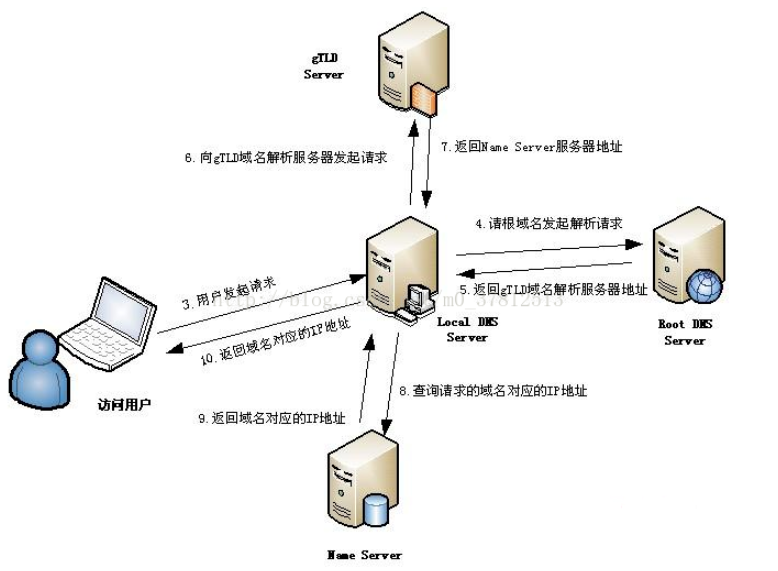
文章目录
- Abstract
- 1、Introduction
- 2、Related Work
- 2.1 HMER Methods
- 2.2 Coverage Mechanism
- 3、Methodology
- 3.1、Background
- 3.2、CNN Encoder
- 3.3、Positional Encoding
- 3.4、Attention Refinement Module
- 3.5、Coverage
- 4 Experiments
论文链接:https://arxiv.org/abs/2207.04410
github地址:https://github.com/Green-Wood/CoMER
Abstract
我们提出了一种新的注意细化模块(ARM),在不影响其并行性的情况下,利用过去的对齐信息来细化注意力权重。此外,我们通过自我覆盖和交叉覆盖,将覆盖信息发挥到极致,它利用了当前和过去的对齐信息。
1、Introduction
除了的书写风格,我们还需要建模符号和上下文之间的关系。例如,在Latex中,模型需要生成“ˆ”、“_”、“{”和“}”来描述二维图像中符号之间的位置和层次关系。在HMER任务中广泛使用编码器-解码器的结构,在编码器部分进行特征提取,在解码器部分进行语言建模。
Transformer是一种仅基于注意机制的神经网络结构,它已逐渐取代RNN成为自然语言处理中的首选模型。通过Transformer的自注意机制,建立一对一连接。这种架构时的Transformer能够更好地在token之间建立长期依赖。目前,Transformer在计算机视觉和多模态中受到越来越多的关注。
虽然Transformer已经成为NLP的标准,但它在HMER任务中的性能与RNN相比并不令人满意。我们注意到,使用变压器解码器的模型仍然存在缺乏注意力覆盖问题。主要表现在两个方面:过度解析意味着图像的某些部分被不必要地经过多次,而过度解析则意味着某些区域仍然未被解析。RNN解码器使用覆盖关注来缓解这一问题。然而,当前Transformer解码器使用了普通的点积计算注意力,而没有覆盖机制,这是限制其性能的关键因素。
Transformer中每一步的计算都是相互独立的,而不像RNN那样,其中当前一步的计算取决于上一步的状态。虽然这种性质改进了变压器中的并行性,但它使得Transformer解码器很难利用注意力覆盖。为了解决上述问题,我们提出了一种新的模型来利用转换解码器的覆盖信息,名为CoMER。受到RNN中的覆盖机制的启发,我们希望Transformer将更多的注意力分配到尚未被解析的区域上。具体地说,我们提出了一种新的、通用的注意细化模块(ARM),它可以在不影响其并行性的情况下,动态地利用过去的对齐信息来细化注意力权值。为了充分利用来自不同层的对齐信息,我们提出了自覆盖和交叉覆盖来分别利用来自当前层和上一层的过去对齐信息。我们进一步表明,CoMER在HMER任务中的表现优于普通的Transformer解码器和RNN解码器。我们的工作的主要贡献总结如下:
- 我们提出了一种新的、通用的注意细化模块(ARM)来细化变压器解码器中的注意权重,在不损害其并行性的情况下,有效地缓解了覆盖缺乏的问题。
- 我们提出了自覆盖、交叉覆盖和融合覆盖,以充分利用Transformer解码器中不同层生成的过去对齐信息。
2、Related Work
2.1 HMER Methods
略
2.2 Coverage Mechanism
覆盖机制是为了解决机器翻译任务中的过翻译和翻译不足问题。之前所有在HMER任务使用覆盖机制的RNN中,通过引入覆盖向量来表示图像特征向量是否已经解析,引导模型把更多的注意力放在未解析的区域。这是一个逐步的细化的过程,解码器需要为每一步收集过去的对齐信息。对于RNN模型,解码器可以自然地在每一步中累积注意权值,但对于执行并行译码的变压器解码器则比较困难。
3、Methodology
CoMER主要由四部分组成:
- CNN编码器,主要从二维公式图像中提取特征。
- 位置编码,为transformer解码器添加位置信息。
- 注意细化模块(ARM),用过去的对齐信息对注意权重进行细化。
- 自覆盖和交叉覆盖利用了来自当前和之前层的对齐信息。
3.1、Background
- Coverage Attention in RNN
注意力覆盖在基于RNN的HMER模型中得到了广泛的应用。覆盖向量为注意力模型提供了一个区域是否已被解析的信息。让编码器产生扁平的输出图像特征
X
f
∈
R
L
×
d
m
o
d
e
l
X_{f}\in R^{L\times d_{model}}
Xf∈RL×dmodel模型,序列长度为
L
=
h
o
×
w
o
L = h_{o}×w_{o}
L=ho×wo。在每一步t中,将之前的注意权值
a
k
a_{k}
ak累积为注意力向量
c
t
c_{t}
ct,然后转化为覆盖矩阵
F
t
F_{t}
Ft。
c
t
=
∑
k
=
1
t
−
1
a
k
∈
R
L
F
t
=
c
o
n
v
(
c
t
)
∈
R
L
×
d
a
t
t
n
c_{t} = \sum^{t-1}_{k=1}a_{k} \in R^{L} \\ F_{t}=conv(c_{t}) \in R^{L \times d_{attn}}
ct=k=1∑t−1ak∈RLFt=conv(ct)∈RL×dattn
这里cov(·)表示11×11卷积层和线性层函数。
在注意机制中,我们可以计算每个图像特征的相似度得分
e
t
,
i
e_{t,i}
et,i。当前步骤t时的注意权重计算如下:
e
t
=
t
a
n
h
(
H
t
W
h
+
X
f
W
x
+
F
t
)
V
a
(等式
3
)
a
t
=
s
o
f
t
m
a
x
(
e
t
)
∈
R
L
e_{t}=tanh(H_{t}W_{h}+X_{f}W_{x}+F_{t})V_{a} (等式3)\\ a_{t}=softmax(e_{t}) \in R^{L}
et=tanh(HtWh+XfWx+Ft)Va(等式3)at=softmax(et)∈RL
- Multi-Head Attention
多头注意点是Transformer中最关键的组成部分。使用模型维度大小 d m o d e l d_{model} dmodel、查询序列长度 L L L和键序列长度 L L L,我们将多头注意力计算分为四个部分:
- 将Q、K和V投影到相同的子空间;
- 计算比例点积 E i E_{i} Ei;
- 计算注意权值 A i A_{i} Ai;
- 将注意权值 A i A_{i} Ai与值 V i V_{i} Vi相乘。
Q i , K i , V i = Q W i Q , K W i K , V W i V E i = Q i K i T d k ∈ R T × L A i = s o f t m a x ( E i ) ∈ R T × L H e a d i = A i V i M u l t i H e a d ( Q , K , V ) = [ H e a d 1 , … , H e a d h ] Q_{i},K_{i},V_{i}=QW^{Q}_{i},KW^{K}_{i},VW^{V}_{i} \\ E_{i}=\frac{Q_{i}K^{T}_{i}}{\sqrt d_{k}} \in R^{T \times L} \\ A_{i}=softmax(E_{i}) \in R^{T \times L} \\ Head_{i}=A_{i}V_{i}\\ MultiHead(Q,K,V)=[Head_{1},\dots,Head_{h}] Qi,Ki,Vi=QWiQ,KWiK,VWiVEi=dkQiKiT∈RT×LAi=softmax(Ei)∈RT×LHeadi=AiViMultiHead(Q,K,V)=[Head1,…,Headh]
3.2、CNN Encoder
我们使用DenseNet 来提取二维公式图像中的特征。图像输出特征为 X a ∈ R h o × w o × d m o d e l X_{a} \in R^{h_{o} \times w_{o} \times d_{model}} Xa∈Rho×wo×dmodel。
3.3、Positional Encoding
略
3.4、Attention Refinement Module
虽然覆盖问题在RNN解码器中得到了广泛的应用,但由于Transformer的并行解码,很难在Transformer解码器中直接使用。由于不能直接在Transformer中建模覆盖信息,导致其在HMER任务中的性能不理想。我们将首先在本小节中介绍在变压器中使用覆盖信息的困难,然后提出一种新的注意力细化模块(ARM)来解决这个问题。
一个简单的解决方案是利用多头注意力权重A,将其累积为C,并使用等式中的conv(.)函数将其转化为覆盖矩阵F。然而考虑到空间复杂性,这种方法不可接受的。如果多头注意力权重 A ∈ R T × L × h A \in R^{T \times L \times h } A∈RT×L×h,conv(.)函数将作用于每一个时间步长和图像特征,这将产生空间复杂度为 O ( T L h d ) O(TLhd) O(TLhd)的覆盖矩阵F。
我们可以看到,瓶颈来自于等式中的tanh(·)函数(见Coverage Attention in RNN小节中的等式3),其中覆盖矩阵需要先与其他特征向量求和,然后乘以向量va。如果我们能先将覆盖矩阵与va相乘,再加上注意的结果,空间复杂度将大大降低到 O ( T L h ) O(TLh) O(TLh)。所以我们修改了等式(3)具体内容如下:
e
t
′
=
t
a
n
h
(
H
t
W
h
+
X
f
W
x
)
v
a
+
F
t
V
a
=
t
a
n
h
(
H
t
W
h
+
X
f
W
x
)
v
a
+
r
t
e^{'}_{t}=tanh(H_tW_h+X_fW_x)v_a+F_tVa=tanh(H_tW_h+X_fW_x)v_a+r_t
et′=tanh(HtWh+XfWx)va+FtVa=tanh(HtWh+XfWx)va+rt
其中,
e
t
′
e^{'}_{t}
et′可以被分为注意项和细化项
r
t
r_{t}
rt,细化项可以由覆盖建模函数直接生成,我们将上述等式命名为ARM(Attention Refinement Framework)。

图1 注意力细化模块(ARM)
为了在Transform中使用ARM,点积矩阵可以被用来作为注意力项,细化项的矩阵R通过注意力权重计算得到。注意,我们在这里使用一般的注意权重A来提供过去的对齐信息。
我们定义一个函数
ϕ
:
R
T
×
L
×
h
⟼
R
T
×
L
×
h
\phi:R^{T \times L \times h} \longmapsto R^{T \times L \times h}
ϕ:RT×L×h⟼RT×L×h,它的输入为注意力权重A,输出为细化矩阵R。使用核大小为
k
c
k_{c}
kc,中间维度为
d
c
≪
h
×
d
a
t
t
n
d_{c} \ll h \times d_{attn}
dc≪h×dattn,输出特征的维度为
L
=
h
o
×
w
o
L=h_{o} \times w_{o}
L=ho×wo,函数
ϕ
\phi
ϕ的定义如下:
R
=
ϕ
(
A
)
=
n
o
r
m
(
m
a
x
(
0
,
K
∗
C
~
+
b
c
)
W
c
)
C
~
=
r
e
s
h
a
p
e
(
C
)
∈
R
T
×
h
o
×
w
o
×
h
c
t
=
∑
k
=
1
t
−
1
a
k
∈
R
L
×
h
R = \phi(A)=norm(max(0,K* \tilde{C}+b_{c})W_{c}) \\ \tilde{C}=reshape(C)\in R^{T \times h_{o} \times w_{o} \times h} \\ c_{t} = \sum^{t-1}_{k=1}a_{k} \in R^{L \times h}
R=ϕ(A)=norm(max(0,K∗C~+bc)Wc)C~=reshape(C)∈RT×ho×wo×hct=k=1∑t−1ak∈RL×h
我们认为函数
ϕ
\phi
ϕ可以提取局部覆盖特征来检测待识别区域的边缘,并识别未解析区域。最后,我们通过减去细化项R来细化注意项E。
A
R
M
(
E
,
A
)
=
E
−
R
=
E
−
ϕ
(
A
)
ARM(E,A)=E-R=E-\phi(A)
ARM(E,A)=E−R=E−ϕ(A)
3.5、Coverage
在本节中,我们将讨论在等式中的一般注意权重A的具体选择,我们提出了自覆盖和交叉覆盖来利用来自不同阶段的对齐信息,并在模型中引入了不同的过去对齐信息。
Self-coverage 自覆盖是指使用当前图层生成的对齐信息作为注意力细化模块的输入。对于当前的层j,我们首先计算注意权重A (j),然后对自己进行细化。
A
(
j
)
=
s
o
f
t
m
a
x
(
E
(
j
)
)
∈
R
T
×
L
×
h
E
^
(
j
)
=
A
R
M
(
E
(
j
)
,
A
(
j
)
)
A
^
(
j
)
=
s
o
f
t
m
a
x
(
E
^
(
j
)
)
A^{(j)} = softmax(E^{(j)}) \in R^{T \times L \times h} \\ \hat{E}^{(j)}=ARM(E^{(j)},A^{(j)}) \\ \hat{A}^{(j)}=softmax(\hat{E}^{(j)})
A(j)=softmax(E(j))∈RT×L×hE^(j)=ARM(E(j),A(j))A^(j)=softmax(E^(j))
Fusion-coverage 结合自覆盖和交叉覆盖,我们提出了一种新的融合覆盖方法,以充分利用从不同层生成的过去对齐信息。
E
^
(
j
)
=
A
R
M
(
E
(
j
)
,
[
A
(
j
)
;
A
^
(
j
−
1
)
]
)
A
^
(
j
)
=
s
o
f
t
m
a
x
(
E
^
(
j
)
)
\hat{E}^{(j)}=ARM(E^{(j)},[A^{(j)};\hat{A}^{(j-1)}]) \\ \hat{A}^{(j)}=softmax(\hat{E}^{(j)})
E^(j)=ARM(E(j),[A(j);A^(j−1)])A^(j)=softmax(E^(j))
4 Experiments

图2 与CROHME2014/2016/2019测试集上当前方法的性能比较(以%计算)

图3 在CROHME2014测试集上,不同长度的识别精度(%)