一、引言
机器学习是当前信息技术中最令人振奋的领域之一。在这门课程中,我们将探索该技术的前沿,并能够亲自实现机器学习的算法。
或许你每天都在不知不觉中使用了机器学习的算法。每次你打开谷歌或必应搜索你需要的内容,正是因为它们拥有出色的学习算法。每次你使用Facebook或苹果的图片分类程序,它能够识别出你朋友的照片,这也是机器学习的应用。每次你阅读电子邮件时,垃圾邮件过滤器能够帮助你过滤大量的垃圾邮件,这同样是一种学习算法。
这里有一些机器学习的案例。比如,数据库挖掘。机器学习被用于数据挖掘的原因之一是网络和自动化技术的增长,这意味着我们拥有历史上最大的数据集。例如,许多硅谷公司正在收集网络上的点击数据(也称为点击流数据),并尝试使用机器学习算法来分析数据,以更好地了解用户并提供更好的服务,这在硅谷有着巨大的市场。另一个例子是医疗记录。随着自动化的出现,我们现在有了电子医疗记录。如果我们可以将医疗记录转化为医学知识,我们就可以更好地理解疾病。再比如计算生物学。还是因为自动化技术,生物学家们收集了大量的基因数据序列、DNA序列等等,通过运行算法让我们更好地了解人类基因组,这对全人类来说意义重大。另外,在工程领域,我们在各个领域都有越来越大的数据集,我们试图使用学习算法来理解这些数据。此外,在机械应用中,有些人无法直接操作。例如,有人已经在无人直升机领域工作了许多年,他们不知道如何编写一段程序让直升机自己飞行,他们唯一能做的就是让计算机自己学习如何驾驶直升机。
事实上,如果你研究过自然语言处理或计算机视觉,你会发现这些语言理解或图像理解都属于AI领域,大部分的自然语言处理和大部分的计算机视觉都应用了机器学习。学习算法还广泛用于自定制程序,每次你去亚马逊时,它都会给出其他电影、产品或音乐的建议,这就是一种学习算法。仔细想一想,他们有数百万的用户,但他们没有办法为数百万用户编写数百万个不同的程序。软件能够为这些自定制的建议提供的唯一方法是通过学习你的行为来为你定制服务。
二、机器学习是什么
机器学习是一种人工智能的分支,它致力于研究如何使计算机能够从数据中学习并做出预测或决策。通过使用各种算法和技术,机器学习可以使计算机自动地从经验中提取规律和模式,并根据这些规律和模式进行预测、分类、聚类等任务。在机器学习中,我们通常将数据集分为训练集和测试集。训练集用于训练模型,使其能够学习到数据中的规律和模式;测试集用于评估模型的性能和泛化能力。通过反复调整模型的参数和算法的选择,我们可以不断提高模型的准确性和性能。
监督学习和无监督学习是机器学习中的两种主要类型。监督学习是指给定一组输入数据和对应的输出标签,通过训练模型来学习输入与输出之间的映射关系。常见的监督学习任务包括分类和回归。无监督学习是指只给定一组输入数据,没有对应的输出标签,通过训练模型来发现数据中的结构和模式。常见的无监督学习任务包括聚类和降维。
除了监督学习和无监督学习,还有其他类型的学习算法,如强化学习和推荐系统。强化学习是指通过与环境的交互来学习如何做出最优的行动策略。推荐系统是指根据用户的历史行为和偏好,为用户推荐个性化的内容或产品。
在实际应用中,选择合适的学习算法和模型是非常重要的。不同的问题和数据集可能需要不同的算法和方法来解决。因此,了解各种学习算法的原理和应用范围,以及如何根据实际情况进行选择和调优,对于设计和构建有效的机器学习系统至关重要。
讲一个通俗易懂的例子,Barret编写了一个西洋棋程序,这程序神奇之处在于,Barret自己并不是个下棋高手,但因为他太菜了,于是就通过编程,让西洋棋程序自己跟自己下了上万盘棋。通过观察哪种布局(棋盘位置)会赢,哪种布局会输,久而久之,这西洋棋程序明白了什么是好的布局,什么样是坏的布局,然后就牛逼大发了,程序通过学习后,玩西洋棋的水平超过了Barret。
一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升。结合上述例子,我认为经验E就是程序上万次的自我练习的经验,而任务T 就是下棋,性能度量值P就是它在与一些新的对手比赛时,赢得比赛的概率。
三、监督学习
监督学习是已经知道数据的label,例如预测房价问题,其中给出了房子的面积和价格。
-
回归问题预测连续值的输出,例如预测房价。

- 分类问题是预测离散值输出,例如判断肿瘤是良性还是恶性。

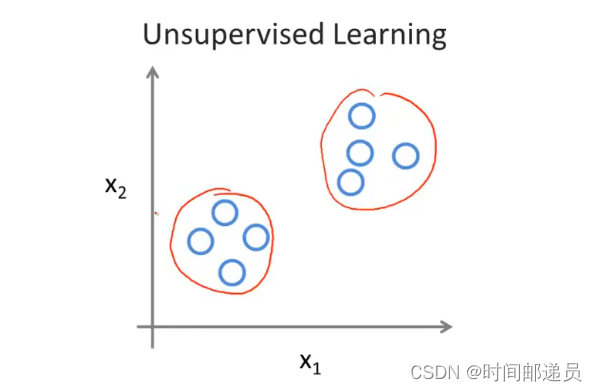
四、无监督学习
无监督学习是不知道数据具体的含义,比如给定一些数据但不知道它们具体的信息,对于分类问题无监督学习可以得到多个不同的聚类,从而实现预测的功能。