这是Python数据分析系列原创文章,我的第199篇原创文章。
一、问题
平时在做数据分析或者程序开发的时候,需要将中间的一些结果或最后的处理结果保存下来,比如保存为txt格式的文本文件,这就涉及列表与txt之间的一种读取和写入操作,本文将用一个简单的例子来实现。
二、一维列表与txt读写转换
2.1 一维列表写入txt文件
将一维列表data中的每个元素写入文件中,每个元素占一行:
data = [1, 2, 3, 4, 5]
with open("output1.txt", "w") as file:
for item in data:
file.write(str(item) + "\n")上述代码将创建一个名为output1.txt的文本文件,并将列表data中的每个元素写入文件中,每个元素占一行。open("output1.txt", "w")用于打开文件,"w"表示以写入模式打开文件。with open(...) as file:语句用于自动管理文件的打开和关闭,确保在使用完文件后正确关闭它。
for item in data循环遍历列表中的每个元素,并使用file.write(...)将每个元素写入文件。str(item)将元素转换为字符串形式,"\n"表示换行符,用于将每个元素写入文件的不同行。
执行上述代码后,将在当前目录下创建一个名为output.txt的文本文件,并将列表中的元素写入文件中。

需要注意的是,如果列表中的元素不是字符串类型,需要使用适当的方法将其转换为字符串形式,以便写入文件。在上面的示例中,使用str(item)将元素转换为字符串。
2.2 读取txt文件为一维列表
逐行读取文件内容,写入列表:
with open("output1.txt", "r") as file:
data = file.read().splitlines()
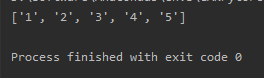
print(data)首先使用open("output1.txt", "r")打开名为input.txt的文本文件,以读取模式打开文件。然后,file.read()方法将整个文件内容作为一个字符串读取出来。接下来,splitlines()方法将字符串按行分割,并返回一个包含每行内容的列表。
执行上述代码后,将读取名为output1.txt的文本文件,并将文件中的每一行作为列表的一个元素存储在data中。
请注意,如果文件非常大,一次性读取整个文件内容可能会占用大量内存。在处理大型文件时,可能需要考虑逐行读取或使用其他适当的方法来处理文件内容。
三、二维列表与txt读写转换
3.1 二维列表写入txt文件
将二维列表data中的每个元素写入文件中,每个元素占一行:
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
with open("output2.txt", "w") as file:
for row in data:
for item in row:
file.write(str(item) + ' ')
file.write('\n')运行以上代码后,将会在当前目录下生成一个名为"output2.txt"的文件,其中包含二维列表的数据。每行表示二维列表中的一行,每个元素之间使用空格分隔。请注意,上述代码将数据以空格分隔并写入文件,如果你需要使用其他分隔符,可以在write()方法中修改。

3.2 读取txt文件为二维列表
读取txt文件,输出为二维列表,每个元素为一行:
with open('output2.txt', 'r') as file:
lines = file.readlines()
data = []
for line in lines:
row = line.strip().split(' ')
data.append(row)lines:
![]()
data:

使用readlines()方法读取文件的所有行,并将其存储在一个列表中。遍历行列表,使用split()方法将每行按照指定的分隔符(如空格)分割为多个元素,并将其存储在二维列表中。请注意,上述代码假设每行数据以空格分隔。如果你的文件中使用其他分隔符,可以在split()方法中修改分隔符参数。另外,strip()方法用于去除每行开头和结尾的空白字符,以确保数据的准确性。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信!