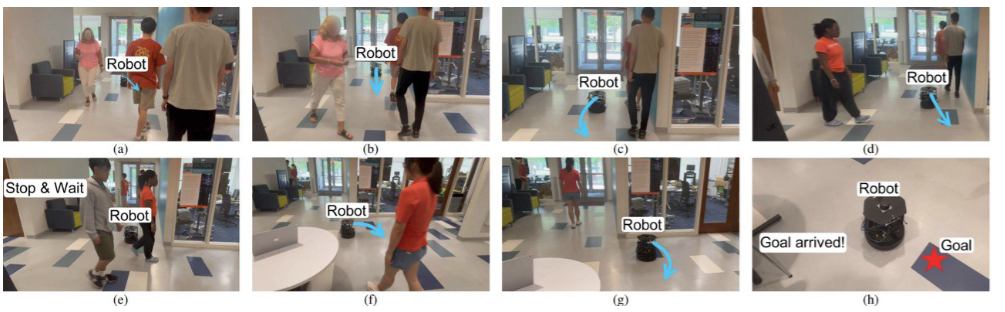
一、什么是ELK
ELK是三个产品的简称:ElasticSearch(简称ES) 、Logstash 、Kibana 。其中:
- ElasticSearch:是一个开源分布式搜索引擎
- Logstash :是一个数据收集引擎,支持日志搜集、分析、过滤,支持大量数据获取。其自带输入(input)、过滤语法(grok)、输出(output)三部分,可将数据输出到ES
- Kibana:为 Elasticsearch 提供了分析和 Web 可视化界面

二、如何搭建ELK
各个版本:
ElasticSearch ,Logstash ,Kibana 的版本都为 7.14.0 , JDK:11
1、搭建 ElasticSearch 和 Kibana
参考我之前的博客:
Springboot中使用Elasticsearch(部署+使用+讲解 最完整)_spring boot elasticsearch-CSDN博客![]() https://blog.csdn.net/qq_73440769/article/details/141477177?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_73440769/article/details/141477177?spm=1001.2014.3001.5501
2、搭建Logstash
1.查看自己的es版本
docker images
2.拉取镜像
这个步骤有点慢,可能是我的网络原因
docker pull docker.elastic.co/logstash/logstash:7.14.0
3.上传mysql的连接jar包
可以去IDEA里面复制你Maven里面的:
创建文件夹存放
mkdir -p /opt/logstash/jarmkdir -p /opt/logstash/jar

4.运行一下镜像获取配置文件
docker run -d --name=logstash logstash:7.14.0
第一次创建 用于复制文件
5.查看日志
docker logs -f logstash 
6.拷贝数据
docker cp logstash:/usr/share/logstash/config /opt/logstashdocker cp logstash:/usr/share/logstash/data /opt/logstashdocker cp logstash:/usr/share/logstash/pipeline /opt/logstash
7.给文件夹赋权
cd /opt/logstashchmod -R 777 ./config ./data ./pipeline
8.删除容器
docker rm -f logstash
9.重新启动容器
docker run -d \
--name=logstash \
--restart=always \
-p 5044:5044 \
-v /opt/logstash/data:/usr/share/logstash/data \
-v /opt/logstash/jar/mysql-connector-java-8.0.25.jar:/usr/share/logstash/mysql-connector-java-8.0.25.jar \
-v /opt/logstash/config:/usr/share/logstash/config \
-v /opt/logstash/pipeline:/usr/share/logstash/pipeline \
logstash:7.14.0

10.更新配置文件logstash.conf
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/mysql-connector-java-8.0.25.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://数据库IP/quick_pickup"
jdbc_user => "数据库用户名"
jdbc_password => "数据库密码"
statement => "
SELECT
id AS id,
openid AS openid,
quick_user_id AS quickUserId,
name AS name,
sex AS sex,
avatar AS avatar,
phone AS phone,
follow AS follow,
fan AS fan,
wallet AS wallet,
DATE_FORMAT(create_time, '%Y-%m-%d %H:%i:%s') AS createTime,
use_time AS useTime,
collect_number AS collectNumber,
mark_number AS markNumber,
brief_introduction AS briefIntroduction
FROM
user
"
lowercase_column_names => false # 关闭传输字段默认小写的配置
# 开启分页
jdbc_paging_enabled => true
jdbc_page_size => 2000
schedule => "*/5 * * * * * UTC" # 每5秒执行一次
}
}
output {
elasticsearch {
hosts => ["es所在服务器的IP:9200"]
index => "user" # Elasticsearch 索引名称
document_id => "%{id}" # 使用 MySQL 的主键 `id` 作为文档 ID
codec => "json"
}
}11.修改logstash.yml


12.重启容器
docker stop logstashdocker start logstash或者:
docker restart logstash

13.再次打印日志查看
docker logs -f logstash三、提醒
记得打开服务器对应的端口(5044)
四、可能遇到的bug
下面是我之前遇到的问题,最后都解决了,上面配置文件是最新更新后的配置文件
- logstash输出到es的字段都是小写
- 时间字段不是我们希望的格式
https://github.com/logstash-plugins/logstash-filter-date/issues/158![]() https://github.com/logstash-plugins/logstash-filter-date/issues/158
https://github.com/logstash-plugins/logstash-filter-date/issues/158
#logstash输入配置
input {
#jdbc输入配置,用来指定mysql中需要同步的数据查询SQL及同步周期
jdbc {
type => "jdbc"
jdbc_connection_string => "jdbc:mysql://localhost:3306/dh_order?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false"
# 数据库连接账号密码;
jdbc_user => "dh_test"
jdbc_password => "Y2017dh123"
# MySQL依赖包路径;
jdbc_driver_library => "mysql/mysql-connector-java-5.1.49.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 数据库重连尝试次数
connection_retry_attempts => "3"
# 判断数据库连接是否可用,默认false不开启
jdbc_validate_connection => "true"
# 数据库连接可用校验超时时间,默认3600S
jdbc_validation_timeout => "3600"
# 是否开启分页
jdbc_paging_enabled => true
# statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
# statement => "SELECT * FROM `t_car_order` limit 1"
statement => "SELECT id,create_time FROM `t_car_order` limit 1"
# 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false);
# lowercase_column_names => false
# Value can be any of: fatal,error,warn,info,debug,默认info;
# sql_log_level => warn
sql_log_level => debug
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中;
# record_last_run => true
# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值;
# use_column_value => true
# 需要记录的字段,用于增量同步,需是数据库字段
# tracking_column => "ModifyTime"
# Value can be any of: numeric,timestamp,Default value is "numeric"
# tracking_column_type => timestamp
# record_last_run上次数据存放位置;
# last_run_metadata_path => "mysql/last_id.txt"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;
# clean_run => false
# 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务,这里设置为每5分钟同步一次
# schedule => "*/5 * * * * *"
# 用来控制增量更新的字段,一般是自增id或者创建、更新时间,注意这里要采用sql语句中select采用的字段别名
# tracking_column => "unix_ts_in_secs"
# tracking_column 对应字段的类型
# tracking_column_type => "numeric"
}
}
#logstash输入数据的字段匹配和数据过滤
# filter {
# mutate {
# copy => { "id" => "[@metadata][_id]"}
# remove_field => ["id", "@version", "unix_ts_in_secs"]
# }
# }
filter {
# date {
# match => ["update_time", "yyyy-MM-dd HH:mm:ss"]
# target => "update_time"
# }
# date {
# match => ["create_time", "yyyy-MM-dd HH:mm:ss"]
# target => "create_time"
# }
# mutate {
# convert => { "create_time" => "text" } # 将create_time字段转换为字符串类型
# }
# ruby {
# code => 'event.set("create_time", event.get("create_time").strftime("%Y-%m-%d %H:%M:%S"))'
# }
# date {
# match => ["create_time", "yyyy-MM-dd HH:mm:ss"]
# target => "create_time"
# timezone => "Asia/Shanghai" # 你的时区
# }
mutate {
add_field => { "index_date" => "%{create_time}" }
}
# mutate {
# rename => { "create_time_string" => "index_date" }
# }
# date {
# # match => ["index_date", "ISO8601"]
# match => ["index_date", "ISO8601"]
# # target => "index_date"
# }
# }
date {
match => ["index_date", "yyyy-MM-dd HH:mm:ss"]
# target => "index_date"
# target => "index_date"
}
# mutate {
# add_field => {
# "index_date1" => "%{index_date}"
# }
}
#logstash输出配置
output {
# 采用stdout可以将同步数据输出到控制台,主要是调试阶段使用
# stdout { codec => json_lines}
stdout { codec => rubydebug}
# 指定输出到ES的具体索引
# elasticsearch {
# index => "rdbms_sync_idx"
# document_id => "%{[@metadata][_id]}"
# }
elasticsearch {
# host => "192.168.1.1"
# port => "9200"
# 配置ES集群地址
# hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"]
hosts => ["localhost:9200"]
# 索引名字,必须小写
# index => "t_car_order-%{+YYYY.MM.dd}"
index => "t_car_order_%{index_date}"
# index => "t_car_order_@timestamp"
# index => "t_car_order3"
# 数据唯一索引(建议使用数据库KeyID)
# document_id => "%{KeyId}"
document_id => "%{id}"
# document_id => "ID"
}
}关于字段大小写问题还可以参考这几篇博客:
Elasticsearch-logstash同步mysql数据 字母大小写问题_es 字段小写-CSDN博客文章浏览阅读2.5k次。logstash同步mysql数据的时候,sql里面含有的大写字母,到了ES的时候就会变成小写,这是因为在jdbc.conf里面没有添加lowercase_column_names => false"这个属性,就导致es里面看到的字段名称全是小写。最后总结:es是支持大写字段名称的,如果想要保留原有的大写字母,需要在同步配置中加上lowercase_column_names ..._es 字段小写https://blog.csdn.net/qinyuezhan/article/details/89215215
Logstash将字段名全部转换为小写 - 腾讯云开发者社区 - 腾讯云Logstash是一个开源的数据收集引擎,用于将不同来源的数据进行收集、转换和传输。它是Elastic Stack(Elasticsearch、Logstash、Kibana)中的一部分,用于处理和分......![]() https://cloud.tencent.com/developer/information/Logstash%E5%B0%86%E5%AD%97%E6%AE%B5%E5%90%8D%E5%85%A8%E9%83%A8%E8%BD%AC%E6%8D%A2%E4%B8%BA%E5%B0%8F%E5%86%99-salon
https://cloud.tencent.com/developer/information/Logstash%E5%B0%86%E5%AD%97%E6%AE%B5%E5%90%8D%E5%85%A8%E9%83%A8%E8%BD%AC%E6%8D%A2%E4%B8%BA%E5%B0%8F%E5%86%99-salon
五、至此ELK搭建结束
欢迎大家在评论区谈一下自己遇到的问题和看法,互相学习。