1、研究背景及意义
随着互联网技术的发展以及大数据、人工智能等新科技时代的来临,我国高校教育改革、高校人才培养也面临着新的机遇与挑战。一方面,为了实现国家战略、支撑快速发展的新经济,需要高校变革发展培养新型人才,满足社会发展的新需求;另一方面,新时代教育理念、教育技术的与时俱进,加速教育信息化、智慧教育的发展,为高素质人才培养提供保障。
现今我国高校已经全面建成数字校园,并逐步向“智慧数字校园”迈进。因此,高校学生在校园中每时每刻都会产生大量的行为数据,如何充分利用这些学生行为数据,助力高校教学改革、提升教学管理水平、提高学生培养质量是现代化高校教育面临的热点问题。
而高校教学活动中,学生测评是其中至关重要一环,是对教学质量和学生学习状态的一种监控手段和方法。目前,已有高校学生测评方法主要是根据学生成绩信息和各种量化积分,并依据学校行政部门指定的管理制度给出一个分数,作为学生评优评先和奖学金的依据。由此可知,已有的测评方法具有间断性,且评测结果未能充分体现学生在校期间的动态学习状态和发展路径过程,因而不具备及时地学生导向调节、精准引导学生发展的能力。此外,若评测系统不能实时反映当前学生的学习状态,不仅不利于学生及时对自身进行调整、提高学习效率、提升学习能力,也不利于学校对学生学习行为的精准干预和管理。这将严重影响高校人才的培养质量,使得高校毕业生难于适应如今高速变革的社会发展的需求。而高等教育是社会发展的重要依靠、是社会发展的动力之源,所以高校人才质量直接影响并制约着国家的发展和未来。
2、知识图谱研究现状
2.1 国内外研究及发展现状
现今我国高校已经全面建成数字校园,并逐步向“智慧数字校园”迈进。因此,高校学生在校园中每时每刻都会产生大量的行为数据,如何充分利用这些学生行为数据,助力高校教学改革、提升教学管理水平、提高学生培养质量是现代化高校教育面临的热点问题。
在高校向智慧化水平迈进过程中,学生测评是其中至关重要一环,是对教学质量和学生学习状态的一种监控手段和方法。高校现多采用收集学生行为数据来开展分析以此构建系统来测评学生发展情况。
而本系统利用知识图谱来解决以上问题:
知识图谱分为领域知识图谱与百科性知识图谱,本系统主要针对学生行为构建领域型知识图谱,据目前研究资料可知:目前高校尚未应用此知识图谱。
知识图谱本身上的节点覆盖足够多的实体,足够多的概念,可以作为用户画像的标签来源,精良的质量使得打上的标签更加的准确。这些标签间有具有联系,图谱中有丰富的语义关系,这样可以帮助机器去理解这些标签的意义。友好的结构利于人们去更好的理解,直观的发现标签间的关系。可以利用标签传播,跨领域推荐等算法去挖掘更多更精准的标签来描述用户,丰富用户标签,提升用户精准度。另外在做学生画像时,学生画像可以单独作为产品可视化的进行呈现,利用图谱中的关系,生成个性化的,动态变化的用户知识图谱。
2.2 领域知识图谱构建的一般过程及技术、方法
学生行为知识图谱构建主要是基于多种数据处理技术,多渠道抽取有价值的学生行为知识,以三元组的形式存储于图数据库中。[1]
知识图谱的构建主要分为自顶向下和自底向上两种构建方法。自顶向下构建方法需要领域专家参与本体构建,而自底向上方法成本较低、自动化程度高,本项目根据实际情况采用自底向上方法构建学生行为知识图谱。
知识图谱的数据来源:数据分为结构化数据、半结构化数据以及非结构化文本数据,结构化数据主要是从学校管理系统中导出的学生基本信息数据以及在学生官方使用学习软件中导出数据,半结构化数据时网页爬取具有一定结构的数据,例如json数据等,而非结构化数据主要是根据学生填写调查问卷以及领域收集文本数据。对于结构化和半结构化数据可以直接提取识别其实体关系属性,而对于调查问卷所得出的纯文本非结构化数据,不仅包含知识,而且内容设计范围大、参差不齐,需要通过自然语言处理技术来提取文本结构的语义。学生行为知识图谱构建流程如图1.4.1所示。
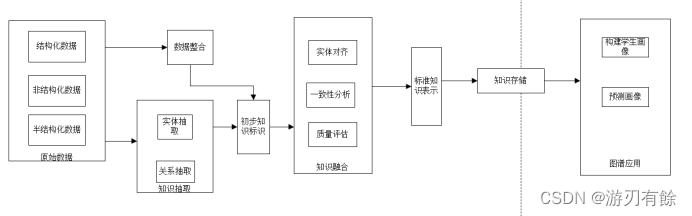
图1.4.1 构建知识图谱流程
**
3.学生行为知识图谱及用户画像的可视化模型构建
**
3.1学生行为知识图谱
根据上述知识图谱构建流程,下面分为知识抽取、知识融合、知识加工三个部分进行论述:
3.1.2 知识抽取
知识图谱基本组成单位是“实体-关系-实体”三元组,以及实体及其相关属性-值对,实体间通过关系相互联结,构成网状的知识结构。知识抽取主要是抽取实体、关系以及属性[2].具体步骤如下所述:
3.1.2.1 实体识别
实体是知识图谱最基本的组成部分,实体识别又称为命名实体识别。对于从学校教务系统中导出的学生基础信息等结构化数据,可以依据表关系直接提取其实体。
而对于学生数据、课程、课堂表现、心理、运动、身体素质、娱乐、等方面的非结构化文本数据的实体抽取,可以看作序列标注问题。[3序列标注是指对于一个句子,输出其对应的一个序列标记,每个字对应一个标记。在命名实体识别中常用 BMEO来进行序列标记,即如果对应的字不是实体的一部分,则标注为O;如果是实体第一个字,则标注为B;如果是实体最后一个字,则标注为E:如果是实体中间的字,则标注为M;标注时可以加上实体的类型。]示例如图3.1.2.1.2所示。

图3.1.2.1.1 命名实体识别序列标记示例
而根据上下文信息预测当前字的标记,本系统基于整个句子作为特征建模而不仅仅是依据其前一个字,在此使用条件随机场模型(CRF),如下图3.1.2.1.2所示,CRF模型充分考虑了上下文特征,使得结果更加精确。系统提取实体内容如下图3.1.2.1.3所示。
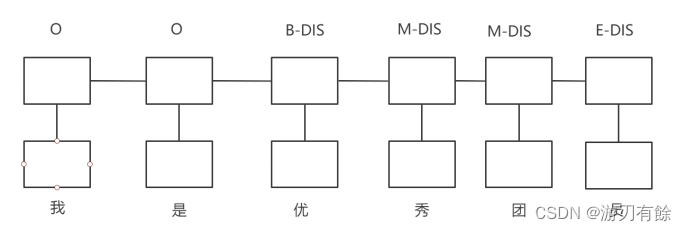
图3.1.2.1.2 CRF网络结构
图3.1.2.1.3 实体抽取图
3.1.2.2 属性抽取
在上述实体抽取基础上,对实体再次进行属性抽取,对于学生基本信息等结构化数据,根据数据表之间存储关系进行属性抽取,例如学生姓名、专业、学院,而对于非结构化数据,主要依靠文本数据对该试题的描述进行识别。属性抽取情况如下表所示;
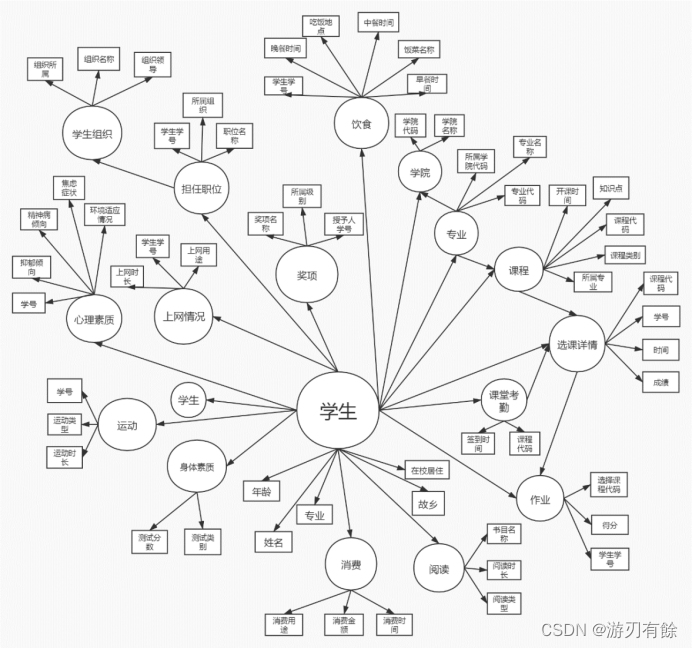
图3.1.2.2.1 属性抽取图
3.1.2.3 关系抽取
实体关系抽取[3]是在命名实体识别前提下,自动识别有一对实体和联系这对实体的关系构成的相关三元组。基本本系统数据源来源多样,对于学生信息等表结构的数据,可以根据表定义的关系直接进行关系抽取。而对于非结构化的文本数据。系统主要采用了基于规则的关系抽取以及深度学习方法进行关系抽取,基于规则的关系抽取首先通过基于规则的模式匹配方式解决关系抽取问题,从文本数据中抽取实体之间的上下位关系,并将模式泛化,在多种文本中均具有适用性。而深度学习方法近年来在关系抽取领域也得到了很多应用,通过采用卷积神经网络(CNN)的架构来模拟给定实体之间的子句,而并非对整个句子进行建模,同时使用LSTM模型来提取最终的关系模式,此种方法弥补了当前大多数基于深度学习的方法主要集中在学习单个句子的语义表示而不能反应上下文的问题,具体如下图3.1.2.2.1所示:
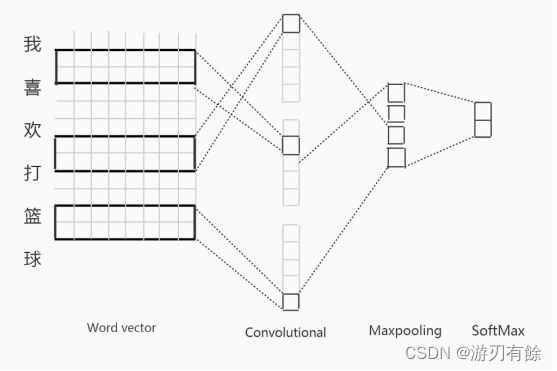
图3.1.2.2.1 CNN关系抽取模型结构图
在此模型中,将句子中第i个字的k维向量表示作为xi,从而该句子表示为:
令表示为h*k窗口大小的卷积核,所以经过卷积操作的特征c为
b为偏置向量,F是非线性激活函数,经过卷积操作,句子转变为特征图c:
最后经过最大值池化的方法,用每个特征图中值最大的特征表示整个特征图,此为一个卷积核提取特征,CNN同时使用多个不同窗口大小的卷积核提取多个特征,最后在全链接Softmax层进行分类。
3.1.3 知识融合
通过上述对学生行为数据命名实体识别和关系抽取,实现了从结构化文本中获取实体和关系的目标。然而这些结果可能会包含错误及冗余信息,所以还需要对数据进行清理和整合,保证知识图谱的质量。
本系统知识融合通过以下部分来详细阐述:
3.1.3.1 实体对齐
实体对齐是指对于从文本中抽取的得到的实体对象。再从知识图谱中选择一组候选对象,通过计算相似度计算将抽取得到的实体对象链接到知识图谱中的实体对象。核心在于实体相似度的度量。在此本系统利用了谷歌的word2vec思想训练得到词向量矩阵。
3.1.3.2 一致性分析
一致性分析[4]是指在知识图谱构建构成中消除语义上的冲突,即通一组实体识别出不同的关系,一致性分析的方法有三种:基于数据源、基于支持度、和基于人工,基于数据源一般对于结构化数据的可信度要优于非结构化数据,例如:从学校教务系统中导出来的学生基本信息数据要优于对学生文本信息数据进行实体命名关系识别得出来的实体数据。而基于支持度是根据每个实体或关系为真的依据在文本中出现的次数进行取舍,而人工是在上述两种方法无法解决时使用人干预的方法进行取舍,由于本系统数据源多样,既有结构化也有非结构化,所以三种方法均使用。
3.1.3.3 质量评估
质量评估[5]是对提取知识的质量和可信度进行量化,舍弃质量较差的知识。而知识图谱的评判方法一般分为基于本体、基于数据、基于人工三种,基于本体是将提取中的实体与成熟公开的知识库进行对比;基于数据是将提取结果与行业数据集进行对比,基于人工是指人工对结果分析;由于现在尚缺少有关于校园等的成熟知识库且数据集也尚无衡量标准,所以系统暂且采用人工分析的办法,人工衡量知识库的质量水准。
3.1.4 知识存储
针对知识图谱的不同表示方式,存储方式也各有所异。对于图结构,Neo4j作为使用量世界排名第一的图数据库,不仅可以存储图结构的数据,而且提供可视化的界面进行管理。并且Neo4j提供的图算法为频繁查询提供了高性能的保障。而在数据安全方面,有完备的事务管理。Neo4j数据灵活,支持各大主流语言,方便敏捷快速的开发模式,因此对于本系统图结构的知识图谱,采用Neo4j作为基础数据库,提供可视化存储和服务。
3.2基于知识图谱的学生画像可视化模型的构建
3.2.1 学生属性标签的构建
利用知识图谱实体与属性之间的关联,可以利用构建的学生行为知识图谱直接提取学生实体以及与学生关联的实体的属性作为学生画像的静态属性标签,主要包括:学生实体的年龄、班级、性别、姓名、在校担任职位、在校选择课程等静态属性,鉴于图谱覆盖范围足够广、以及实体之间的相互联系,所以标签具有优良的质量。系统刻画的学生画像属性标签如下表1所示:


表1 学生画像属性标签表
3.2.2 学生行为标签的构建
在获得学生属性标签后,依据学生用户行为数据进行统计分析从而产生行为标签,根据现今已有数据,学生行为标签主要包括学习标签、心理健康标签、身体素质标签、消费标签、娱乐标签。而对于某些学生行为数据不足、数据量过小问题,基于学生行为知识图谱可以使得标签传播、标签扩展,从而扩大学生标签范围以及弥补数据量不足,例如某些学生根据其行为无法为其得出标签结果,则可以通过其好友而分析该学生的画像标签,而且该学生所拥有好友的共性标签越多,该学生具有该标签的可能性越大,从而产生学生好友之间的标签传播,学生标签单单阐述某一种问题,基于图谱可以为其实现标签扩展,例如:学生是软件工程专业从而得到学生是IT行业标签。标签建立体系如下表2所示:
图3.2.2.1 基于行为标签的用户画像
3.2.3 学生画像的可视化模型
本系统中,学生行为数据主要聚焦在学生学业水平、身体健康、心理素质、实践能力扩展、娱乐、消费、课堂表现等方面。各类原始数据经过数据清洗后,将通过算法和数学模型进行最终的标签匹配,所以算法模型的设计很大程度上决定着用户画像最终实现效果,在学生画像的构建中,系统采用多样的计算模型。
针对学生课堂活跃程度、娱乐等评分类标签,采用了行为类型权重及时间衰减算法:。再结合学生课堂参与程度、课堂考勤、作业完成、阅读类型、打球时间等不同行为的权重类型以及考虑时间衰减因子,最终得到相匹配的学生课堂标签。
针对学生消费标签,采用RFM模型,动态显示了一个客户的全部消费轮廓,标签计算时,通过对每个用户最近消费(R)、消费频率(F)、消费金额(M)三个维度的综合计算,实现学生群体的精确细分,区别出高消费、一般消费、低消费用户,从而确定学生的家庭经济状况,便于教育管理者进行学校内部贫困生评选等活动,使得结果更加客观化。
对于学生学业水平标签,使用统计分析办法,采用规则进行统计计算,例如:学生在校六个学期经过统计分期期末测试学业水平均处于年级前10%,则此学生则有“学霸”标签、学生体测成绩反映其身体素质水平处于班级靠前,则学生拥有“运动健儿”标签,
针对心理素质、生活等标签,根据基于规则的自然语言分析得出标签,例如:学生在调查问卷中填写有关于心理测试问题的答案:对于“焦虑”、“烦躁”、“压力大”、“失眠”、“老师批评”、“心情沮丧”等词汇进行统计分析,从而得出学生近期心理状态,而“按时早饭”、“体育锻炼”、“熬夜”、“通宵”等词汇的频率决定着生活标签的评定。
最终得到的学生用户画像可以单独作为产品为学生进行可视化呈现,利用当下流行技术E charts、D3.js在微信小程序等移动端等为学生用户描绘出多图形、图像及图表数据展示的用户画像,并对学生群体使用进行某一特征向量的提取,从而生成某一类学生群体的用户画像。

图3.2.3.1 学生用户画像
3.2.4预测未来“谁是学霸”——基于知识图谱的学生画像预测
针对学生用户已经构建的学生画像,系统主要采用朴素贝叶斯算法来对学生未来的学业水平成绩进行预测。
朴素贝叶斯(Naive Bayes)假设特征P(A)在特定结果P(B)下是独立的,在已知P(A|B)时求P(B|A):
使用朴素贝叶斯算法,可以在已知P(第1个学期学业水平成绩×第2学期学业水平成绩×…×第n-1学期学业水平成绩|第n学期学业水平成绩)的情况下求出P(第n学期学业水平成绩|第1个学期学业水平成绩×第2学期学业水平成绩×…×第n-1学期学业水平成绩),即可以通过该算法根据前n个学期的学业水平成绩预测第n个学期的学业水平成绩,公式如下:

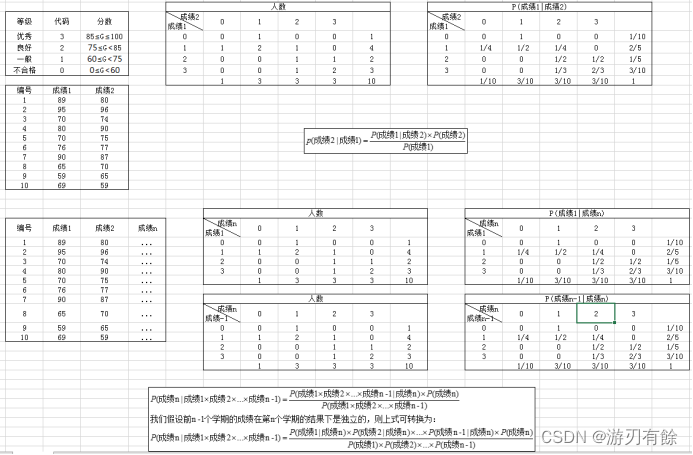
图5.3.1 朴素贝叶斯预测成绩原理
4、 总结
为了能够使学生通过平台可以全面了解个人综合能力发展、学习与专业核心能力情况、综合素质评价、健康、饮食情况等信息,首先需要对学生个人信息、在校期间各类的数据(例如课程缺勤、作业完成、对社团及各项体育项目的参加情况)进行汇集、预处理等。
在前述采集数据的基础上,进行实体-关系识别,利用知识图谱构建技术,构建出学生行为知识图谱,并利用用户画像方法,构建出学生个性化信息用户画像。
并在此基础上,进一步将前述复杂的数据及分析结果以图形、图像及图表等多种可视化方式呈现出来,以便于为学生和教师直观展示前述学生测评与分析的结果。例如,可视化的呈现出学生行为属性、生活习惯、消费水平等信息,以及完整描述教育目标群体的特征等。
知识图谱的应用非常广泛,特别适合于智能客服、金融、公安、航空和医疗等“知识密集型”领域。知识图谱是动态发展的,基于大数据不断收集与更新基础上,利用计算机,半自动地分析和挖掘出相关信息之间的联系,辅助人决策。知识图谱应用仍在发展,如果知识是人类进步的阶梯,知识图谱就是AI进步的阶梯。
参考文献
[1] 宁泽飞.孙静宇.王欣娟[D].基于知识图谱和标签感知的推荐算法,太原理工大学,2021.11.15
[2]李俊丽,张洋,陈润赫[R],基于可视化知识图谱的心电图特征分析,青岛大学自动化学院,2021.09.05
[3]魏自强.郑伟伟.许永康[R].基于百科知识的医疗数据知识图谱构建,贵州航天计量测试技术研究所,《网络安全技术应用》2020.
[4]杨笑然.基于知识图谱的医疗专家系统[D],浙江大学,2018.1.15