表设计主要强调什么场合该选择什么技术,没有最高级的技术,只有最适合的技术。

1.表的特性
普通堆表的不足之处
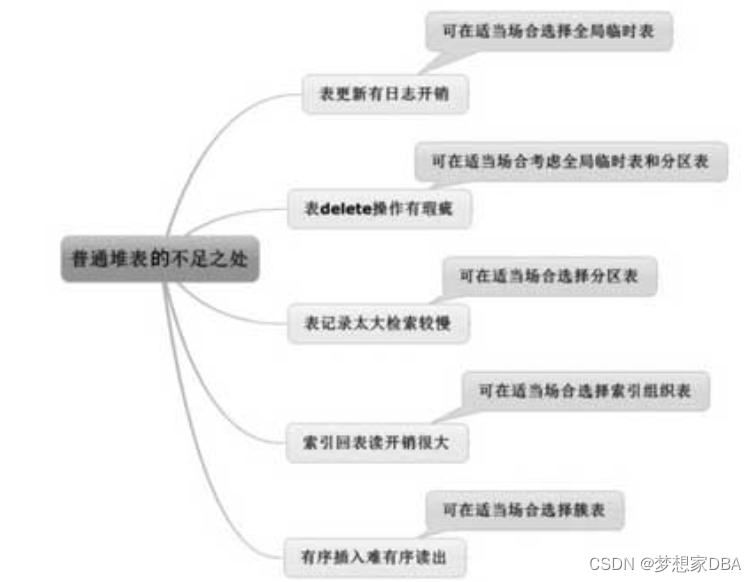
1.查看产生多少日志
[oracle@oracle-db-19c ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Wed Jan 4 14:27:13 2023
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
SQL> alter session set container=PDB1;
Session altered.
SQL> select a.name,b.value
2 from v$statname a,v$mystat b
3 where a.statistic#=b.statistic#
4 and a.name='redo size';
NAME
--------------------------------------------------------------------------------
VALUE
----------
redo size
0
SQL>[oracle@MaxwellDBA ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Wed Jan 4 15:25:31 2023
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
sys@cdb$root:orclcdb> alter session set container=ORCLPDB1;
Session altered.
sys@cdb$root:orclcdb> select a.name,b.value
2 from v$statname a,v$mystat b
3 where a.statistic#=b.statistic#
4 and a.name='redo size';
NAME VALUE
---------------------------------------------------------------- ----------
redo size 0
1 row selected.
sys@cdb$root:orclcdb>
实验准备工作,创建观察redo的视图
[oracle@MaxwellDBA ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Wed Jan 4 15:25:31 2023
Version 19.3.0.0.0
Copyright (c) 1982, 2019, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
sys@cdb$root:orclcdb> alter session set container=ORCLPDB1;
Session altered.
sys@cdb$root:orclcdb> select a.name,b.value
2 from v$statname a,v$mystat b
3 where a.statistic#=b.statistic#
4 and a.name='redo size';
NAME VALUE
---------------------------------------------------------------- ----------
redo size 0
1 row selected.
sys@cdb$root:orclcdb>
观察删除记录产生了多少redo
SQL> select * from v_redo_size;
NAME
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
VALUE
----------
redo size
11871068
SQL> delete from t;
73262 rows deleted.
SQL> select * from v_redo_size;
NAME
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
VALUE
----------
redo size
22920220
SQL> select 22920220 - 11871068 from dual;
22920220-11871068
-----------------
11049152
SQL> 删除语句产生了差不多11M的日志量
观察插入记录产生了多少redo
SQL>
SQL> insert into t select * from dba_objects;
73264 rows created.
SQL> select * from v_redo_size;
NAME
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
VALUE
----------
redo size
34265784
SQL> select 34265784 - 22920220 from dual;
34265784-22920220
-----------------
11345564
SQL> 观察更新记录产生了多少redo
SQL>
SQL> update t set object_id=rownum;
73264 rows updated.
SQL> select * from v_redo_size;
NAME
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
VALUE
----------
redo size
47178732
SQL> select 47178732 - 34265784 from dual;
47178732-34265784
-----------------
12912948
SQL> 更新语句产生了差不多12M的redo
三个试验说明了对表的更新操作,无论是删除、插入还是修改,都会产生日志.
虽说安全第一,不过在某些特定的场合,某些表的记录只是作为中间结果临时运算而根本无须永久保留,这些表无须写日志,那就既高效又安全了!
delete无法释放空间
实际上工作中不少性能问题都和delete操作有关。
原因是:delete是最耗性能的操作,产生的undo最多,而且因为undo需要redo来保护的缘故,delete产生的redo量也最大。所以不少性能问题都和delete操作有关。
观察未删除表时产生的逻辑读
SQL> show user;
USER is "MAXWELLPAN"
SQL> drop table t purge;
Table dropped.
SQL>
SQL> create table t as select * from dba_objects;
Table created.
SQL> set autotrace on
SQL> select count(*) from t;
COUNT(*)
----------
73263
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 397 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| T | 73263 | 397 (1)| 00:00:01 |
-------------------------------------------------------------------
Statistics
----------------------------------------------------------
75 recursive calls
0 db block gets
1546 consistent gets
1422 physical reads
0 redo size
552 bytes sent via SQL*Net to client
384 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
20 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>用delete命令删除t所有记录后,逻辑读发生了微小的变化
SQL>
SQL> set autotrace off
SQL> delete from t;
73263 rows deleted.
SQL> commit;
Commit complete.
SQL> set autotrace on
SQL> select count(*) from t;
COUNT(*)
----------
0
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 397 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| T | 73263 | 397 (1)| 00:00:01 |
-------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
1426 consistent gets
0 physical reads
0 redo size
549 bytes sent via SQL*Net to client
384 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> 使用truncate命令清空表后,逻辑读终于大幅度下降了。
SQL>
SQL> set autotrace off
SQL> truncate table t;
Table truncated.
SQL> set autotrace on
SQL> select count(*) from t;
COUNT(*)
----------
0
Execution Plan
----------------------------------------------------------
Plan hash value: 2966233522
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 397 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| T | 73263 | 397 (1)| 00:00:01 |
-------------------------------------------------------------------
Statistics
----------------------------------------------------------
1 recursive calls
1 db block gets
3 consistent gets
0 physical reads
104 redo size
549 bytes sent via SQL*Net to client
384 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL>delete 删除并不能释放空间,虽然delete将很多块的记录删除了,但是空块依然保留,Oracle在查询时依然会去查询这些空块。而truncate是一种释放高水平位的动作,这些空块被回收,空间也被释放了。
不过truncate显然不能替代delete,因为truncate是一种DDL操作而非DML操作,truncate后面是不能带条件的,即truncate table t where…是不允许的。但是如果表中这些where条件能形成有效的分区,Oracle是支持在分区表中做truncate分区的,命令大致为 alter table t truncate partition '分区名',如果where 条件就是分区条件,那等同于换个角度实现了 truncate table t where…的功能。
这就是分区表最实用的功能之一了,高效地清理数据,释放空间,老师将在后续章节中详细描述分区表的特性。
表记录太多检索较慢
有没有什么好方法能提升检索的速度呢?主要思路就是缩短访问路径来完成同样的更新查询操作。简单地说,完成同样的需求,访问块的个数越少越好。Oracle 为了尽可能减少访问路径提供了两种主要技术,一种是索引技术,另一种则是分区技术。
索引本身也是一把双刃剑,既能给数据库开发应用带来极大的帮助,也会给数据库带来不小的灾难。
分区表,除了之前描述的具有高效清理数据的功能外,还有减少访问路径的神奇本领。
索引回表读开销很大
观察TABLE ACCESS BY INDEX ROWID 产生的开销
SQL>
SQL> show user;
USER is "MAXWELLPAN"
SQL> drop table t purge;
Table dropped.
SQL> create table t as select * from dba_objects where rownum<=200;
Table created.
SQL> create index idx_obj_id on t(object_id);
Index created.
SQL> set linesize 1000
SQL> set autotrace traceonly
SQL> select * from t where object_id<=10;
9 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3784017797
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9 | 927 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T | 9 | 927 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_OBJ_ID | 9 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"<=10)
Statistics
----------------------------------------------------------
51 recursive calls
126 db block gets
54 consistent gets
3 physical reads
25504 redo size
3584 bytes sent via SQL*Net to client
397 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
9 rows processed
SQL>
![[Android]序列化原理Serializable](https://img-blog.csdnimg.cn/c096e680339c41f48b76798685da4b9b.png)