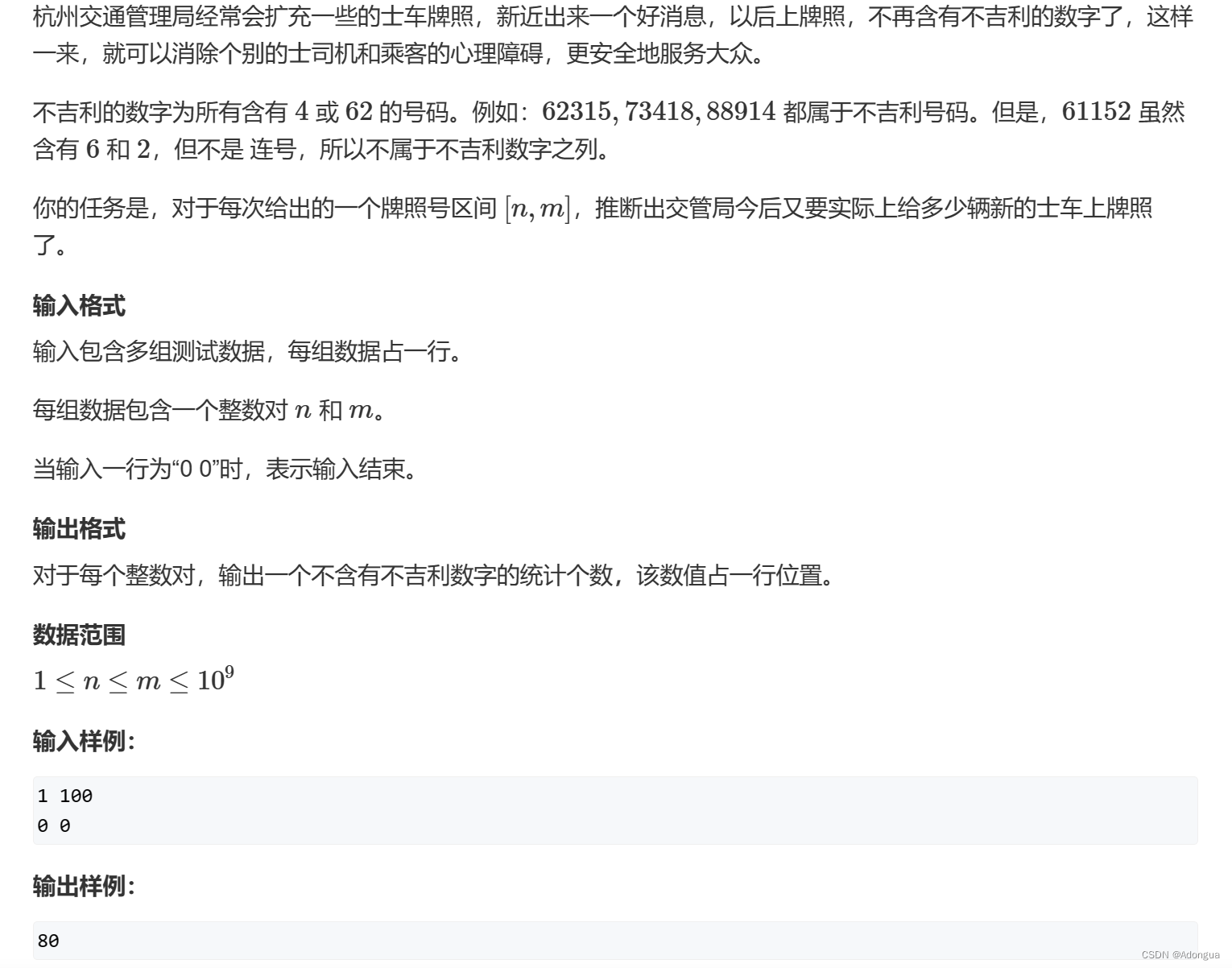
TIPS
1. 函数递归必须存在限制条件。
2. 一维数组与二维数组在内存当中是连续存放的,二维数组的话反正也是一行一行往下走。如果能知道起始地址的话,后面顺藤摸瓜会很容易。
3. 数组越界的话,C语言本身是不做检查的。数组传参传的是数组首元素的地址(地址,指针,内存编号三者概念完全等价),并不是把整个数组都传过去。因此如果想要知道数组元素数的话,必须要在外面用sizeof(arr)/sizeof(arr[0])算好,这个公式的话是不能在函数内部去算的。当然,计算字符数组的话也可以用strlen()
4. 指针变量的类型主要有两个意义。第一个意义在于决定了当对指针进行解引用操作的时候,势力范围是多少;还有一个意义在于决定了指针±整数的时候的步长大小
5. 符号位也要参与运算的,你以为你是符号位就这么表示着正负颐享天年了?做梦
6. 如果两个符号位都是1,不用慌,不用去忧虑什么符号位因为都是统一起来了的,该进位进位,该截断丢掉就截断丢掉
7. 内存里面的一切运算与存储都是补码,当然在屏幕上让你看到的还是要再转为原码,打印出原码对应的数值
8. 正数的原码反码补码一样
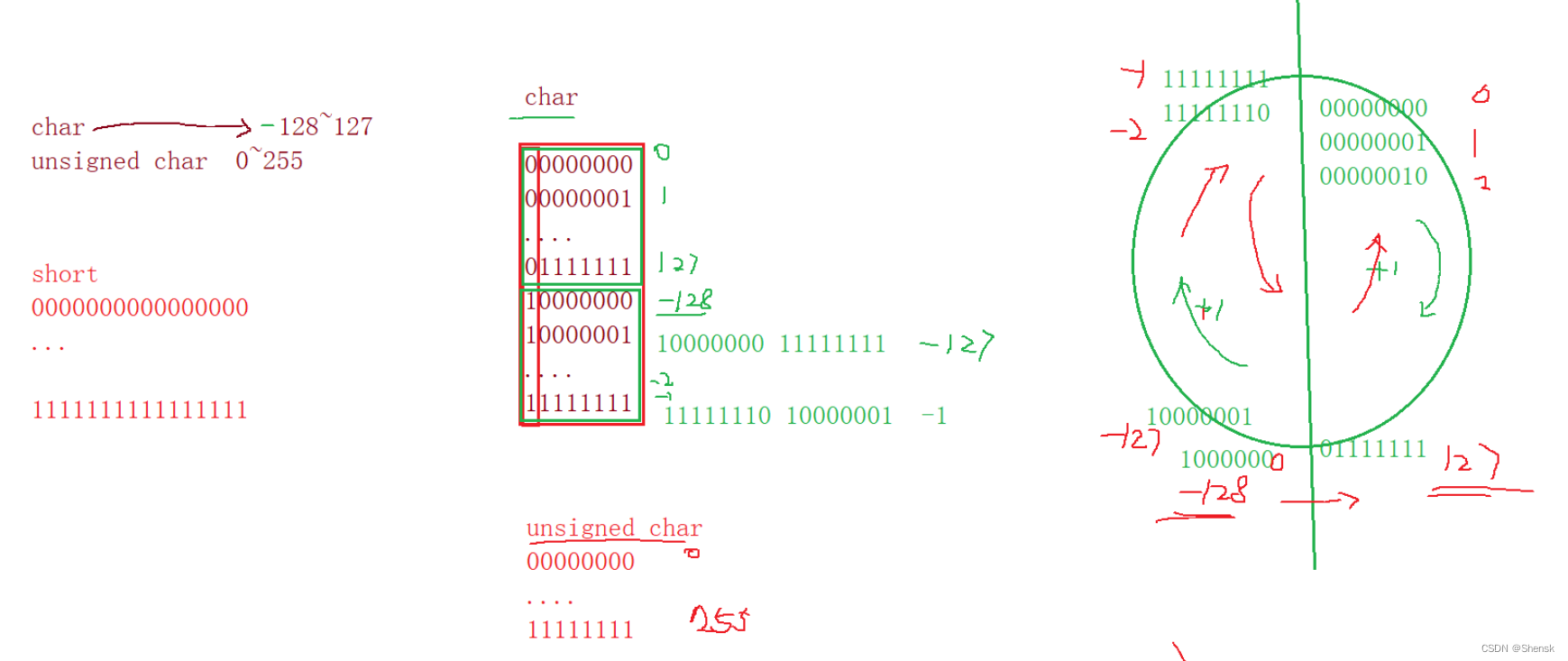
9. char类型的世界里只有-128~127,不可能超出这个范围,你放一个再大的值,也会因为发生截断而回归到这个范围里面(详见下文)
10. 把一个数据放到内存里面的时候,计算机是不知道到底是有没有符号的,是用的人去决定,我用%d,这就说明我认为它是有符号的;我用%u则反之。
11. 一切都是内存单元/一个字节,一切都是二进制,什么字符啊,各种其他乱七八糟的具像东西,计算机才不认识,计算机就认识二进制。
12. 数据类型不是说告诉你这里面到底该放什么东西?而是说我开辟了多少内存空间,至于里面放什么你管我,比如char类型,只说明我开辟了1个字节内存空间,至于里面才不字符呢,我放数字又咋了,而事实上,也只能放数字
13. 整型提升的规则就是:如果当前要提升数的是有符号的,那么就高位补符号位,如果是没有符号的,高位补0。(注意:这个看有没有符号,只看当前要提升的数是不是有符号的,千万千万不要被%u干扰,这个是整型提升完成之后,对结果再一次发生解读的变化),整型提升只有发生在整型运算时,比如单单看char的值用不着整型提升。
14. 
数据类型(整型,浮点数,构造类型,指针类型,空类型)
C语言中的内置数据类型我们之前也已经讲过,无非就是那么几种类型。那么问题就来了,为什么需要那么多数据类型呢?
数据类型的作用
1. 数据类型决定申请开辟的内存空间大小(字节)
2. 数据类型决定看待内存的视角(我认为内存里面放的是什么?继而影响我的解读方式)
整型家族

1. 那为什么字符类型char也会被归到整型家族里面去呢?因为字符在存储的时候存储的是ASCII码值,而ASCII码值是整数,所以在归类的时候,字符属于整型家族没有问题。而char又分为unsigned char与signed char,整型家族的每个数据类型都可以是有符号的或者无符号的。
2. 这边得稍微注意一下:比如说我写int num; / long num; 等,这些都是默认有符号的。而char的话如果你写char str; 这个char到底是默认有符号的还是无符号的这个是取决编译器的,在常见的编译器下,也默认有符号的。
浮点数家族

构造类型(自定义类型)

1. 这个构造类型其实就是自定义类型
2. 数组类型也属于自定义类型,还有结构体类型struct,还有枚举类型enum,还有联合类型union。其实这些都是我们自己去创造出一个类型,比如说我定义“学生”这样一个类型。
3. 那数组类型为啥是自定义类型呢?比如说int arr[10],我这个数组arr它的类型实际上是int [10];如果我定义int arr[11],数组arr它的类型就是int [11],随着元素个数与元素类型的变化,数组的类型也在发生着变化。
指针类型

空类型

整型数据类型在内存中的存储
1. 数据类型的作用:数据类型决定申请开辟的内存空间大小(字节),决定看待内存的视角(我认为内存里面放的是什么?继而影响我的解读方式)
二进制原码,反码,补码(只对于整型而言,浮点数没有这个的)
1. 计算机中的整数有三种二进制的表示方法:原码,反码,补码。这三种表示方法均有符号位,数值位两部分(都是有的,缺一不可能)。符号位都是用0表示正,用1表示负。


2. 对于正数而言,原码,反码,补码都是一模一样,没有任何区别很是省心;负数的话,三种表示方法各不相同,需要通过计算得到。
3. 有一点需要注意:电脑内存当储存的是二进制补码这个不假,但是在VS内存窗口上展示的时候,是用十六进制展示的(四个二进制位为一个十六进制位)。
4. 对于负数而言,它的原反补到底是怎么算的呢?首先的话还是得写出原码:
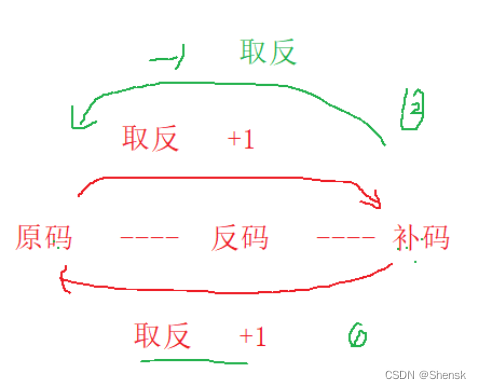
5. 我们已经知道,对于整形来说:数据存放内存中其实是在内存里面存放补码(正数的原反补一样,而负数的话需要通过计算),那么为什么存放的是补码呢?在计算机系统中,数据一律用补码来表示与存储,原因是:
1. 使用补码,可以将符号位与数值域统一处理,也就是说我在进行计算的时候很省心,压根就不用去注意你的最高位是符号位还是数据位,直接统一处理无所谓,该怎么来就怎么来。
2. 同时,加法和减法也可以统一处理(CPU只有加法器)
3. 对于负数,补码原码互相转换,运算过程是一模一样的,不需要使用额外的硬件电路。
啥意思呢?举个例子:

unsigned 修饰 / %d / %u
1. unsigned 修饰的时候内存里面的二进制补码不会发生任何变化,但计算机对它的解读会发生变化。变化在于:高位不是符号位了,而是老老实实乘以权重的数据位了,这时候如果要整型提升的时候,高位就补0
2. %d是打印 有符号 的 整数,它认为在内存里面存放的是一个有符号的整数,打印的时候,如果那个数据没有达到整型int的长度(4字节),就会发生整型提升,(顺便提一下:内存里面放的是补码,然后打印在屏幕上的话,需要先把它转化成原码,打印出原码所对应的数字,而且是先整型提升再转换为原码打印)
3. %u是打印无符号的整数,如果有整型提升的话,区别就在于对整型提升完了之后的32位二进制补码的解读
注意:%d与%u打印时如果涉及到整型提升:
先根据原先的类型(有无符号)整型提升
再根据d/u解读整型提升后的结果,转换原码,打印原码的值
整型数据类型在内存的存储注意
1. 数据类型
数据类型决定申请开辟的内存空间大小(字节),数据长度超出就截断
决定看待内存的视角即:影响我的解读方式
2. 原/反/补
补码符号位既表示±,也参与加减等运算
内存里存放,运算 -> 补码 注:十进制数运算与二进制补码运算吻合
求值,打印 -> 转回原码
3. unsigned 修饰/%d/%u
%d与%u打印先根据原先的类型(有无符号)整型提升
4. 截断/加减进退位超长丢弃
代码里面出现的整数 -> 32位的二进制补码
5. 整型提升
限于整型运算与打印时,如:算char的值时就不需要整型提升,直接按8位二进制算
练习
1. 
答案:1 1 255
解析:
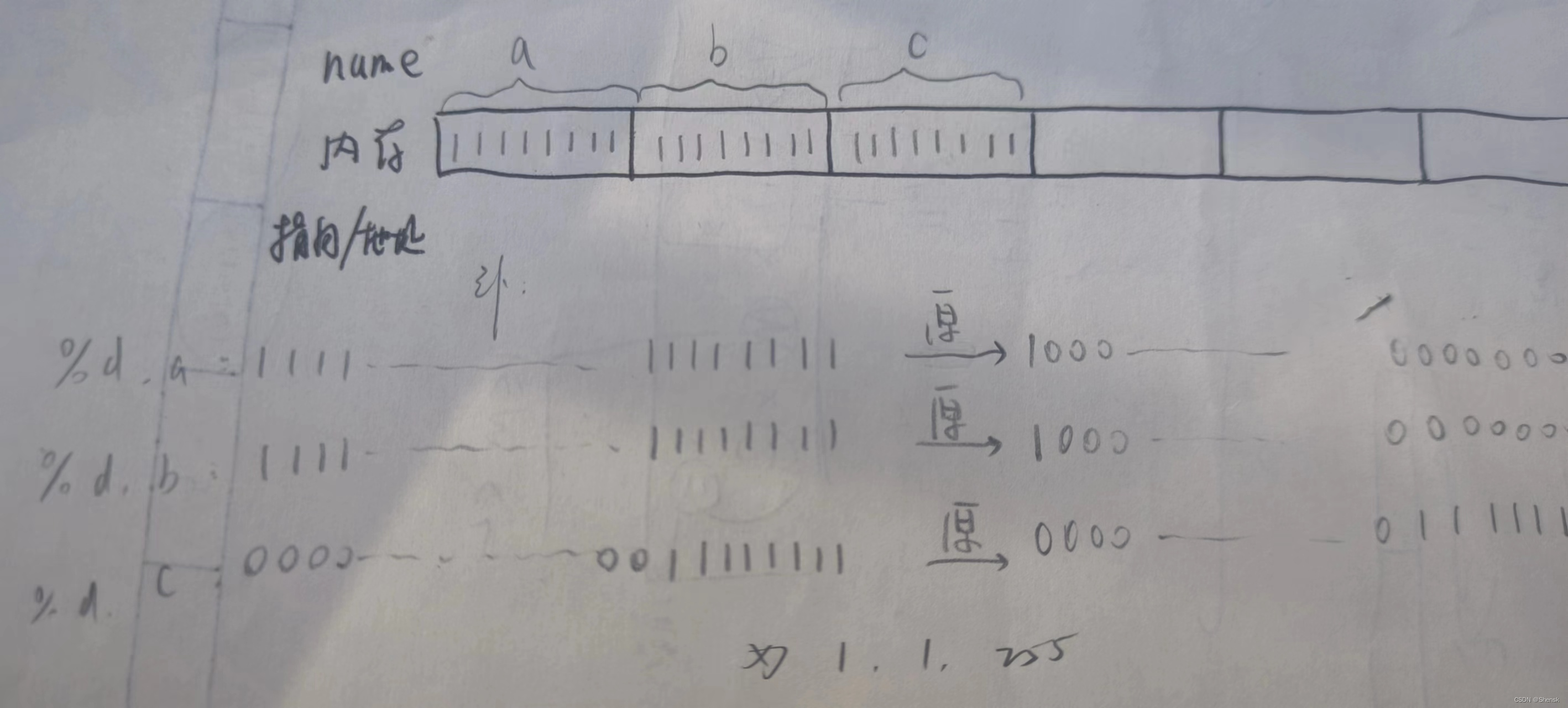
2.

答案:

解析:
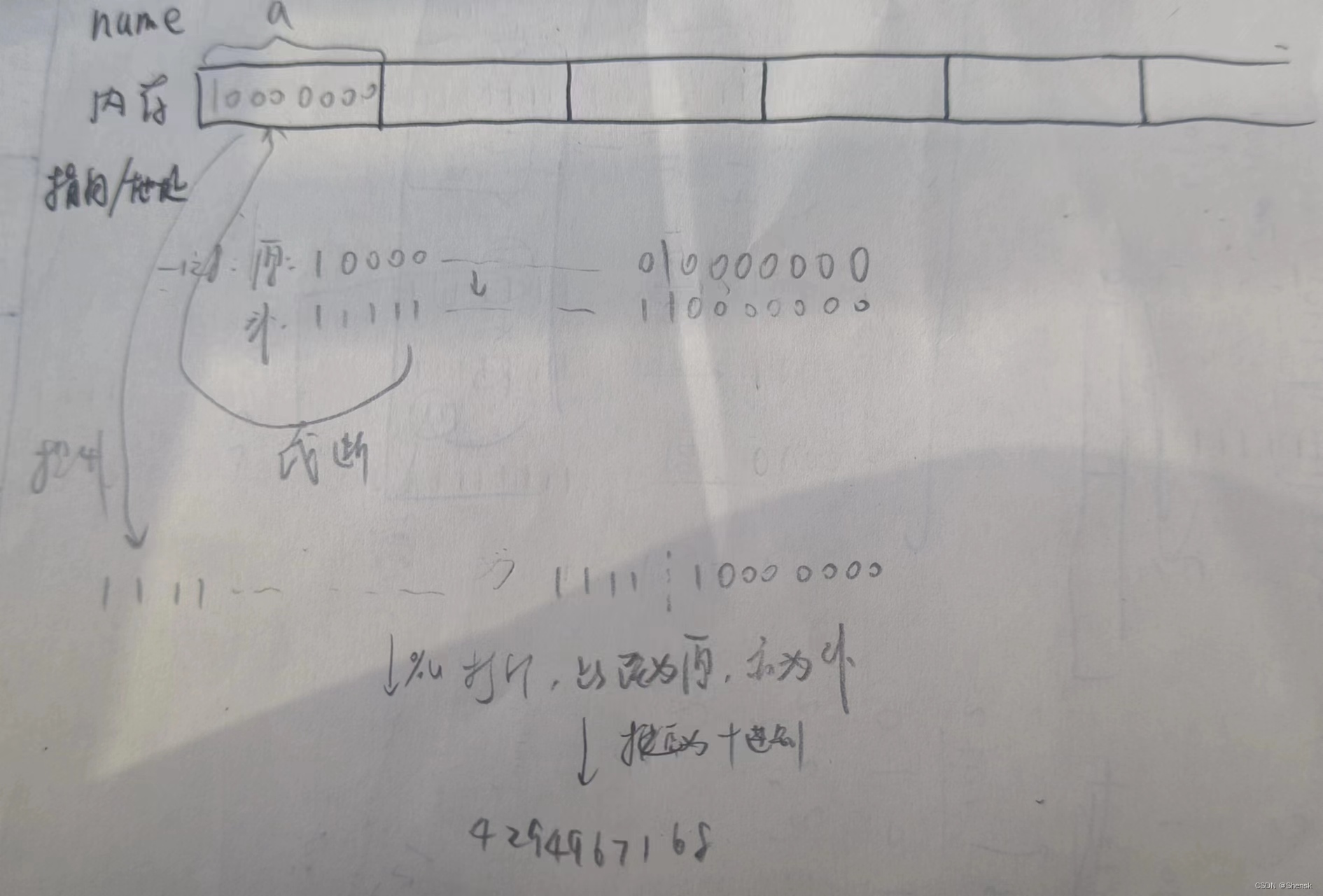
3.

答案:
解析:
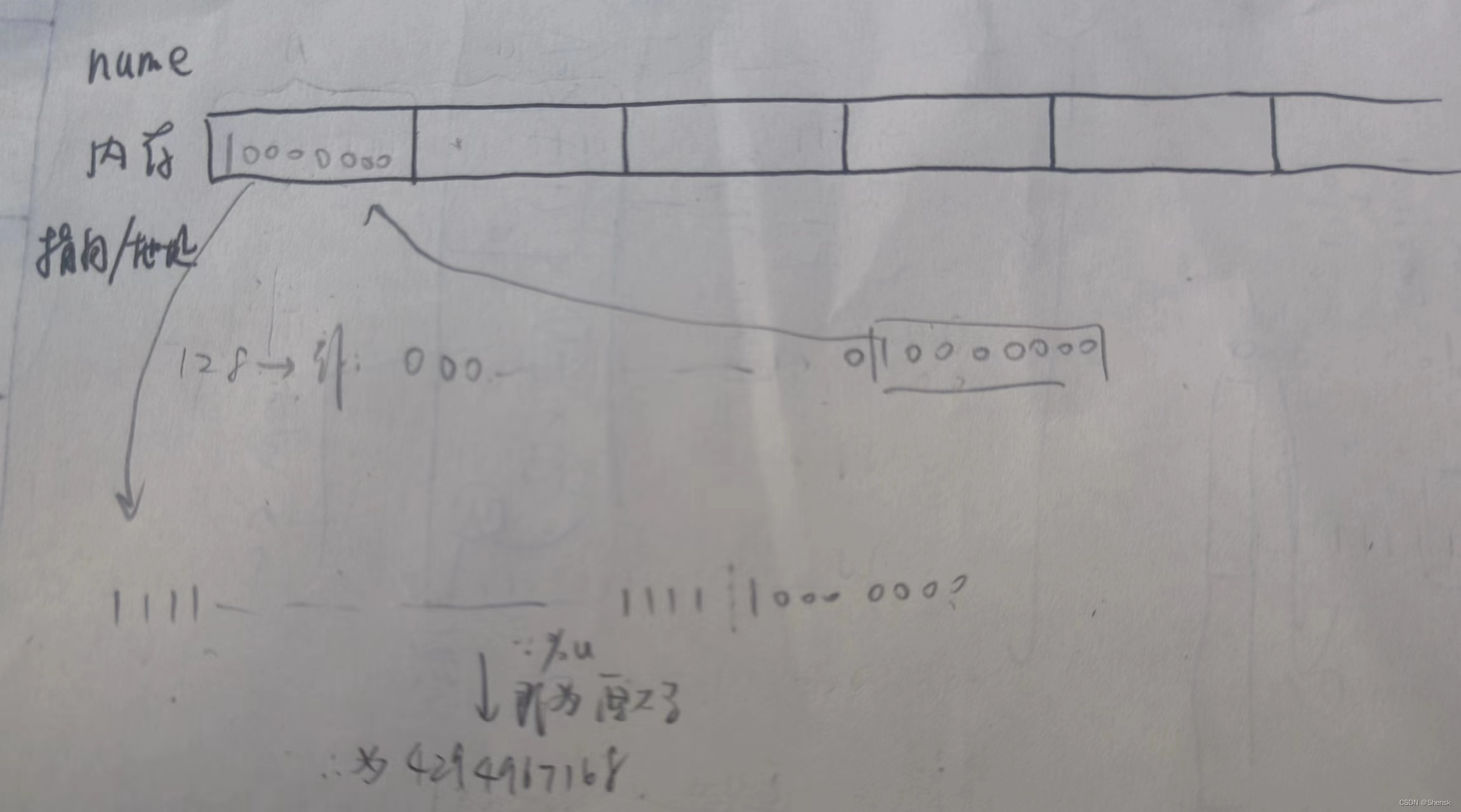
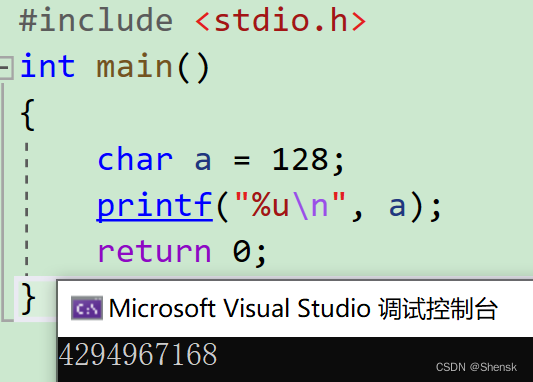
4.

答案:

解析:
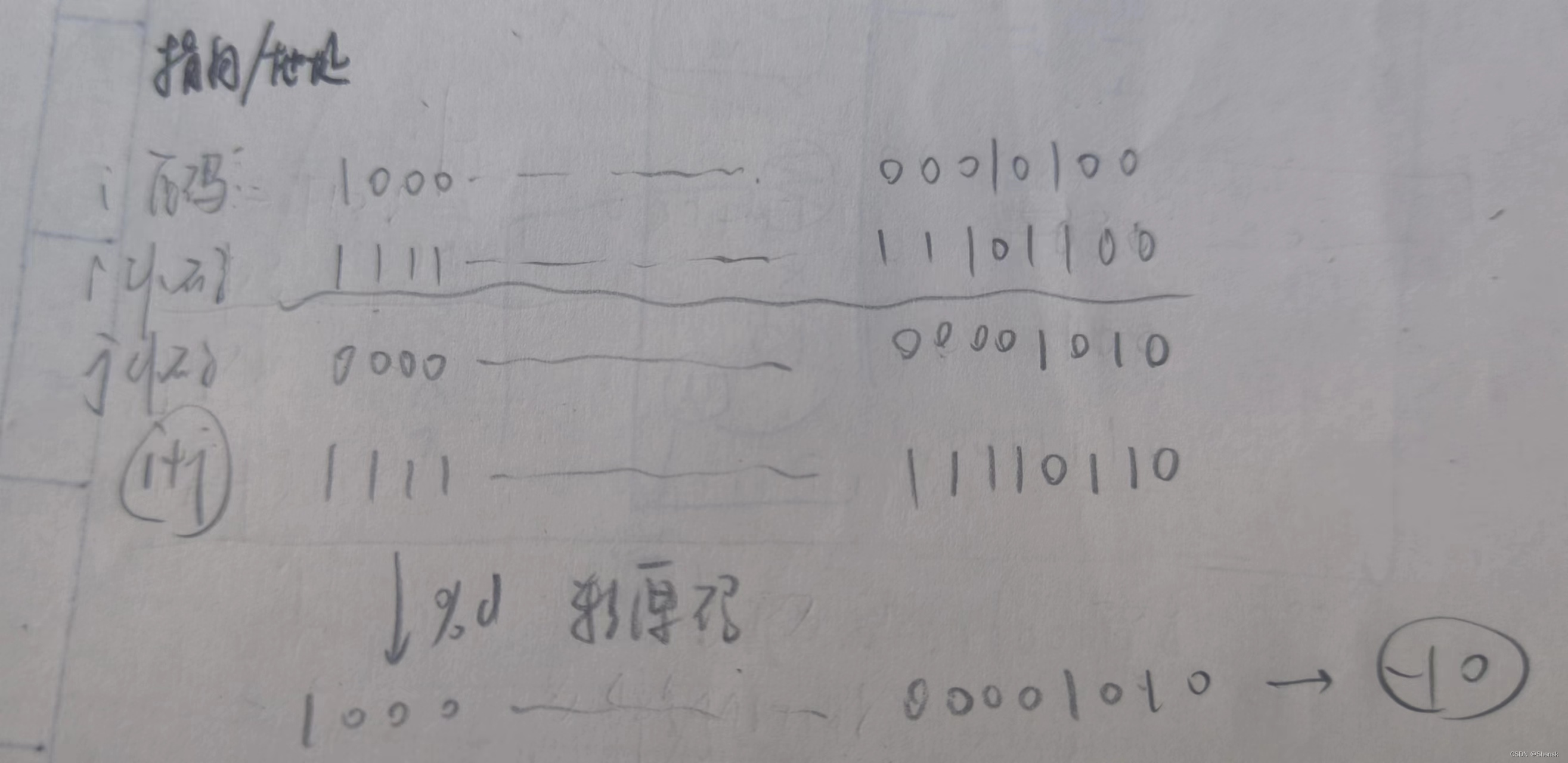
5.

答案:
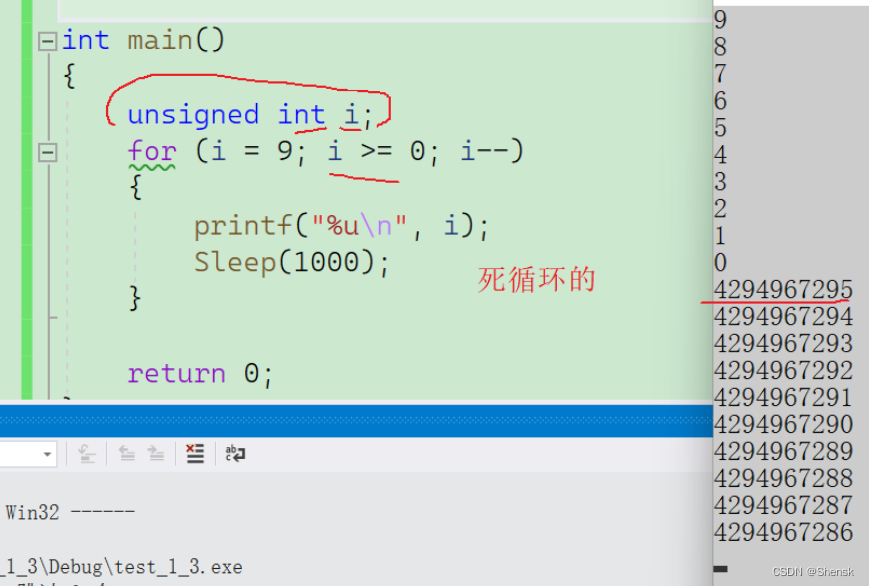
解析:
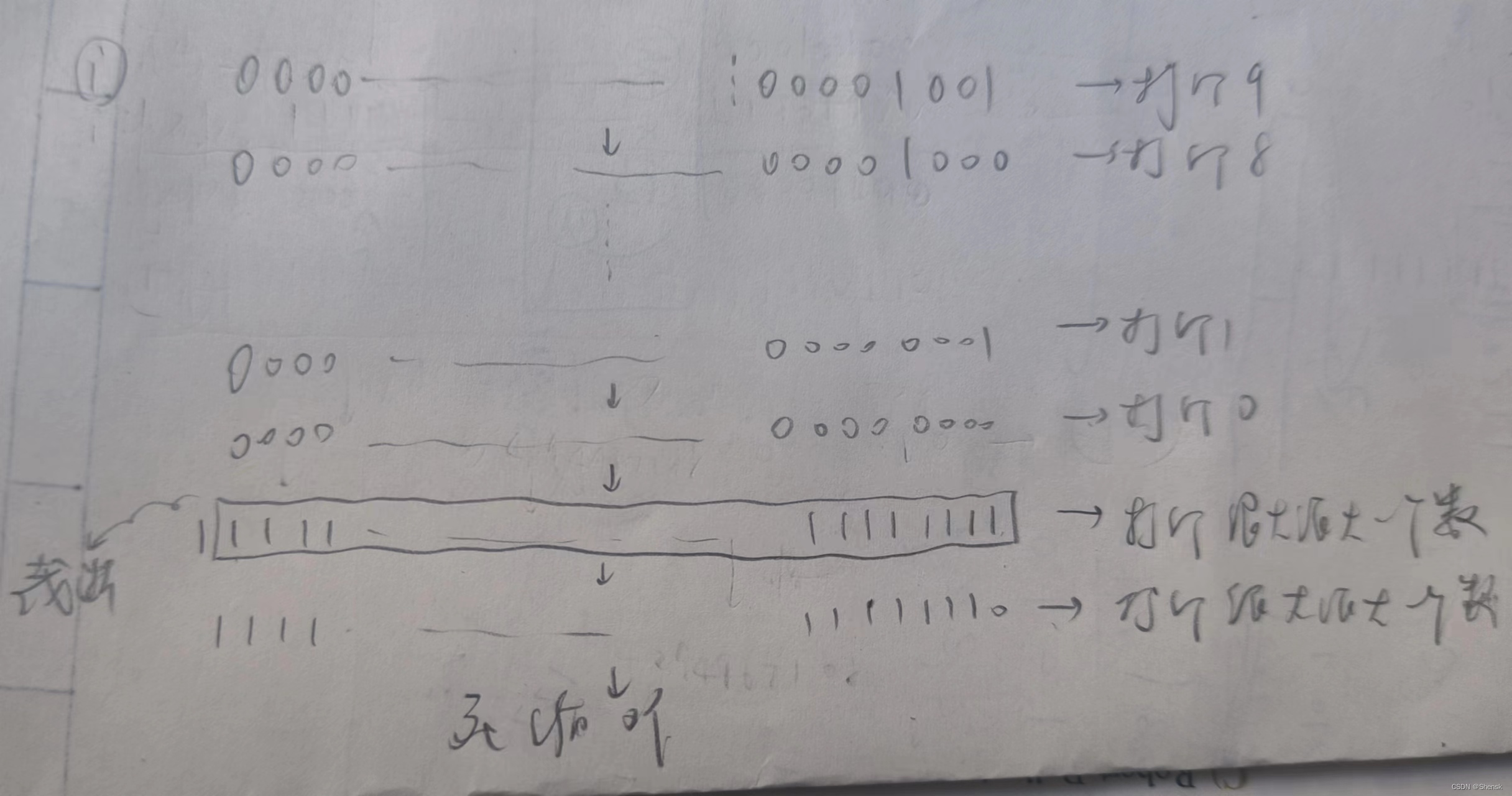
6.

答案:
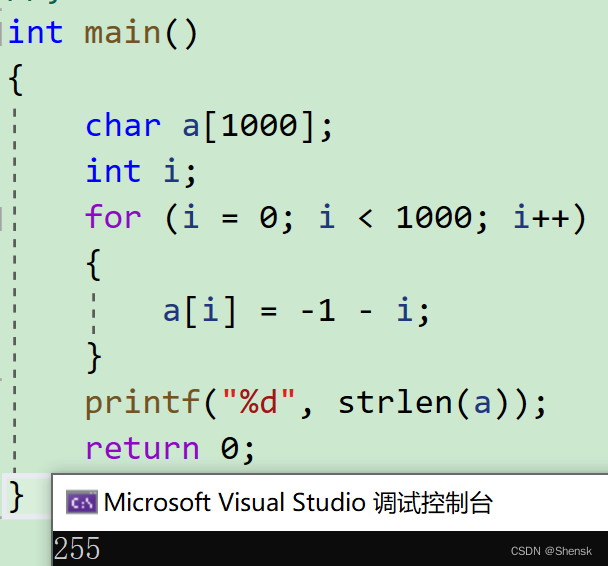
解析: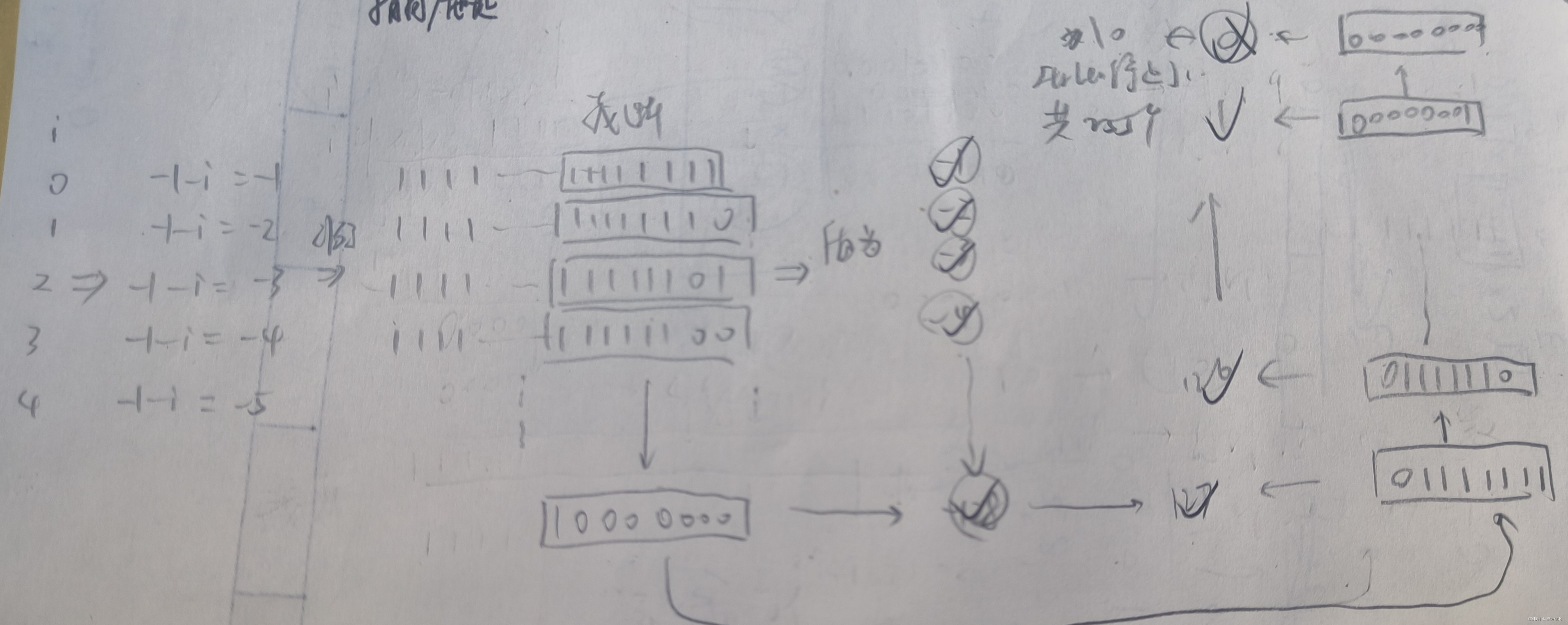
7.

答案:死循环
解析:

无符号的char的类型不可能超过255