一、爬虫学习建议:
在编写python爬虫程序时,只需要做以下两件事:
发送GET请求,获取HTML [第一类]
解析HTML,获取数据 [第二类]
这两件事,python都有相应的库帮你去做,你只需要知道如何去用它们就可以了。
爬虫目前涉及两种一是获取网页类的如urllib库,requests库,对网页进行获取,获取内容,保存,响应等。
二、解析网页内容:
是网页中有很多内容,爬虫的本质是选择我需要的内容,例如我只想网页中的一部分图片,一部分视频或者一部分特殊的内容,这个选择的“部分”主要有:
1.正则表达式
2.xpath
3.BeautifulSoup
4.jsonparh
5.selenium
前期练习的时候,可以使用requests库+正则表达式 进行练习
后期使用的过程中,建议requests库+xpath库+Xpath Helper【浏览器工具】
工作中建议重点:requests库+xpath库+Xpath Helper【浏览器工具】+selenium结合使用
三、本次重点梳理关于selenium的事项--浏览器的下载对应驱动
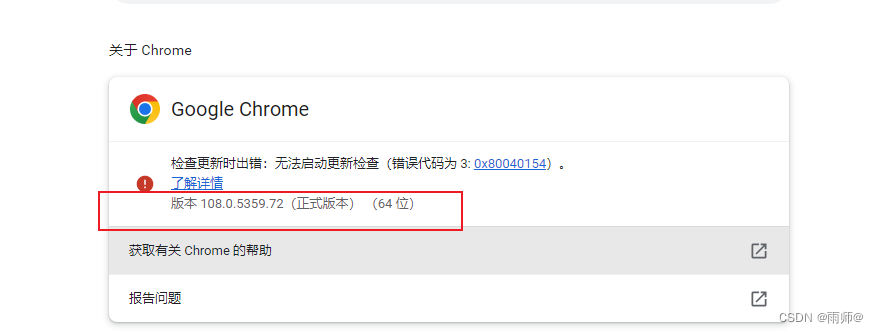
3.1查看自己电脑的chrome的版本号码
python中使用chrome,首先自己的电脑的安装chrome浏览器,并且查看版本号码,然后去下载对应的驱动程序
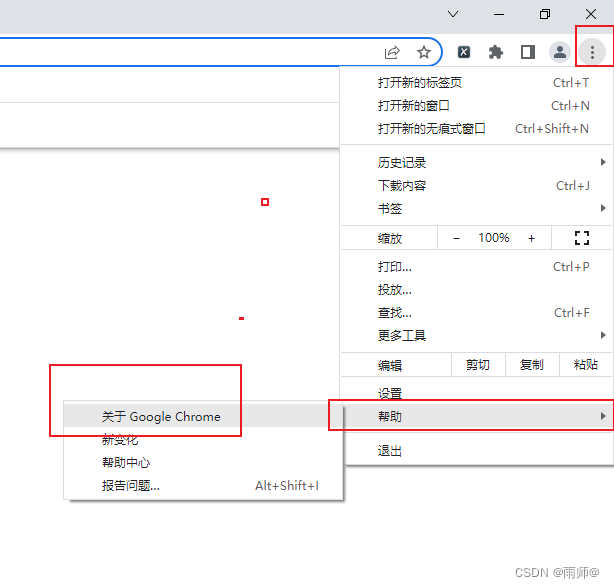
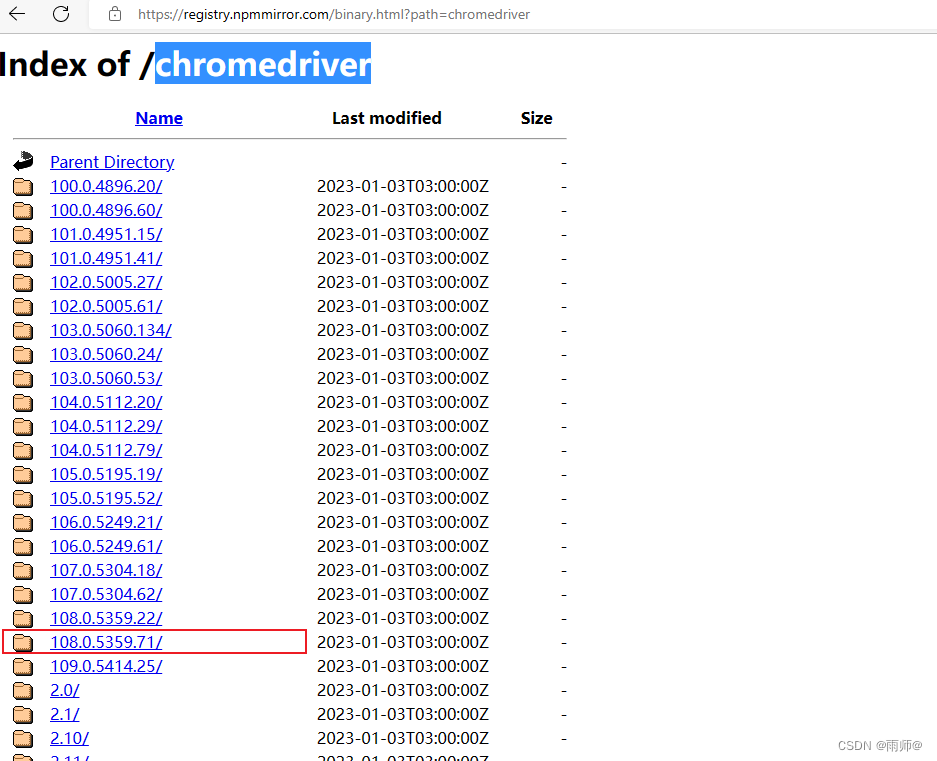
3.2驱动的下载chromedriver
https://registry.npmmirror.com/binary.html?path=chromedriver查找与自己电脑最接近的浏览器的版本号码进行下载

3.3把下载的压缩包解压放入你的python的程序的目录下

四、code代码
4.1selenium背景内容
随着爬虫的反扒措施加强,原来的受限,能不能利用现在的浏览器方式进行数据获取就是放在研究的地方,seleniu也是自动化测试工具
可以打开浏览器,然后相认一样操作浏览器,可以直接获取网页上的各种信息
4.2python中安装selenium
pip install selenium
4.3验证是否可以使用
#让selenium启动谷歌浏览器的导入工作
from selenium.webdriver import Chrome
#1.创建浏览器对象
web=Chrome(executable_path="./chromedriver")
#2.打开一个网址
web.get("http://www.baidu.com")
#3.获取网页的title--验证是否驱动以及程序的是否可以使用
print(web.title)4.4selenium+xpath联合使用的小实例
#让selenium启动谷歌浏览器的导入工作
from selenium.webdriver import Chrome
from lxml import etree
#1.创建浏览器对象,并且指定程序的驱动存在位置
web=Chrome(executable_path="./chromedriver")
#2.打开一个网址
web.get("https://sc.chinaz.com/tupian/huacaotupian.html")
#3.page_source获取浏览器当前页面的源码数据
html_text=web.page_source
#4.打印数据
# print(html_text)
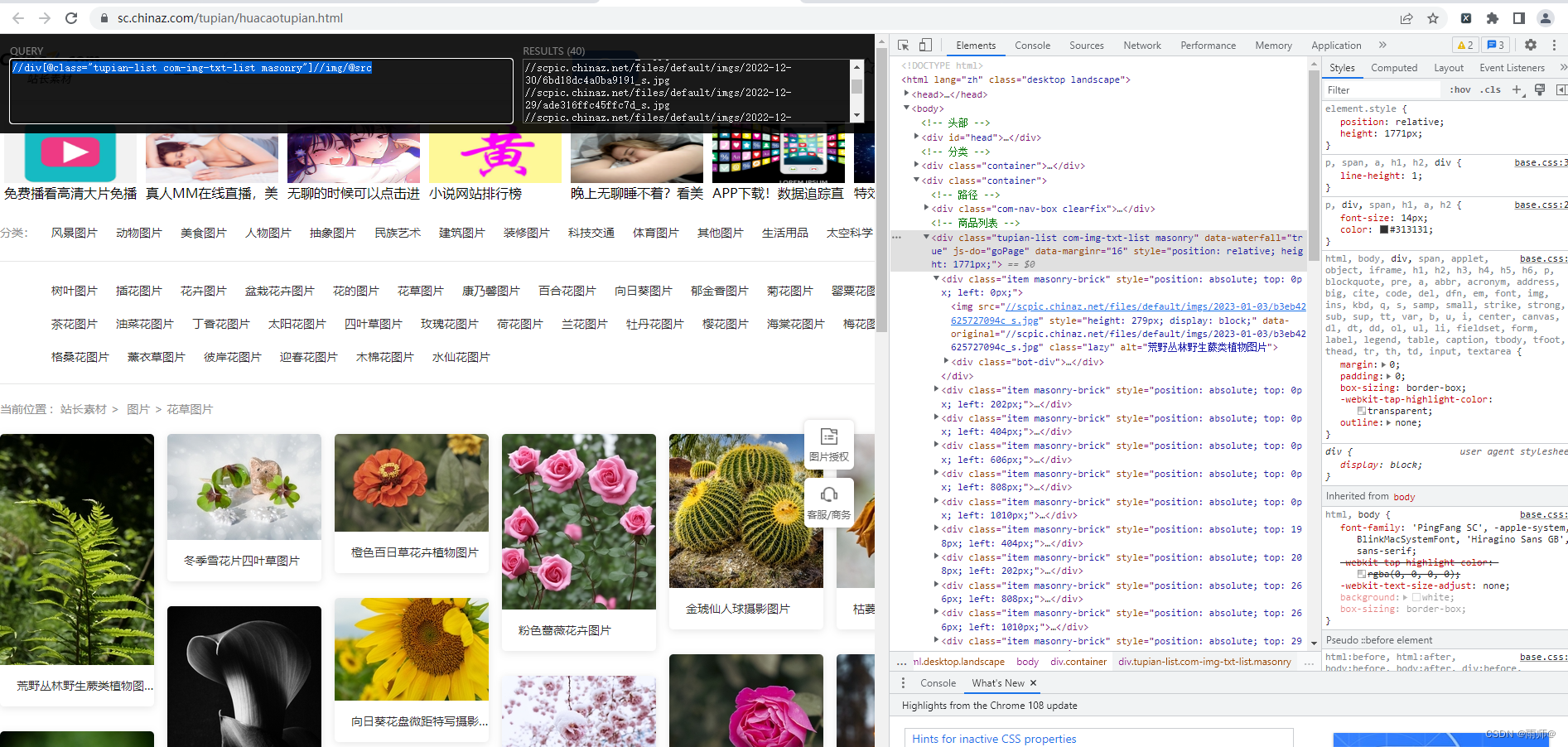
#5.小实例,获取站长之家的一些图片地址链接地址
tree=etree.HTML(html_text)
# xpath的规则
xpathguize='//div[@class="tupian-list com-img-txt-list masonry"]//img/@src'
jpgslists=tree.xpath(xpathguize)
for jpgurl in jpgslists:
print(jpgurl)
# #.获取网页的title--验证是否驱动以及程序的是否可以使用
# print(web.title)4.5使用工具获取xpath规则的步骤以及方法
五、selenium的常用功能:
5.1实例 通过自动通过百度搜索 内容

#让selenium启动谷歌浏览器的导入工作
from time import sleep
from selenium import webdriver
#1.创建浏览器对象,并且指定程序的驱动存在位置
from selenium.webdriver.common.by import By
bro=webdriver.Chrome(executable_path="./chromedriver")
#2.打开一个网址
bro.get("https://www.baidu.com/")
#3.标签定位
# 语法:find_element(by, value)
# by:查找的依据(根据什么属性来找),比如"id", "class name"
# value:属性或者标签名称具体的值,比如"a",
# .find_element()和find_elements()的区别
#
# (1)find_element()的返回结果是一个WebElement对象,如果符合条件的有多个,默认返回找到的第一个,如果没有找到则抛出NoSuchElementException异常。
#
# (2)find_elements()的返回结果是一个包含所有符合条件的WebElement对象的列表,如果未找到,则返回一个空列表。
# (1)通过webdriver对象的find_element("属性名","属性值")
# 获取百度的搜索框对象
# search_input_baidu=bro.find_element("id","kw")
# search_input_baidu=bro.find_element(by="id",value="kw")
# t通过id属性查找带标签
search_input_baidu=bro.find_element(By.ID,"kw")
# 在输入框中输入搜索条件"站长之家"
search_input_baidu.send_keys("站长之家")
sleep(1)
# 点击搜索按钮
# 通过类属性查找定位到标签
btn_baidu=bro.find_element(By.CLASS_NAME,"bg s_ipt_wr new-pmd quickdelete-wrap")
# 单击搜索按钮
btn_baidu.click()
sleep(5)
# 浏览器退出
bro.quit()
# #标签交互
5.2补充信息:
执行js程序代码:
# 执行js代码,js代码移动到屏幕的最低端
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')# 回退
bro.back()
# 前进
bro.forward()
# 浏览器退出
bro.quit()
# #标签交互