)]= wordToOne.reduceByKeyAndWindow(
(a: Int, b: Int) => (a + b),
(x: Int, y: Int) => (x - y),
Seconds(12),
Seconds(6)
)*/
// 处理单词统计次数为0的问题
val wordToSumDStream: DStream[(String, Int)]= wordToOne.reduceByKeyAndWindow(
(a: Int, b: Int) => (a + b),
(x: Int, y: Int) => (x - y),
Seconds(12),
Seconds(6),
new HashPartitioner(2),
(x:(String, Int)) => x._2 > 0
)
// 5 打印
wordToSumDStream.print()
// 6 启动=》阻塞
ssc.start()
ssc.awaitTermination()
}
}
4.2.6 window的其它操作
1、countbywindow(windowlength,slideinterval):返回一个滑动窗口计数流中的元素个数
2、reducebywindow(func,windowlength,slideinterval):通过使用自定义函数整合滑动区间流元素来创建一个新的离散化数据流
第 5 章:dstream输出
dstream通常将数据输出到,外部数据库或屏幕上。
dstream与rdd中的惰性求值类似,如果一个dstream及其派生出的dstream都没有被执行输出操作,那么这些dstream就都不会被求值。如果streamingcontext中没有设定输出操作,整个context就都不会启动。
1、输出操作api如下:
1)saveastextfiles([prefix,[suffix]):以text文件形式存储这个dstream的内容。每一批次的存储文件名基于参数中的prefix和suffix。”prefix-time_in_ms[.suffix]“
2)saveasobjectfiles(prefix,[suffix]):以java对象序列化的方式将dstream中的数据保存为sequencefiles。每一批次的存储文件名基于参数中的为”prefix-time_in_ms[.suffix]“。
3)saveashadoopfiles(prefix,[suffix]):将stream中的数据保存为hadoop files。每一批次的存储文件名基于参数中的为”prefix-time_in_ms[.suffix]“。
注意:以上操作都是每一批次写出一次,会产生大量小文件,在生产环境,很少使用。
4)print():在允许流程序的驱动节点上打印dstream中的每一批次数据的最开始10个元素。这用于开发和调试。
5)foreachrdd(func):这是最通用的输出操作,即将函数func用于产生dstream的每一个rdd。其中参数传入的函数func应该实现将每一个rdd中数据推送到外部系统,如将rdd存入文件或者写入数据库。
在企业开发中通常采用foreachrdd(),它用来对dstream中的rdd进行任意计算。这和transform()有些类似,都可以让我们访问任意rdd。在foreachrdd()中,可以重用我们在spark中实现的所有行动操作(action 算子)。比如,常见的用例之一是把数据写到如mysql的外部数据库中。
2、foreachrdd代码实操
package com.atguigu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming10_output {
def main(args: Array[String]): Unit = {
// 1 初始化SparkStreamingContext
val conf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
val ssc = new StreamingContext(conf, Seconds(3))
// 2 通过监控端口创建DStream,读进来的数据为一行行
val lineDStream = ssc.socketTextStream("hadoop102", 9999)
// 3 切割=》变换
val wordToOneDStream = lineDStream.flatMap(_.split(" "))
.map((_, 1))
// 4 输出
wordToOneDStream.foreachRDD(
rdd=>{
// 在Driver端执行(ctrl+n JobScheduler),一个批次一次
// 在JobScheduler 中查找(ctrl + f)streaming-job-executor
println("222222:" + Thread.currentThread().getName)
rdd.foreachPartition(
//5.1 测试代码
iter=>iter.foreach(println)
//5.2 企业代码
//5.2.1 获取连接
//5.2.2 操作数据,使用连接写库
//5.2.3 关闭连接
)
}
)
// 5 启动=》阻塞
ssc.start()
ssc.awaitTermination()
}
}
3、注意
1)连接不能写在driver层面(序列化)
2)如果写在foreach则每个rdd中的每一条数据都创建,得不偿失
3)增加foreachpartition,在分区创建(获取)
第 6 章:优雅关闭
流式任务需要7*24小时执行,但是有时涉及到升级代码需要主动停止程序,但是分布式程序,没办法做到一个个进程去杀死,所以配置优雅的关闭就显得至关重要了。
关闭方式:使用外部文件系统来控制内部程序关闭。
1、主程序
package com.atguigu.sparkstreaming
import java.net.URI
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext, StreamingContextState}
object SparkStreaming11_stop {
def main(args: Array[String]): Unit = {
//1.初始化Spark配置信息
val sparkconf = new SparkConf().setMaster("local[*]").setAppName("sparkStreaming")
// 设置优雅的关闭
sparkconf.set("spark.streaming.stopGracefullyOnShutdown", "true")
//2.初始化SparkStreamingContext
val ssc: StreamingContext = new StreamingContext(sparkconf, Seconds(3))
// 接收数据
val lineDStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop102", 9999)
// 执行业务逻辑
lineDStream.flatMap(_.split(" "))
.map((_,1))
.print()
// 开启监控程序
new Thread(new MonitorStop(ssc)).start()
//4 启动SparkStreamingContext
ssc.start()
// 将主线程阻塞,主线程不退出
ssc.awaitTermination()
}
}
// 监控程序
class MonitorStop(ssc: StreamingContext) extends Runnable{
override def run(): Unit = {
// 获取HDFS文件系统
val fs: FileSystem = FileSystem.get(new URI("hdfs://hadoop102:8020"),new Configuration(),"atguigu")
while (true){
Thread.sleep(5000)
// 获取/stopSpark路径是否存在
val result: Boolean = fs.exists(new Path("hdfs://hadoop102:8020/stopSpark"))
if (result){
val state: StreamingContextState = ssc.getState()
// 获取当前任务是否正在运行
if (state == StreamingContextState.ACTIVE){
// 优雅关闭
ssc.stop(stopSparkContext = true, stopGracefully = true)
System.exit(0)
}
}
}
}
}
2、测试
1)发送数据
[atguigu@hadoop102 ~]$ nc -lk 9999
hello
2)启动hadoop集群
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /stopSpark