目录
一、SpringCloudAlibaba 源码分析
1.1、SpringCloud & SpringCloudAlibaba 常用组件
1.2、Nacos的服务注册表结构是怎样的?
1.2.1、Nacos的分级存储模型(理论层)
1.2.2、Nacos 源码启动(准备工作)
1.2.3、运行 Nacos
1.2.4、Nacos的分级存储模型(源码层)
1.3、Nacos如何支撑数十万服务注册压力?
1.4、Nacos如何解决实例列表并发读写冲突问题
1.4.1、并发读写冲突
1.4.2、并发写冲突
一、SpringCloudAlibaba 源码分析
1.1、SpringCloud & SpringCloudAlibaba 常用组件
我们脑海中因该出现一幅图:
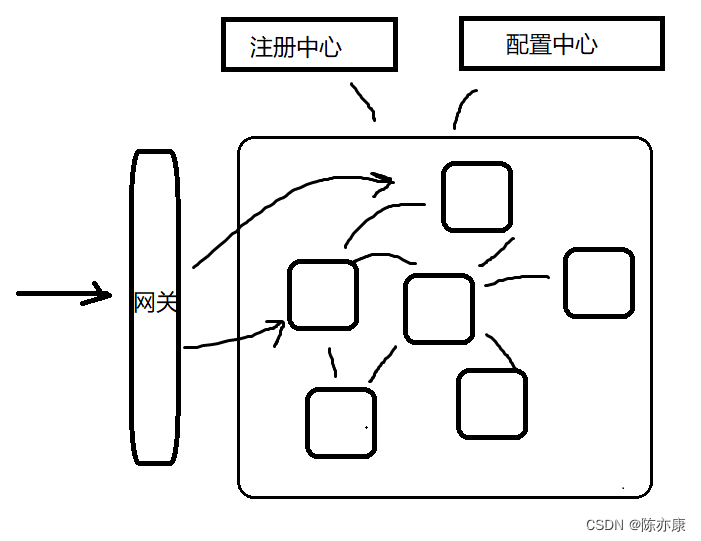
- 首先,我们肯定有无数个小的微服务.
- 这无数个微服务之间是不是要进行一个相互调用,那么就会用到 OpenFeign 这样的组件.
- 这么多服务要相互调用,怎么去管理呢,这就需要用到 nacos 组件去做注册中心,那么所有的服务就会去找注册中心去注册自己的服务.
- 那么我拉取到的服务可能是一个列表,那么将来在远程调用的时候就需要做负载均衡,就需要使用 LoadBalancer 这个组件.
- 这么多服务将来要做统一配置的管理怎么办,就需要引入 nacos 作为配置中心.
- 这时候微服务集群就形成了,将来对外提供服务,是不是随便什么人都能访问呢?显然不行,所有在微服务群前面就需要有 gateway 网关 作为入口.
- 那么就算你可以访问了,万一流量激增,引起微服务雪崩,给我整个服务搞崩了,肯定不行,因此就需要 sentinel 来做限流、熔断降级保护.
- 还有一个问题,在分布式系统下,就会引发分布式事务问题,如何解决呢,这就需要 Seata 上场了.
实际上,微服务的组件远不止于此,还有很多的组件,但是以上呢,就是我们最常用的几个组件啦~
1.2、Nacos的服务注册表结构是怎样的?
Tips:要了解Nacos的服务注册表结构,需要从以下两方面入手
1. Nacos的分级存储模型 2.Nacos的服务端源码分析
1.2.1、Nacos的分级存储模型(理论层)

a)Nacos 分级模型中最外层就是 namespace,起到一个环境隔离的作用,比如我们开发的时候会去区分开发环境、测试环境、生产环境...等等.
b)现在环境隔离好了,比如开发环境下,我们肯定是有很多很多的服务,这时候我们就可以业务模块进行分组,比如交易模块(分一个组),里面就会有像 订单、支付有关的微服务. (像阿里这种服成千上万个服务,进行分组管理就会很方便,但是小型企业的就没必要了,一般就使用默认组即可).
c)那么分组下面就到了一个个微服务了,而服务只是一个概念,提供了这样一个功能,将来为了保证服务的一个高可用,肯定就需要把每个服务部署成集群,而且部署的时候不能只是简单的说就整两太那么简单,肯定要部署到全国各地不同的机房,保证了异地容灾,不至于一个机房毁了,整个服务崩溃.
d)集群的下面就是才是我们具体的实例,可想而知,一个集群下肯定也是有多个实例的.
问题来了:这么一个分级存储的模型怎么用 java 代码来实现的呢?如果让你来实现,会用什么呢?我们是不是可以用 map 的 key value 结构去存储,接下来我们就来看看具体的源码怎么实现~
1.2.2、Nacos 源码启动(准备工作)
a)想要进行到 Nacos 源码层面进行分析,首先需要我们去官网下载好 Nacos 源码:https://github.com/alibaba/nacos
这里以 1.4.2 的 Nacos 版本为例
b)将 nacos 源码导入到工程当中,将其修改为模块




c)Nacos底层的数据通信会基于 protobuf 对数据做序列化和反序列化。并将对应的 proto 文件定义在了consistency这个子模块中:

d)安装 protoc:https://github.com/protocolbuffers/protobuf/releases
配置环境变量.
e)进入 nacos-1.4.2 的 consistency 模块下的src/main目录下,输入以下两个命令进行编译,生成对应的 Java 文件.
protoc --java_out=./java ./proto/consistency.proto
protoc --java_out=./java ./proto/Data.proto
entity 下就可以看到生成了如下代码:

1.2.3、运行 Nacos
a)添加 Nacos 的 SpringBoot 服务,指定启动模式为单机

b)运行的时候如果提到 Java 发行版本的问题,记得去改一下 JDK 版本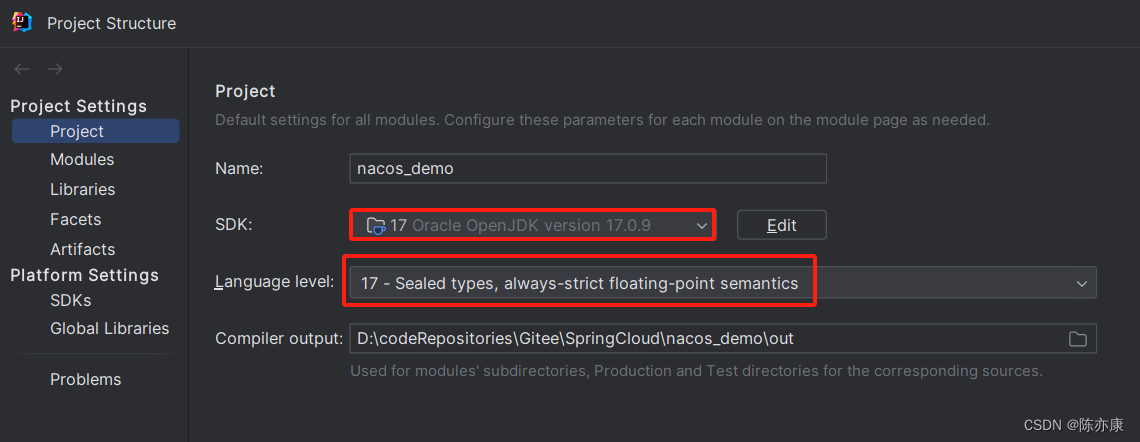

1.2.4、Nacos的分级存储模型(源码层)
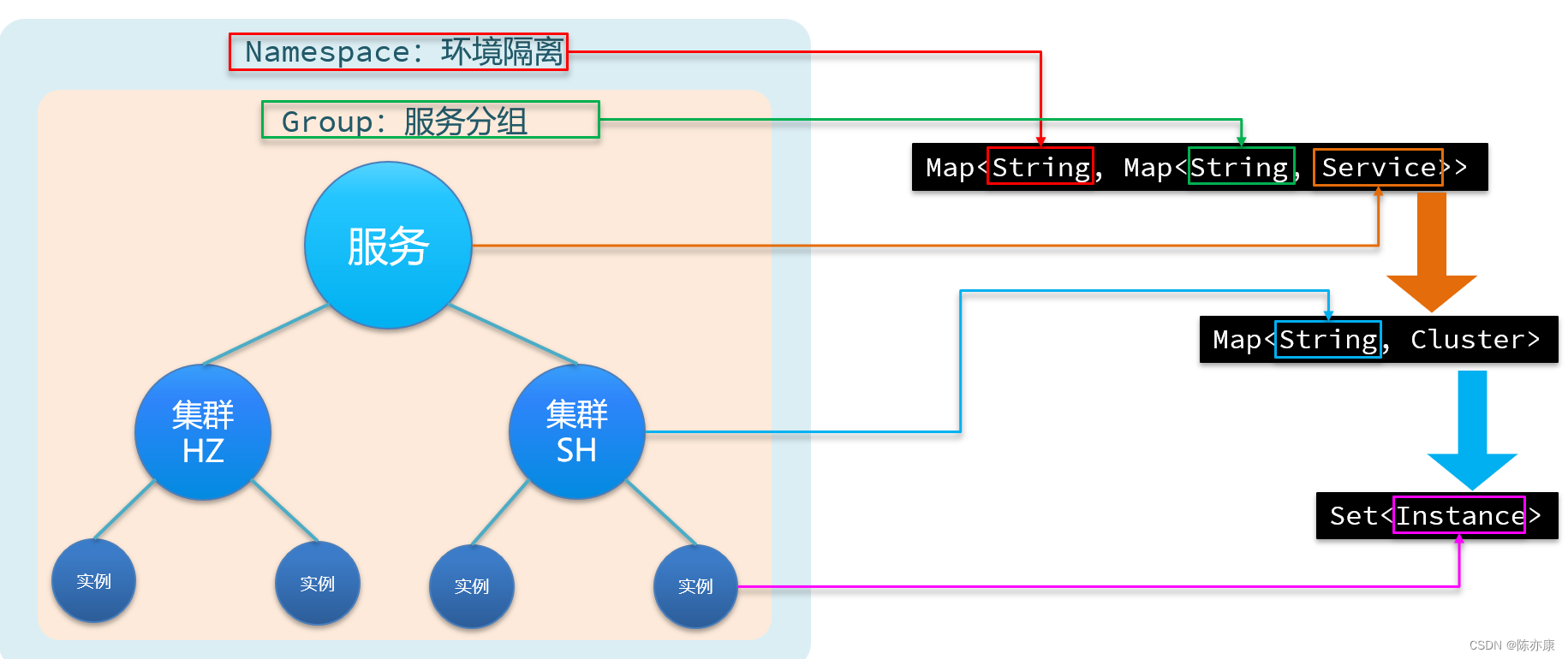
a)Nacos 的分级存储模型对应到源码中,实际上就是一个多层嵌套 Map,key 就是 String 类型的 namespace,而他的 value 又是一个 Map.
b)这个第二层的 Map 就表示 group 和 服务了,key 就服务名称,而 value 就是一个服务 service.
c)服务实际上就是一个类,由于一个服务往往是有多个集群的,因此在 service 类中又维护了一个 map,key 就是集群名称(例如,上海、广州、杭州...).
d)他的值 cluster 集群也是一个类,这个类里面就维护了两个 Set 集合,一个是临时实例,另一个就是非临时实例.
1.3、Nacos如何支撑数十万服务注册压力?
a)首先 nacos 肯定是要做成一个集群的,那么就可以对服务注册请求左负载均衡,会大大减轻压力.
b)其次,nacos 内部接收到服务注册请求时,不会立即更新到注册表中,而是将服务注册的任务放到了一个阻塞队列中,然后就响应给客户端了,但是实际上在这个注册的动作还是没有完成的,而是后续开启一个线程池,写了一个死循环,获取阻塞队列中的队头元素(如果存在就获取,不存在就阻塞等待,直到阻塞队列中有新元素为止). 因此这个更新动作实际上是异步实现的.
如下源码:
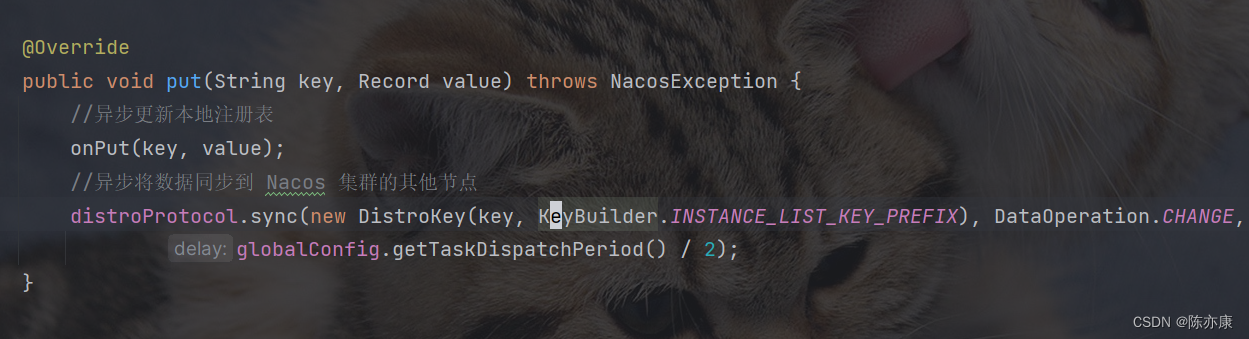
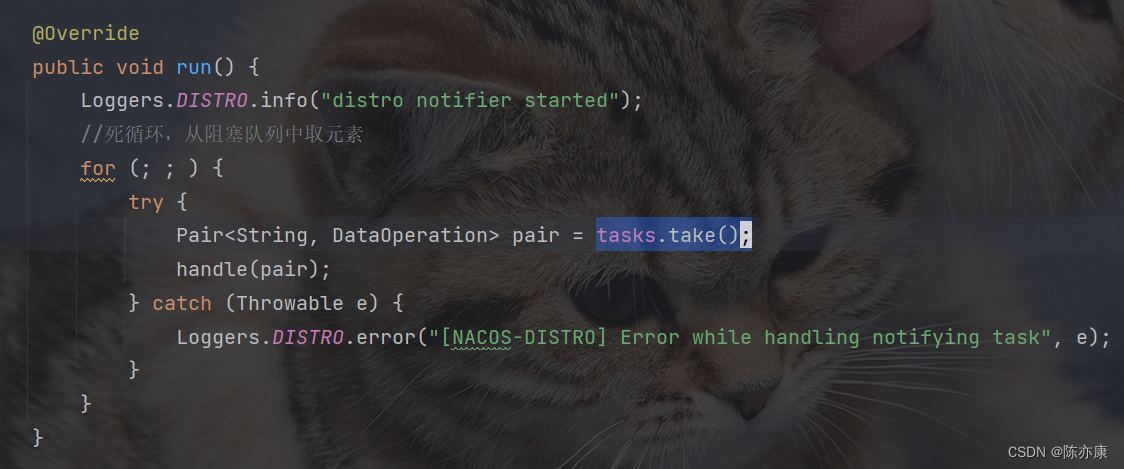
c)无论是更新本地列表,还是集群的一致性操作,都是通过异步执行的. 当然这些都是临时实例啊,非临时实例的话就不一样了,因为要保证强一致性,因此他的性能就难以保障了,所以在默认请情况下,所有实例都是临时的,性能会更好一点.
1.4、Nacos如何解决实例列表并发读写冲突问题
1.4.1、并发读写冲突
a)首先,Nacos 的实例列表,实际上也就是 Map,这个集合里面装的就是旧的列表,现在要对这个旧的列表做修改,那一边写一边读可能会造成脏读的问题.
b)因此,处理这种问题,我们最直接的可能就是想到使用加锁来处理,但是加锁的开销也不小,涉及到用户态到内核态的转换... 那么 Nacos 这里采取的是 CopyOnWrite 技术,也就是说,他不是直接来改这个集合中的数据,而是先把这个集合中的数据拷贝了一份,放到一个全新的集合中,然后再在这个全新的集合中进行更新修改操作,改完了之后再直接覆盖掉旧数据.
c)而这个过程中读取的是旧的实例列表,因此不会受到任何影响.
如下源码:
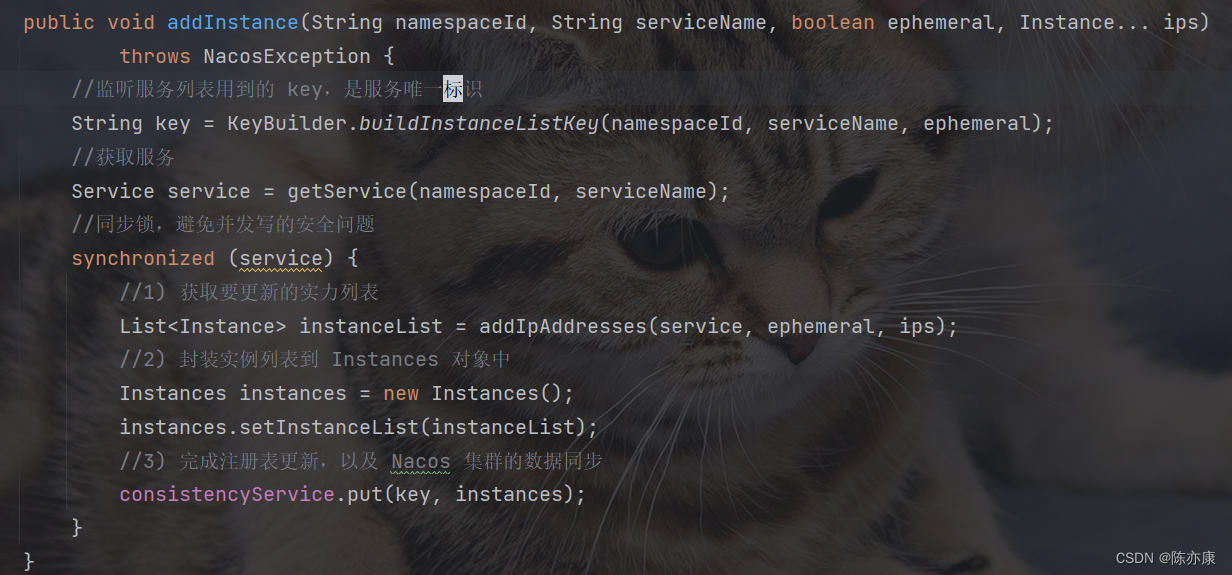
public List<Instance> updateIpAddresses(Service service, String action, boolean ephemeral, Instance... ips)
throws NacosException {
// 根据namespaceId、serviceName获取当前服务的实例列表,返回值是Datum
// 第一次来,肯定是null
Datum datum = consistencyService
.get(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), ephemeral));
// 得到服务中现有的实例列表
List<Instance> currentIPs = service.allIPs(ephemeral);
// 创建map,保存实例列表,key为ip地址,value是Instance对象
Map<String, Instance> currentInstances = new HashMap<>(currentIPs.size());
// 创建Set集合,保存实例的instanceId
Set<String> currentInstanceIds = Sets.newHashSet();
// 遍历要现有的实例列表
for (Instance instance : currentIPs) {
// 添加到map中
currentInstances.put(instance.toIpAddr(), instance);
// 添加instanceId到set中
currentInstanceIds.add(instance.getInstanceId());
}
// 创建map,用来保存更新后的实例列表
Map<String, Instance> instanceMap;
if (datum != null && null != datum.value) {
// 如果服务中已经有旧的数据,则先保存旧的实例列表
instanceMap = setValid(((Instances) datum.value).getInstanceList(), currentInstances);
} else {
// 如果没有旧数据,则直接创建新的map
instanceMap = new HashMap<>(ips.length);
}
// 遍历实例列表
for (Instance instance : ips) {
// 判断服务中是否包含要注册的实例的cluster信息
if (!service.getClusterMap().containsKey(instance.getClusterName())) {
// 如果不包含,创建新的cluster
Cluster cluster = new Cluster(instance.getClusterName(), service);
cluster.init();
// 将集群放入service的注册表
service.getClusterMap().put(instance.getClusterName(), cluster);
Loggers.SRV_LOG
.warn("cluster: {} not found, ip: {}, will create new cluster with default configuration.",
instance.getClusterName(), instance.toJson());
}
// 删除实例 or 新增实例 ?
if (UtilsAndCommons.UPDATE_INSTANCE_ACTION_REMOVE.equals(action)) {
instanceMap.remove(instance.getDatumKey());
} else {
// 新增实例,instance生成全新的instanceId
Instance oldInstance = instanceMap.get(instance.getDatumKey());
if (oldInstance != null) {
instance.setInstanceId(oldInstance.getInstanceId());
} else {
instance.setInstanceId(instance.generateInstanceId(currentInstanceIds));
}
// 放入instance列表
instanceMap.put(instance.getDatumKey(), instance);
}
}
if (instanceMap.size() <= 0 && UtilsAndCommons.UPDATE_INSTANCE_ACTION_ADD.equals(action)) {
throw new IllegalArgumentException(
"ip list can not be empty, service: " + service.getName() + ", ip list: " + JacksonUtils
.toJson(instanceMap.values()));
}
// 将instanceMap中的所有实例转为List返回
return new ArrayList<>(instanceMap.values());
}1.4.2、并发写冲突
a)对于并发写冲突,也就是说同时有多个线程来拷贝我们的实例,即使通过 CopyOnWrite 技术,你拷贝一份,我也拷贝一份,然后大家都各写各的,最后都去覆盖同一个旧的列表,这个时候还是会出现写冲突的问题.
b)因此,这里代码中的处理实际上就是直接给服务加锁,因此访问同一个服务的多个实例就只能串行执行了.
如下源码: