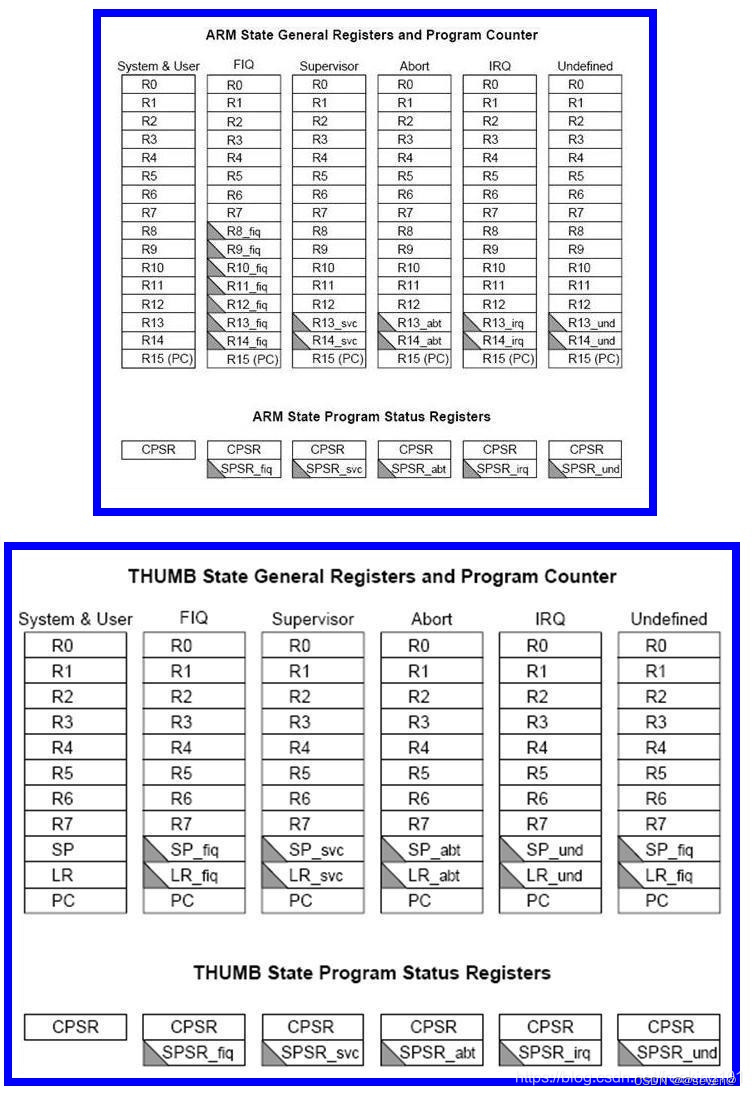
背景
我们内部基于 dpdk 自研的高性能负载均衡器 dpdk-lvs 已经在多个机房部署上线,运行正常,但近期有多个金融相关的业务反馈,服务数据包在经过dpdk-lvs转发后,会出现hang住的情况。
问题
1、dpdk-lvs 已经在多个机房上线,运行时间已超过半年,为何突然有业务反馈异常
2、反馈问题的业务多与金融区相关(金融区由于其特殊性,会额外增加安全方面的加固策略)
3、为什么问题表现均为服务hang住
问题排查
首先,我们怀疑与 dpdk-lvs 或与金融的某些安全策略相关,因此我们做了如下测试(后端上跑的均是相同的测试代码,并模拟了服务端逻辑):
1、client < ----- > dpdk-lvs < ----- > rs(金融区) 不正常
2、client < ----- > dpdk-lvs < ----- > rs(非金融区) 正常
3、client < ----- > lvs < ----- > rs(金融区) 正常
4、client < ----- > lvs < ----- > rs(非金融区) 正常
通过1、2组测试能够得出结论:该问题与金融区相关且dpdk-lvs转发正常
通过3、4组测试能够得出结论:该问题与金融区无关且kernel版lvs转发正常
通过1、3组测试能够得出结论:该问题与dpdk-lvs有关,经过dpdk-lvs的请求不正常
通过2、4组测试能够得出结论:该问题与dpdk-lvs/lvs无关,经过dpdk-lvs/lvs的请求均正常
以上 4 组结论两两冲突,无法定位问题是与dpdk-lvs相关还是与金融区相关,排查一度进入僵局,无法定位故障点。
为了进一步排查,我们在 client 和后端 rs 上抓包排查,发现 client 的请求均能够正常到达 rs,而 rs 的大部分数据也能够正常回复给 client,但有固定的几个包总是会被重传且直至超时,以下是抓包截图:
其中 10.128.129.14 是 rs 的 ip,10.115.167.0/24 是 dpdk-lvs的local ip,通过在 rs 上的抓包结果可以清楚的看出 rs 发给 dpdk-lvs 的 length 为 184 的包正确传输,但 length 为 2 的包一直在重传,且直至超时都没有成功,同时在 client 上的抓包显示,client 收到了这个 length 为 2 的包,但是由于 tcp checksum error 被丢掉了,并没有交给上层应用去处理,这样就解释了为什么异常时的表现是hang住,因为某个数据包一直在重传,直至 timeout。
通过上面的分析,我们又产生了疑问:现在的硬件网卡一般都具有csum offload的功能,能够通过网卡硬件帮我们做checksum,难道是网卡的checksum offload功能出现了问题?如果真是网卡硬件的offload功能出现问题,那影响的应该不是某一个特定的数据包,而是所有经过这块网卡的数据包才对,因此我们怀疑是网卡在针对某个特定数据包的计算checksum的时候产生了错误,为了验证这个问题,我们在dpdk-lvs上进行抓包分析,以下是抓包截图:
这个包就是被不断重传的包,能够看到dpdk-lvs确实收到了这个包,并且处理逻辑也完全正常,剩下的步骤只有通过网卡做checksum并把这个数据包转发出去,问题似乎确实是出在了计算checksum这里,我们在分析这个包有什么特点,可以看到,这个包的初始大小=ethernet header length + ip header length + tcp header length + tcp data = 14 + 20 + 20 + 5 = 59,而我们知道,在网络中传输的数据帧最小长度为64字节,除去FCS的4字节(这部分也由网卡自行计算后添加在数据包末尾),最小长度应为60字节,也就是说,到达网卡的数据包如果不够60字节,那么网卡会在动在数据包末尾增加全0的padding来使数据包能够达到60字节,所以这个数据包也是需要网卡硬件来补充1字节的padding来达到最小传输长度。对此rfc894是这样规定的:
因此rs的网卡在数据包长度不足60字节时需要做两件事情:
- 补充1字节的 padding 达到最小长度 60 字节* 补充的 adding 为全 0
可以看到,在二层头中,确实有个补充的 1 字节的 padding:ec,这个 padding 并没有按rfc894的规定填充成全0,而是填了非 0 值,这样就造成了dpdk-lvs的网卡在计算 tcp checksum 时把这个 padding 误当成了 tcp data 而计算了check sum,因此在 client 接收到这个数据包并根据ip伪头部和tcp头部计算出来的 checksum 与数据包 tcp 头部的 checksum 不一致,因此并没有把这个数据包交给上层应用处理而是直接 drop。
(网卡手册针对 TCP/UDP checksum部分的说明)
至此,问题的原因已经很明显了:部分机器的网卡在做padding时未按照rfc894的规定补充全 0 而是补充了其他值,导致 dpdk-lvs 的网卡在做 checksum offload 时 padding 的数据也参与了 checksum 的计算。
分析正常的 rs 和不正常的rs在网卡硬件上的差别,发现:网卡的硬件型号相同,驱动型号也相同,但不正常的网卡 fireware 与正常的网卡不相同,而fireware我们没有办法自行升级或降级。
整个故障的过程可以大概表示为:
client dpdk-lvs rs
---1--- >
< ---2---
< ---3---
**步骤1:**数据包正常,请求数据
**步骤2:**部分数据包初始长度小于60字节,需要网卡补充padding,网卡先计算checksum填入tcp包头后补充padding至数据包末尾,此时checksum正常,但padding不为全0
步骤3:dpdk-lvs收到步骤2的包进行正常转发逻辑处理后转发至网卡,由网卡计算checksum并转发,但在计算新的checksum时由于padding非全0导致checksum计算错误,client收到后丢弃了这个包
ps:以上是rs的网卡在添加padding时补充的不是全0,另一种场景是client的网卡在添加padding时补充的不是全0,这两种情况都会导致上述问题的出现。
问题解决
至此,我们已经能够解释最开始提出的三个问题:
1、dpdk-lvs已经在多个机房上线,运行时间已超过半年,为何突然有业务反馈异常A:该业务是在某个核心机房上线了dpdk-lvs后出现了问题,其他机房很早上线了dpdk-lvs但由于其他机房是改业务的备份机房实际并未启用,因此半年多来一直没有发现问题
**2、反馈问题的业务多与金融区相关(金融区由于其特殊性,会额外增加安全方面的加固策略)**A:排查发现是金融区的某一批次机器的fireware存在bug导致,与金融区本身的安全策略无关
3、为什么问题表现均为服务hang住A:问题的实质是出现丢包,服务在等待响应,因此表现为hang住
接下来我们将解决该问题:
只要让 dpdk-lvs 在处理数据包时,忽略数据包以前的 padding 部分,而由 dpdk-lvs 的网卡重新去处理padding(由于网卡计算 checksum 是在补充 padding 之前,因此可以保证此时的 checksum 一定是正确的)。由于 dpdk-lvs 是基于 dpdk 开发的,数据包在 dpdk-lvs 中是以 mbuf 的结构保存和处理的,以下是 mbuf 的结构:
数据帧被存储在 headroom 和 tailroom 之间(与skb类似),pkt_len=data_len=整个数据帧的长度,我们要做的就是将 padding 从 data 中去除(放到 tailroom 中去),因此可以在数据包入口处添加以下代码:
int padding_length = mbuf->data_len - (mbuf->l2_len +rte_be_to_cpu_16(ipv4_hdr->total_length));
mbuf->data_len = mbuf->data_len - padding_length;
mbuf->pkt_len = mbuf->data_len;