随着人工智能(AI)技术的迅猛发展,Fine-tuning作为一项重要而神奇的技术崭露头角。Fine-tuning俗称“微调技术。其本质上是对已有模型进行能力的迁移学习扩展,由于重新训练神经网络模型的成本太高,所以使用微调技术可以降低训练成本,在大模型领域使用最为频繁。
在本篇文章中,我们将深入探讨Fine-tuning的概念、原理以及如何在实际项目中运用它,以此为初学者提供一份入门级的指南。
一、什么是大模型
ChatGPT大模型今年可谓是大火,在正式介绍大模型微调技术之前,为了方便大家理解,我们先对大模型做一个直观的抽象。
本质上,现在的大模型要解决的问题,就是一个序列数据转换的问题:
输入序列 X = [x1, x2, ..., xm], 输出序列Y = [y1, y2, …, yn],X和Y之间的关系是:Y = WX。
我们所说的“大模型”这个词:“大”是指用于训练模型的参数非常多,多达千亿、万亿;而“模型”指的就是上述公式中的矩阵W。
在这里,矩阵W就是通过机器学习,得出的用来将X序列,转换成Y序列的权重参数组成的矩阵。
需要特别说明:这里为了方便理解,做了大量的简化。在实际的模型中,会有多个用于不同目的的权重参数矩阵,也还有一些其它参数。

二、大模型Fine-tuning的概念
Fine-tuning源于对已经训练好的模型进行微调的概念。传统的机器学习模型需要通过大量数据进行训练,而Fine-tuning则利用了在庞大数据集上训练好的大型深度学习模型。这些预训练模型,如ChatGPT大模型,已经通过数以亿计的文本数据学到了庞大的知识库。
在预训练模型的基础上进行额外训练,使其适应特定任务或领域。这一过程包括选择预训练模型,准备目标任务的数据,调整模型结构,进行微调训练,以及评估和部署。
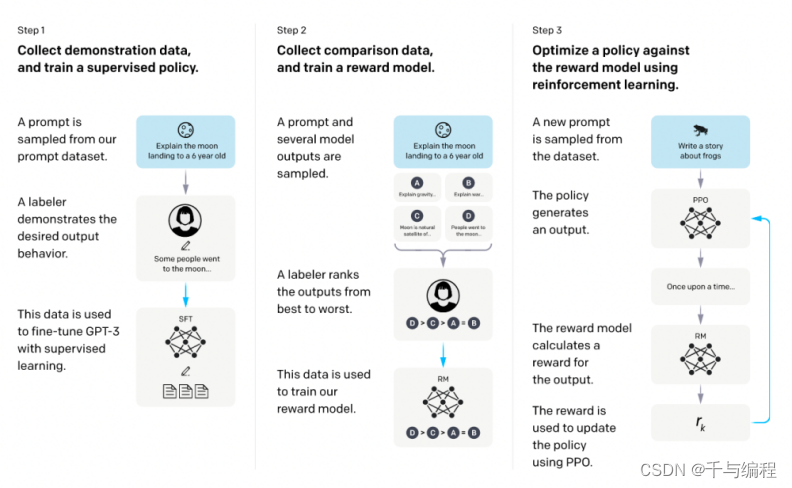
微调的优点在于节省时间和资源,提高性能,但也存在过拟合风险和模型选择与调整的复杂性。总体而言,它是一种强大的技术,特别适用于数据受限或计算资源有限的情况。
三、大模型微调的方式
在 OpenAI 发布的 ChatGPT应用中,就主要应用了大模型微调技术,从而获得了惊艳全世界的效果。
而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。
3.1 full fine-tuning全量微调
大模型全量微调通过在预训练的大型模型基础上调整所有层和参数,使其适应特定任务。这一过程使用较小的学习率和特定任务的数据进行,可以充分利用预训练模型的通用特征,但可能需要更多的计算资源。
3.2 参数高效微调
PEFT技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。
Prompt Tuning
Prompt Tuning的出发点,是基座模型(Foundation Model)的参数不变,为每个特定任务,训练一个少量参数的小模型,在具体执行特定任务的时候按需调用。
Prompt Tuning的基本原理是在输入序列X之前,增加一些特定长度的特殊Token,以增大生成期望序列的概率。
具体来说,就是将X = [x1, x2, ..., xm]变成,X` = [x`1, x`2, ..., x`k; x1, x2, ..., xm], Y = WX`。
如果将大模型比做一个函数:Y=f(X),那么Prompt Tuning就是在保证函数本身不变的前提下,在X前面加上了一些特定的内容,而这些内容可以影响X生成期望中Y的概率。
Prefix Tuning
Prefix Tuning的灵感来源是,基于Prompt Engineering的实践表明,在不改变大模型的前提下,在Prompt上下文中添加适当的条件,可以引导大模型有更加出色的表现。
Prefix Tuning的出发点,跟Prompt Tuning的是类似的,只不过它们的具体实现上有一些差异。
而Prefix Tuning是在Transformer的Encoder和Decoder的网络中都加了一些特定的前缀。
具体来说,就是将Y=WX中的W,变成W` = [Wp; W],Y=W`X。
Prefix Tuning也保证了基座模型本身是没有变的,只是在推理的过程中,按需要在W前面拼接一些参数。
LoRA
LoRA是跟Prompt Tuning和Prefix Tuning完全不相同的另一条技术路线。
LoRA背后有一个假设:我们现在看到的这些大语言模型,它们都是被过度参数化的。而过度参数化的大模型背后,都有一个低维的本质模型。
通俗讲人话:大模型参数很多,但并不是所有的参数都是发挥同样作用的;大模型中有其中一部分参数,是非常重要的,是影响大模型生成结果的关键参数,这部分关键参数就是上面提到的低维的本质模型。
首先, 要适配特定的下游任务,要训练一个特定的模型,将Y=WX变成Y=(W+∆W)X,这里面∆W主是我们要微调得到的结果;
其次,将∆W进行低维分解∆W=AB (∆W为m * n维,A为m * r维,B为r * n维,r就是上述假设中的低维);
接下来,用特定的训练数据,训练出A和B即可得到∆W,在推理的过程中直接将∆W加到W上去,再没有额外的成本。
另外,如果要用LoRA适配不同的场景,切换也非常方便,做简单的矩阵加法即可:(W + ∆W) - ∆W + ∆W`。
四、Fine-tuning的步骤和流程
备注:预训练模型是指在庞大的数据集上进行训练得到的模型。这些数据集通常是通过无监督学习或其他任务进行训练的。简单来说就是“模型的母体”。
- 准备微调数据集: Fine-tuning的成功与否密不可分于数据的质量。确保你的数据与模型预期的输入格式一致,进行必要的清理和标记。
备注:微调数据集是指在模型微调过程中所使用的数据集,比如原有大模型是识别动物类的大模型,现在我们准备了全部是猫狗的图片数据集,迁移模型的识别到识别猫狗上。
- 调整模型数据集输入: 根据具体任务,调整模型的输入以适应任务的特性。比如,文本分类任务可能需要在模型输入中包含任务相关的信息。
备注:本质上,就是调节模型识别的标签,比如原来识别的猫,现在让识别成狗,就是调整模型的标签输入
- 定义损失函数: 根据任务类型,定义适当的损失函数。这是模型优化的目标,对于分类任务,通常使用交叉熵损失。
备注:损失函数就好比你在玩打靶游戏,目标是尽量靠近靶心。当你射击命中靶心时,你会得到一个很小的损失分数,代表你的射击非常准确;而当你偏离靶心时,损失分数会相应增加,代表你离目标更远了。
在机器学习中,损失函数类似于靶心,我们的模型的预测结果就类比为射击的结果。损失函数衡量了模型预测值与真实值之间的差距,我们的目标是尽量减小这种差距,即尽量减小损失函数的值。
备注:冻结部分模型可以用一个简单的例子来解释。假设你正在准备一道复杂的菜肴,这个菜需要煎牛排、炒蔬菜和做汁料。你已经有了一个非常熟练的牛排煎得恰到好处的步骤,这是你多年的经验总结出来的。但是你对于炒蔬菜和做汁料的处理方法还不是很熟悉。
那么在这个情况下,你可以决定冻结(保持不变)你熟练的牛排煎的步骤,因为你已经能够很好地完成它。你只需要专注于学习和改进炒蔬菜和做汁料的步骤,以充分利用你的努力。
- 选择优化器和学习率: 选择一个适当的优化器(如Adam)和学习率。预训练模型的学习率通常较小,因为它已经包含了大量的知识。
我们可以将机器学习模型的参数调整过程类比为学生学习的过程。学习过程中,学生需要根据老师的指导不断调整学习策略,使得自己的学习效果越来越好。
优化器就像是学生的学习策略,它决定了如何根据反馈信息来更新模型的参数。不同的优化器有不同的策略,比如一些优化器会根据参数的梯度(导数)大小来调整参数的更新步长,而另一些优化器则会考虑参数的历史更新情况来调整步长。这些策略旨在使模型更好地逼近最优解,就像学生通过不断调整学习策略来提高学习效果一样。
学习率则类似于学生的学习步长,它决定了每次参数更新的幅度。如果学习率很小,那么参数更新的幅度会很小,学习过程会比较稳定但可能会收敛得比较慢;如果学习率很大,那么参数更新的幅度会很大,学习过程可能会比较震荡但可能会收敛得较快。选择合适的学习率可以帮助模型更快地找到最优解,就像选择合适的学习步长可以帮助学生更快地掌握知识一样。
- 进行微调训练: 利用准备好的数据和定义好的设置,开始模型的训练。迭代多个周期,直到在验证集上表现良好。
- 评估模型性能: 使用测试集来评估fine-tuned模型的性能。查看模型在任务上的表现,并根据需要进行调整。
备注:评估模型性能就好比是给学生考试一样,我们想知道学生掌握知识的程度。在考试中,我们通过评估学生的答题情况来得出一个分数,这个分数反映了学生在掌握知识方面的能力。
五、大模型微调开源项目
作者后来将各种大模型的高效微调,统一到了一个项目里:https://github.com/hiyouga/LLaMA-Factory(opens new window)
| Model | Default module | ||
| href="https://github.com/facebookresearch/llama" LLaMA | q_proj,v_proj | ||
| href="https://huggingface.co/meta-llama" LLaMA-2 | q_proj,v_proj | ||
| href="https://huggingface.co/bigscience/bloom" BLOOM | query_key_value | ||
| href="https://huggingface.co/bigscience/bloomz" BLOOMZ | query_key_value | ||
| href="https://huggingface.co/tiiuae/falcon-7b" Falcon | query_key_value | ||
| href="https://github.com/baichuan-inc/Baichuan-13B" Baichuan | W_pack | ||
| href="https://github.com/baichuan-inc/Baichuan2" Baichuan2 | W_pack | ||
| href="https://github.com/InternLM/InternLM" InternLM | q_proj,v_proj | ||
| href="https://github.com/QwenLM/Qwen-7B" Qwen | c_attn | ||
| href="https://github.com/THUDM/ChatGLM3" ChatGLM3 | query_key_value | ||
| href="https://huggingface.co/microsoft/phi-1_5" Phi-1.5 | Wqkv |
5.1 ChatGLM大模型微调
- 项目简介: 基于 PEFT 的高效 ChatGLM 微调,兼容 ChatGLM 与 ChatGLM-2 模型,支持 Full Tuning、LoRA、P-Tuning V2、Freeze等微调方式。
- 备注: 关于这些微调方式,我来给你通俗易懂地解释一下:
- Full Tuning(全参数微调):就像你重新学习一门课程一样,这种微调方式会重新调整模型中所有参数,让模型在新的任务上学习适应最佳的参数配置。这样可以让模型更好地适应新的数据和任务,但可能需要花费更多的时间和计算资源。
- LoRA(Layer-wise Relevance Adaption,逐层相关性适应):这种微调方式是针对特定层次的调整,就好比给身体的不同部位做不同的锻炼一样。通过逐层调整,模型可以更灵活地适应新的任务,而不是一刀切地调整所有参数。
- P-Tuning V2:这是谷歌提出的一种参数微调方法,它使用了预训练的大型语言模型来进行微调,以适应特定的应用场景。这种方式类似于在预训练的基础上进行精细化调整,以获得更好的性能。
- Freeze(冻结):就像冻结时间一样,这种微调方式会保持模型的某些部分不变。在微调时,你可以冻结一些不需要调整的模型参数,集中精力在需要调整的部分上,以节省时间和计算资源,同时保留已有的良好性能。
- ChatGLM项目地址:GitHub - hiyouga/ChatGLM-Efficient-Tuning: Fine-tuning ChatGLM-6B with PEFT | 基于 PEFT 的高效 ChatGLM 微调

5.2 LLaMA大模型微调
- 项目简介:基于 PEFT 的高效 LLaMA 微调,兼容 LLaMA 与 LLaMA-2 模型。
- 项目地址:GitHub - hiyouga/LLaMA-Factory: Easy-to-use LLM fine-tuning framework (LLaMA, BLOOM, Mistral, Baichuan, Qwen, ChatGLM)

- 总结一下, 大模型的微调技术的诞生是源于大模型进行训练的成本,因为训练一次大模型类似以上的ChatGLM大模型微调以及LLaMA大模型微调,训练主机的显存需要20GB以上,一般的公司是承受不起的。
- 而且数据集比较大,所以训练一次的电费都不小,因此微调技术可以快速实现能力的迁移,这就是Fine-tuning的微调技术,实现个性化AI的应用。