前言
毫无疑问的是,关于人工智能方向,python真的十分方便和有效。
这里呢,我将介绍python众多OCR模块中一个比较出色的模块:cnocr
模块介绍
cnocr是一个基于PyTorch的开源OCR库,它提供了一系列功能强大的中文OCR模型和工具,可以用于图像中的文字检测、文字识别和文本方向检测等任务。它可以识别各种不同风格和字体的中文文字,包括简体字和繁体字,可根据具体需求在官方文档中查找对应的模型作为参数输入实例化cnocr方法。官方也提供有英文的识别模型,但其他语言就暂时没有更多的模型,但可以根据自己的需要和自己准备的数据集对模型进行训练。
项目地址:https://github.com/breezedeus/CnOCR
demo实例
cnocr的开发目标就是“使用简单”,因此,你仅仅需要一些简单的操作便能够完成ocr工作。
安装基本上无坑,pip直接就装上了
pip install cnocr这里是一个简单的例子:

这是项目目录,sample.py是demo脚本,images里装着需要识别的图片,outs是处理后的图片:

这是sample.py的代码
from cnocr import CnOcr
import cv2
from PIL import Image, ImageDraw, ImageFont
FONT_STYLE = ImageFont.truetype("msyhl.ttc", 30, encoding="utf-8")
# 图片名称
file_name = 'images/img.png'
target_name = 'outs/img.png'
ocr = CnOcr()
result = ocr.ocr(file_name)
# 将ocr识别的内容、以及具体位置打包成字典
txts = []
for re in result:
# print(re['position'][0])
# print(type(re['position'][0]))
txts.append([re['text'], [re['position'][2], re['position'][0]]])
# 创建一个可以在给定图像上绘图的frame对象
frame = cv2.imread(file_name)
for tt in txts:
# text是识别出来的文字
text = tt[0]
# site是他的矩形识别图形的起点、终点列表
# 样式为[[起始点x轴坐标, 起始点y轴坐标], [终点x轴坐标, 终点y轴坐标]]
site = tt[1]
print(text, site)
cv2.rectangle(frame, (site[0][0], site[0][1]), (site[1][0], site[1][1]), color=(0, 255, 0), thickness=3)
# 请根据实际情况在原图上标字,这里是默认将字体标在了识别框下方100的位置,因此仅作参考
# img = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
# draw = ImageDraw.Draw(img)
# draw.text((site[1][0], site[1][1] + 100), text, (0, 255, 0),
# font=FONT_STYLE)
# frame = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
cv2.imwrite(target_name, frame)
这是生成的图片

这是识别到的内容
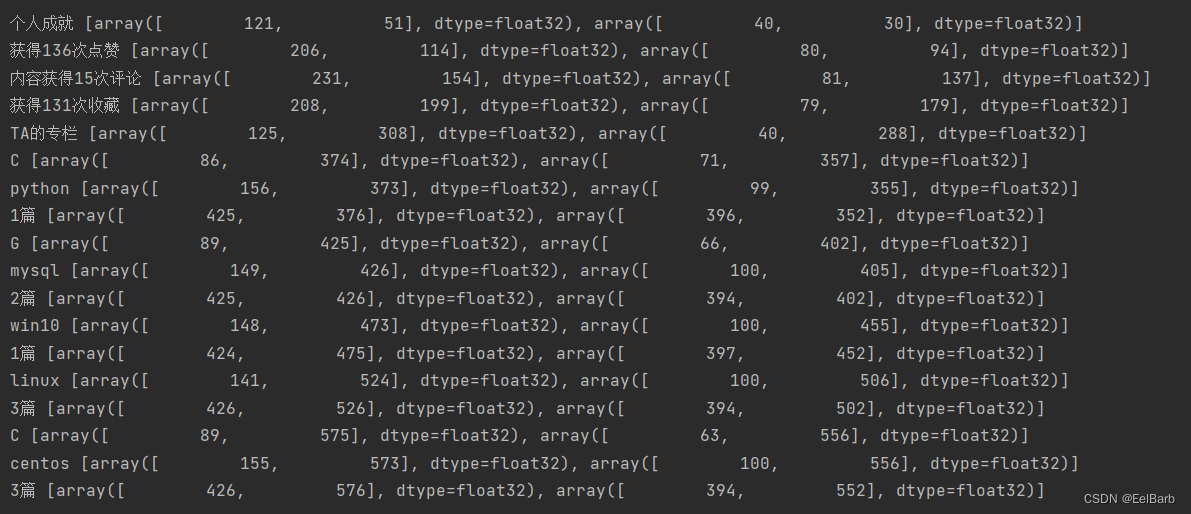
至此,一次简单的ocr便完成了