目录
源算子
1,从集合中读取数据
2,从文件读取数据
3,从 Socket 读取数据
4,从 Kafka 读取数据
5,自定义源算子
6,Flink 支持的数据类型
6.1 Flink 支持多种数据类型,包括但不限于:
6.2对于 POJO 类型,Flink 有以下要求:
转换算子
输出算子
源算子

Flink是一个强大的流处理框架,可以从各种数据源中获取数据,并构建DataStream进行转换处理。在Flink中,数据的输入来源通常被称为数据源,而读取数据的算子被称为源算子(Source)。因此,Source可以被视为整个处理程序的输入端。
在Flink代码中,添加源算子的通用方式是调用执行环境的addSource()方法。通过调用addSource()方法,可以获取DataStream对象,并向该方法传入一个实现了SourceFunction接口的对象作为参数。该接口定义了从数据源读取数据的方法。
以下是一个示例代码片段,演示如何使用addSource()方法添加源算子:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 添加源算子
DataStream<String> stream = env.addSource(new CustomSourceFunction());在上面的示例中,CustomSourceFunction是一个实现了SourceFunction接口的自定义类,它定义了从特定数据源读取数据的方法。通过调用addSource()方法并将CustomSourceFunction实例作为参数传递,可以创建一个包含源算子的DataStream对象。
通过这种方式,您可以轻松地将Flink与各种数据源集成,并开始处理流数据。请注意,Flink还提供了其他方法来添加数据源和构建DataStream,具体取决于您的需求和使用的编程语言。
1,从集合中读取数据
在处理数据时,直接在代码中创建集合并使用执行环境的 fromCollection 方法进行读取是一种简单且常用的方式。这种方法将数据临时存储在内存中,并形成一个特殊的数据结构,作为数据源供后续处理使用。
这种方式的优点在于简单易用,适用于数据量较小且不需要频繁更新的场景。它为开发者提供了一种快速在代码中创建数据集的方式,尤其在测试和验证阶段非常方便。
然而,这种方式的局限性也比较明显。由于数据存储在内存中,它不适合处理大规模数据集,因为内存资源有限。此外,一旦程序结束,数据集就会丢失,无法用于持久化存储或后续分析。
综上所述,虽然直接在代码中创建集合并使用执行环境的 fromCollection 方法进行读取是一种简单且常用的方式,但它主要用于测试和较小规模数据的处理。对于大规模数据或需要持久化存储的场景,建议使用更稳定和可靠的数据源读取方式,如从文件、数据库或消息队列系统中获取数据。
package com.atguigu.chapter05
import org.apache.flink.streaming.api.scala._
object SourceCollection {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val clicks = List(Event("Mary", "/.home", 1000L), Event("Bob", "/.cart",
2000L))
val stream = env.fromCollection(clicks)
stream.print()
env.execute()
}
}2,从文件读取数据
在真实的应用场景中,将数据直接写入代码并不是常见的做法。这样做不仅降低了代码的可维护性和灵活性,而且难以应对数据变化或数据源增多的情况。
为了提高数据处理和应用的灵活性与可扩展性,通常我们会从各种存储介质中获取数据。其中,读取日志文件是一种非常常见的方式。日志文件由于其结构化、标准化的特点,成为了许多应用进行数据收集、分析和处理的理想选择。
3,从 Socket 读取数据
数据处理中,我们通常面对的是有界数据,无论是从集合还是文件中读取。然而,在流处理场景中,数据呈现出截然不同的特性。流数据通常是无限的或具有近乎无限的生命周期,因为它不断地生成并在持续的时间段内持续存在。
当我们提到从 socket 读取文本流时,它作为一个简单的例子,突显了流处理的一个关键特点。这种方式的数据源是无界的,因为文本可以从 socket 源源不断地传输进来,没有明确的结束点。这种无界数据流的处理带来了独特的挑战,需要特定的策略和技术来应对。
值得注意的是,这种方式由于其吞吐量较小和稳定性较差,通常仅用于测试和演示目的。在生产环境中,为了高效地处理流数据并获得可靠的性能,更常见的做法是利用消息队列系统如 Apache Kafka 作为数据传输层。
4,从 Kafka 读取数据
Kafka 和 Flink 的结合,使得流处理能力得到了极大的提升。Kafka 作为分布式消息传输队列,具有高吞吐、易于扩展的特性,为实时流处理提供了强大的数据传输能力。与此同时,Flink 作为一个流处理框架,具备高效的分析计算能力,能够快速处理大量的实时数据。
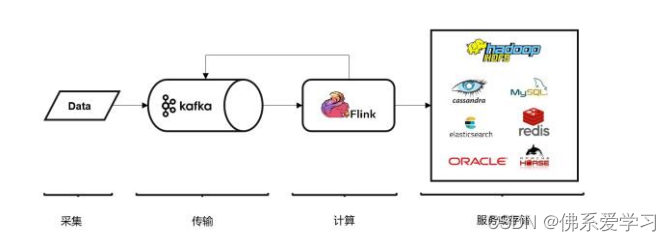
这种结合的优势在于,Kafka 负责数据的收集和传输,能够保证数据在分布式环境中的可靠传输和高吞吐量;而 Flink 则专注于数据的分析和处理,能够快速地处理实时数据流,提供实时的分析结果。
为了方便地使用 Kafka 作为数据源,Flink 官方提供了 flink-connector-kafka 连接工具,其中包含了一个名为 FlinkKafkaConsumer 的消费者类,它是一个 SourceFunction,用于从 Kafka 中读取数据。通过引入相应的依赖,开发者可以轻松地将 Kafka 作为数据源集成到 Flink 流处理应用中。
这种架构的优点在于,它能够帮助企业快速构建实时流处理应用,提高数据处理和分析的效率。同时,由于 Kafka 和 Flink 的高度集成和优化,这种架构还能够提供更好的扩展性和稳定性,满足企业不断增长的数据处理需求。
5,自定义源算子
在 Apache Flink 中,自定义算子是一种高级功能,允许用户根据特定的业务逻辑或数据处理需求编写自定义的算子。通过自定义算子,您可以扩展 Flink 的内置功能,实现更灵活和定制化的数据处理流程。
要创建自定义算子,您需要遵循以下步骤:
- 定义数据类型:首先,确定您要处理的输入和输出数据类型。这可以是 Flink 支持的基本类型、复合类型或自定义类型。
- 创建算子类:创建一个 Java 类来实现您所需的自定义算子逻辑。您需要继承
org.apache.flink.api.common.operators.Operator类或其子类,并实现必要的方法。 - 实现处理函数:在自定义算子类中,您需要实现处理函数(
process()方法)。该方法定义了您的自定义逻辑,用于处理输入数据并生成输出数据。 - 注册用户定义的函数:使用 Flink 的 UDF(User-Defined Function)机制注册您的自定义算子。这允许您在 Flink SQL 或 DataStream API 中使用自定义算子。
- 测试和验证:编写测试用例来验证您的自定义算子的功能和性能。确保它能够正确地处理输入数据并产生期望的输出结果。
- 使用自定义算子:一旦您完成了自定义算子的开发和测试,就可以将其集成到 Flink 作业中,并与其他 Flink 算子一起使用。
6,Flink 支持的数据类型
Flink 拥有自己完整的数据类型系统,为数据处理提供了便利。该系统通过使用“类型信息”(TypeInformation)来统一描述数据类型。TypeInformation 不仅是 Flink 中所有类型描述符的基类,还涵盖了类型的基本属性,并为每种数据类型生成特定的序列化器、反序列化器和比较器。
6.1 Flink 支持多种数据类型,包括但不限于:
- 基本类型:Java 和 Scala 的基本类型及其包装类,如 Int、Long、Double 等,以及 Void、String、Date、BigDecimal 和 BigInteger。
- 数组类型:包括基本类型数组(如 int[]、double[])和对象数组(如 String[])。
- 复合数据类型:
- Java 元组类型(TUPLE):Flink 内置的元组类型,最多支持 25 个字段。
- Scala 样例类及 Scala 元组:不支持空字段。
- 行类型(ROW):具有任意个字段的元组,支持空字段。
- POJO(Plain Old Java Object):Flink 自定义的类似于 Java bean 的类。
4.辅助类型:Option、Either、List、Map 等。
5.泛型类型(GENERIC):Flink 支持所有 Java 类和 Scala 类,但如果没有按照 POJO 类型的定义要求来定义,将被当作泛型类处理。
在这些类型中,元组类型和 POJO 类型最为灵活,因为它们支持创建复杂类型。而 POJO 还支持在键(key)的定义中直接使用字段名,大大提高了代码的可读性。因此,在项目实践中,流处理程序中的元素类型往往被定义为 Flink 的 POJO 类型。
6.2对于 POJO 类型,Flink 有以下要求:
- 类必须是公共的(public)且独立的(没有非静态的内部类)。
- 类必须有一个公共的无参构造方法。
- 类中的所有字段必须是 public 且非 final 修饰的;或者提供一个公共的 getter 和 setter 方法,这些方法需符合 Java bean 的命名规范。
- 对于 Scala 的样例类,它类似于 Java 中的 POJO 类。例如,Scala 的 Event 就是一个样例类,使用起来非常方便。
转换算子
转换算子
输出算子
输出算子