各位朋友大家好,博主新创立了一个公众号《自学编程村》哈,感兴趣的可以也关注关注捏~~
【简介】
它是由村长发起,然后邀请了一些小伙伴来作为自己的嘉宾,不定时的为大家分享学习、生活、信息。他们中间,有来自中国科学技术大学、武汉大学、山东大学,有的是CSDN万粉博主,有的是ACM竞赛选手,有的是双非上岸BAT大厂的学长们~~
【我们的任务是】
1、分享自身原创的学习教程,包含但不限于C/C++、Java、Golang、Python、matlab等语言语法、STL/SpringCloud等组件、数据结构、算法、操作系统及系统编程、计算机网络及网络编程、数据库,各种项目等等,也会为大家分享大量的面经。
2、和同学们分享行业内的第一消息,同时分享分享职场生活、校园生活。并致力于消除校招、CS保研(含跨保)、考研、留学等方面的信息差。
3、与各位村友探讨人生职业规划,路该怎么走,我们该怎么办。【关注方式】:拉到底部或在主页扫描名片的二维码,或直接微信搜索 自学编程村 关注。
各位感兴趣就关注,不感兴趣就算啦,不强求的哈~~~
本节,我们通过介绍事务,以事务为线索,来介绍数据库恢复技术。所介绍到的代码实例会兼顾到使用sql sever和Mysql的同学们(实际上二者本身也相差无几)
而数据库的恢复技术是事务的一致性决定的,同时也是对事务进行操作。其看似是数据库的知识,实际上还是与事务息息相关。因此,本文通篇的行文线索为事务。
(如果想看MVCC、Read View有关的知识,还请看下一节呦,我们会在下一篇文章来详细地介绍这些内容,我把它归属到了并发控制技术当中了)
目录
事务的基本概念
事务的引入和介绍
事务的ACID特性
事务控制
事务开始
事务提交
数据库恢复技术
故障发生的原因
数据库恢复技术的实现
建立冗余数据
数据转储
登记日志文件
数据库的恢复策略
1、事务内部故障的修复
恢复方法:
具体步骤:
2、系统故障的恢复
恢复方法:
具体步骤:
具有检查点的恢复技术
3、介质故障的恢复
利用数据库镜像技术恢复
(本来是想在本节介绍数据库并发控制技术的,但是那样的话就字太多、文章太长了,所以我就分开啦~)
事务的基本概念
事务的引入和介绍
事务,是数据库中的一个重要的组成。
那什么叫做事务?事务字面上理解即是指要做的事情,在SQL当中,事务可以理解为一组控制语句序列的集合。它是一个不可分割的工作单位,也是恢复和并发控制的基本单位。
我们可以来通过举例来尝试理解一下事务的概念:
比如银行转账,分为你先转给银行、银行再转到指定的用户的账户上这样两个过程。它不可以出现:你给银行转过了,但是由于某些原因(比如网断了),你的目标账户没有收到来自银行的转账,那你的钱被银行私吞了?银行说我给你转了啊,可事实是目标账户并没有收到。这就引发了问题。所以,我们就希望你转给银行、以及银行再转到指定账户上这样一个过程是原子的。
所以说,我们就引入了事务这样一个概念,使得这一系列的动作必须全要做,要么都不做,让它们是一个不可分割的工作单位,让它是原子的。
我们之前在介绍进程的时候,我们尝试着和程序做了比较。那么我们也不妨思考一下,事务和程序有什么样的区别或者是联系呢?
在关系型数据库当中,通常,一个程序包含了大量的事务。因为事务它的一些比较优秀的特性,往往会被用在业务比较复杂的场景。当然,一个事务也可以是一整个程序。
我们接下来先来介绍事务的特性,然后再来介绍我们应当如何操作事务。
事务的ACID特性
事务有四大特性,分别为原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)
我们来介绍一下:
1、原子性:即事务内部的一系列的SQL语句是不可分割的,要么全做,要么全不做。
2、一致性:事务的一致性基本可以理解为事务对于数据库数据完整性的遵循。这些完整性可以是实体完整性,可以是参照完整性,也可以是自定义完整性。它是一种状态,在事务成功完成、成功提交后的状态成为一致性状态,否则,则称非一致性状态。而事务需要保证事务提交的前后,事务是从一个一致性状态转换到另一个一致性状态。
比如刚刚银行转账的例子,如果那两个操作全做,或者是全不做,那么事务都是处于一致性的状态。否则,事务就处于非一致性状态(比如只做了一个)
3、隔离性:其就是事务对并发执行的一个控制,控制事务之间是否可见,保证事务执行时不被其他事务干扰。按照隔离级别来分类,可以分为读提交、读未提交、可重复读和串行化四种,这四种隔离级别在下文也会详细介绍到。
4、持久性:即字面意思——持久的。指事务一旦提交,其对事务的改变就是永久的。即便系统出现故障也不会丢失(写入到外存当中了)。
这四点特性,我们在后面介绍到数据库并发控制的时候依然会详细地介绍。
所以说,有了事务,程序员就能够把注意力集中在业务的处理上,而不需要考虑并发控制等一系列问题以及潜在的危机,比如服务器宕机,比如网络问题等。
那么现在,如果破坏了事务的ACID特性的某个,就有可能会出现异常执行的情况。破坏的方式有:(1)多个事务并行运行时,不同事务的操作交叉执行;(2)事务在运行过程中被强行停止而造成数据丢失损坏等。一旦被破坏,那么就会有可能使得事务处于一种非一致性的状态。
所以我们就需要解决。让它在发生了这些问题的时候,不处于一致性状态或者是能够回到一致性状态去。其对应的两点刚好就是并发控制技术和恢复技术所要解决是问题。
那么我们现在就来详细介绍一下数据库恢复技术和并发控制技术
不过在此之前,我们先来介绍一些铺垫的知识
事务控制
事务开始
事务开始的方式有两大类,一种是自动开始,是系统提供的事务,一种是手动开始,是用户自定义的事务。
一种是自动开始,即系统内置提供的事务。一般情况,这样的SQL语句一条就是一个事务。
这些语句包括:ALTER TABLE、 CREATE 、DELETE 、DROP 、FETCH 、GRANT、 INSERT、 OPEN 、REVOKE、 SELECT 、UPDATE
所以我们之前写的一些SQL语句,它都可以认为是一条就是一个事务。
另一种是手动开始。
一般我们在SQL Server中,我们用begin transaction来表示事务开始;
在MySQL当中,我们用begin 或者start transaction来表示事务开始。
事务提交
事务提交的方式有两种,一种是正常提交,我们用commit命令;一种是回滚操作,我们用rollback命令。
commit表示该事务正常结束。(即把我刚刚做的事情都提交上去了)
rollback表示回滚,即回到在该事务begin之处的状态。
我们可以来演示一下:
因为我们演示希望通过命令行的方式,所以,我们所采用的环境为Linux Centos 7,数据库为MySQL
我们登录我们的MySQL,然后这是我们的数据库:
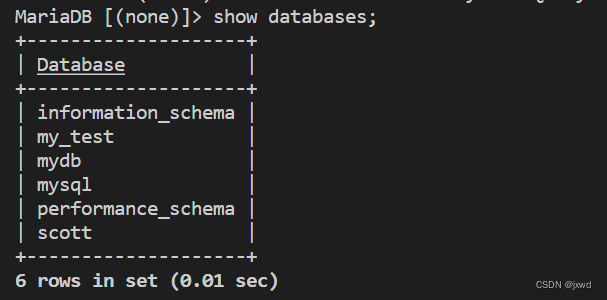
我们接下来进入到mydb数据库下:

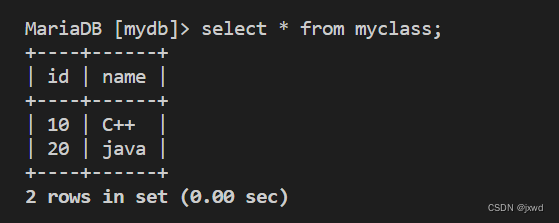
然后给大家再看一下该数据库中有哪些表:
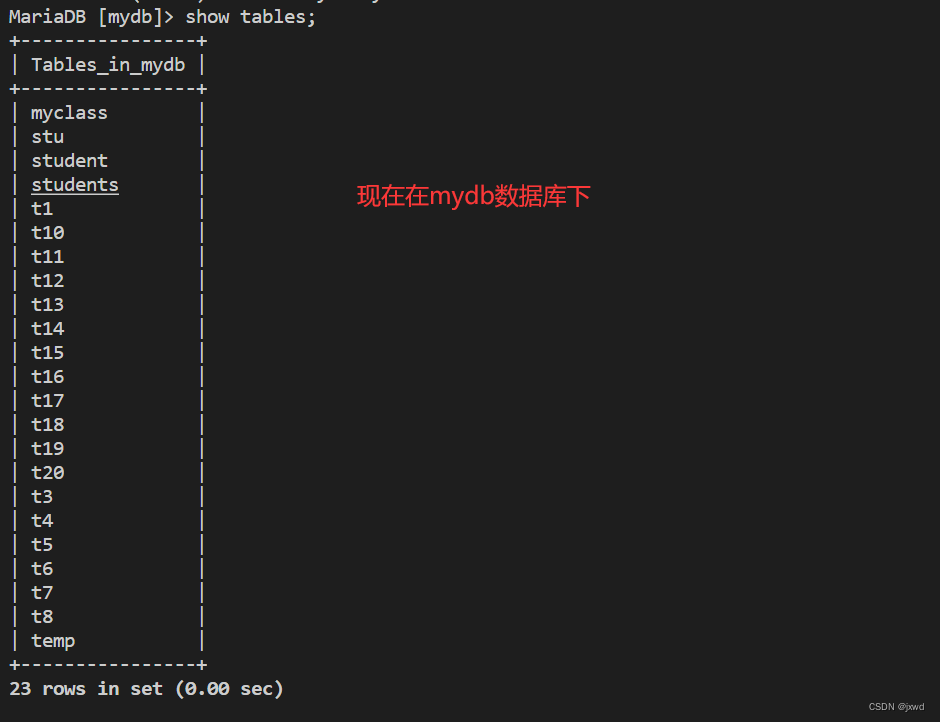
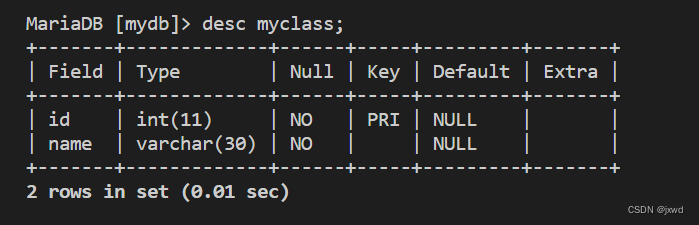
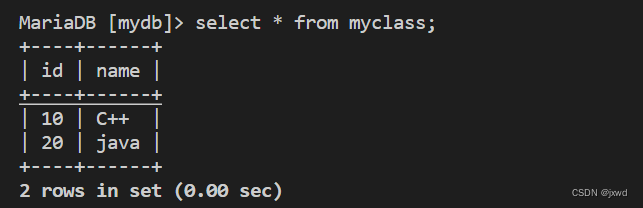
我们的演示就用最上面的myclass这个表。这个表的结构和已有数据如下图:
前置的工作已经告知,现在我们开始:
1、开始事务:(在SQL Server中是begin transaction)

2、然后进行插入:
![]()
3、查询一下插入后的结果:
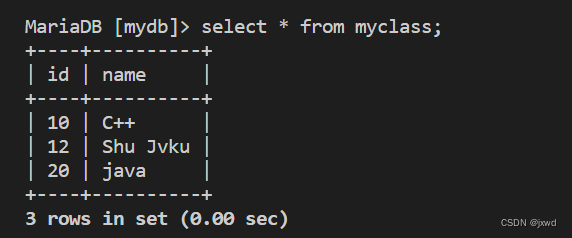
4、回滚

5、此时事务已经结束,我们可以再查找一下结果:
如图所示,上面的结果回到了begin开始前的状态。即回滚到了事务开始前的状态。
在事务中,我们也可以自己来设置回滚点,然后我们也可以通过rollback+回滚点,回滚到我们指定的位置。
关于事务的控制就暂时说到这里。
数据库恢复技术
为何要有数据库恢复技术?
诚如前面所言,事务在运行当中,故障是难以避免的,而事务一旦发生了故障,那必然是需要被强制终止。可是事务一旦强行终止,事务如果没有做完,那么就违背了事务的原子性,使得事务处于一种不一致性的状态。所以,我们就需要通过数据库恢复技术,让处于不一致性的状态转变为一致性的状态——即恢复到事务还没有开始之前的状态。
这和回滚操作比较像。但是回滚是事务(应用程序)自身完成的,倘若一整个进程都被干掉了的情况下,靠事务的回滚是无力回天的。并且从某种意义上来说,回滚并不算是事务发生了故障,因为事务正常结束的方式有两种,用户可以控制,为commit和rollback,回滚之时,事务正常结束了。
而我们的数据库恢复技术,主要针对的是严重的故障。即程序出现了严重的错误时,我们应当如何恢复它。而在这个时候,原本的事务甚至是应用程序已经被强制退出了。自然不可以直接用rollback这么简单。
故障发生的原因
故障发生的原因都有哪些呢?
我们可以将故障分为这样四种:(1)事务内部的故障;(2)系统故障;(3)介质故障;(4)由计算机病毒所引发的故障。
1、对于事务内部的故障:
①对于可以预期的,我们一般就在事物内部进行回滚操作即可(实际上它严格意义上不是系统层次的故障,即不算故障)。这一般是在程序设计上对于出现的非法的结果的一种处理。就类似于我们在之前写程序的时候,如果出现了非法的情况(比如除零错误、有实际意义的数变成了负数等),我们就perror,然后exit();同样的道理,我们这里如果出现了问题,就rollback,让其事务回到原处。它还是比较容易理解的。
②还有一些是非预期的,对于非预期的错误,它是不可以由应用程序处理的。一般是由服务器的操作系统来帮助我们处理。比如:算术溢出、死锁、违反了某些完整性的约束等。
我们以后说的事务内部的故障都说是非预期的故障。
我们一般是通过想方设法撤销事务来还原(即Undo)
2、对于系统故障:
我们一般称之为软故障,即在软件层面上出现的故障。比如系统停止了运转等,一般情况下,如果发生了系统故障,那么会出现下面的情况:
1)整个系统的正常运行突然被破坏;
2)所有正在运行的事务都非正常终止;
3)不会破坏数据库;
4)内存中数据库缓冲区的信息全部丢失
上面情况也非常好理解。就是软件层面出现了问题,程序崩溃,进程强制退出。事务、缓冲区等都会被强行停止或者清空。但不会破坏数据库本身、硬件层面等。
那么导致系统故障的原因都有哪些呢?
1)特定类型的硬件错误(如CPU故障)(我们将其考虑在系统故障的范围内)
2)操作系统故障
3)DBMS代码错误
4)系统断电
那么在系统发生故障的时候,如果事务还未提交,我们和上面第一种情况一样,强行撤消(UNDO)所有未完成事务。
事务已提交,但缓冲区中的信息尚未完全写回到磁盘上。那么我们的思路是采用重做策略(Redo),即重新执行。
(如果事务已经提交了,事务就结束了,事务结束时系统发生故障不会破坏ACID特性,所以不在我们此时讨论的系统故障范围内)
3、对于介质故障:
也被称之为硬故障,即硬件层面上发生的故障。也称外存故障。
出现介质故障的原因通常有:
1)磁盘损坏
2)磁头碰撞
3)瞬时强磁场干扰
由于这些是比较严重的错误,有可能导致之前已经成功但还未来得及写入磁盘上的事务也没了,所以,采取的做法是:装入数据库发生介质故障前某个时刻的数据副本,然后重做自此时始的所有成功事务,将这些事务已提交的结果重新记入数据库。
4、对于由计算机病毒所引发的故障:
我们知道,计算机病毒实际上就是程序;针对不同的病毒程序,往往会都能做到魔高一尺;就好像黑客一样。一种人为的故障或破坏,是一些恶作剧者研制的一种计算机程序;可以繁殖、传播;会破坏、盗窃系统中的数据;也会破坏系统文件。这类往往是防不胜防,甚至整个操作系统都能给你干崩了。
对上述故障进行总结,即所有的故障总共分为两大类:1)数据库本身发生了故障、被破坏;2)数据库没有被破坏,但是数据有可能不正确——其导致不正确的原因是由于事务的非正常结束所导致的。
数据库恢复技术的实现
那么我们现在就来去讨论,数据库恢复技术到底是怎么样去实现的。
基本原理:建立冗余数据,在发生问题的时候利用存储在系统其它地方的冗余数据来重建数据库中已被破坏或不正确的那部分数据。
那么关键问题就在于:
1)如何建立冗余数据;
2)如何利用冗余数据实施数据库恢复。
我们一个一个来介绍。
建立冗余数据
总的来说,建立冗余数据总共有两种方法,分别是:
1)数据转储;
2)登录日志文件。
数据转储
存储概念
所谓转储,就是将原有的数据拷贝一份保存到磁盘的其他位置作为副本。官方的话来说,就是DBA将整个数据库复制到磁带或另一个磁盘上保存起来的过程,备用的数据称为后备副本或后援副本。
那么我们有了转储的数据(也就是副本),在数据库发生问题的时候,我们可以将后备副本重新装入,然后使得数据库重新恢复到转储时的状态。
就好像你打游戏做任务存档一样。做完一个任务后会自动存档。不存在任务做到一半了,然后保存的。任务要么完成了,要么没有完成,在任务中途退出、断电等的时候,存档是在你该任务完成之前。那么恢复到转储时的状态也就是恢复到你打游戏做该任务之前的状态。存的那个档就可以认为是副本。
即这样的状态:
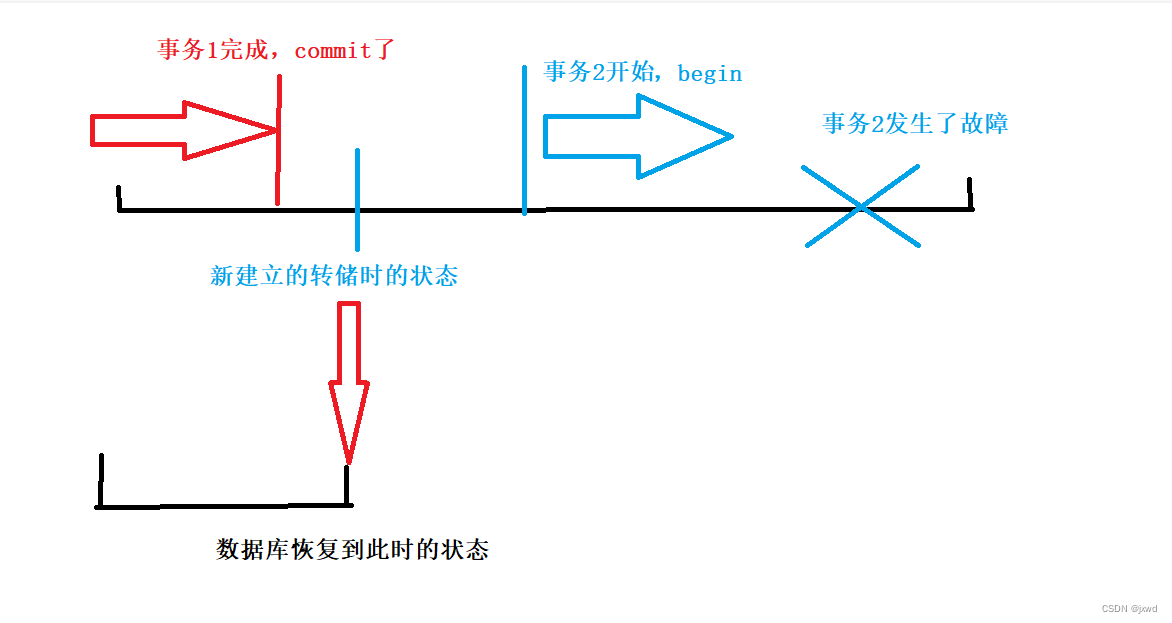
其还是比较简单的 。因为说白了它不就是搞了一个副本、搞了一个备份么。并且只能够在事务处于一致性状态的时候进行存档。
转储方法
转储方法分为静态转储、动态转储、海量转储和增量转储。
实际上很简单哈。
1)所谓静态转储,即在系统中无运行事务时进行的转储操作。即在转储的时候无数据运行。如果把存储方法也看成是一种事务,那它就好像我们事务隔离性的串行化这样的隔离级别一样(我们下面会详细说到)。
这样的转储方式,在转储开始时数据库处于一致性状态,转储期间不允许对数据库的任何存取、修改活动,它最终得到的一定是一个数据一致性的副本。所以它很简单,容易实现。(即同串行化的优点和缺点)
2)所谓动态转储,就是相对于静态存储,在存储的时候可以有事务运行,事务和存储工作可以是并发的。如果把存储方法也看成是一种事务,那么它就和我们事务隔离性的读提交方式一样(我们下面会详细说到)(所以这样一种存储方式同读提交的优点和缺点)
【优点】:转储期间允许对数据库进行存取或修改;不用等待正在运行的用户事务结束、不会影响新的事务的运行。
【缺点】:不能保证副本中的数据正确有效。会引发不可重复读的问题。(同“读提交”)但是我们这里不说那么“深奥”,就举个例子来稍微理解一下,下文在介绍到并发控制的时候会详细说到。
比如:在转储期间的某个时刻Tc,系统把数据A=100转储到磁带上,而在下一时刻Td,某一事务将A改为200。转储结束后,后备副本上的A已是过时的数据了
解决方法:建立日志文件来解决,在建立动态转储的时候,各事务对数据库的修改活动也要登记下来。(我们下一节在介绍到解决隔离性问题的时候,也会具体地说到)
3)增量转储和海量转储
通俗一点来理解,海量转储即每次转储把所有的数据都转储一遍;而增量转储每次仅转储上次转储后更新过的数据。完事。
它们的优缺点实际上也是显而易见的啦:①从恢复角度看,使用海量转储得到的后备副本进行恢复往往更方便。②但如果数据库很大,事务处理又十分频繁,则增量转储方式更实用更有效。
大家经常会看到这样一个表格:
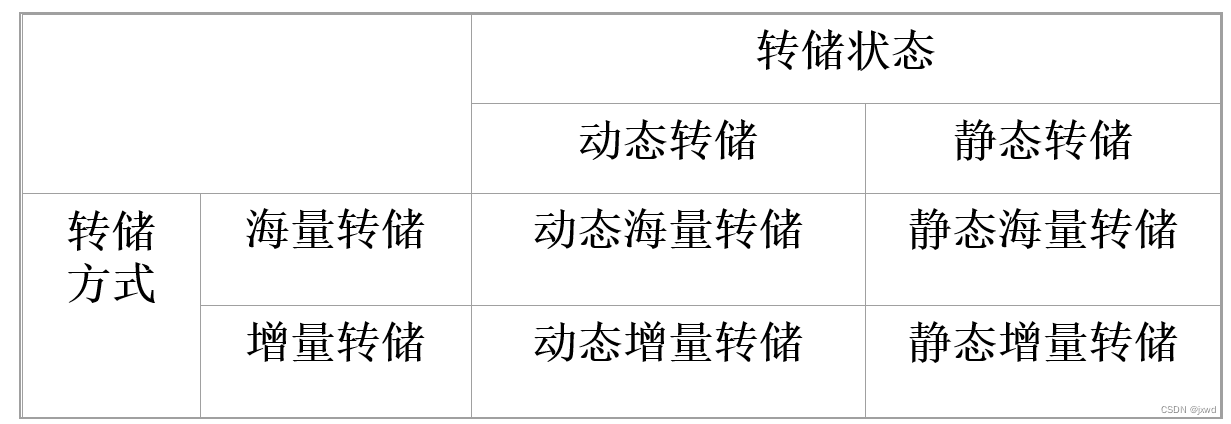
还是比较容易理解的。
登记日志文件
这是数据库恢复技术的第二种方法。
这个和解决事务隔离性问题的Read view就更像了。我们可以来探究一下。
对于日志文件,我们需要记录什么?怎样记录?
1)日志文件(log)主要用来记录事务对数据库的更新操作。
2)记录的方式:要么以记录(SQL)为单位,或者是以数据块为单位(可以理解为是多条SQL)
对于以记录为单位的数据库,需要记录每个事务的开始标志、结束标志、事务标识、操作类型、操作对象、更新前的旧值、更新后的值。它和undo log的实现是非常相像的;(我们在这里简单介绍一下,等下面介绍到undo log日志的版本链时再详细探讨)
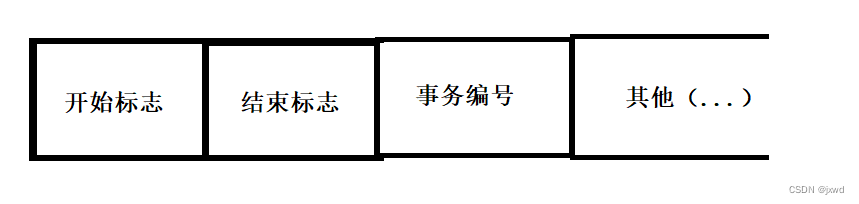
(注:上述是示意图)
对于每条更新操作,
我们有:
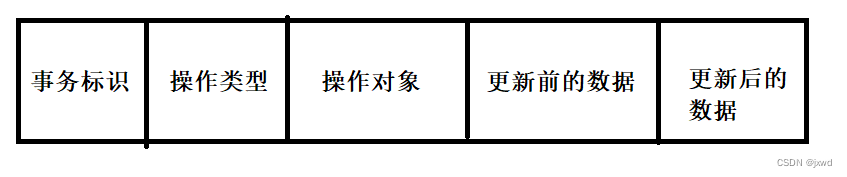
(注:上述是示意图)
那么对于以数据块为单位的记录方式,每条日志文件我们会有事务标识、被更新的数据块等内容。
有了日志文件,我们就可以进行事务故障恢复、系统故障恢复以及协助后备副本进行介质故障恢复。
我们在登记日志文件的时候,一定是按照时间顺序来去登记,这也很好理解。同时,我们是先写日志文件,后写数据库。否则,如果反过来,则有可能刚刚写入数据库、还没有来得及写入日志文件时发生了故障,这样的话以后就无法恢复这个修改了。而倘若是先写日志,但没有修改数据库,按日志文件恢复时只不过是多执行一次不必要的UNDO操作,并不会影响数据库的正确性。
数据库的恢复策略
有了上面刚刚的技术支持,那么我们在具体恢复的时候,操作是怎样进行的呢?
1、事务内部故障的修复
恢复方法:
由恢复子系统应利用日志文件撤消(UNDO)此事务已对数据库进行的修改。(需要注意的是:事务故障的恢复由系统自动完成,对用户是透明的,不需要用户干预)
具体步骤:
1)反向扫描文件日志(即从最后向前扫描日志文件),查找该事务的更新操作。2)对该事务的更新操作执行逆操作。3)直至读到此事务的开始标记为止。
2、系统故障的恢复
恢复方法:
对于已完成的事务,进行Redo(重做)操作;对于未完成的事务,进行Undo(撤销)操作。
具体步骤:
1、正向扫描日志文件(从头扫描),同时维护两个队列。一个是Redo队列,一个是Undo队列。分别存储着已经完成的事务(有begin transaction/begin/start transaction和commit/Rollback标志)和未完成的事务(仅有begin transaction/begin/start transaction标志)。
2、对Undo队列事务进行Undo处理:反向扫描日志文件,对每个Undo事务的更新操作执行逆操作;将日志记录中“更新前的值”写入数据库。
3、对重做(Redo)队列事务进行重做(REDO)处理:正向扫描日志文件,对每个REDO事务重新执行登记的操作;然后将日志记录中“更新后的值”写入数据库。
都是很显然的做法,顺理成章,水到渠成。
具有检查点的恢复技术
对于系统故障,以及上面的事务故障,我们在恢复的时候,搜索整个日志将耗费大量的时间;与此同时,Redo重新执行了大量的事务,也会浪费大量的时间。
为了提高修复效率,我们就提出一种恢复技术——即为具有检查点的恢复技术(checkpoint)
为了实现这样一种技术,我们需要做到:1)在日志文件当中增加一个记录,我们称之为检查点记录(注意它是一条记录,不是一个点);2)增加一个新的文件——命名为重新开始文件;3)需要恢复子系统在记录到日志文件期间动态地维护日志。
那么检查点记录的内容有哪些呢?在检查点记录中,我们主要记录的是建立检查点时刻所有正在执行的事务清单,以及这些事务最近一个日志记录的地址。
(如下图)
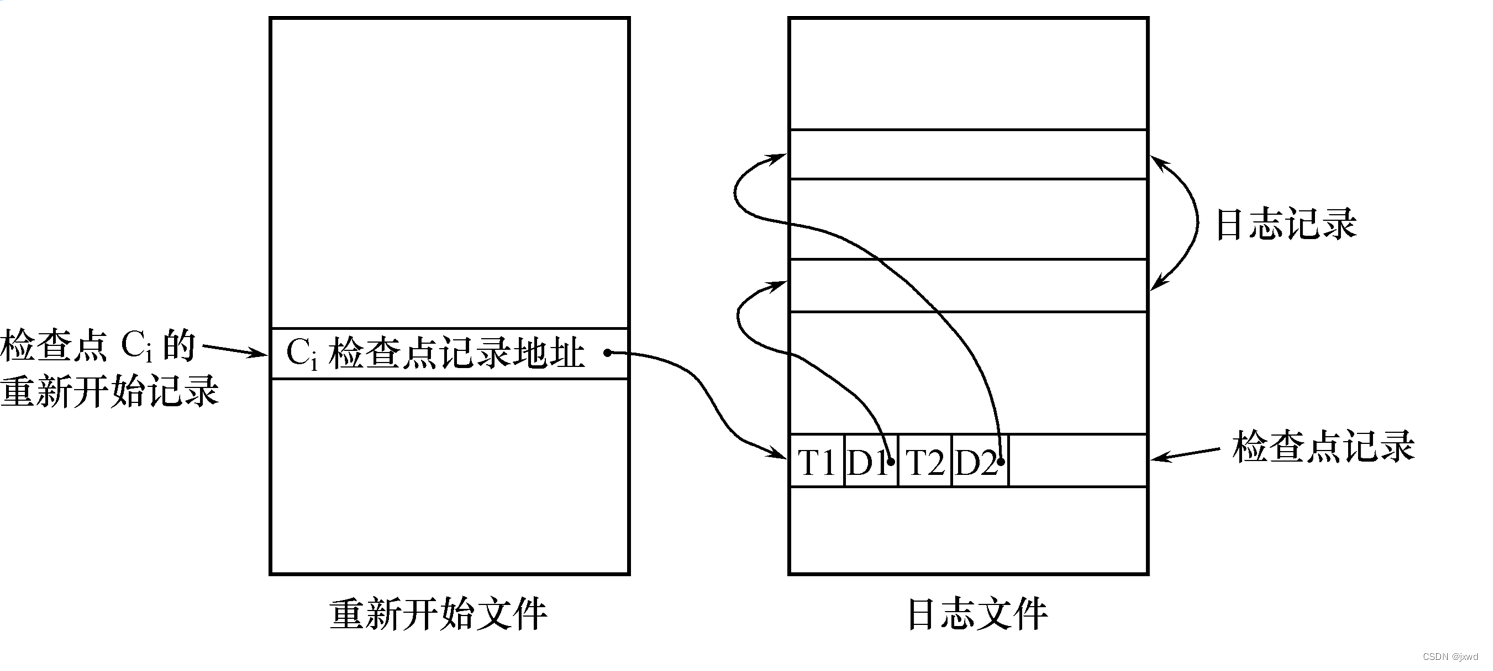
动态维护日志文件的方法:周期性(即按照某种规律)地执行如下操作:建立检查点,保存数据库状态。
1.将当前日志缓冲区中的所有日志记录写入磁盘的日志文件上
2.在日志文件中写入一个检查点记录
3.将当前数据缓冲区的所有数据记录写入磁盘的数据库中
4.把检查点记录在日志文件中的地址写入一个重新开始文件
使用检查点进行恢复,它可以提高效率,原因在于:倘若事务T在一个检查点之前提交,T对数据库所做的修改已写入数据库。所以,在进行恢复处理时,没有必要对事务T执行REDO操作。这样会大大提高了恢复的效率。
举例说明:
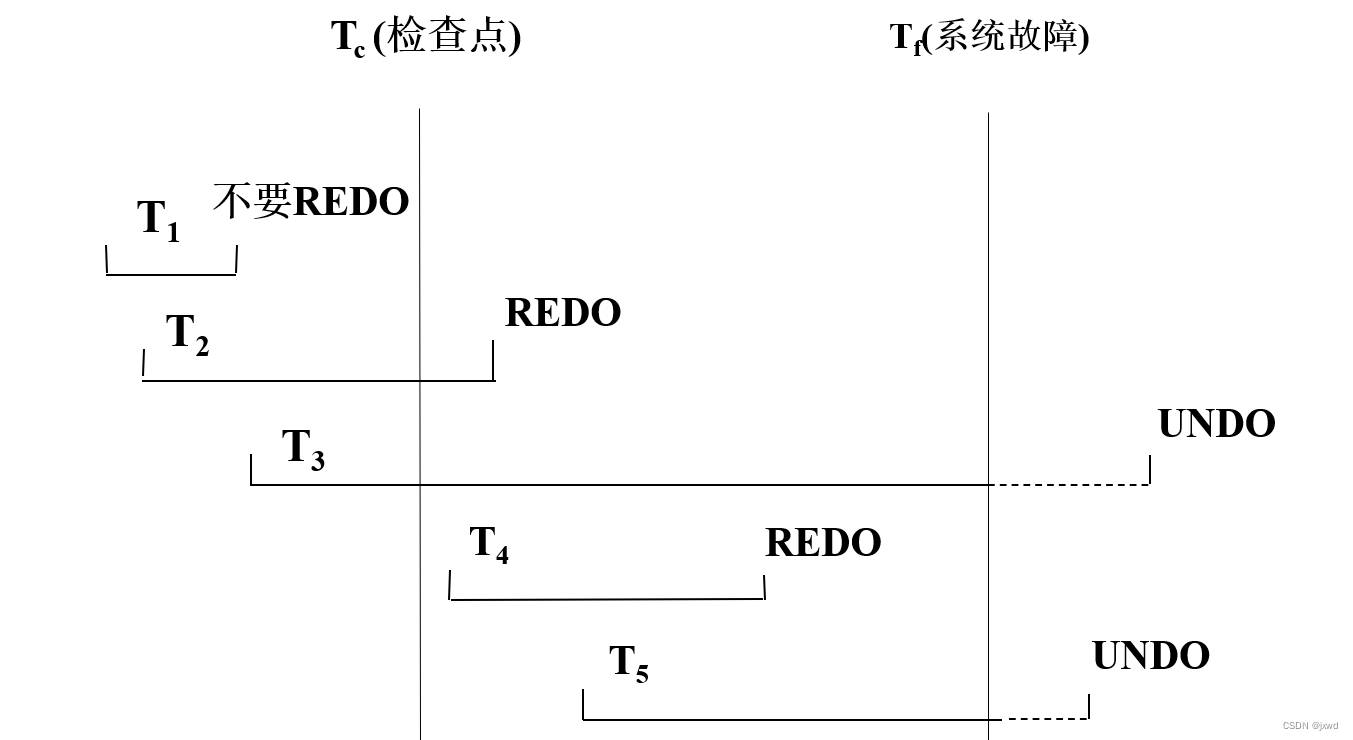
如上图,
1)T3和T5在故障发生时还未完成,所以予以撤销
2)T2和T4在检查点之后才提交,它们对数据库所做的修改在故障发生时可能还在缓冲区中,尚未写入数据库,所以要REDO
3)T1在检查点之前已提交,所以不必执行REDO操作
【具体恢复步骤】:
1)先找重新开始文件,从重新开始文件中找到最后一个检查点记录在日志文件中的地址,由该地址在日志文件中找到最后一个检查点记录。
2)由该检查点记录得到检查点建立时刻所有正在执行的事务清单Active_list,然后建立两个事务队列Undo_list 和 Redo_list,然后把Active_list暂时放入Undo_list队列,Redo队列暂为空。
3)从检查点开始正向扫描日志文件,直到日志文件结束。如有新开始的事务T,把T暂时放入Undo_list队列。如有提交的事务P,把P从Undo_list队列移到Redo_list队列。
4)对Undo_list中的每个事务执行Undo操作,对Redo_list中的每个事务执行Redo操作。
3、介质故障的恢复
需要重新完成两个事情:1.重装数据库。2.重做已完成的事务。
因为你的整个硬件都坏掉了。需要更换或者修复设备,然后重装、重做。
下面的是具体的恢复步骤,可以简单了解一下:
1、装入最新的后备数据库副本(离故障发生时刻最近的转储副本) ,使数据库恢复到最近一次转储时的一致性状态。
(1)对于静态转储的数据库副本,装入后数据库即处于一致性状态。
(2)对于动态转储的数据库副本,还须同时装入转储时刻的日志文件副本(也就是第二步).
2、装入有关的日志文件副本(转储结束时刻的日志文件副本) 后,重做已完成的事务(重做的方法不再赘述)。
总而言之,介质故障的恢复是需要DBA介入的,其主要工作是重装最近转储的数据库副本和有关的各日志文件副本,然后执行系统提供的恢复命令。这其中具体的恢复操作仍由DBMS完成
利用数据库镜像技术恢复
实际上这还是比较简单的,如下图:
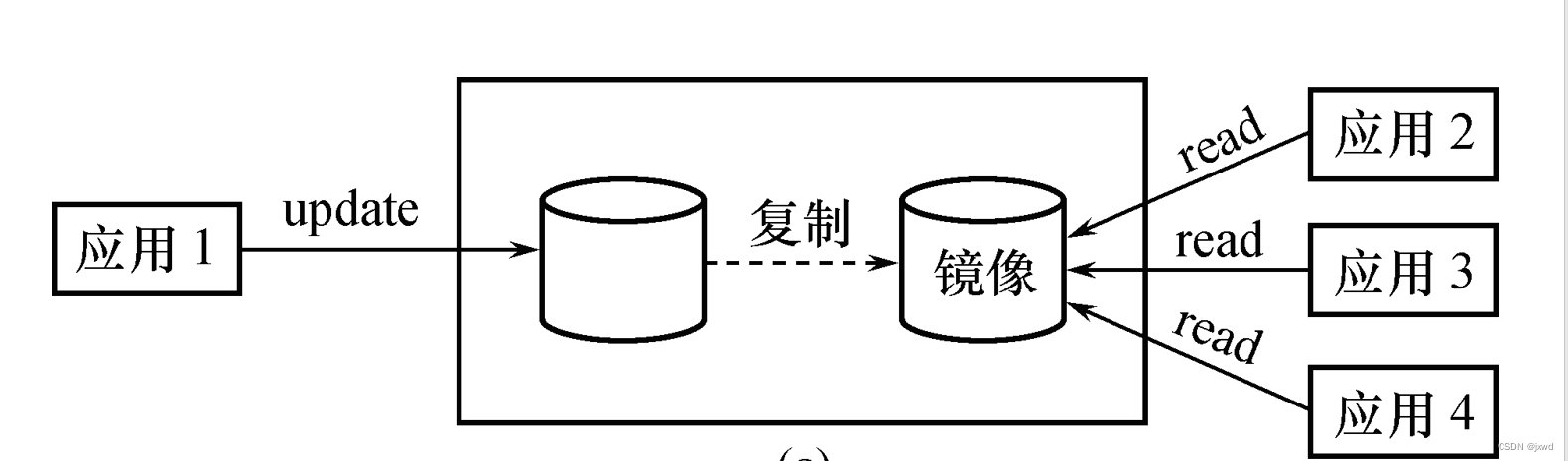
DBMS把数据库的关键部分拷贝到另外一个磁盘之中,作为镜像。同时,DBMS会自动保证镜像数据和主数据库的一致性,即每当主数据库更新时,DBMS自动把更新后的数据复制过去。
那么当发生了介质故障之时,它可由镜像磁盘继续提供使用,同时DBMS自动利用镜像磁盘数据进行数据库的恢复,不需要关闭系统和重装数据库副本。(如上图)
好啦,本节内容就到这里啦~~
码字不易,给个关注呗,笔芯~~~~