1.异常处理
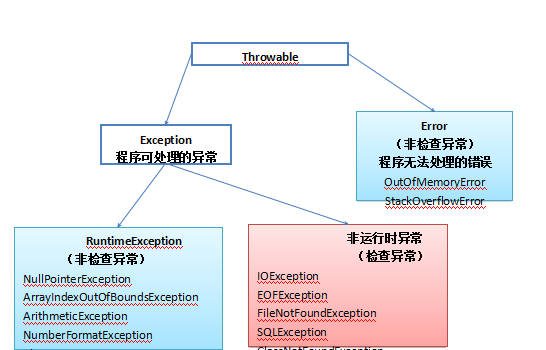
都是Throwable的子类:
① Exception(异常):是程序本身可以处理的异常。
② Error(错误): 是程序无法处理的错误。这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,一般不需要程序处理。
③ 检查异常(编译器要求必须处置的异常) : 除了Error,RuntimeException及其子类以外,其他的Exception类及其子类都属于可查异常。这种异常的特点是Java编译器会检查它,也就是说,当程序中可能出现这类异常,要么用try-catch语句捕获它,要么用throws子句声明抛出它,否则编译不会通过。
④ 非检查异常(编译器不要求处置的异常): 包括运行时异常(RuntimeException与其子类)和错误(Error)。
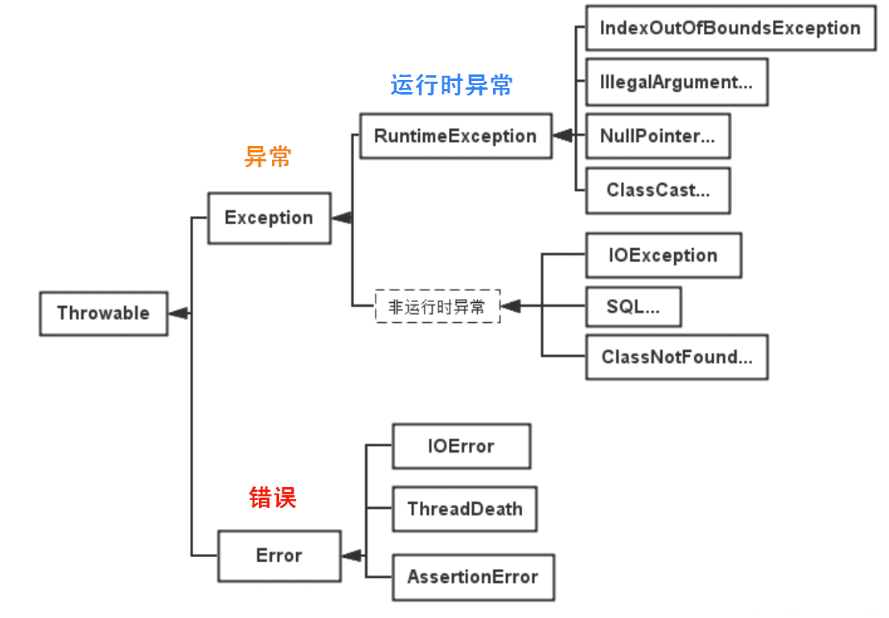
Throwable
Throwable 是 Java 语言中所有错误与异常的超类。
Throwable 包含两个子类:Error(错误)和 Exception(异常),它们通常用于指示发生了异常情况。
Throwable 包含了其线程创建时线程执行堆栈的快照,它提供了 printStackTrace() 等接口用于获取堆栈跟踪数据等信息。
Error(错误)
Error 类及其子类:程序中无法处理的错误,表示运行应用程序中出现了严重的错误。
此类错误一般表示代码运行时 JVM 出现问题。通常有 Virtual MachineError(虚拟机运行错误)、NoClassDefFoundError(类定义错误)等。比如 OutOfMemoryError:内存不足错误;StackOverflowError:栈溢出错误。此类错误发生时,JVM 将终止线程。
这些错误是不受检异常,非代码性错误。因此,当此类错误发生时,应用程序不应该去处理此类错误。按照Java惯例,我们是不应该实现任何新的Error子类的!
Exception(异常)
程序本身可以捕获并且可以处理的异常。Exception 这种异常又分为两类:运行时异常和编译时异常。
- 运行时异常
都是RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。
运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。 - 非运行时异常 (编译异常)
是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
可查的异常(checked exceptions)和不可查的异常(unchecked exceptions)
- 可查异常(编译器要求必须处置的异常):
正确的程序在运行中,很容易出现的、情理可容的异常状况。可查异常虽然是异常状况,但在一定程度上它的发生是可以预计的,而且一旦发生这种异常状况,就必须采取某种方式进行处理。
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于可查异常。这种异常的特点是Java编译器会检查它,也就是说,当程序中可能出现这类异常,要么用try-catch语句捕获它,要么用throws子句声明抛出它,否则编译不会通过。 - 不可查异常(编译器不要求强制处置的异常)
包括运行时异常(RuntimeException与其子类)和错误(Error)。
2.接口中的变量默认是public static final 的,方法默认是public abstract 的
3. 被final关键字修饰的类不能被继承,但抽象类存在的意义在于被其它类继承然后实现其内部方法的,这样final和抽象类之间就产生了矛盾。
4.重载的实现是编译器根据函数的不同的参数表,对同名函数的名称做修饰,那么对于编译器而言,这些同名函数就成了不同的函数。但重写则是子类方法对父类的方法的延申,即子类不仅继承了父类的方法,还向父类的方法中添加了属于自己的内容,改变了父类方法原本的内容,而final代表了一种不可变,这明显与重写形成了冲突。因此被final修饰的类可以被重载但不能被重写。
5.正则匹配
\d 匹配一个数字字符。等价于 [0-9]。
\D 匹配一个非数字字符。等价于 [^0-9]。
\f 匹配一个换页符。等价于 \x0c 和 \cL。
\n 匹配一个换行符。等价于 \x0a 和 \cJ。
\r 匹配一个回车符。等价于 \x0d 和 \cM。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。
\S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\t 匹配一个制表符。等价于 \x09 和 \cI。
\v 匹配一个垂直制表符。等价于 \x0b 和 \cK。
\w 匹配字母、数字、下划线。等价于'[A-Za-z0-9_]'。
\W 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'。
6.方法重写
- 参数列表必须完全与被重写方法的相同;
- 返回类型必须完全与被重写方法的返回类型相同;
- 访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为public,那么在子类中重写该方法就不能声明为protected。
- 父类的成员方法只能被它的子类重写。
- 声明为final的方法不能被重写。
- 声明为static的方法不能被重写,但是能够被再次声明。
- 子类和父类在同一个包中,那么子类可以重写父类所有方法,除了声明为private和final的方法。
- 子类和父类不在同一个包中,那么子类只能够重写父类的声明为public和protected的非final方法。
- 重写的方法能够抛出任何非强制异常,无论被重写的方法是否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以。
- 构造方法不能被重写。
- 如果不能继承一个方法,则不能重写这个方法。
7.方法重载
被重载的方法必须改变参数列表(参数个数或类型或顺序不一样);
被重载的方法可以改变返回类型;
被重载的方法可以改变访问修饰符;
被重载的方法可以声明新的或更广的检查异常;
方法能够在同一个类中或者在一个子类中被重载。
无法以返回值类型作为重载函数的区分标准。
8.内存模型
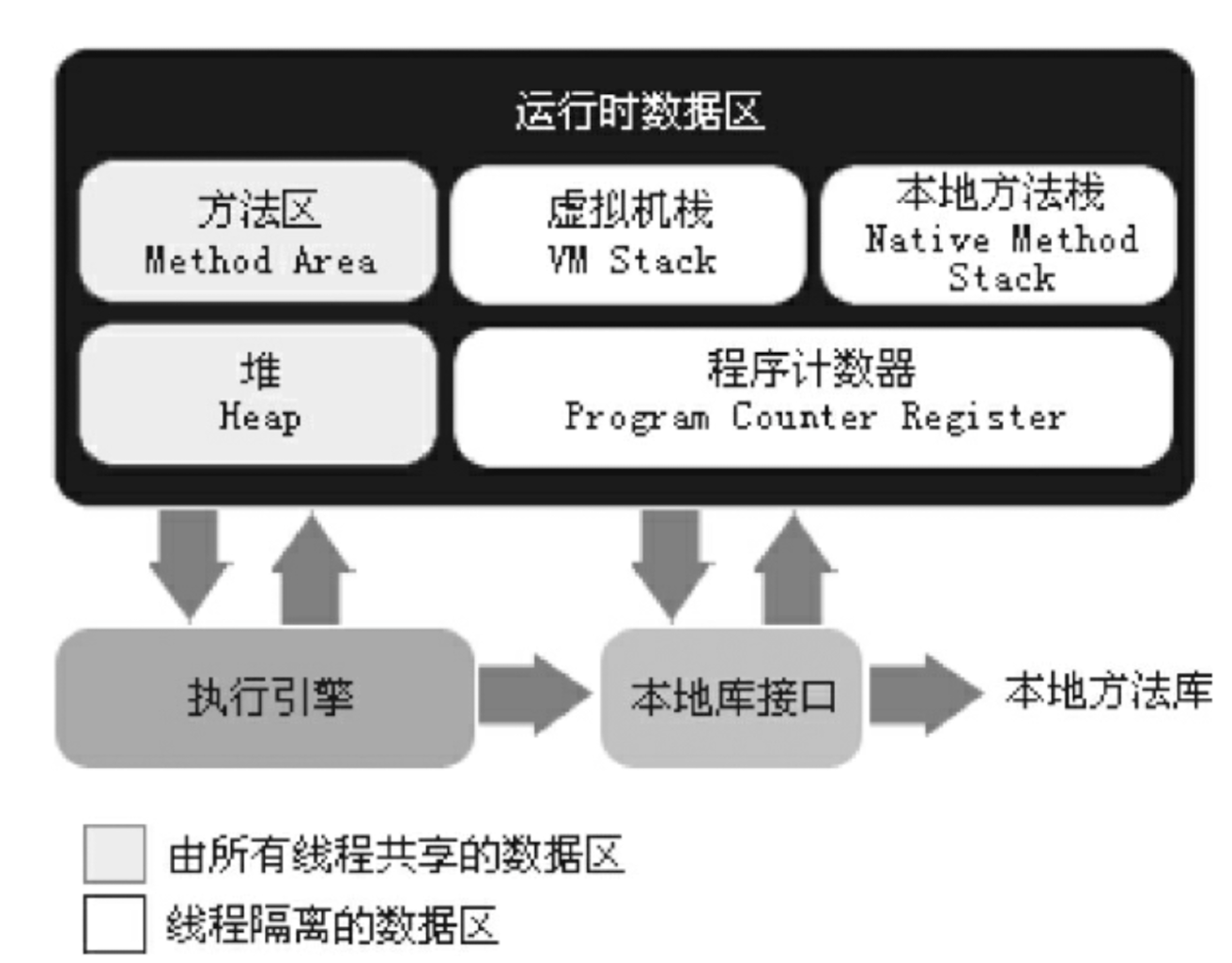
- 程序计数器:是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的信号指示器(偏移地址),Java编译过程中产生的字节码有点类似编译原理的指令,程序计数器的内存空间存储的是当前执行的字节码的偏移地址,每一个线程都有一个独立的程序计数器(程序计数器的内存空间是线程私有的),因为当执行语句时,改变的是程序计数器的内存空间,因此它不会发生内存溢出 ,并且程序计数器是jvm虚拟机规范中唯一一个没有规定异常的区域;
- java虚拟机栈:线程私有,生命周期和线程一致。描述的是 Java 方法执行的内存模型:每个方法在执行时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行结束,就对应着一个栈帧从虚拟机栈中入栈到出栈的过程。没有类信息,类信息是在方法区中 。
- java堆:对于绝大多数应用来说,这块区域是 JVM 所管理的内存中最大的一块。线程共享,主要是存放对象实例和数组
- 方法区:属于共享内存区域,存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
- 本地方法栈:(Native Method Stack)是 Java 虚拟机(JVM)为每个线程分配的一块内存区域,用于支持 Java 调用本地方法(Native Method)。与本地虚拟机栈类似,本地方法栈也是与线程生命周期绑定的。
主要作用包括:
- 本地方法调用:
本地方法栈用于支持 Java 虚拟机调用本地方法,即使用 Java 本地接口(JNI)调用由其他语言(如 C、C++)编写的本地库中的方法。 - 本地方法执行:
本地方法栈中存储了本地方法的执行信息,包括方法的参数、局部变量以及执行过程中的状态。每个本地方法调用都会创建一个新的栈帧(Frame)来存储与该方法相关的信息。 - 线程安全:
本地方法栈是线程私有的,每个线程都有自己的本地方法栈,因此不需要考虑多线程同步的问题。
与本地虚拟机栈类似,本地方法栈也可能存在栈溢出的问题,因此 JVM 的配置参数中可能包含设置本地方法栈大小的选项。通常情况下,开发者不太需要直接关注本地方法栈的细节,因为本地方法的调用通常是由 JVM 提供的库和实现来处理的。
需要注意的是,本地方法栈和本地虚拟机栈的区别在于它们分别用于存储 Java 方法的信息和本地方法的信息。在 Java 虚拟机规范中,并没有规定本地方法栈和本地虚拟机栈具体的实现细节,这些细节可能取决于具体的 JVM 实现。
9.匿名内部类的创建格式为:
new 父类构造器(参数列表)|实现接口(){
//匿名内部类的类体实现
}
- 使用匿名内部类时,必须继承一个类或实现一个接口
- 匿名内部类由于没有名字,因此不能定义构造函数
- 匿名内部类中不能含有静态成员变量和静态方法
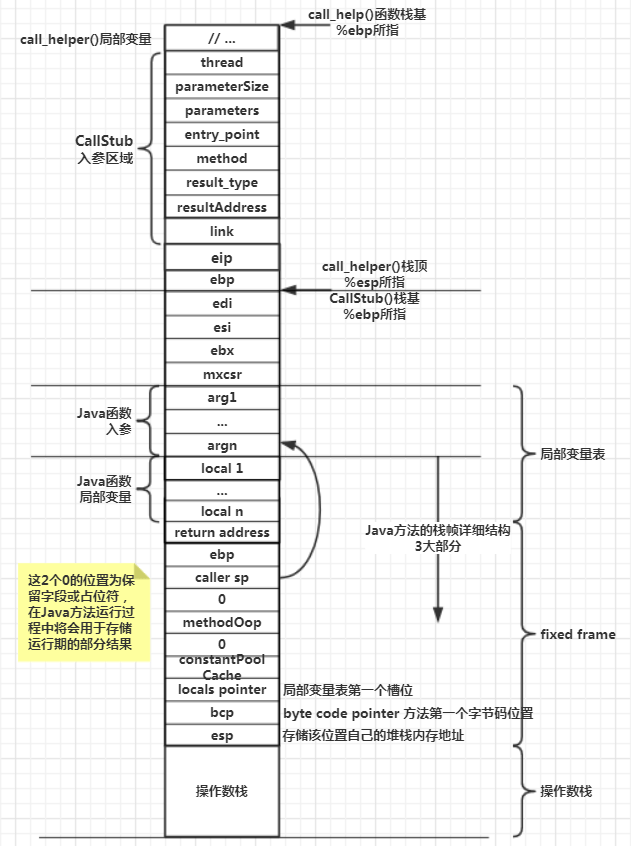
10.局部变量不是在该方法被执行/调用时创建,而是应该为在该变量被声明并赋值时创建,可以理解为“当代码执行到该变量被赋值的代码时才被创建” 栈会为每个方法在运行的时候分配一块独立的栈帧内存区域,栈帧又包含“局部变量表”、“操作数栈”、“动态链接”以及“方法出口”四个部分。
栈帧(Stack Frame)是在程序执行过程中,用于支持方法调用和执行的一种数据结构。每个方法调用时,都会创建一个新的栈帧,栈帧中包含了方法的局部变量表、操作数栈、动态链接、方法返回地址等信息。
一个典型的栈帧包括以下主要部分:
- 局部变量表(Local Variable Table):
用于存储方法参数和局部变量的值。局部变量表的大小在编译时确定,包括方法参数、方法内部定义的局部变量以及一些额外的空间。 - 操作数栈(Operand Stack):
用于执行运算操作的栈。操作数栈存储方法执行过程中的操作数,以及方法执行过程中的临时变量。 - 动态链接(Dynamic Linking):
指向运行时常量池中该栈帧所属方法的引用。通过动态链接,可以支持方法调用过程中的动态分派。 - 方法返回地址:
指向方法调用者在代码中的位置,即方法返回时需要继续执行的位置。 - 附加信息:
包括一些额外的信息,例如异常处理信息、调试信息等。
当一个方法被调用时,Java 虚拟机会创建一个新的栈帧并推入方法调用栈。方法执行完成后,栈帧会被弹出,控制权回到调用该方法的栈帧。
栈帧的概念是在程序执行时为了支持方法调用和返回而设计的,它允许方法之间的嵌套调用和控制流的转移。栈帧的结构在 Java 虚拟机规范中有详细的定义,不同的 JVM 实现可能在具体实现上有所不同。
11.Servlet与CGI 的比较
和CGI程序一样,Servlet可以响应用户的指令(提交一个FORM等等),也可以象CGI程序一样,收集用户表单的信息并给予动态反馈(简单的注册信息录入和检查错误)。
然而,Servlet的机制并不仅仅是这样简单的与用户表单进行交互。传统技术中,动态的网页建立和显示都是通过CGI来实现的,但是,有了Servlet,您可以大胆的放弃所有CGI(perl、php、甚至asp),利用Servlet代替CGI,进行程序编写。
- 对比一:当用户浏览器发出一个Http/CGI的请求,或者说调用一个CGI程序的时候,服务器端就要新启用一个进程(而且是每次都要调用),调用CGI程序越多(特别是访问量高的时候),就要消耗系统越多的处理时间,只剩下越来越少的系统资源,对于用户来说,只能是漫长的等待服务器端的返回页面了,这对于电子商务激烈发展的今天来说,不能不说是一种技术上的遗憾。而Servlet充分发挥了服务器端的资源并高效的利用。每次调用Servlet时并不是新启用一个进程,而是在一个Web服务器的进程敏感词享和分离线程,而线程最大的好处在于可以共享一个数据源,使系统资源被有效利用。
对比二:传统的CGI程序,不具备平台无关性特征,系统环境发生变化,CGI程序就要瘫痪,而Servlet具备Java的平台无关性,在系统开发过程中保持了系统的可扩展性、高效性。 - 对比三:传统技术中,一般大都为二层的系统架构,即Web服务器+数据库服务器,导致网站访问量大的时候,无法克服CGI程序与数据库建立连接时速度慢的瓶颈,从而死机、数据库死锁现象频繁发生。而我们的Servlet有连接池的概念,它可以利用多线程的优点,在系统缓存中事先建立好若干与数据库的连接,到时候若想和数据库打交道可以随时跟系统"要"一个连接即可,反应速度可想而知。
12.AOP常用注解
- @Before:Before 通知,用于方法执行前增强
- @AfterReturning :After Returning 通知,方法正常执行返回后增强
- @AfterThrowing:After Throwing 通知,方法执行通过抛出异常退出时
- @After:After (Finally) 通知,方法执行退出时执行增强,不管是正常返回,还是抛出异常退出,相当于try{}catch{}finally{}中的finally的语句。
- @Around:Around 通知,最强大的通知,环绕在目标方法前后执行。它有机会在方法运行之前和之后进行工作,并确定该方法何时、如何以及是否真正开始运行
13.bean的作用域由@scope注解来修改,该注解有五个不同的取值,分别是:singleton、prototype、request、session、global-session。
- singleton,在每一个Spring容器中,一个Bean定义只有一个对象实例(默认为singleton)
- prototype,允许Bean的定义可以被实例化任意次(每次调用都创建一个一个实例)
- request,在一次HTTP请求中,每个Bean定义对应一个实例。该作用域仅在基于Web的Spring上下文(例如SpringMVC)中才有效
- session,在一个HTTP Session中,每个Bean定义对应一个实例。该作用域仅在基于Web的Spring上下文(例如SpringMVC)中才有效
- global-session,在一个全局HTTP Session中,每个Bean定义对应一个实例。该作用域仅在基于Web的Spring上下文(例如SpringMVC)中才有效
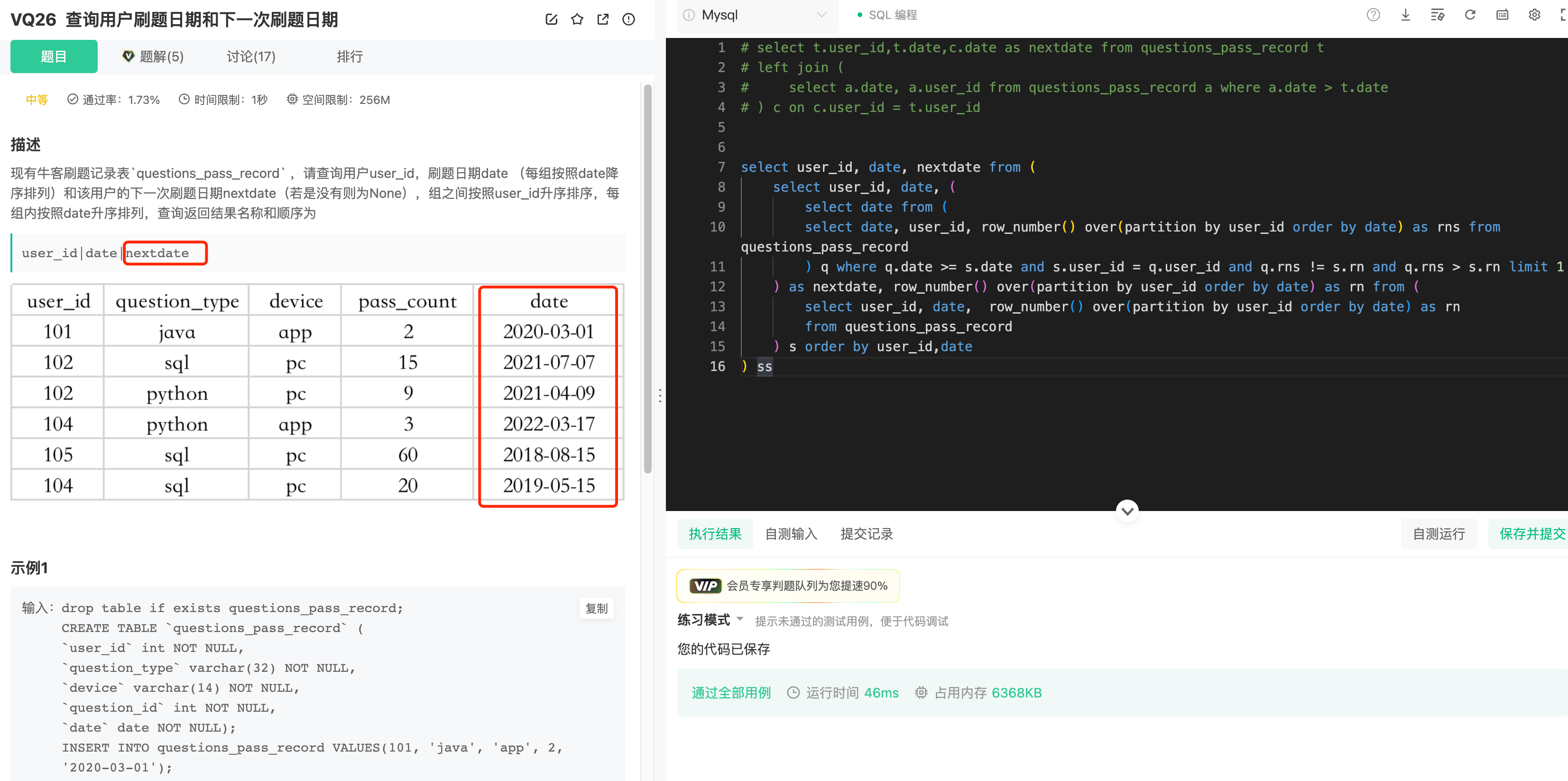
14.SQL
15.bean的注入有3种方式:1.属性注入、2.构造器注入、3.接口注入。bean的创建方式:1.构造器创建、2.实例工厂创建、3.静态工厂创建。
16.数据库的三级模式结构分为:概念模式,外模式,内模式
概念模式:也称为逻辑模式
是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
是数据库模式结构的中间层
一个数据库只有一个概念模式
外模式:也称为子模式
对应于用户级
一个数据库可以有多个外模式
内模式:也称为存储模式
对应于物理级
是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式
一个数据库只有一个内模式
两级映像:(为了能够在以上三个抽象层次之间的联系和转换,在三级模式之间设计了两层映像)
两层映像保证了数据库中的数据能够具有较高的逻辑独立性和物理独立性。
外模式/模式映像
外模式/模式映像,保证了当模式改变时,外模式不用变(逻辑独立性)
模式/内模式映像
模式/内模式映像,保证了当内模式改变时,模式不用变(物理独立性)
17.范式是符合某一种级别的关系模式的集合。关系数据库中的关系必须满足一定的要求,满足不同程度要求的为不同范式。
目前关系数据库有六种范式:
第一范式( 1NF )、第二范式( 2NF )、第三范式( 3NF )、 Boyce-Codd 范式( BCNF )、第四范式( 4NF )和第五范式( 5NF )。
满足最低要求的范式是第一范式( 1NF )。在第一范式的基础上进一步满足更多要求的称为第二范式( 2NF ),其余范式以次类推。
一般说来,数据库只需满足第三范式( 3NF )就行了。
第一范式:主属性(主键)不为空且不重复,字段不可再分(存在非主属性对主属性的部分依赖)。
第二范式:如果关系模式是第一范式,每个非主属性都没有对主键的部分依赖。
第三范式:如果关系模式是第二范式,没有非主属性对主键的传递依赖和部分依赖。
BCNF 范式:所有属性都不传递依赖于关系的任何候选键。
18.在对byte型的变量进行相加时,会先自动转换为int型进行计算,所以计算结果也是int型的,int型赋值给byte需要强制转换
19.我相信仔细看的话,每一本Java书都有讲过。“假设利用 return 语句从 try 语句块中退出。在方法返回前,finally子句的内容将被执行。如果 finally 子句中也有一个 return 语句,这个返回值将会覆盖原始的返回值。”
20.在类内部可以用户可以使用关键字 this.构造方法名() 调用(参数决定调用的是本类对应的构造方法) 在子类中用户可以通过关键字super.父类构造方法名()调用(参数决定调用的是父类对应的构造方法。) 反射机制对于任意一个类,都能够知道这个类的所有属性和方法,包括类的构造方法。
21.创建线程的方法:
1)从Java.lang.Thread类派生一个新的线程类,重写它的run()方法;
2) 实现Runnable接口,重写Runnable接口中的run()方法。
22.链接:《深入理解Java虚拟机》P228:对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类名称空间。这句话可以表达得更通俗一些:比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个虚拟机加载,只要加载它们的类加载器不同,那么这两个类必定不相等。接口类是一种特殊类,因此对于同一接口不同的类装载器装载所获得的类是不相同的。
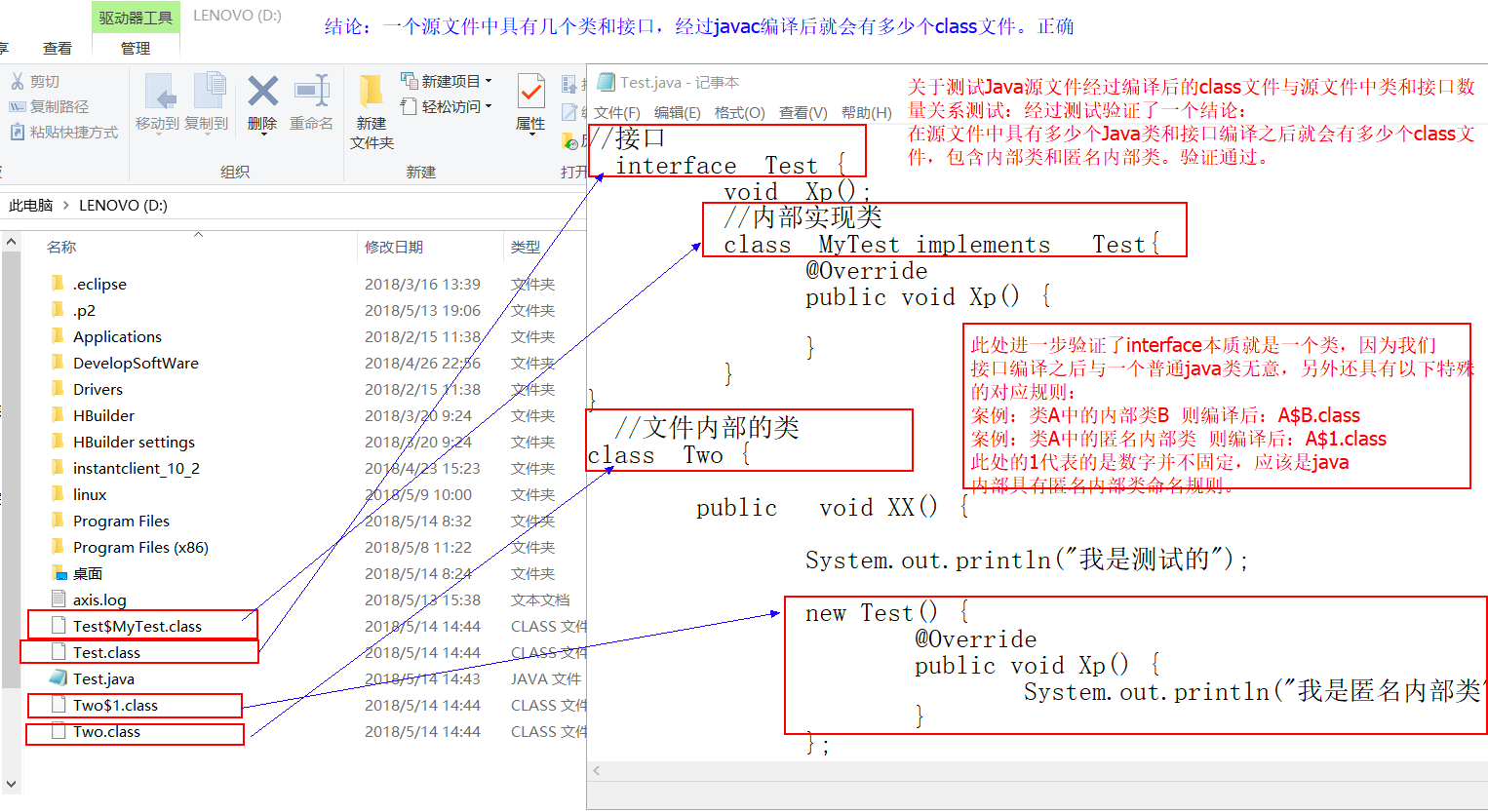
23.一个原文件中有几个类和结果,经过javac编译过后就会有多少个class文件
24.下列哪个对访问修饰符作用范围由大到小排列是正确的?
public>protected>default>private
25.基础数据类型
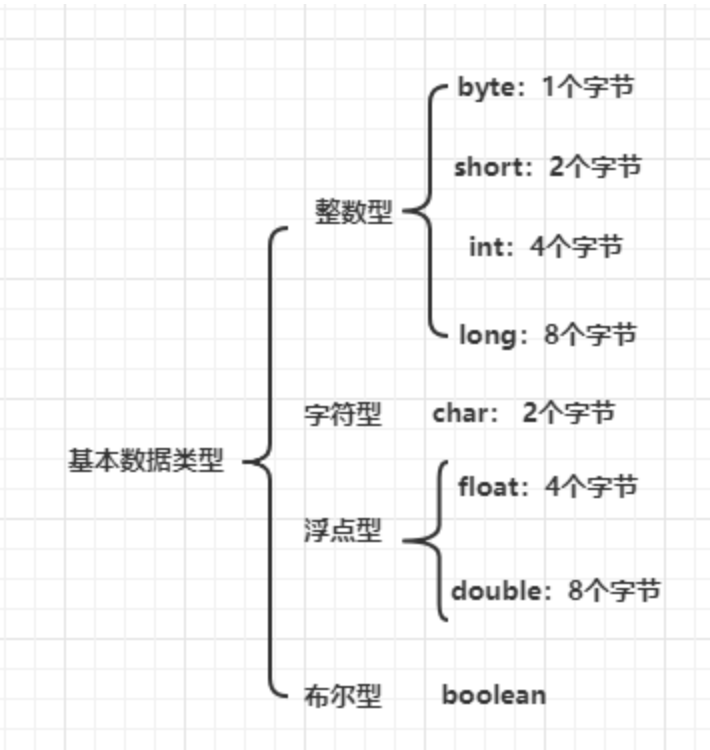
Java编程语言支持的八种原始数据类型是:
-
byte:byte数据类型是8位带符号的二进制补码整数。最小值为-128,最大值为127(含)。的byte数据类型可以是在大型保存存储器有用 阵列,其中存储器的节省实际上重要的。它们也可以用于int限制其位置的地方,以澄清您的代码;变量范围有限的事实可以作为文档的一种形式。
-
short:short数据类型是一个16位带符号的二进制补码整数。最小值为-32,768,最大值为32,767(含)。与一样byte,也适用相同的准则:在实际short需要节省内存的情况下,可以使用a来以大阵列保存内存。
-
int:默认情况下,int数据类型是32位带符号的二进制补码整数,其最小值为-231,最大值为231 -1。在Java SE 8和更高版本中,可以使用int数据类型表示无符号的32位整数,其最小值为0,最大值为2 32 -1。使用Integer类可将int数据类型用作无符号整数。有关更多信息,请参见“数字类”部分。像静态方法compareUnsigned,divideUnsigned等已被添加到 Integer类,以支持算术运算的无符号整数。
-
long:long数据类型是64位二进制补码整数。带符号的long的最小值为-263,最大值为263 -1。在Java SE 8和更高版本中,可以使用long数据类型表示无符号的64位长,其最小值为0,最大值为2 64 -1。当您需要的值范围比所提供的宽时,请使用此数据类型int。该 Long班还包含方法,如compareUnsigned,divideUnsigned等长,以支持算术运算的无符号。
-
float:float数据类型是单精度32位IEEE 754浮点。其值的范围超出了本文的讨论范围,但在Java语言规范的“ 浮点类型,格式和值”部分中进行了指定。与针对byte和的建议一样,如果您需要将内存保存在大的浮点数数组中short,请使用float(而不是double)。永远不要将这种数据类型用于精确值,例如货币。为此,您将需要使用 java.math.BigDecimal类。 数字和字符串覆盖BigDecimal以及Java平台提供的其他有用的类。
-
double:double数据类型是双精度64位IEEE 754浮点数。其值的范围超出了本文的讨论范围,但在Java语言规范的“ 浮点类型,格式和值”部分中进行了指定。对于十进制值,此数据类型通常是默认选择。如上所述,永远不要将这种数据类型用于精确值,例如货币。
布尔值:boolean数据类型只有两个可能的值:true和false。将此数据类型用于跟踪真/假条件的简单标志。这种数据类型代表一小部分信息,但是其“大小”并不是精确定义的。
char:char数据类型是单个16位Unicode字符。它的最小值为’\u0000’(或0),最大值为’\uffff’(或65,535,包括端值)。
26.父类B静态代码块->子类A静态代码块->父类B非静态代码块->父类B构造函数->子类A非静态代码块->子类A构造函数
27.java 加载数据库驱动的方式
1.DriverManager.registerDriver(new …);
2.Class.forName(“com…”); //静态代码块
3.System.setProperty(“jdbc.drivers”,“com…”); //DriverManager的静态代码块static{loadInitialDrivers();}
DriverManager 简介:
DriverManager 是 Java JDBC API 提供的一个类,用于管理一组数据库驱动程序。其主要作用是加载数据库驱动程序并建立数据库连接。以下是 DriverManager 的实现原理:
1.加载数据库驱动程序:
- 在使用 JDBC 连接数据库之前,需要加载特定数据库的 JDBC 驱动程序。DriverManager 提供了 registerDriver 方法用于注册 JDBC 驱动程序。
- 驱动程序通常通过调用 Class.forName(“com.mysql.cj.jdbc.Driver”) 或者 DriverManager.registerDriver(new com.mysql.cj.jdbc.Driver()) 进行注册。
2.获取数据库连接:
- 通过 DriverManager.getConnection 方法获取数据库连接。该方法接受一个 URL、用户名和密码作为参数,返回一个表示与数据库的连接的 Connection 对象。
- getConnection 方法会尝试加载注册过的驱动程序,并调用每个驱动程序的 connect 方法来建立数据库连接。
3.驱动程序的加载和注册:
- 当 JVM 加载一个类时,会执行该类的静态初始化代码。大多数 JDBC 驱动程序在静态初始化代码块中会调用 DriverManager.registerDriver 方法,将自己注册到 DriverManager 中。
- 还可以使用 Class.forName 方法动态加载并注册驱动程序,该方法会自动执行静态初始化代码块。
4.连接池管理:
- DriverManager 并没有提供连接池的直接支持,但可以通过其他方式结合连接池框架使用。一些数据库连接池框架(如 Apache DBCP、C3P0、HikariCP)提供了对 DriverManager 进行包装的功能,以便更好地管理和控制数据库连接。
5.数据库连接的生命周期:
- 通过 DriverManager 获取的数据库连接,其生命周期由应用程序管理。通常,连接使用后需要显式地关闭,以释放资源。
- 在关闭连接时,应用程序可以调用 Connection 对象的 close 方法,将连接返回给连接池或直接关闭,具体取决于连接池的使用方式。
总体而言,DriverManager 的实现原理是通过加载和注册 JDBC 驱动程序,然后通过连接字符串、用户名和密码等信息创建数据库连接。虽然 DriverManager 是 JDBC 的一部分,但在实际应用中,更多的是使用连接池来管理数据库连接,以提高性能和资源利用率。
27. int与Integer、new Integer()
(1) int与Integer、new Integer()进行比较时,结果永远为true
(2) Integer与new Integer()进行比较时,结果永远为false
(3) Integer与Integer进行==比较时,看范围;在大于等于-128小于等于127的范围内为true,在此范围外为false。
下面是解析过程:
①.Integer与int比较时,Integer会有拆箱的过程,我们可以看看拆箱的代码:
直接返回的就是value,因此int与Integer以及new Integer()进行 ==比较时结果都是true。
②.Integer a=n时,如果n大于等于-128小于等于127时,会直接从IntegerCache中取,不在这个范围内,会new一个对象,所以Integer与new Integer进行 ==比较时,结果都是false。
③.Integer与Integer比较,需要看范围,如果在-128~127(包含-128,不包含127)范围内,因为都是从IntegerCache中取值,所以相等;若不在这个范围内,则都要去new一个对象,所以结果为false。
28. jdk 8后新增了default修饰符。接口中,被default修饰的方法,可以不是必须要实现的。
29.private是私有变量,只能用于当前类中,题目中的main方法也位于当前类,所以可以正确输出
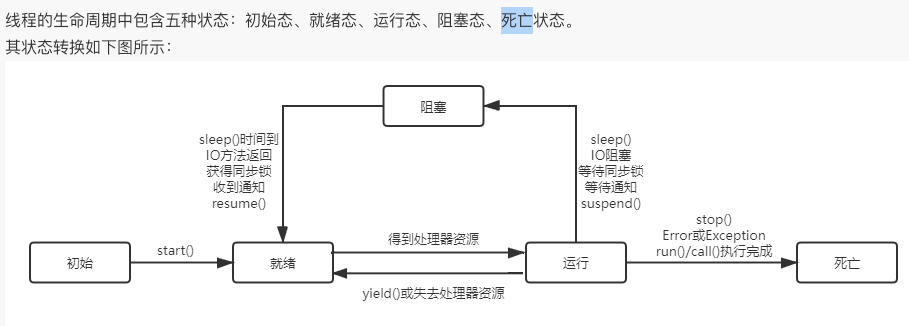
30.线程五种状态





![[每日一题] 01.24 - 求三角形](https://img-blog.csdnimg.cn/direct/5a1bd7b1673140cd93e755b8d7e3d18a.png)